BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
Author: Google AI Language, Jacob Devlin
Link: https://arxiv.org/pdf/1810.04805.pdf
Reading date: March 13, 2022
Type: Paper
Abstract
BERT - Bidirectional Encoder Representations from Transformers
목적 : 레이블링 되지 않은 텍스트를 모든 레이어에서 오른쪽, 왼쪽 문맥 모두 같이 고려하면서 deep bidirectional representations을 pretrain 하는 것이다.
이렇게 pretrained BERT모델로 output layer를 붙여 다양한 task에서 높은 성능을 보인다.
Introduction
하위 task에 pre-trained language representations를 적용하기 위한 2가지 방법이 있다.
-
feature-based
특정 task를 위한 모델 구좌에 추가적인 feature를 붙이는 것이다.
ex) ELMo
-
fine-tuning
pre-trained된 파라미터들을 fine-tuning하는 것이다.
ex) Generative Pre-trained Transformer(OpenAI GPT)
이런 방식들은 pre-training할 때, 동일한 objective function을 가지는 unidirectional language models를 사용한다.
→ 한계 : 일반적인 language 모델은 unidirectional(n-gram 방식), 아키텍처 선택에 제한을 준다.
이러한 규제는 문장단위 task에 최적이 아니며, 양방향으로 문맥 통합하는 것이 중요한 QA와 같이 토큰단위 task들에 fine-tuning 할 때, 안좋은 영향을 준다.
논문에서 BERT는 MLM(Masked Language Model)로 unidirectionality 규제를 완화한다.
MLM
입력 데이터에서 랜덤하게 몇몇 토큰을 가리고, 가려진 토큰의 id를 예측한다.
이 방식은 전체적인 문맥을 파악하도록 도와준다.
next sentence prediction
문장들이 서로 이어지는 지를 pre-train한다.
- BERT의 contributions
- 랜덤하게 토큰들을 mask하여 pre-trained deep bidirectional representations를 가능하게 했다.(문맥 파악)
- pre-trained representations가 task별로 아키텍처가 매우 세분화되는 것을 줄여주었다. 당시 문장단위와 토큰단위에 SOTA를 달성한 첫번째 fine-tuning based reprsentation 모델이었다.
- 11개의 NLP task에 SOTA를 달성했었다.
Related Work
- 일반적인 pre-training language representation에 대한 긴 역사
Unsupervised Feature-based Approaches
word embedding을 pre-train 하기 위해서, left-to-right language 모델링 기법들이 사용되었다.
이러한 방식은 문장 임베딩 같이 더 굵직하거나 paragrah 임베딩으로 일반화되간다.
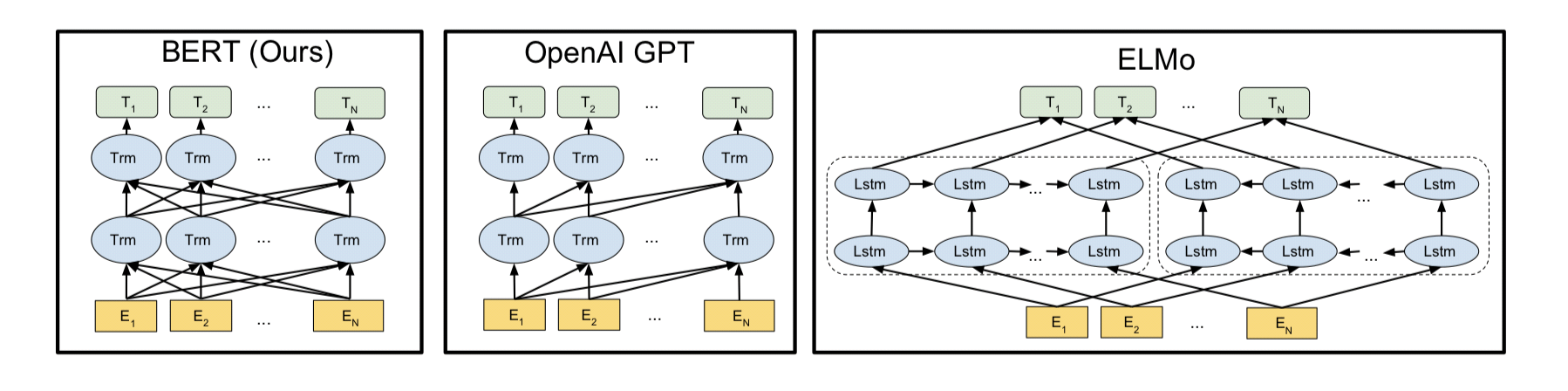
ELMo와 그 이전 방법들은 left-to-right으로 문맥에 대한 피처들과 right-to-left language모델을 추출한다.
left-to-right과 right-to-left representation을 연결하여 각 토큰의 contextual representation을 만든다.
