Sequence to Sequence (Seq2Seq)란?
Sequence-to-Sequence(seq2Seq) 은 입력된 시퀀스(Input Sequence)로부터 다른 도메인의 시퀀스(Output Sequence)를 출력하는 모델입니다.
NLP, Chatbot, Machine Translation이 대표적인 예입니다. Input sequence와 Output sequence를 각각 질문과 대답으로 구성하면 Chatbot을 만들 수 있습니다. 또한 Input sequence를 입력 문장, Output sequence를 출력(대상) 문장으로 만들면 Machine Translation를 만들 수 있습니다.
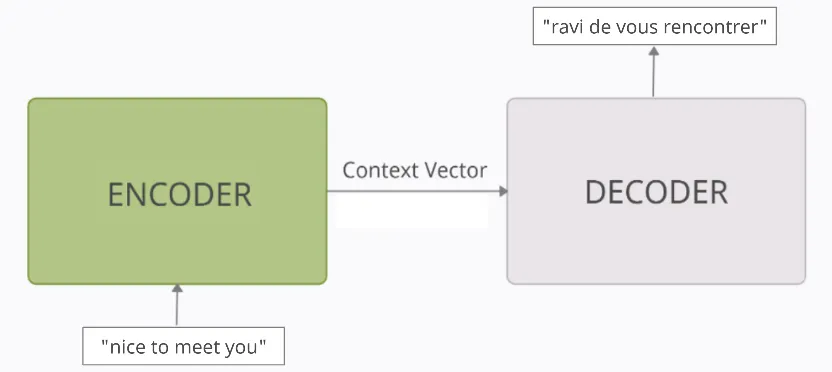
예를 들어, seq2seq모델로 만들어진 번역기는 Input "nice to meet you"를 받아서, Output "ravi de vous rencontrer" 프랑스 문장을 출력할 수 있습니다.
그 외에도 Text summarization, speech to text 등에서 쓰일 수 있습니다.
Seq2Seq Architecture
seq2seq모델은 주로 RNN, LSTM, GRU 및 Transformer와 같은 Neural Network 아키텍쳐를 사용해서 구현됩니다. seq2seq는 보통 Encoder와 Decoder 두 부분으로 구성됩니다.
