SVM 전반적인 설명
svm : support Vector Machine
- 고차원 데이터의 분류문제에 좋은 성능
- 트레이드오프(generalization ability, training data) 관계에서 generalization ability 증가시키는 방향
- Statistical learning theory에 근거
SVM 상황
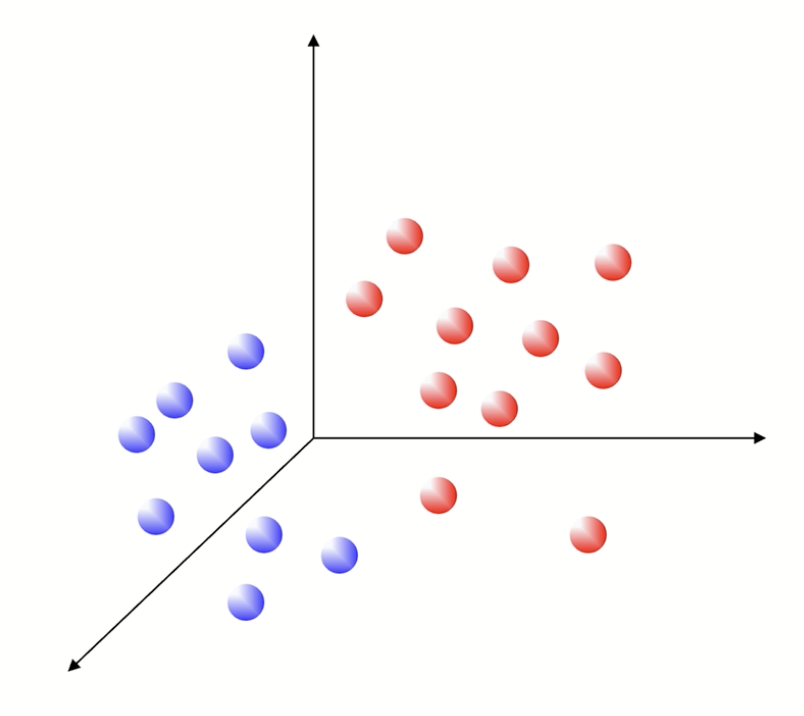