그렇지만 deep한 bidirectional은 아니다.
Unsupervised Fine-tuning Approaches
contextual token representation을 생성하는 인코더들을 레이블링 되지 않은 텍스트로 pre-train하고 fine-tuning하는 방법이다.
이 방법의 장점은 파라미터 수가 적다는 것이다.
이 예시로 OpenAI GPT가 있다.
Transfer Learning from Supervised Data
큰 데이터셋의 supervised task에서는 효과적인 transfer를 보여줬다.
컴퓨터 비전 연구에서도 큰 pre-trained 모델들에서 transfer learning의 중요성을 보였다.
→ImageNet으로 pre-train된 모델을 fine-tuning
BERT
- 2가지 스텝으로 구성
- pre-training
- 레이블링이 안된 pre-training task와 다른 데이터로 학습
- fine-tuning
- pre-trainined 모델의 파라미터를 초기값으로 가진다.
- 레이블링된 데이터를 가지고 fine-tuning을 진행한다.
- pre-training
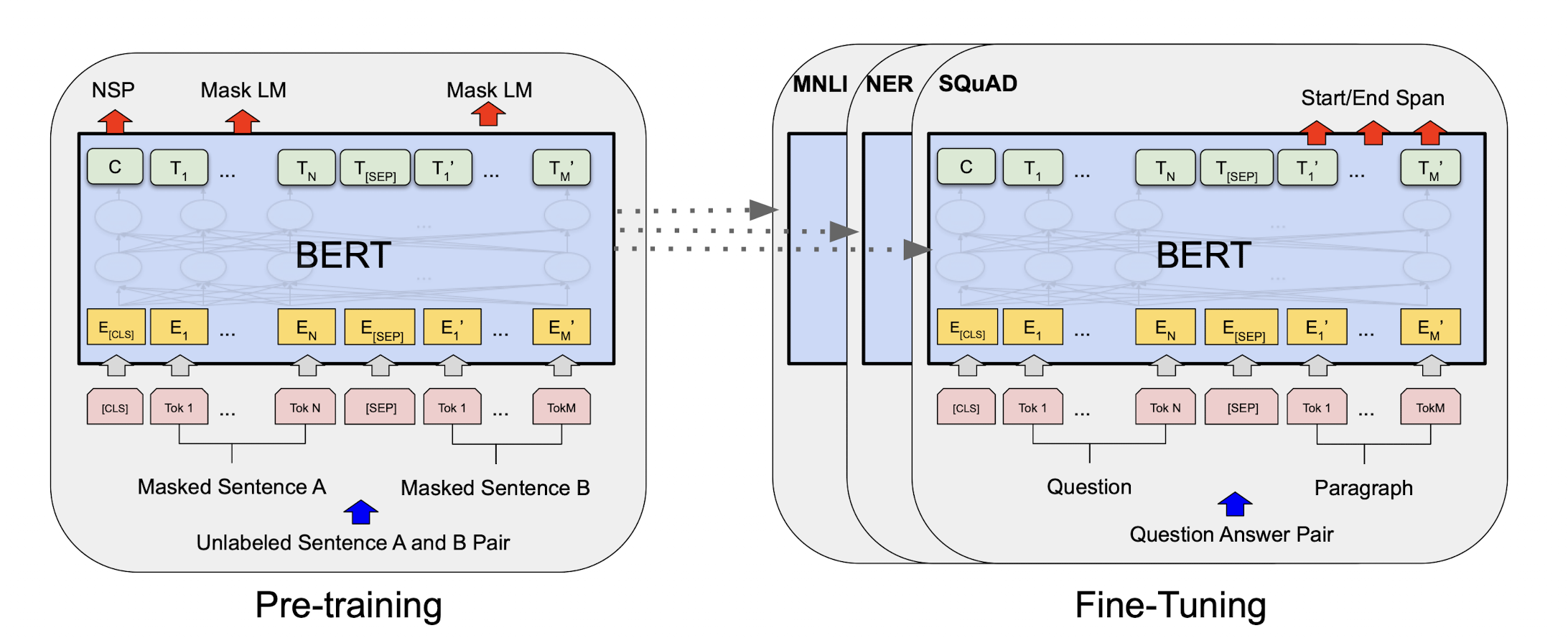
→ 서로 다른 하위 task에 사용할 때도 같은 pre-trained 파라미터를 사용한다.
