NLP 분야 중, 기계번역에서는 Encoder-Decoder 방식의 번역 알고리즘이 대부분 사용되었습니다. 이는 입력값을 encoder로 고정된 일정 크기의 context vector로 압축 시키고, decoder를 통해 원하는 출력 값을 산출하는 방식이였습니다. 하지만 이런 접근은 (1) 고정된 크기의 context vector로 인해 bottleneck 현상을 발생시켜 번역 품질 악화 유래, (2) RNN의 문제 vanishing gradient(기울기 소실) 문제를 일으켰습니다. 여기서 제안된 것이 Attention을 활용한 기계번역입니다.
Attention의 메카니즘은 Neural Machine Translation by Jointly Learning to Align and Translate 논문에서 처음 소개 되었습니다.
기계번역에서의 어텐션 구조
기존 인코더-디코더 아키텍처에서의 기계번역은 encoder의 마지막 hidden state만을 활용해서 고정된 사이즈의 context vector를 생성했습니다.
하지만, 어텐션을 활용한 아키텍쳐에서는 인코더의 모든 RNN셀의 hidden state를 활용하는 것입니다. 즉, 각각의 hidden state를 디코더에서 활용해서 dynamic한 context vector를 사용하여 번역을 하는 것이 핵심입니다.
이렇게 하면
- 고정된 사이즈의 컨텍스트 벡터 문제를 해결할 수 있습니다.
- 입력문장에서
Attention(포커스)해야될 단어에 대한 메카니즘을 설정할 수 있습니다.

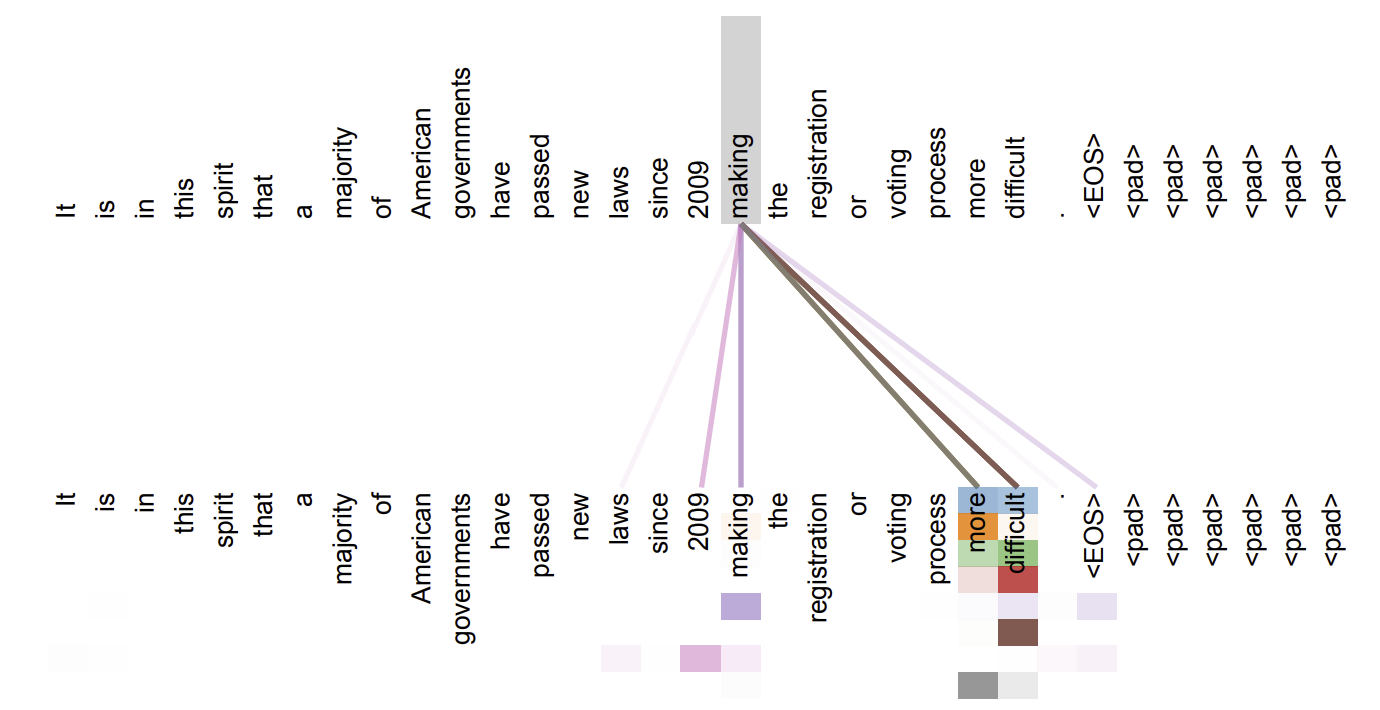
위의 예제는 전통 인코더-디코더의 예시입니다. 컨텍스트 벡터를 위해 우리는 마지막 RNN셀의 hidden state 만을 사용했습니다.