Encoder는 입력 문장의 모든 단어를 순차적으로 입력 받은 후, 이 모든 단어를 압축해서 고정된 길이의 하나의 벡터로 만듭니다. 이 압축된 하나의 벡터를 context vector라고 합니다. 그 후, context vector를 Decoder로 전송합니다.
Context vector는 입력 문장의 모든 정보를 내포하고 있는 벡터입니다. 컨텍스트 벡터는 디코더가 올바른 예측을 할 수 있도록 도와줍니다.
Decoder는 컨텍스트 벡터를 받아 번역된 단어를 한개씩 순차적으로 출력합니다.
인코더와 디코더를 좀 더 자세히 살펴봅시다.
Encoder
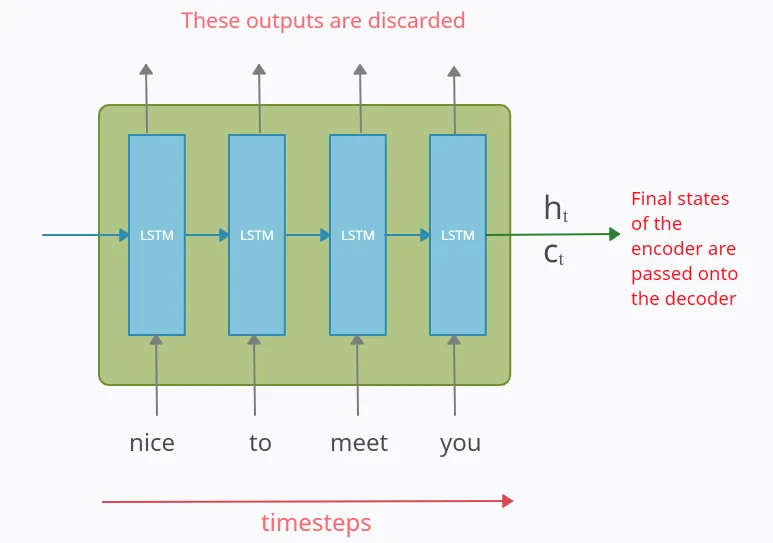
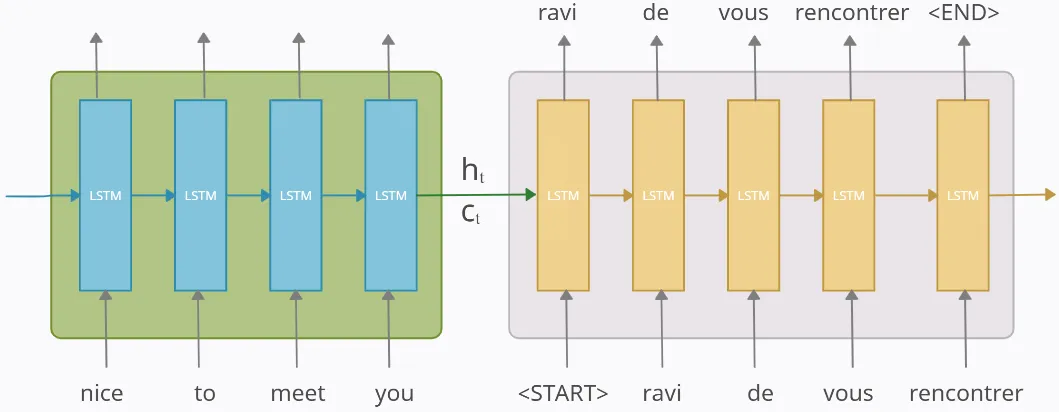
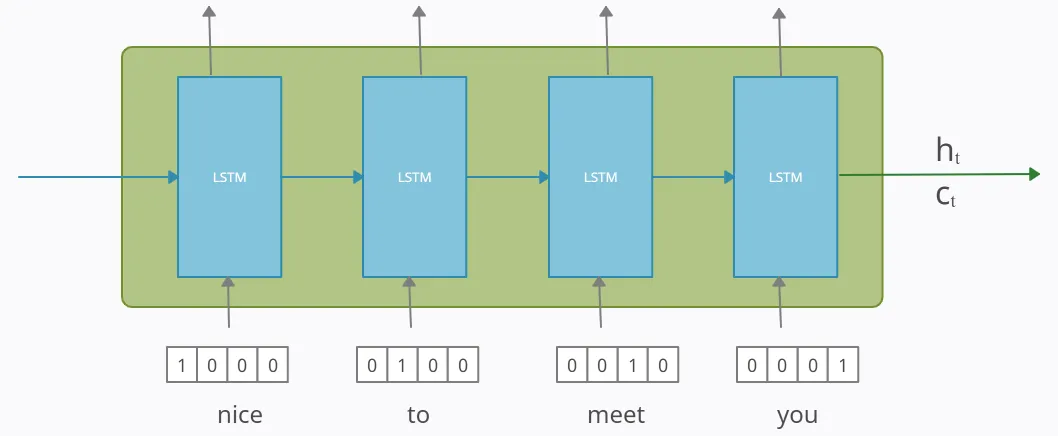
다음 예시는, 인코더를 LSTM 셀들로 구성한 예입니다. 입력문장은 word Tokenization을 통해 단어 단위로 쪼개집니다. 그리고 단어 토큰은 LSTM 셀의 각 시점()의 입력이 됩니다.
인코더는 단어 토큰을 받아 모든 정보를 포함하는 hidden state()와 cell state()를 만듭니다. 이 states는 디코더로 전송되는데, 이 states를 context vector라고 합니다. 이 컨텍스트 벡터는 디코더에서 출력 시퀀스를 만들기 위해 사용됩니다.
(인코더에서 LSTM 셀들의 출력값들은 버려집니다.)