Model Architecture
BERT의 모델 구조는 multi-layer bidirectional Transformer 인코더이다.
L : layer 수
H : hidden 사이즈
A : self-attention head 수
로 아래 수식에서 표현한다.
base 경우는 OpenAI GPT 모델과 모델 사이즈가 같다.
그러나, constrained self-attention을 사용과 bidirectional self-attention 사용의 차이를 가진다.
Input/Output Representations
- 3만개의 토큰 vocabulary를 가진 WordPiece 임베딩 사용하였다.
- 문장 제일 앞에는 [CLS] 토큰이다. CLS는 special classification token으로 final hidden vector에서(그림1에서 C) token sequence의 결합된 의미를 가지고, 간단한 classifier를 붙여 분류문제를 해결할 수 있다. 만약 분류문제가 아니라면 이 토큰을 무시하면 된다.
- 하나의 sequence 안에는 문장 쌍들이 있다. 이 문장들을 구별하기 위해 [SEP]-special token과 어느 문장에 속하는지 알려주는 임베딩을 한다.
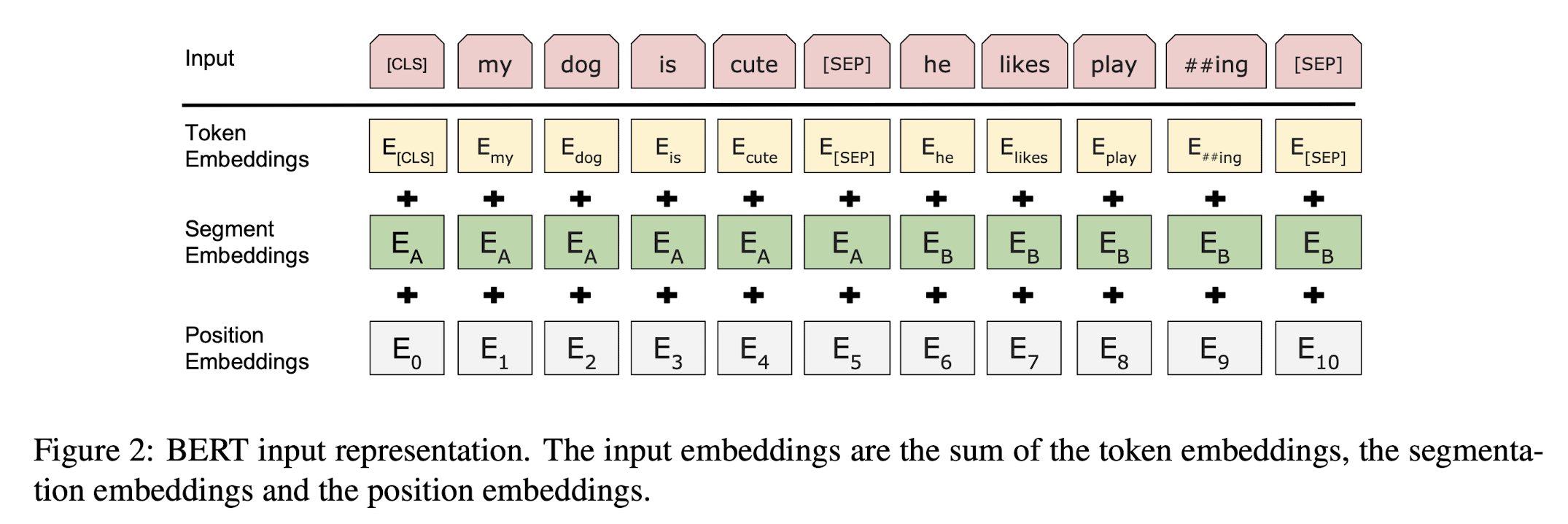
- 그림2처럼 Input represnetation은 상응하는 토큰과 segment와 position 임베딩을 합해서 구한다.
Pre-training BERT
기존 모델들과 다르게 2가지의 unsupervised task를 이용한다.
-
Masked LM
deep bidirectional representation을 위해 랜덤하게 몇몇 input 토큰들을 가리고 이를 예측한다. → “masked LM(MLM)”
[MASK] 토큰을 예측했던 pre-train과 달리 fine-tuning은 [MASK]토큰이 없다. 그래서 항상 masked 토큰을 실제 [MASK]토큰으로 대체하지 않는다.