위의 예제는 어텐션을 활용한 예시입니다.
Fully Connected Network (FC)에 모든 RNN cell의 hidden state 를 활용하고, 디코더로부터의 출력값이 없기 때문에 를 다시 활용해서, scores 을 생성해줍니다.
그리고 Softmax를 취해주면 확률분포를 얻게 됩니다. 이 확률을 Attention Weight 라고 합니다. 이 값은, 각 단어가 얼마만큼 ATTENTION (Focus) 될 것인지 나타냅니다. 즉, I 단어에 90%, you에 10% 포커스 한다는 말입니다.
Attention wieght값을 활용해서 첫번째 context vector cv1을 만듭니다. 첫번째 context vector는 I에 90퍼 포커스 한 값, you에 10퍼 포커스 한 값입니다.
디코더 파트의 첫번째 RNN셀에 cv1과 첫번째 디코더의 입력 시퀀스 값을 넣어줍니다. 현재까지 번역된 값이 없기 때문에 문장의 시작을 의미하는 스페셜 토큰 START가 입력값이 됩니다. 그러면 첫번째 output Nan을 얻습니다. 이것이 첫번째 스텝입니다.
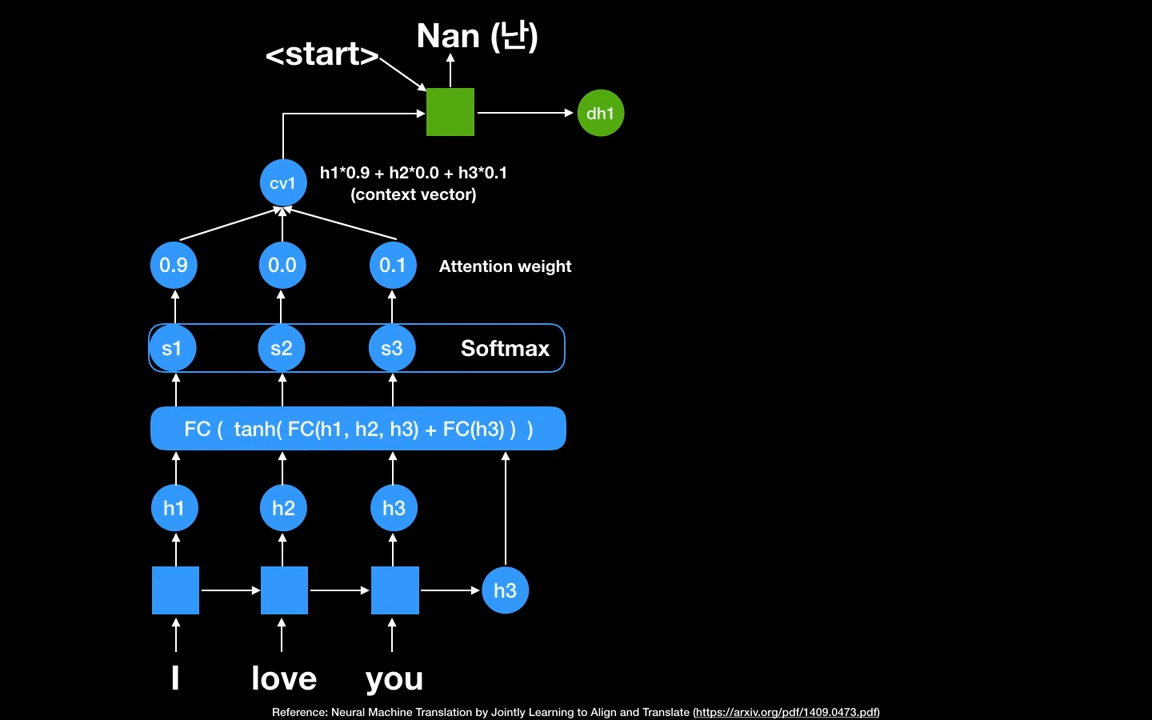
두번째 스텝입니다. 디코더의 첫번째 hidden state 가 Fully connected Network의 입력값으로 사용됩니다. 중요한것은 가 항상 사용된다는 점입니다. 왜냐면 이 값들은 어떤값을 중요하게 포커스 할것인지를 계산하기 위해서입니다. 이것을 활용해서 를 다시 생성합니다.
