Math
1.벡터, L1 L2 norm

숫자의 배열(리스트)n차원 공간에서의 한 점원점으로부터 상대적 위치종류 1) 열벡터 - 세로로 긴 형태 2) 행벡터 - 자로로 긴 형태 스칼라곱 - $\\alpha X$ 주어진 벡터 길이 변환 $\\alpha X = \\begin{bmatrix} \\alpha
2.행렬, 역행렬, 경사하강법
벡터를 원소로 가지는 2차원 배열코드(넘파이) 에서는 행벡터 기준으로 한다.$X = \\begin{bmatrix} x{11} & x{12} & \\cdots & x{1m} \\ x{21} & x{22} & \\cdots & x{2m} \\ \\vdots & \\vdot
3.소프트맥스, 활성함수, 역전파
모델의 출력을 확률로 해석할 수 있게 변환해주는 연산이다.$softmax(o) = (\\frac{exp(o1)}{\\sum{k=1}^{p}exp(ok)},\\cdots,\\frac{exp(o_p)}{\\sum{k=1}^{p}exp(o_k)})$$\\mathbb{R}^p
4.확률론 Basic
확률론 기본개념 회귀에서는 L2 norm으로 예측오차의 분산을 가장 최소화하는 방향으로 학습한다. 분류에서는 교차 엔트로피로 모델예측의 불확실성을 최소화하는 방향으로 학습한다. 확률변수 종류 확률분포 $$D$$에 따라 1) 이산확률변수 확률변수가 가질 수 있
5.통계학 Basic
우선 통계적 모델링 은 적절한 가정 위에서 확률분포를 추정하는 것이다. 유한한 개수의 데이터만 관찰하기 때문에 근사적으로 확률분포를 추정한다.모수는 확률분포의 특성들이다.모수적 방법론 : 데이터가 특정 확률분포를 따른다고 선험적으로 가정한 후, 그 분포를 결정하는 모수
6.베이즈 통계학
먼저 조건부 확률부터 살펴보면$P(A\\cap B) = P(B)P(A|B)$베이즈 정리는 조건부확률을 이용하여 정보를 갱신하는 방법을 알려준다.사전확률 - 데이터 분석 전, 모수나 가설 등 사전에 설정하는 확률분포Evidence - 데이터 자체의 분포사전확률을 베이즈
7.CNN Basic
신호(signal)를 커널을 이용해 국소적으로 증표 또는 감소시켜서 정보를 추출, 필터링하는 것CNN에서 사용하는 연산은 계속 convolution이라고 불러왔지만 정확히는 cross-correlation이다. \*\*\* 위치(i,j)에 따라 커널이 바뀌지 않는다.1
8.RNN Basic
먼저 시퀀스 데이터란 소리, 문자열, 주가 등의 데이터처럼 나열된 데이터를 말한다.이벤트의 순서가 중요하다는 특징이 있다.독립동등분포가정을 잘 위배하기 때문에 순서를 바꾸거나 과거정보에 손실이 발생하면 데이터의 확률분포도 바뀐다.조건부 확률을 이용해 앞으로 발생할 데이
9.SVM 복잡한 수식 쉽게 이해하기!
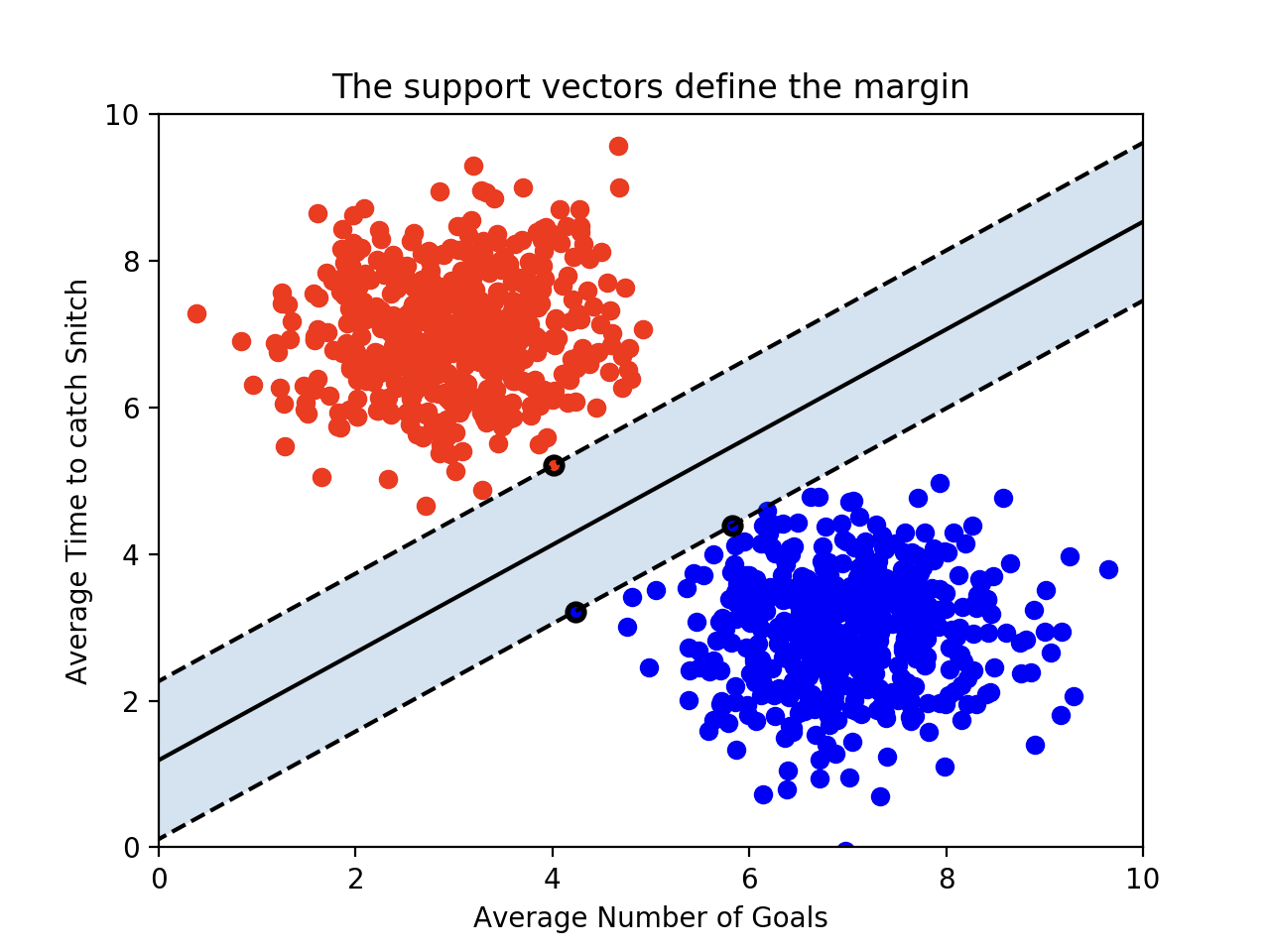
svm : support Vector Machine고차원 데이터의 분류문제에 좋은 성능트레이드오프(generalization ability, training data) 관계에서 generalization ability 증가시키는 방향Statistical learning