논문에서는 전체 input token 포지션의 15%를 랜덤하게 고르고
이 중 80%만 [MASK]토큰으로 바꾼다.
나머지 10%는 랜덤한 토큰으로 바꾸고
나머지 10%는 바꾸지 않는다.
-> 이 부분을 MASK상의 DropOut이라고 혼자 이해했다...ㅎㅎ
cross-entropy loss로 원래 토큰과 비교한다.
-
Next Sentence Prediction (NSP)
많은 중요한 task들은 문장들간의 relationship의 이해를 기반으로 둔다.
그래서 BERT에서는 이를 두 문장이 연결되어있는지 아닌지를 예측한다.
실제로 문장B의 50%는 문장A 다음 나오는 문장들이고 → IsNext로 레이블링 된다.
나머지 50%는 랜덤한 문장이다. → NotNext로 레이블링 된다.
이는 QA나 NLI에서 특히 높은 성능을 보여준다.
Pre-training data
- BookCorpus ( 800M words)
- English Wikipedia (2,500M words)
Fine-tuning BERT
트랜스포머의 self-attention으로 인해 BERT가 많은 하위 task들에 적용할 수 있기 때문에 Fine-tuning이 간단하다.
간단하게 input과 output 데이터들을 BERT에 잘 맞추고 end-to-end로 모델을 fine-tune한다.
입력 데이터에서 pretraining에 사용한 문장 A - B 관계는 아래와 비슷하다.
- 패러프래이징 문장 쌍
- 가설 - 전제
- 질문 - 지문
- 생성 - 없음
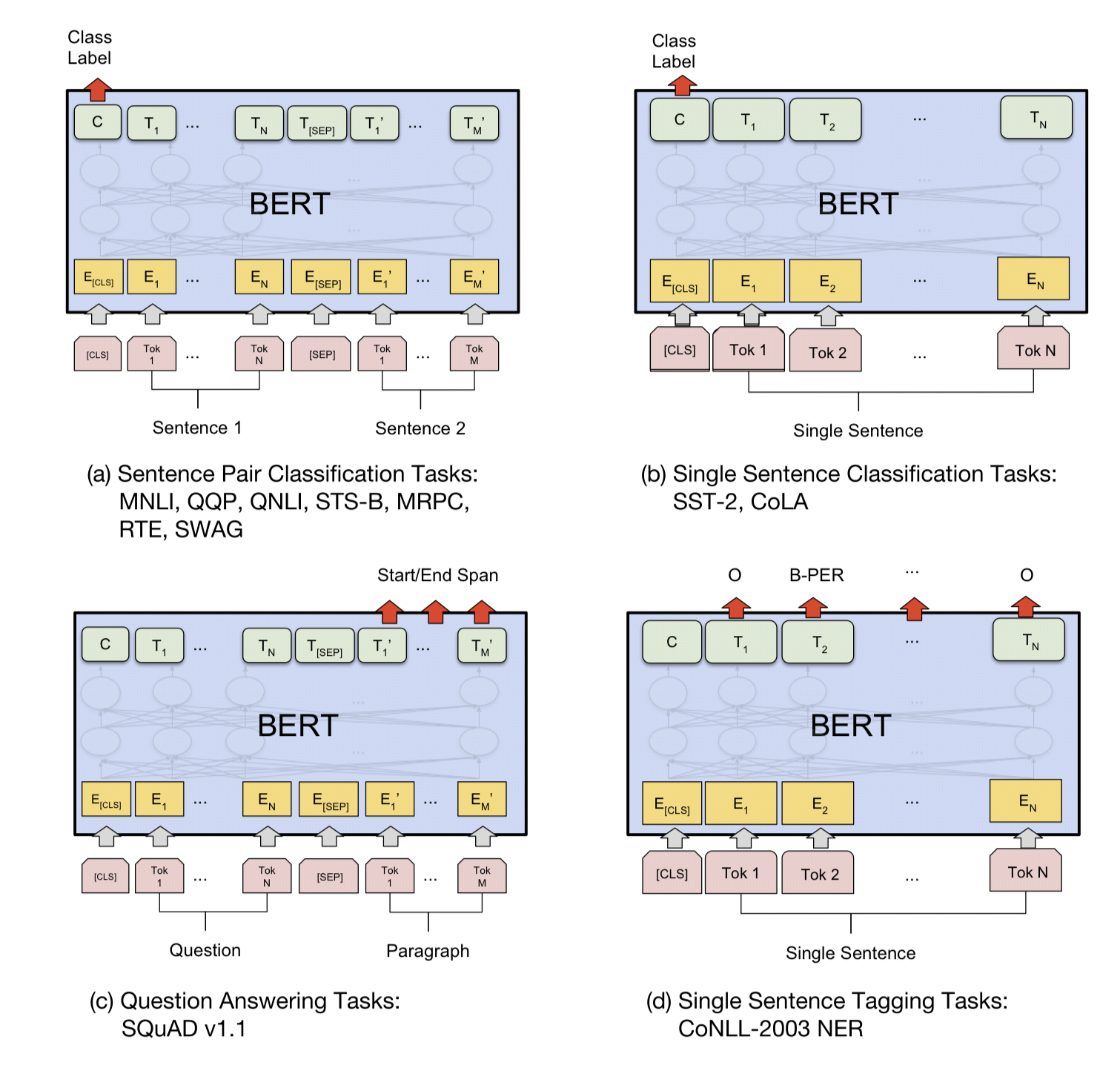
아웃풋에서는 token representation은 output layer에 시퀀스 tagging이나 QA처럼 토큰단위 task를 위해 제공된다. [CLS]는 분류문제일때 제공된다.
