이번 포스팅에서는 Sequence to Sequence 네트워크를 활용해서 프랑스어<->영어로 번역하는 번역기를 만들어보겠습니다.
해당 내용은 PyTorch를 참조해서 만들었습니다.
Recab
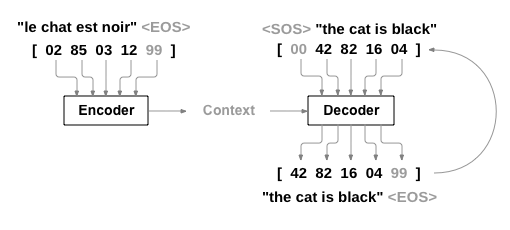
시작 전, Seq2Seq 구조를 다시 한번 살펴보겠습니다.
이전 포스팅에서 설명드린 것과 같이 Encoder는 input sequence를 순차적으로 입력 받아 input 내용을 포함하는 Context를 만들어 Decoder에 전달합니다. Decoder는 Encoder에서 전달받은 Context와 Decoder의 input sequence를 입력받아 가능성이 높은 token/단어를 출력 및 예측하는 구조입니다.
소스를 통해 구현해보도록 합시다. 우선 라이브러리들을 import 합니다.
library import
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import re
import random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import numpy as np
from torch.utils.data import TensorDataset, DataLoader, RandomSampler
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")Data Processing
모델을 훈련하기 위해서는 데이터가 필요합니다. 우리는 번역기를 만들 것이기 때문에, 영어와 프랑스어 데이터를 사용합니다. 이번 포스팅에서는 [영어-프랑스어]로 매칭되어 있는 데이터를 사용할 것입니다. 데이터는 manythings에서 다운 및 확인 가능합니다.
Download Data
다음 명령어를 통해 데이터를 다운받아 줍니다.
# download data
!wget http://www.manythings.org/anki/fra-eng.zip
!unzip fra-eng.zip데이터를 다운받게 되면 다음과 같은 포맷 형식의 데이터를 확인할 수 있습니다. 우리는 여기서 필요한 데이터는 오직 첫 두문장 영어와 프랑스어 부분입니다 (나머지는 필요하지 않음).
# fra-eng.txt
Go. Va ! CC-BY 2.0 (France) Attribution: tatoeba.org #2877272 (CM) & #1158250 (Wittydev)
Go. Marche. CC-BY 2.0 (France) Attribution: tatoeba.org #2877272 (CM) & #8090732 (Micsmithel)
...Data Preprocessing Function
기존 original 데이터 파일은 불필요한 데이터들을 가지고 있습니다. 유니코드들을 ascii코드로 변환하고(unicodeToAscii), 모든 문자를 소문자 처리, punctuation 제거 등을 하는 데이터를 전처리하는 메소드를 만들어줍니다.
def unicodeToAscii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
# 단어와 구두점 사이 공백 추가 (e.g.,) "I am a student." => "I am a student ."
s = re.sub(r"([?.!,¿])", r" \1", s)
# (a-z, A-Z, ".", "?", "!", ",") 이들을 제외하고는 전부 blank로 변환.
s = re.sub(r"[^a-zA-Z!.?]+", r" ", s)
return s.strip()Vocabulary Creation
훈련 전 우리는 단어들을 numeric vector로 변형시켜주어야 합니다. 각 문장에서 각 단어들은 one-hot vector으로 표현합니다. 예를 들어, SOS는 00, EOS는 01, the는 02로 표현됩니다.

이렇게 표현하기 위해서는, 단어당 고유한 인덱스를 부여해주어야 합니다. 이 모든 것을 처리하기 위해 Lang 클래스를 사용합니다. Lang 클래스는 다음과 같은 features를 가지고 있습니다.
- word2index: word를 index로 표현한 딕셔너리 (e.g., {'SOS': 1, 'EOS': 2, 'the': 3})
- index2word: index를 word로 표현한 딕셔너리 (e.g., {1: 'SOS', 2: 'EOS', 3: 'the'})
- word2count: words의 개수SOS_token = 0 #문장의 시작을 의미하는 스페셜 token
EOS_token = 1 #문장의 끝을 의미하는 스페셜 token
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {} # word to index
self.word2count = {} # word count
self.index2word = {0: "SOS", 1: "EOS"} # index to word
self.n_words = 2 # 단어 수, 지금은 sos, eos를 추가했으므로 2개임
def addSentence(self, sentence):
# 문장별로 확인
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
# 단어집합에 추가
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1Load the Data
데이터 파일을 읽기 위해 파일을 라인으로 분할 후, 다시 라인을 쌍으로 분할합니다.
def readLangs(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = [], [], []
print("Reading lines.....")