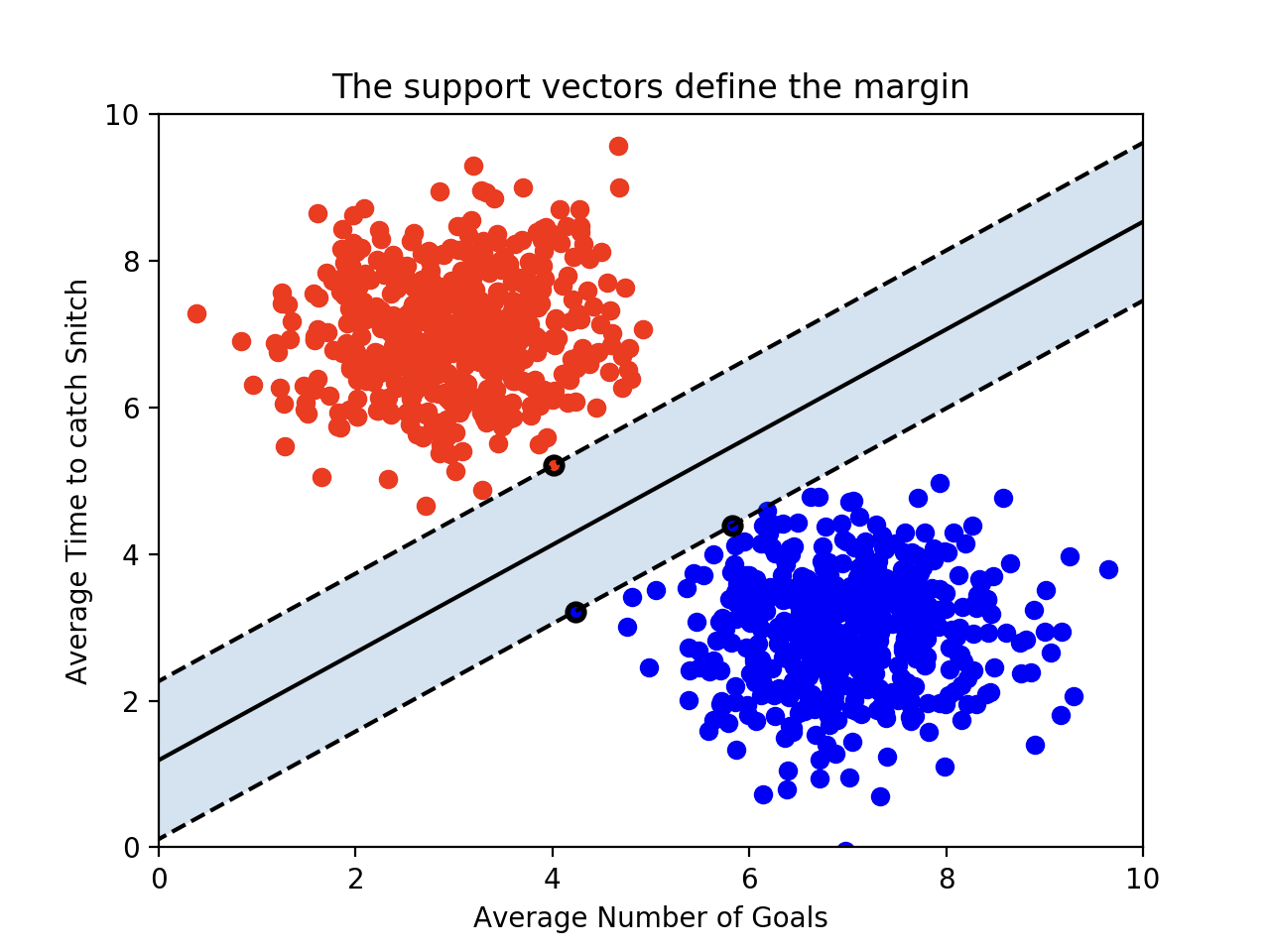
-> 이진분류문제의 예시이다.
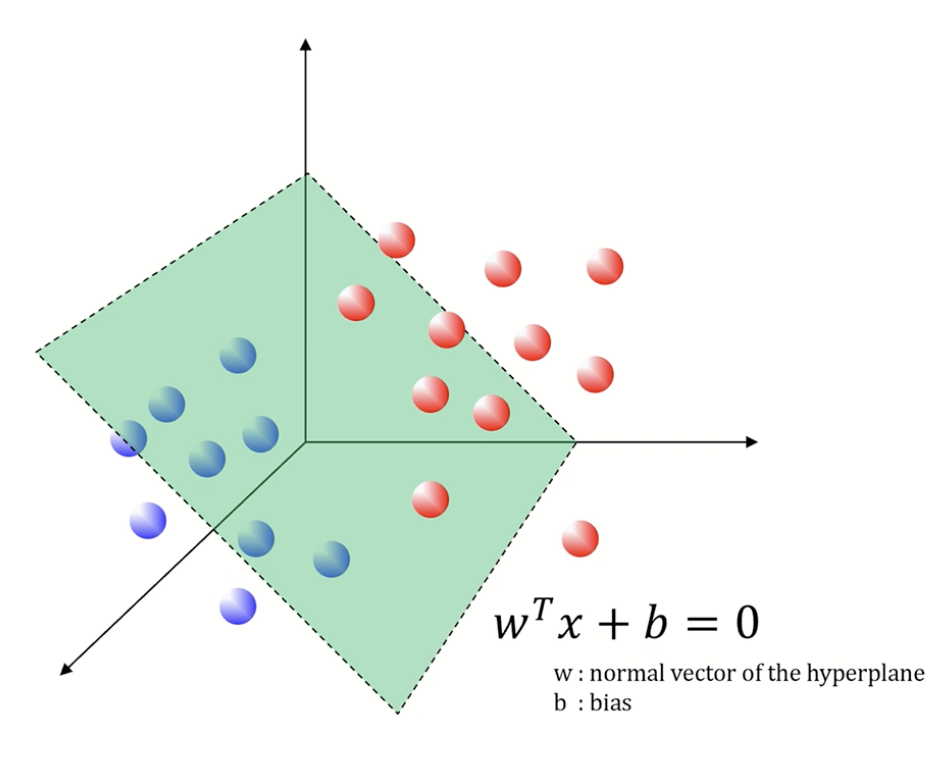
이처럼 hyper plane, decision boundary를 찾는 것이 목표이다!
그런데 이렇게 클래스를 구별할 수 있는 경계들이 너무 많다...
그러면 기준을 세워볼까...?
svm 기준 | Margin
바로 Margin!