pre-training에 비해 fine-tuning은 덜 비싸다.
Experiments
논문에서는 BERT를 11개의 NLP task에 fine-tuning했다.
GLUE
GLUE
- The General language Understanding Evaluation benchmark
- 다양한 자연어 understanding task들의 모음
일반적인 분류 문제에서 C : 마지막 히든 벡터, W : 분류 레이어 가중치들
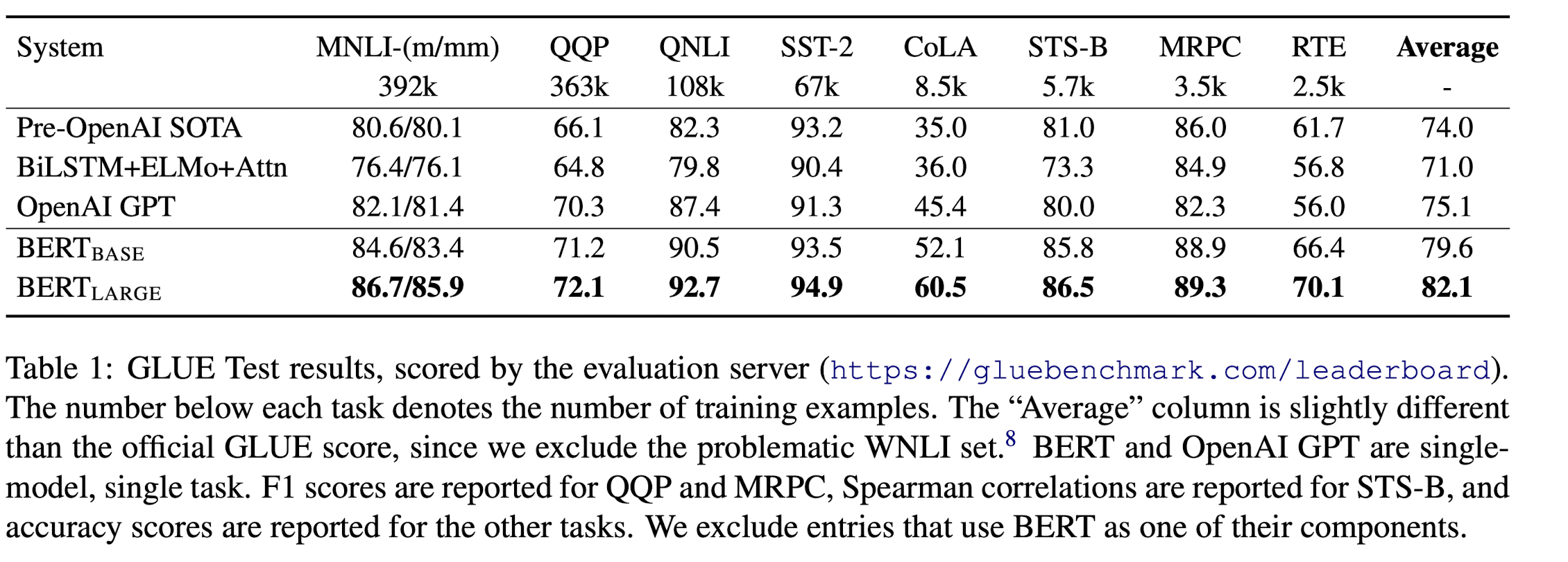
- 매우 적은 학습 데이터에서 BERT_LARGE가 BERT_BASE를 크게 능가한다.