Softmax 취해서 새로운 확률분포를 얻습니다. 문맥 중요도가 이제는 I에 10퍼센트 포커스, you에 90퍼센트 포커스로 변경되었습니다.
Attention wieght값을 활용해서, 두번째 context vector cv2를 생성합니다.
디코더 파트의 두번째 RNN셀에 cv2와 첫번째 스텝의 output값을 활용해서 두번째 output nul을 얻습니다.
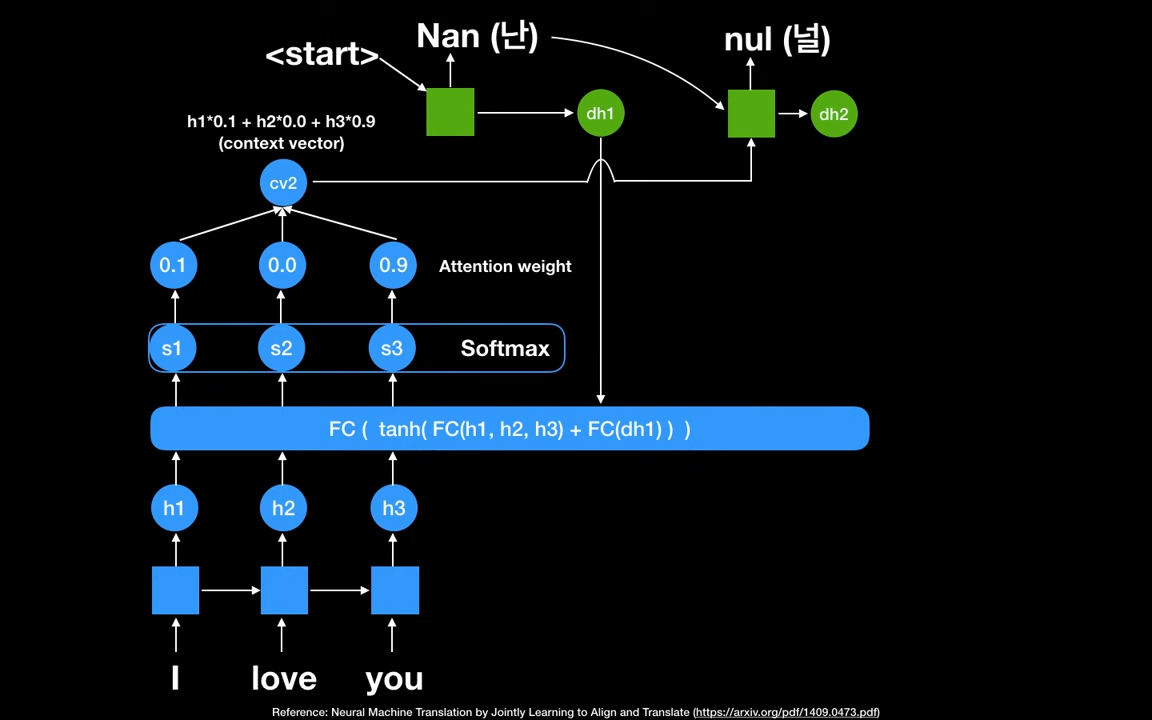
세번째 스텝입니다. 디코더의 두번째 hidden state 가 Fully connected Network의 입력값으로 사용됩니다. 새로 Attention weight를 얻어, 세번째 context vector cv3을 생성합니다.
디코더 파트의 세번쨰 RNN셀에 cv3와 두번째 스텝의 output값을 활용해서 세번째 output saranghey를 얻습니다.