Decoder
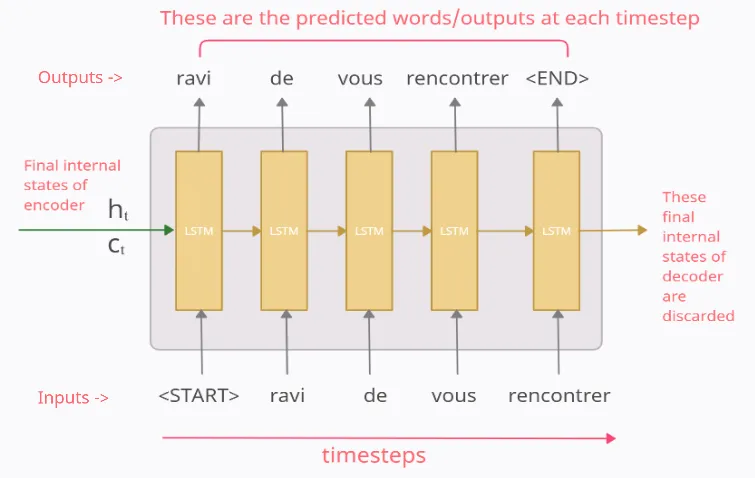
디코더 역시 LSTM 셀들로 구성되어 있습니다. 중요한 것은 디코더의 첫번째 states()는 인코더의 마지막 states()로 셋팅됩니다. 이 컨텍스트 벡터는 바람직한 출력 시퀀스를 만드는 것을 도와줍니다.
time step = 1
첫번째 시점()에서, 디코더 LSTM셀은 초기 입력으로 문장 시작을 의미하는 symbol <sos>를 입력받습니다. <sos>가 입력되면, input과 states()를 사용해서 다음에 등장할 확률이 높은 단어 ravi를 예측합니다.
time step = 2
두번째 시점()의 디코더 LSTM셀은 예측된 단어 ravi를 LSTM 셀의 입력으로 사용합니다. 또한, states()를 사용해서 de를 예측합니다.
time step = 3
세번째 시점()의 디코더 LSTM셀은 예측된 단어 de를 LSTM의 셀의 입력으로 사용합니다. 또한 states()를 사용해서 vous를 예측합니다.
디코더는 이런식으로 다음에 올 단어를 예측하고, 그 예측한 단어를 다음시점의 LSTM 셀의 입력으로 넣습니다. 이 작업은 문장 끝을 의미하는 symbol <eos>가 다음 단어로 예측될때까지 반복됩니다.
이 모든 작업은 테스트의 과정 이야기 입니다. 훈련 단계와 테스트 단계는 작동방식이 조금 다릅니다.
Training 과정에서는 Decoder에게 context vector와 실제 정답인 <sos>ravi de vous rencontrer를 입력받으면 ravi de vous rencontrer<eos>가 나와야 한다고 정답을 알려주면서 훈련합니다 (Teacher Forching).
Data Vectorizing
훈련과 테스트를 하기 위해서, 우리는 데이터를 벡터화해야합니다.
다음과 같이 raw data가 주어져있다고 가정합니다.
X = “nice to meet you” → Y_true = “ravi de vous rencontrer”우리는 우리의 target-sequence의 시작과 끝에 문장의 시작과 끝을 알려주는 스페셜 symbols을 추가합니다 (<sos> <eos>)
X = “nice to meet you” → Y_true = “<sos> ravi de vous rencontrer <eos>”그리고, input과 output 데이터에 원-핫 인코딩을 사용해서 벡터화합니다.
X = (x1, x2, x3, x4) → Y_true = (y0_true, y1_true, y2_true, y3_true, y4_true, y5_true)다음은 input 시퀀스와 output 시퀀스의 원-핫코딩 벡터의 표현을 보여줍니다.
For input X
‘nice’ → x1 : [1 0 0 0]
‘to’ → x2 : [0 1 0 0]
‘meet’ → x3 : [0 0 1 0]
‘you’ → x4 : [0 0 0 1]For Output Y_true
‘<sos>’ → y0_true : [1 0 0 0 0 0]
‘ravi’ → y1_true : [0 1 0 0 0 0]
‘de’ → y2_true : [0 0 1 0 0 0]
‘vous’ → y3_true : [0 0 0 1 0 0]
‘rencontrer’ → y4_true : [0 0 0 0 1 0]
‘<eos>’ → y5_true : [0 0 0 0 0 1]Training and Testing
Training and Testing Encoder
인코더의 작동은 훈련 단계와 테스트 단계 모두 동일하게 진행됩니다. 인코더는 input sequence의 각 토큰/단어를 하나씩 입력받아, 최종 states를 디코더로 전송합니다. 인코더의 파라미터는 backpropagation을 사용해서 업데이트 됩니다.