SQuAD v1.1
Question Answering 쌍 100k개로 이뤄져있다.
GLUE와 달리 질문과 지문이 주어지고 정답을 맞추는 것이다.
질문 → A 임베딩, 지문 → B 임베딩
S : start 벡터, E : end 벡터를 나타내고
word i의 probability는 해당 토큰과 S의 dot product 연산 이후, softmax를 통해 구해진다.
Answer span의 끝부분에서도 유사한 공식이 사용된다.
후보 span의 스코어는 로 구한다.
에측할 때는 범위만 가능하다.
SQuAD v2.0
v1.1에 비해 더 현실적으로 answer가 짧지 않도록 변경하였다.
예측시 비교를 위해
no-answer span 스코어와 best non-null span을 비교한다.
→ ,
여기서 이면 non-null answer로 예측한다.
SWAG
SWAG - The Situations With Adversarial Generations dataset으로 113k 문장쌍으로 이루어져 있고
grounded common-sense inference를 평가하기 위해 사용한다. 4가지 선택 중 가장 그럴 듯한 하나를 고른다.
SWAG 데이터셋으로 fine-tuning할 때는,
input 문장들을 4개로 구성하고
주어진 문장의 concat → 문장 A,
가능한 연결 → 문장 B
task specific한 V를 학습시키고, [CLS]토큰을 표현한 C를 dot product, softmax 연산을 진행한다.
Ablation Studies
Effect of Pre-training Tasks
- No NSP : MLM을 이용한 bidirectional 모델, 그러나 NSP가 없다.
- LTR & No NSP : LTR(Left-to-Right) LM을 사용하고, NSP가 없다.
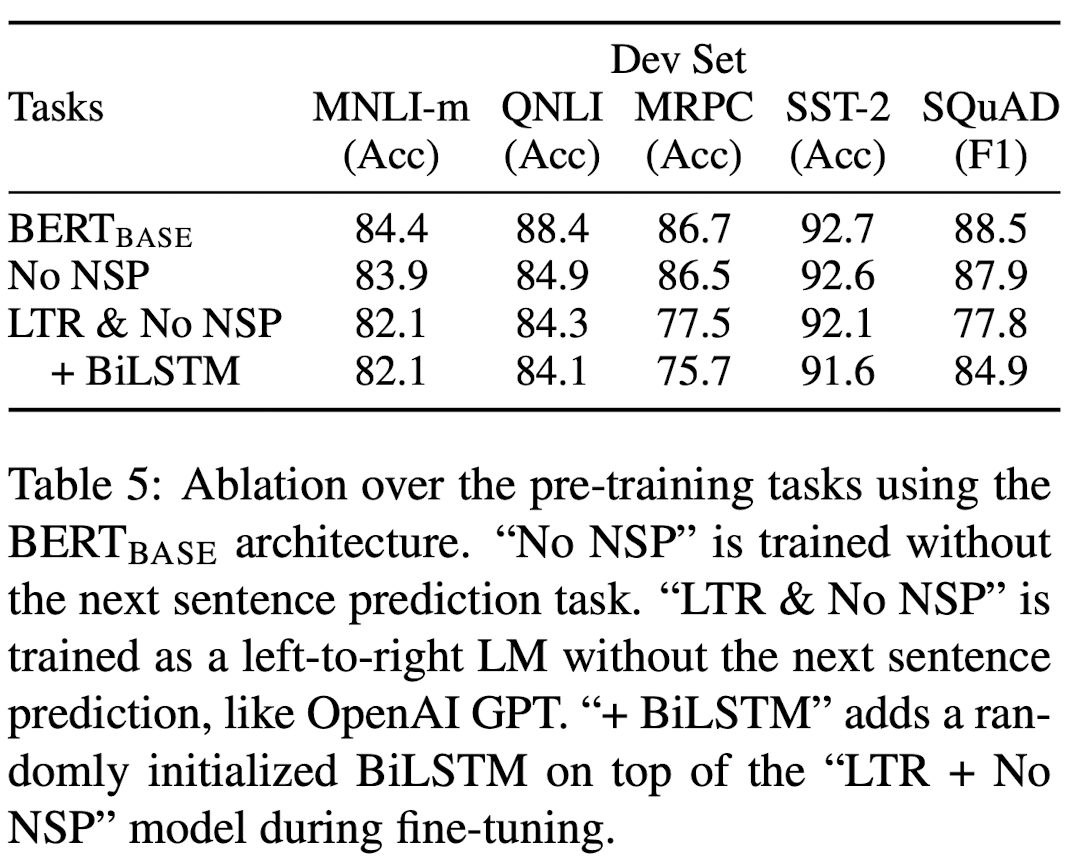
→ LTR보다는 MLM이 좋고, NSP없는 것보다 있는 것이 좋다.
