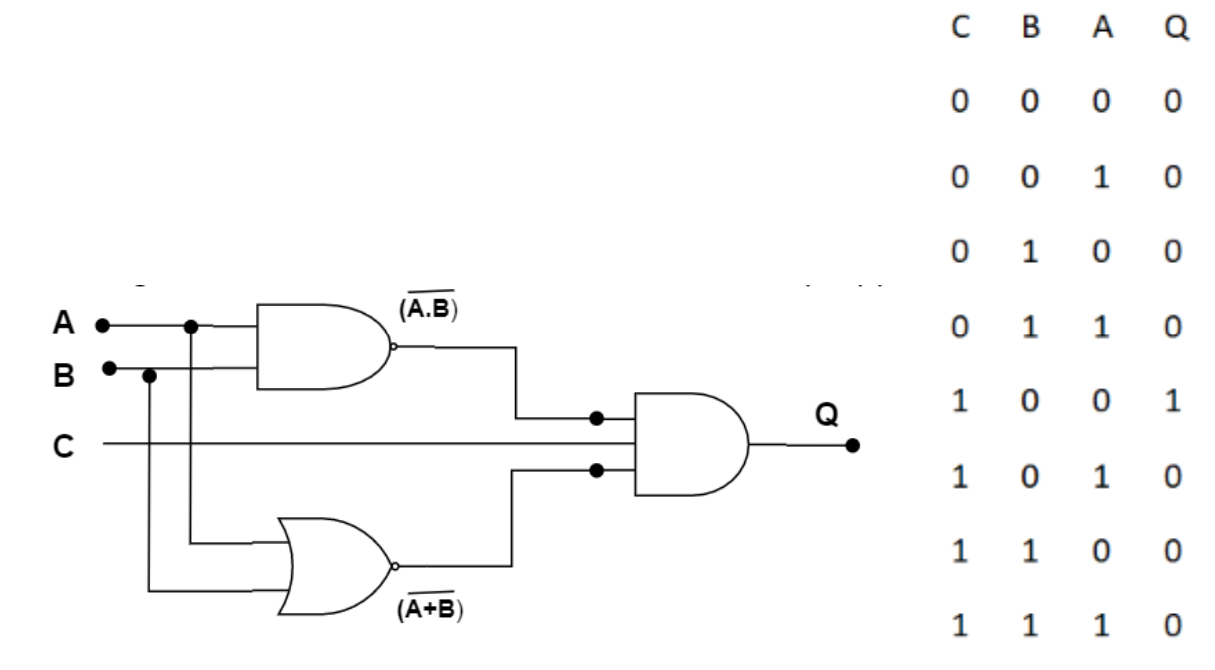
지난 포스팅에 이어, 여러개의 input을 받아 XOR 논리 연산 결과를 분류하는 Neural Networks을 훈련해보도록 하겠습니다. 진행과정은 거의 동일하며, 파라미터들만 조금 변형시키면 됩니다.
우선 라이브러리들을 다운받아줍니다.
!pip install pygad==2.17.0
import numpy
import pygad
import pygad.nn
import pygad.gannTraining Dataset 준비
# Preparing the NumPy array of the inputs; this is the input training data of the neural network
data_inputs = numpy.array([[0, 0, 0],
[0, 0, 1],
[0, 1, 0],
[0, 1, 1],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0],
[1, 1, 1]])
# Preparing the NumPy array of the outputs; this is the output training data of the neural network
data_outputs = numpy.array([0,
0,
0,
0,
1,
0,
0,
0])input의 수는 3개, 분류를 위한 레이블은 0 또는 1이므로 2개로 정의합니다.