Training Decoder (Teacher Forcing)
위에서 설명드린것과 같이 디코더의 훈련 단계와 테스트 단계는 조금 다릅니다. 디코더를 훈련하기 위해서는, 우리는 이전 시점의 실제 출력/토큰(예측된 출력/토큰이 아님)을 현재 시점의 입력으로 사용하는 Teacher Forcing방식을 사용합니다.
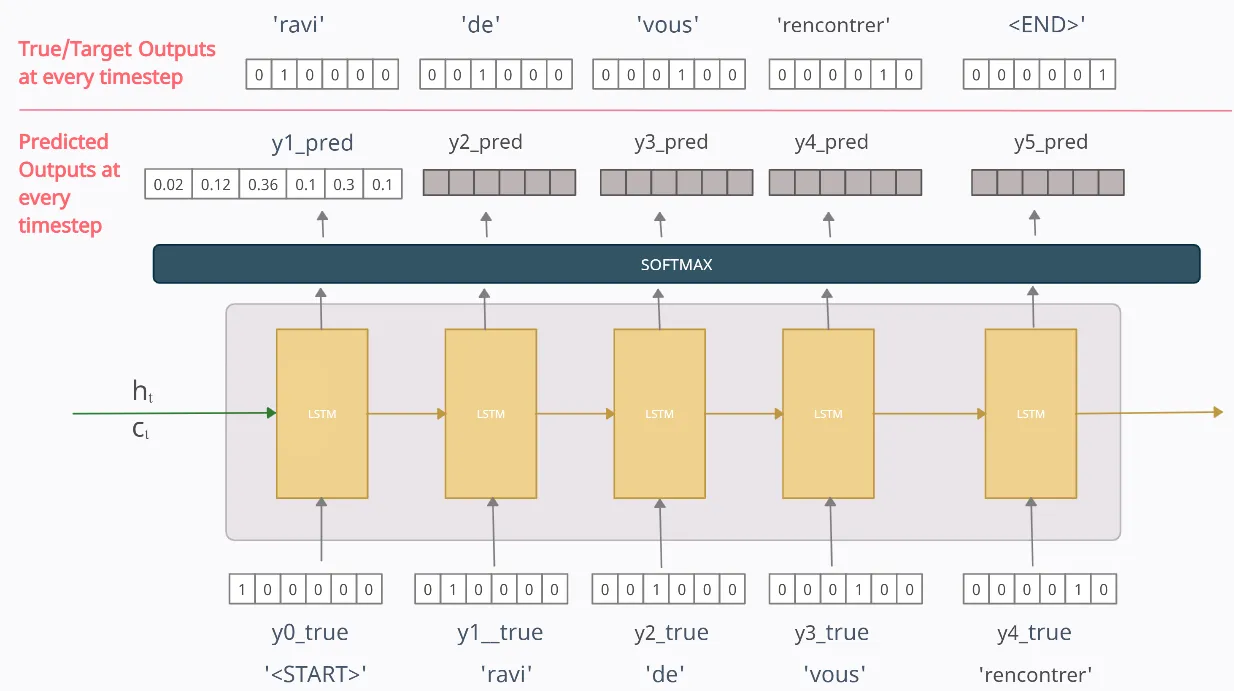
우선 첫번째 훈련의 iteration을 살펴봅시다. 디코더에서 임의의 시점 에서 output yt_pred는 softmax activation 함수를 사용해서 생성된 output 데이터세트의 전체 vocabulary에 대한 확률 분포입니다. output sequence의 각 단어별 확률값을 변환하고, 최대 확률을 가진 토큰/단어가 예측 값으로 선택됩니다.
예를 들어, 위에 그림을 참고하여, y1_pred = 은 우리 모델이 출력 시퀀스의 첫번째(1st) 토큰이 일 확률은 0.02, ravi일 확률은 0.12, de일 확률은 0.36이라고 생각함을 알려줍니다. 우리는 예측된 단어를 확률이 가장 높은 단어로 간주합니다. 그렇기 때문에 첫번째 단계에서 예측된 단어/토큰은 0.36의 확률을 가진 de입니다.
time step = 1
단어 <START>를 표현하기 위해 벡터 [1 0 0 0 0 0]가 input으로 사용됩니다. 우리는 우리 모델이 output으로 y1_true=[0 1 0 0 0 0]을 예측하기를 원합니다, 하지만 우리 모델이 막 훈련하기 시작했을 때는, output은 아마 다를 것입니다. 일때 예측된 값을 y1_pred=[0.02 0.12 0.36 0.1 0.3 0.1]라고 해봅시다. 이 결과는 첫번째 토큰은 'de'라고 예측한 결과를 보여줍니다.