# read the file and split into lines
with open("fra.txt", "r") as lines:
for i, line in enumerate(lines):
# split every line into pairs and normalize
input_line, output_line, _ = line.strip().split('\t')
pairs.append([normalizeString(input_line), normalizeString(output_line)])
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs 예문이 많고 빠르게 학습하고 싶기 때문에 데이터 세트를 상대적으로 짧고 간단한 문장으로만 정리하겠습니다. 여기서 최대 길이는 10단어(끝 구두점 포함)이며 "I am" 또는 "He is" 등의 형식으로 번역되는 문장으로 필터링합니다(아포스트로피는 이전에 대체됨).
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH and p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]Full Process for Data
데이터를 준비하는 전체 과정은 다음과 같습니다.
- 데이터 파일을 읽어 lines으로 분리 후, 각 lines들을 다시 pairs로 분리합니다.
- 텍스트 정규화, 길이 및 내용별로 필터링 셋팅해줍니다.
- pair로 된 문장에서 vocabulary list를 만들어줍니다.
def prepareData(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print(f"Read {len(pairs)} sentence pairs")
pairs = filterPairs(pairs)
print(f"Trimmed to {len(pairs)} sentence pairs")
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words: ")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, ouput_lang, pairs = prepareData("eng", "fra", True)
print(random.choice(pairs))# output:
Reading lines.....
Read 227815 sentence pairs
Trimmed to 16340 sentence pairs
Counting words...
Counted words:
fra 5404
eng 3497
['je prends du poids .', 'i m gaining weight .']Seq2Seq 모델 셋팅
Encoder와 Decoder라고 하는 두개의 RNN으로 구성된 모델을 만들어줍니다. Encoder는 input sequence를 읽어 context vector를 출력하고, Decoder는 해당 vector를 읽어 output sequence를 생성합니다.
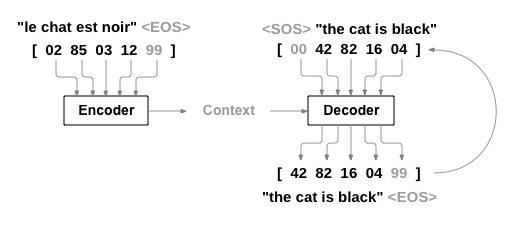
문장 "Je ne suis pas le chat noir"는 영어로 "I am not the black cat"입니다. 대부분의 입력문장의 단어는 출력문장에서 직접 번역되지만, 순서가 약간 다릅니다(e.g., chat noir와 black cat은 동일한 순서에 있지만 ne와 pas같은 단어가 입력문장에 더 추가되어 있음)
Encoder 셋팅
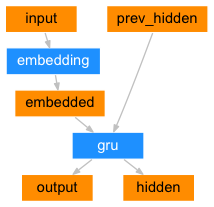
인코더는 모든 input 단어에 대해 vector와 hidden state를 출력하고, 다음 input word에 hidden state를 사용합니다.
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, dropout_p=0.1):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.dropout = nn.Dropout(dropout_p)
def forward(self, input):
embedded = self.dropout(self.embedding(input))
output, hidden = self.gru(embedded)
return output, hiddenDecoder 셋팅
여기서는 가장 간단한 디코더의 형식을 사용합니다 (인코더의 마지막 출력만 사용).
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)
decoder_hidden = encoder_hidden
decoder_outputs = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs.append(decoder_output)
if target_tensor is not None:
# Teacher forcing: Feed the target as the next input
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
return decoder_outputs, decoder_hidden, None # We return `None` for consistency in the training loop
def forward_step(self, input, hidden):
output = self.embedding(input)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.out(output)
return output, hiddenTraining
Preparing Training Data
훈련하기 위해 각 pair에 대해 input tensor(입력 문장에 있는 단어의 인덱스들)와 target tensor(타겟 문장에 있는 단어의 인덱스들)가 필요합니다. 이러한 벡터를 생성하는 동안 우리는 EOS 토큰을 두 시퀀스에 추가합니다.
# sentence로부터 index값 가져오기
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
# EOS 토큰 추가
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(1, -1)
# tensor값 리턴
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
# 데이터 로드
def get_dataloader(batch_size):
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
n = len(pairs)
input_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)
target_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)
for idx, (inp, tgt) in enumerate(pairs):
inp_ids = indexesFromSentence(input_lang, inp)
tgt_ids = indexesFromSentence(output_lang, tgt)
inp_ids.append(EOS_token)
tgt_ids.append(EOS_token)
input_ids[idx, :len(inp_ids)] = inp_ids
target_ids[idx, :len(tgt_ids)] = tgt_ids
train_data = TensorDataset(torch.LongTensor(input_ids).to(device),
torch.LongTensor(target_ids).to(device))
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
return input_lang, output_lang, train_dataloaderTraining model
인코더를 통해 입력문장을 훈련하기 위해, 모든 출력 문장과 마지막 hidden state를 관찰합니다. 그리고 디코더는 SOS 토큰을 제일 첫번째 input으로 받고, 인코더의 마지막 hidden state를 디코더의 첫번째 hidden state로 처리합니다.