추가로 LTR + RTL을 연결하여 표현하면 2배로 비용이 비싸지고, QA와 같은 task에서 직관적이지 않다. 그리고 덜 강력하다.
Effect of Model Size
BERT모델의 레이어 수, hidden units, attention heads를 다르게 하여 모델 사이즈를 조절하여 실험하였다.
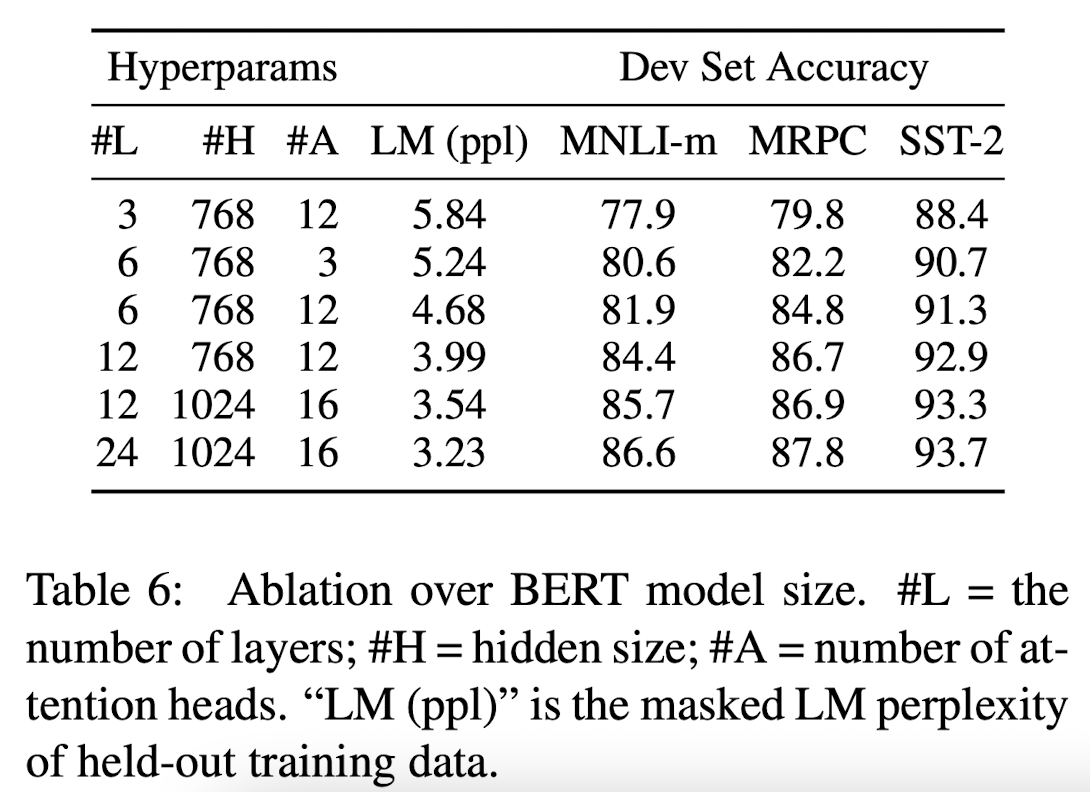
→ 모델이 커질수록 정확도도 증가하였다.
하위 task를 위한 dataset이 작아도 pre-training 을 해줬기 때문에 모델 크기가 클수록 정확도도 좋았다.
Feature-based Approach with BERT
BERT는 fine-tuning 방법이었지만 ELMo와 같이 feature-based 방법도 사용할 수 있다.
장점
- 트랜스포머 인코더는 모든 NLP task에 적용할 수 없기 때문에, network를 붙여 사용할 수 있다.
- 미리 학습 데이터에 대한 비싼 representation을 먼저 계산하고 더 저렴한 모델로 많은 실험을 진행할 수 있다는 부분에서 Computational 이점을 가질 수 있다.