이제, y1_pred값을 input으로 사용하여 일때를 예측해봅시다. 그렇게 할 수 있지만 실제로는 수렴 속도가 느리고 모델이 불안정하며 기술이 좋지 않은 등의 문제가 발생하는 것으로 나타났습니다.
그래서, 이것을 바로잡기 위해서 Teacher forcing이 도입되었습니다. 이전 시점(-1)의 실제 output/token값을 현재시점()의 input으로 사용합니다 (예측된 output 사용을 하지 않음). 이것은 =2일때 input이 y1_true=[0 1 0 0 0 0] 임을 의미합니다 (y1_pred = [0.02 0.12 0.36 0.1 0.3 0.1])
=2일때 output은 아마 랜덤한 벡터값 y2_pred를 출력할 것입니다. =3일때 y2_true=[0 0 1 0 0 0] 를 input으로 사용합니다 (y2_pred가 아님). 이런식으로 각 시점 에서, 우리는 이전시점(-1)에서의 true output값을 input값으로 사용합니다.
마지막으로, loss는 모델의 매개변수를 업데이트하기 위해 backpropagation을 사용해서 각 시점으로부터 예측된 outputs (yt_pred)와 에러로부터 계산됩니다. Loss Function은 target-sequence와/Y_ture
마지막으로, 각 시간 단계의 예측된 outputs(yt_pred)에 대해 손실이 계산되고 errors는 시간에 따라 역전파되어 모델의 매개변수를 업데이트합니다. 사용된 Loss function은 target-sequence/Y_true와 predicted-sequence/Y_pred 사이의 범주형 cross-entropy loss function입니다.
- Y_true = [y0_true, y1_true, y2_true, y3_true, y4_true, y5_true]
- Y_pred = [
‘<START>’, y1_pred, y2_pred, y3_pred, y4_pred, y5_pred] - 마지막 디코더의 states는 버려집니다.
Testing Decoder
실제 어플리케이션에서는, 우리는 Y_true가 없고 오직 X값만을 가지고 있습니다. 따라서 target-sequence/Y_true가 없기 때문에, Training 단계에서 수행한 작업을 사용할 수 없습니다.
따라서 모델을 테스트할 때, -1에서 예측된 output yt-1_pred(훈련단계와 달리 실제 출력이 아님)이 현재 시점 의 input으로 사용합니다. Rest는 Training 단계와 모두 동일합니다.
이제 모델을 훈련했고, 훈련한 1개의 문장에 대해 테스트한다고 가정해 보겠습니다. 만약 우리가 모델을 잘 훈련했다면, 훈련된 문장에서만 모델이 거의 완벽하게 수행되어야 하지만, 설명을 위해 모델이 잘 훈련되지 않았거나 부분적으로 훈련되었다고 가정하고 이제 테스트합니다.