마진을 최대화할 수 있는 hyperplane을 찾자
→ generalization error를 최소화
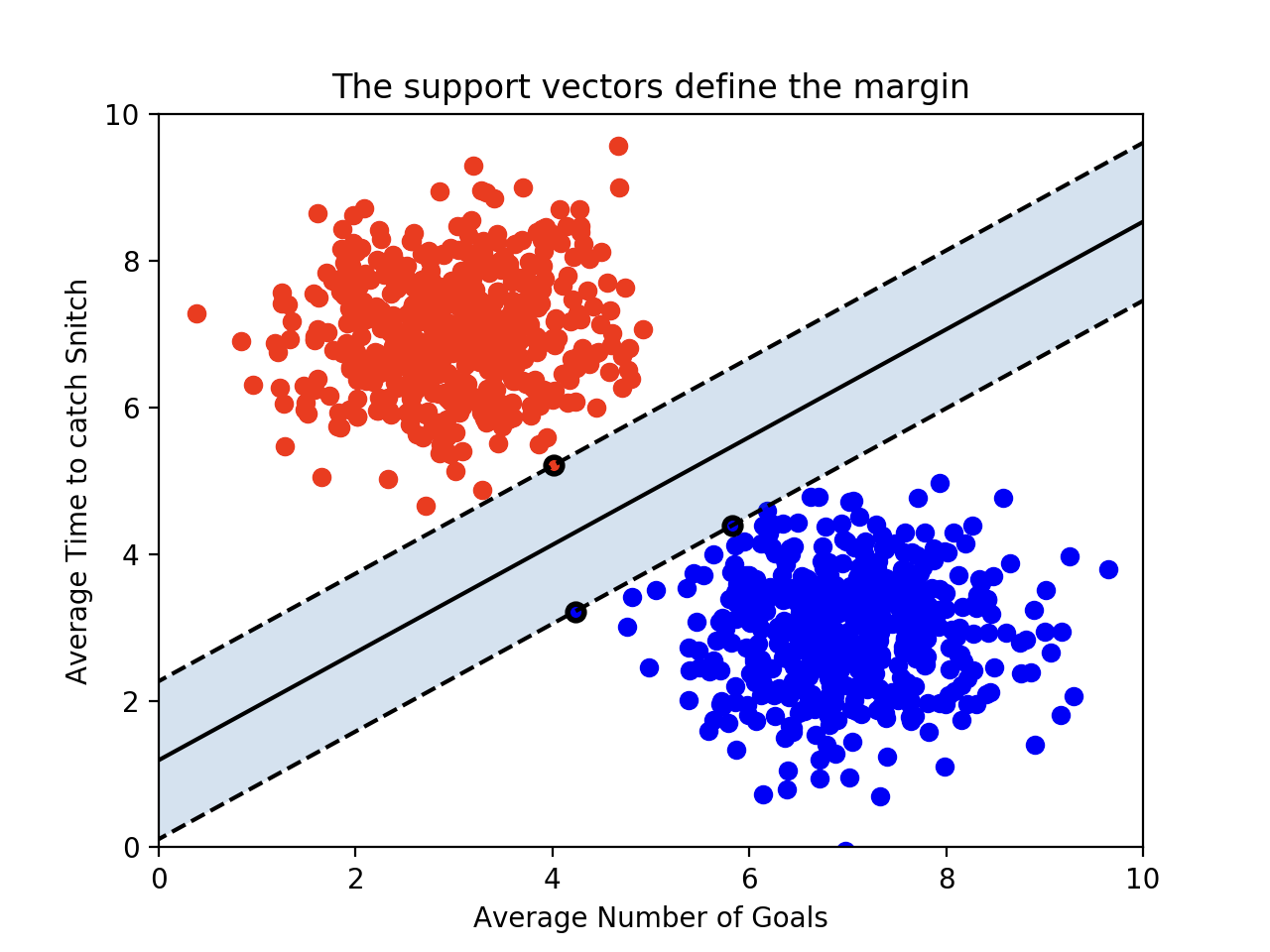
Margin : 각 클래스에서 가장 가까운 관측치 사이의 거리
W로 표현 가능 ( Wx + b )
1) Plus-plane
빨간색 클래스가 y=1
WTXi+b≥1
2) Minus-plane
파란색 클래스가 y=-1
WTXi+b≤−1
이 2개 사이의 거리가 Margin이고 이 마진을 최대화하는 hyperplane을 찾자
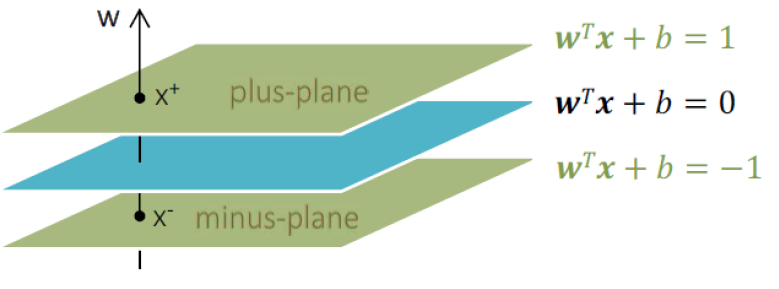
최적의 decision boundary
=> WTXi+b=0
그리고 이 둘(+/- plane)의 관계는
x+=x−+λw
즉, 평행이동관계
수학적으로 보는 Margin
λ 구하기
wTx++b=1
⇒ wT(x−+λw)+b=1
⇒ wTx−+b+λwTw=1
여기서 wTx−+b = -1
⇒ −1+λwTw=1
λ=wTw2
⚠️잊지말자 우리는 W에 주목!⚠️
Margin 구하기
Margin
=distance(x+,x−)
=∣∣x+−x−∣∣2
=∣∣x−+λw−x−∣∣2
=∣∣λw∣∣2
=λwTw
=wTw2
=∣∣w∣∣22
결론!