num_inputs = data_inputs.shape[1] # this is the total number of combinations of the logic gate
num_classes = 2 # this is two since this is '0' and '1'.pygad.gann.GANN class의 인스턴스 생성
# the configuration/architecture of the neural network
GANN_instance = pygad.gann.GANN(num_solutions=num_solutions,
num_neurons_input=num_inputs,
num_neurons_hidden_layers=[2],
num_neurons_output=num_classes,
hidden_activations=["relu"],
output_activation="softmax")Population Weights를 벡터화
# the population of the GA is initialized
population_vectors = pygad.gann.population_as_vectors(population_networks=GANN_instance.population_networks)
initial_population = population_vectors.copy()Fitness Function 정의
# We define the fitness function of the GA here - the fitness function attempts to maximum the prediction accuracy
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs
predictions = pygad.nn.predict(last_layer=GANN_instance.population_networks[sol_idx],
data_inputs=data_inputs)
correct_predictions = numpy.where(predictions == data_outputs)[0].size
solution_fitness = (correct_predictions/data_outputs.size)*100
return solution_fitnessGeneration Callback Function 정의
# The callback_generation function attempts to indicate the fitness values when running the GA
last_fitness = 0
def callback_generation(ga_instance):
global GANN_instance, last_fitness
population_matrices = pygad.gann.population_as_matrices(population_networks=GANN_instance.population_networks,
population_vectors=ga_instance.population)
GANN_instance.update_population_trained_weights(population_trained_weights=population_matrices)
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))
print("Change = {change}".format(change=ga_instance.best_solution()[1] - last_fitness))
last_fitness = ga_instance.best_solution()[1].copy()pygad.GA class를 활용하여 인스턴스 생성
# the GA parameters are defined here
num_parents_mating = 4
num_generations = 50
mutation_percent_genes = 5
parent_selection_type = "sss"
crossover_type = "single_point"
mutation_type = "random"
keep_parents = 1
init_range_low = -2
init_range_high = 5ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
mutation_percent_genes=mutation_percent_genes,
init_range_low=init_range_low,
init_range_high=init_range_high,
parent_selection_type=parent_selection_type,
crossover_type=crossover_type,
mutation_type=mutation_type,
keep_parents=keep_parents,
callback_generation=callback_generation)GA 실행
ga_instance.run()output:
Generation = 1
Fitness = 87.5
Change = 87.5
Generation = 2
Fitness = 87.5
Change = 0.0
...
Generation = 50
Fitness = 100.0
Change = 0.0Plot results 확인
ga_instance.plot_result()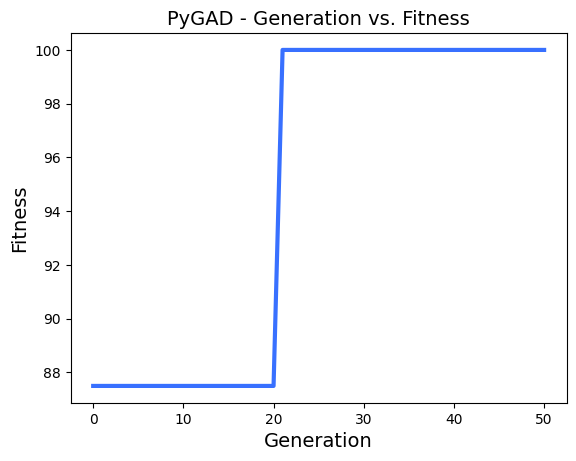
Best Solution 정보
# the GA searching results are illustrated
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Parameters of the best solution : {solution}".format(solution=solution))
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))output:
Parameters of the best solution : [-2.16907787 -0.74764627 -3.89528076 -0.68231215 0.08914895 1.00505111
-0.68862449 2.42638237 -0.69874121 -0.97105534]
Fitness value of the best solution = 100.0
Index of the best solution : 0# Tackle the generation of which the best fitness is appeared.
if ga_instance.best_solution_generation != -1:
print("Best fitness value reached after {best_solution_generation} generations.".format(best_solution_generation=ga_instance.best_solution_generation))output:
Best fitness value reached after 21 generations.Trained Weights를 사용해서 분류 예측
# the predicitons of the trained neural networks are shown
predictions = pygad.nn.predict(last_layer=GANN_instance.population_networks[solution_idx],
data_inputs=data_inputs)
print("Predictions of the trained network : {predictions}".format(predictions=predictions))output:
Predictions of the trained network : [0, 0, 0, 0, 1, 0, 0, 0]통계 계산
num_wrong = numpy.where(predictions != data_outputs)[0]
num_correct = data_outputs.size - num_wrong.size
accuracy = 100 * (num_correct/data_outputs.size)
print("Number of correct classifications : {num_correct}.".format(num_correct=num_correct))
print("Number of wrong classifications : {num_wrong}.".format(num_wrong=num_wrong.size))
print("Classification accuracy : {accuracy}.".format(accuracy=accuracy))output:
Number of correct classifications : 8.
Number of wrong classifications : 0.
Classification accuracy : 100.0.
현재 머신러닝, 딥러닝을 공부하고 있습니다.