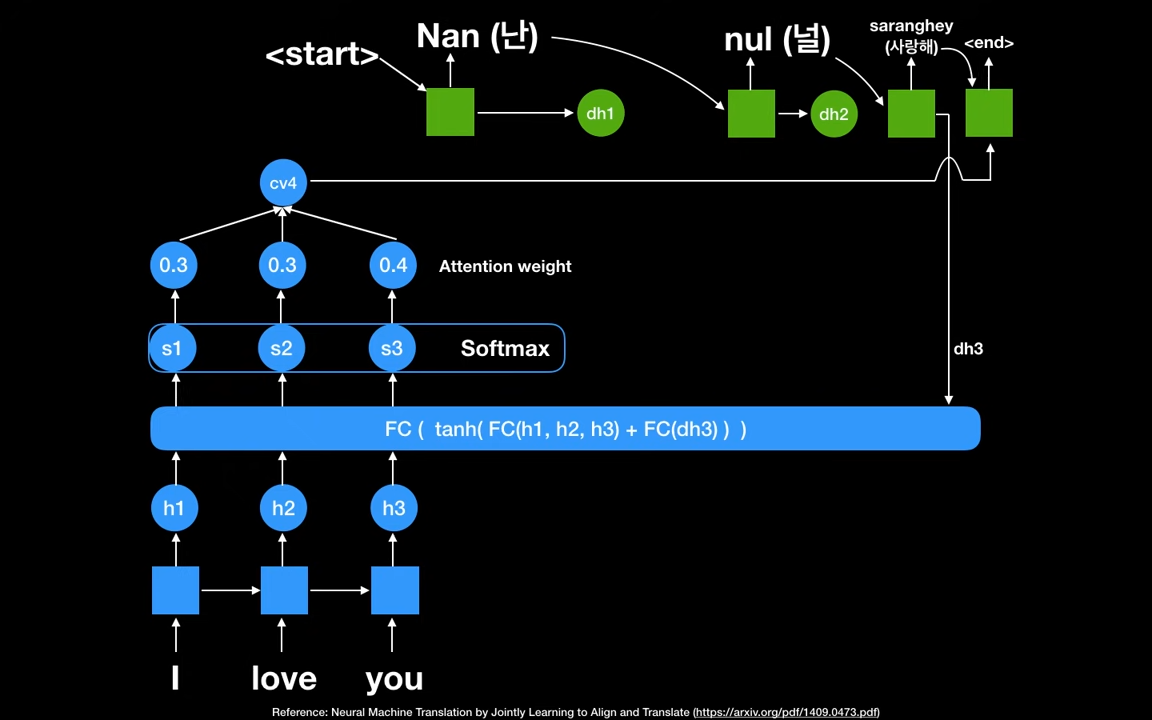
end가 나올때까지 반복합니다.
여기서 중요한 것은 Attention Weight 입니다. 이 값을 사용해서 어디를 포커스해서 문맥을 볼 것인지 모델링할 수 있게 합니다.
또한, context vector가 각 시점 별로 디코더를 지날때마다 달라진다는 점입니다.
위의 예시를 통해 간략하게 Attention의 아키텍처를 살펴보았습니다. 실제로 연산은 어떻게 진행할까요??
Attention Score
위의 예시에서는 Fully Connected Network를 사용해서 scores 를 계산했습니다.
Attention Score 는 디코더의 시점 에서 번역 단어를 예측하기 위해, 인코더의 모든 hidden state 들이 디코더의 hidden state 와 얼마나 유사한지를 판단하는 스코어값입니다.
dot-production 어텐션 메카니즘에서는 와 인코더의 i번째 hidden state의 Attention score 계산방법은 dot-production 계산을 통해 이뤄집니다.
와 인코더의 모든 hidden state의 attention scores 모음값을 라고 정의할때, 로 나타낼 수 있습니다.
Softmax로 확률분포 계산
에 softmax를 적용해서 확률분포를 얻습니다. 이것을 Attention Distribution이라고 하며, 각각의 값을 Attention Weight라고 합니다.
디코더의 시점 에서 Attention weights의 모음값인 분포를 라고 할때, 로 나타낼 수 있습니다.
Attention Value(Context Vector) 얻기
어텐션의 최종값을 얻기 위해 각 인코더의 hidden state와 attention weight를 곱하고 더합니다. 이것은 위의 예의 cv1, cv2, cv3와 동일합니다.
= cvN
Attention value와 디코더의 hidden state 연결
어텐션 값 를 구하면 디코더의 와 결합해서 하나의 벡터로 만드는 작업을 수행합니다. 이를 라고 합니다. 이 를 예측 연산의 입력으로 사용해서 인코더로부터 얻은 정보를 활용해서 예측을 좀 더 잘 할 수 있게 됩니다.
Reference