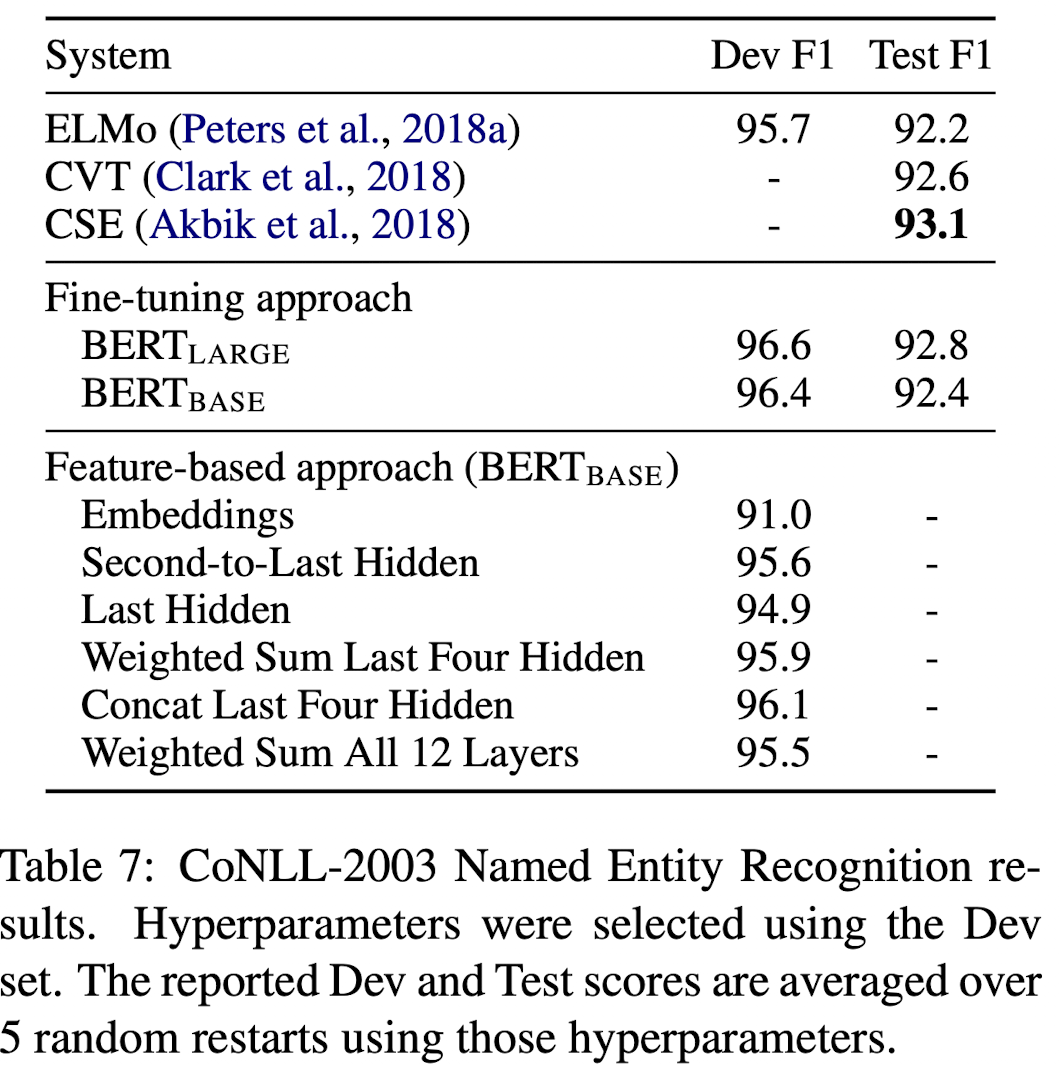
→ fine-tuning없이 activations를 추출하고 마지막 레이어에 Bi-LSTM을 붙여서 해당 레이어만 학습을 진행하여 비교하였다. 결과 Four Hidden이 높게 나왔다.
마무리
많은 task에서 높은 성능을 보여줘서 매우 놀랐다. 내가 느끼기로는 주로 내용의 이해가 필요한 부분 위주로 잘 된다고 생각하고 문장 생성이나 다른 NLP task에서의 성능은 잘 모르겠다...
엄청 복잡한 것보다 간단한 아이디어로 성능이 높이는 것이 더욱 의미있고 가치있는 아이디어라고 생각하는데, BERT가 MLM과 NSP로 NLP에 많은 의미를 가져온 것 같다.