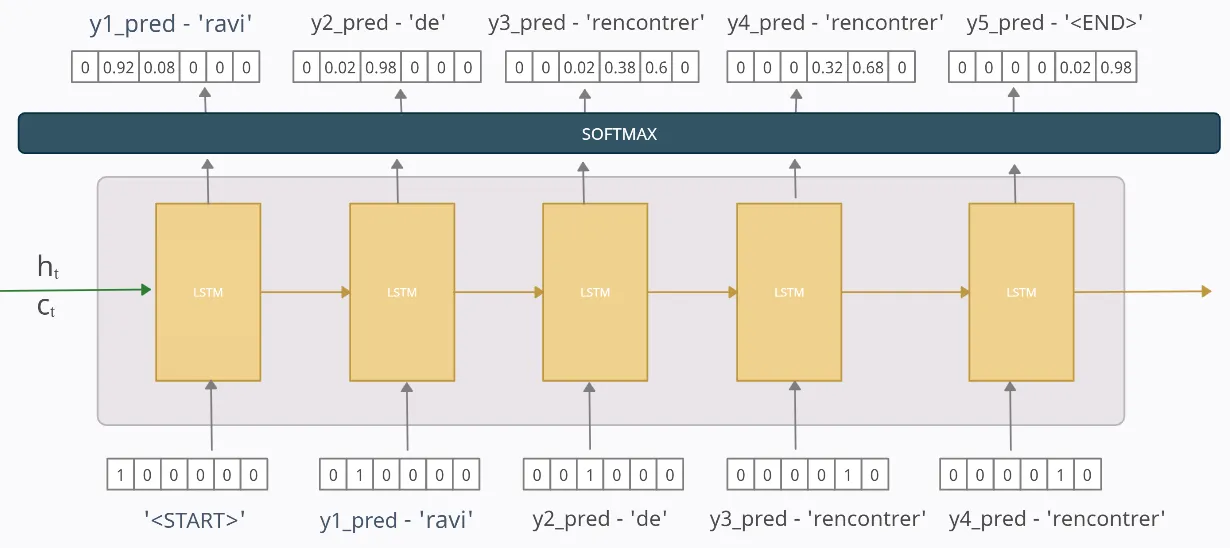
time step = 1
y1_pred = [0 0.92 0.08 0 0 0]는 모델이 output-sequence의 첫번째 토큰/단어가 0.92의 확률로 'ravi'가 될 것으로 예측하므로, 다음 단계(=2)에서 이 예측된 토큰/단어는 오직 입력으로만 사용될 것입니다.
time step = 2
첫번째 시점으로부터 예측된 토큰/단어 'ravi'가 input으로 사용됩니다. 우리의 모델은 다음 output-sequence의 다음 토큰/단어가 0.98의 확률로 'de'가 될 것으로 예측하므로, 다음 단계(=3)에서 이 예측된 토큰/단어는 오직 입력으로 사용됩니다.
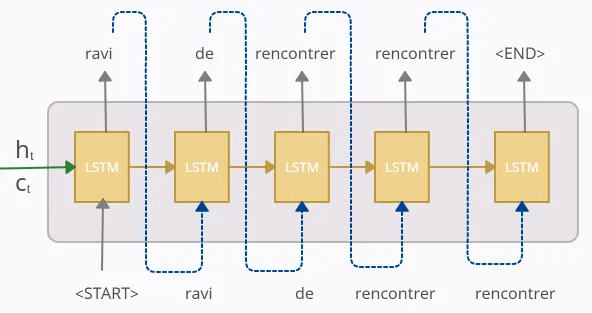
이런식으로 매 시점마다 과정이 문장의 끝을 알리는 스폐셜 토큰 <END>가 나올때까지 반복됩니다.
우리의 훈련된 모델을 따르면, predicted-sequence는 “ravi de rencontrer rencontrer”입니다. 우리모델은 3번째 단어를 잘못 예측했음에도 불구하고, 우리는 이것을 다음단계의 입력으로 사용했습니다. 모델의 정확성은 사용 가능한 데이터 양과 모델이 얼마나 잘 훈련되었는지에 따라 달라집니다. 모델은 잘못된 output을 예측할수 있음에도 불구하고, 이 output은 테스트 단계에서 input으로 사용됩니다.
Embedding Layer
인코더와 디코더의 input-sequence는 사실 embedding layer를 통과하여 input의 단어 벡터의 차원을 줄입니다. 왜냐하면 원-핫 인코딩 벡터의 차원은 매우 크며, embedding layer를 통과한 벡터는 단어를 훨씬 더 잘 표현할 수 있기 때문입니다. 인코더 부분의 경우, 임베딩 레이어가 단어 벡터의 차원을 4에서 3으로 줄이는 경우 아래에 표시될 수 있습니다. 그림의 보라색 벡터가 임베딩된 벡터입니다. embedding layer는 사전훈련된 Word2Vec 임베딩 등을 사용할 수 있습니다.