max margin = max ∣∣w∣∣22 ⇒ min 2∣∣w∣∣2
목적식 : minimize2∣∣w∣∣22
제약식 : yi(wTxi+b)≥1,i=1,2,3,...,n
Lagrangian multiplier를 이용하여 Lagrangian Primal
maxaminw,bL(w,b,α)=21∣∣w∣∣22−∑i=1nαi(yi(wTxi+b)−1)
우선 min문제 해결 → 미분 = 0
- W에 대한 미분 ⇒ w=∑i=1nαiyixi
- b에 대한 미분 ⇒ ∑i=1nαiyi=0
21∣∣w∣∣22=21∑i=1nαiyi(∑i=1nαiyixiTxi)=21∑i=1n∑j=1nαiαjyiyjxiTxj
∑i=1nαi(yi(wTxi+b)−1)=∑i=1nαiyi(wTxi+b)+∑i=1nαi=−∑i=1n∑j=1nαiαjyiyjxiTxj+∑i=1nαi
* 이제 α만 구하면 W, b 알 수 있다
이제 max문제를 해결한다. | Lagrangian dual solution
∑i=1nαi−21∑i=1n∑j=1nαiαjyiyjxiTxj
이 문제를 풀기 위해서는 KKT conditions을 만족해야 한다.

4번을 이용해서 구해본다.
1) αi>0 일 때, 뒤에가 0
⇒ +/- plane위에 위치, 이를 support vector 라고 부른다.
2) αi=0 일 때, 뒤에가 0일 필요 없다.
W, b 구하기
목표였던 W를 구하자면
support vector일 때만 αi∗≥ 0 이니까
support vector만 가지고 decision boundary 구할 수 있다.
b는 support vector 값 하나 (xsv,ysv) 를 넣어봐서 구할 수 있다.
지금까지 살펴본 linearly한 SVM을 HardMargin이라고 한다.
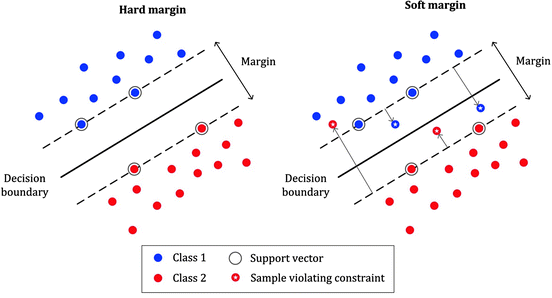
Non-linear SVM
soft margin이란
직선으로는 분류하기 힘들다
→ 약간의 error를 허용하자!
목적식 : minimize2∣∣w∣∣22+C∑i=1nξi
(ξ : 허용하는 error)
Hard margin과 비교해보면 뒤에 정규화 식이 붙었다.
trade-off | C
허용하는 error vs margin
C : trade-off를 결정하는 parameter
C가 높을 수록, error 많이 허용하지 않는다. ( 하드마진에 가까워진다. )
C가 작을 수록 error 많이 허용한다. ( 소프트마진에 가까워진다. )
Kernel
SVM에서 선형으로 분리할 수 없는 점들을 분류하기 위해 사용한다.
f(x)=∑i∈SVαi∗yiK+b
- Linear Kernel
- K<x1,x2>=<x1,x2>
- Polynomial Kernel
- K<x1,x2>=(a<x1,x2>+b)d
- Sigmoid Kernel
- K<x1,x2>=tanh(a<x1,x2>+b)
- Gaussian Kernel (rbf kernel)
- K<x1,x2>=exp(2σ2∣∣x1−x2∣∣22)
출처 : [핵심 머신러닝] SVM 모델 유튜브 강의