이전 포스팅에서 설명드렸다 싶이, 훈련을 위해서 우리는 Teacher Forcing 컨셉을 사용합니다 (예측된 타겟 출력을 input으로 사용하지 않고, 실제 타겟 출력을 다음 input으로 사용함)
def train_epoch(dataloader, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion):
total_loss = 0
for data in dataloader:
input_tensor, target_tensor = data
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
encoder_outputs, encoder_hidden = encoder(input_tensor)
decoder_outputs, _, _ = decoder(encoder_outputs, encoder_hidden, target_tensor)
loss = criterion(
decoder_outputs.view(-1, decoder_outputs.size(-1)),
target_tensor.view(-1)
)
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)그밖에 소요시간 계산, plot등을 위한 함수를 만들어줍니다.
import time
import math
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker
import numpy as np
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# this locator puts ticks at regular intervals
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points) 전체 훈련 과정은 다음과 같습니다
- timer 시작
- optimizer와 creterion 초기화
- training pairs 세트 생성
- empty loss 배열 선언
def train(train_dataloader, encoder, decoder, n_epochs, learning_rate=0.001,
print_every=100, plot_every=100):
start = time.time() # timer 시작
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)
criterion = nn.NLLLoss()
for epoch in range(1, n_epochs + 1):
loss = train_epoch(train_dataloader, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if epoch % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, epoch / n_epochs),
epoch, epoch / n_epochs * 100, print_loss_avg))
if epoch % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)Reading lines.....
Read 227815 sentence pairs
Trimmed to 16340 sentence pairs
Counting words...
Counted words:
fra 5404
eng 3497
0m 28s (- 7m 13s) (5 6%) 1.5306
0m 56s (- 6m 38s) (10 12%) 0.7936
1m 24s (- 6m 7s) (15 18%) 0.5095
1m 52s (- 5m 36s) (20 25%) 0.3519
2m 20s (- 5m 8s) (25 31%) 0.2561
2m 49s (- 4m 41s) (30 37%) 0.1951
3m 16s (- 4m 12s) (35 43%) 0.1549
3m 44s (- 3m 44s) (40 50%) 0.1270
4m 12s (- 3m 16s) (45 56%) 0.1070
4m 40s (- 2m 48s) (50 62%) 0.0928
5m 7s (- 2m 19s) (55 68%) 0.0826
5m 34s (- 1m 51s) (60 75%) 0.0750
6m 4s (- 1m 24s) (65 81%) 0.0692
6m 31s (- 0m 55s) (70 87%) 0.0647
6m 59s (- 0m 27s) (75 93%) 0.0608
7m 27s (- 0m 0s) (80 100%) 0.0581Evaluation
평가는 training과 대부분 동일하지만 목표가 없기 때문에(e.g., loss 줄이기), 각 단계마다 디코더의 예측을 자체적으로 피드백하기만 하면 됩니다. 단어를 예측할 때마다, 이를 출력 문자열에 추가하고 EOS 토큰을 예측하면 종료합니다.
def evaluate(encoder, decoder, sentence, input_lang, output_lang):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentence)
encoder_outputs, encoder_hidden = encoder(input_tensor)
decoder_outputs, decoder_hidden, _ = decoder(encoder_outputs, encoder_hidden)
_, topi = decoder_outputs.topk(1)
decoded_ids = topi.squeeze()
decoded_words = []
for idx in decoded_ids:
if idx.item() == EOS_token:
decoded_words.append('<EOS>')
break
decoded_words.append(output_lang.index2word[idx.item()])
return decoded_words, _def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs)
print('>', pair[0])
print('=', pair[1])
output_words, _ = evaluate(encoder, decoder, pair[0], input_lang, output_lang)
output_sentence = ' '.join(output_words)
print('<', output_sentence)
print('')dropout layers를 eval mode에 셋팅해줍니다.
encoder.eval()
decoder.eval()
evaluateRandomly(encoder, decoder)#output:
> je suis un garcon de la campagne .
= i m a country boy .
< i m a country boy . <EOS>
> vous etes douees pour ca .
= you re great at this .
< you re great very much time . <EOS>
> tu es prevenant .
= you re considerate .
< you re just young to be her daughter . <EOS>
> je deviens certainement fou .
= i m definitely going crazy .
< i m just going to get mad at . <EOS>
> ils sont tous ici .
= they re all here .
< they are all the time here . <EOS>
> j ai honte car j ai agi stupidement .
= i m ashamed because i acted foolishly .
< i m ashamed because i acted foolishly . <EOS>
> je suis aussi curieuse que vous .
= i m as curious as you are .
< i m as curious as you are . <EOS>
> c est desormais un homme .
= he s a man now .
< he s a man of very poor . <EOS>
> elles sont bleues .
= they re blue .
< they re not supposed to do that . <EOS>
> elles sont etonnees .
= they re surprised .
< they re about to have that decision . <EOS>이렇게 Seq2Seq를 사용해서 번역기를 생성해보았습니다. 현재에는 Attention Mechanism을 활용하여 성능을 훨씬 더 높였는데, 다음 포스팅에서는 Attention Mechanism을 다뤄보겠습니다.
Reference