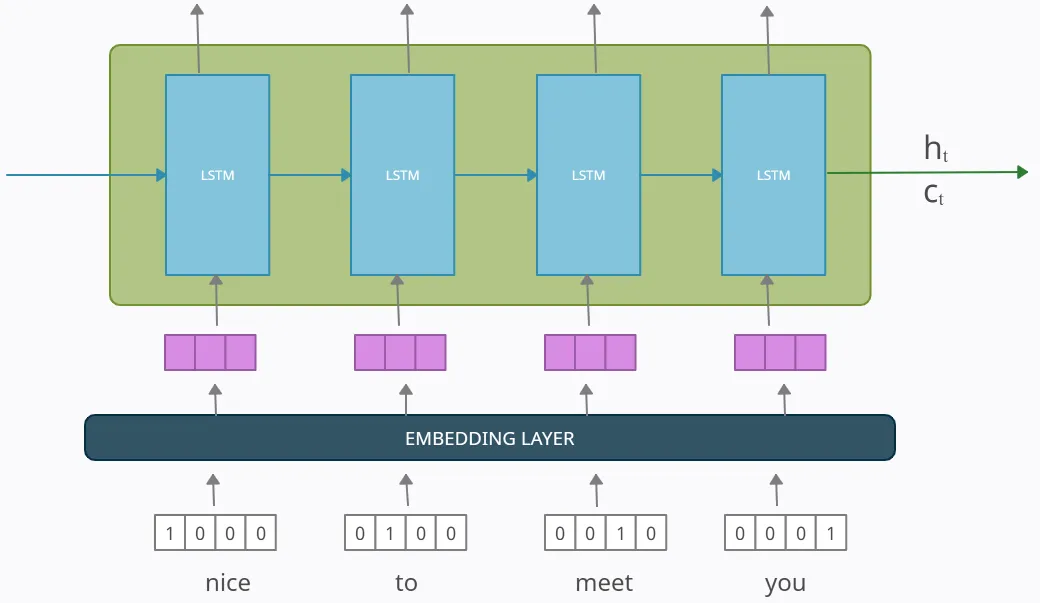
Summarization
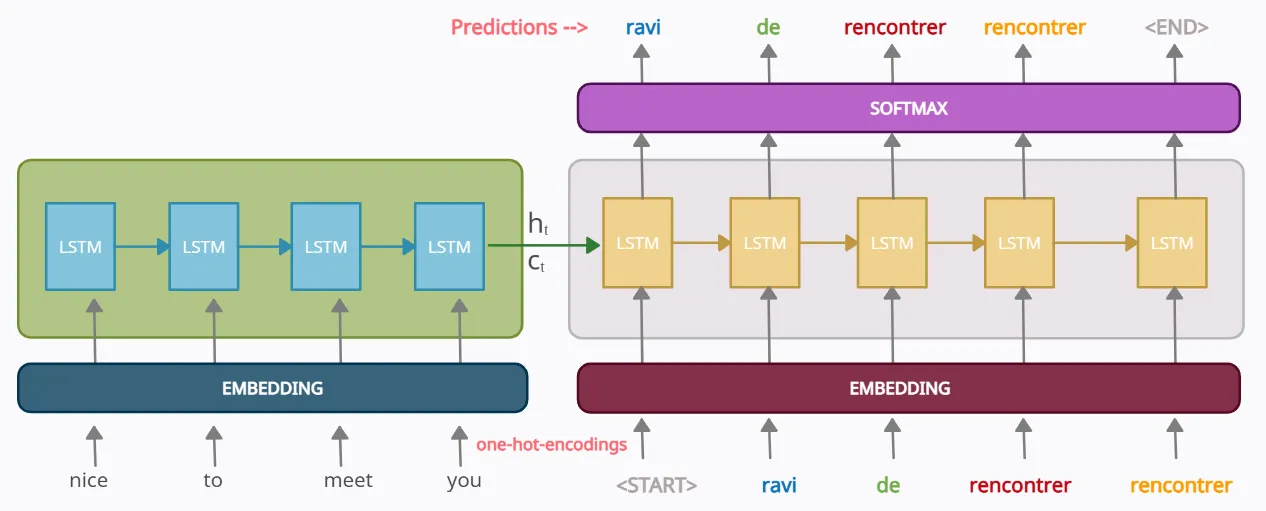
이것이 가장 기본적인 seq2seq의 구조입니다. seq2seq는 어떻게 구현하느냐에 따라 더 복잡해질 수 있습니다. 어텐션 매커니즘을 통해 지금 알고 있는 컨텍스트 벡터보다 더욱 문맥을 반영할 수 있는 컨텍스트 벡터를 구해서 매 시점마다 입력으로 사용할 수 있습니다.
Rerences
https://medium.com/analytics-vidhya/encoder-decoder-seq2seq-models-clearly-explained-c34186fbf49b
