
6학기가 끝나고 휴학 전 겨울방학에 무언가를 공부하고 또 기록하는 일이 필요할 것 같아서 이거라도 해야될 것 같아서...혼공학습단에서 <혼자 공부하는 머신러닝+딥러닝>을 신청하게 되었다.

Google Colab으로 실습을 하지만 저는 연구실에 있는 딥러닝 머신으로도 돌릴 예정이라 서버에 대해서도 조금 공부를 하려고 합니다.

제 거는 아니지만 제가 관리하기도 하고 이러라고 있는 딥러닝머신 아닐까요? (교수님 : 아니다이놈아)
사담은 여기까지 하고 내용 정리&실습을 진행해보겠습니다.
아래 내용은 <혼자 공부하는 머신러닝+딥러닝> 과 숙명여자대학교 소프트웨어학부 <데이터사이언스개론> 수업을 참고하여 작성한 내용입니다.
1. 인공지능과 머신러닝, 딥러닝
인공지능이란?
사람처럼 학습, 추론, 지각 능력(지능)을 가진 컴퓨터 시스템을 만드는 기술
- 일반 인공지능(artificial general intelligence)/강인공지능(Strong AI) : 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템
- 약인공지능(Week AI) : 현재 현실에서 사용하고 있는 AI. 주로 보조역할을 함
머신러닝이란?
자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 대표적인 머신러닝 라이브러리 : 사이킷런(scikit-learn)
딥러닝이란?
인공신경망(artificial neural network)을 기반으로 한 방법을 통칭하여 부르는 말
- 대표적인 딥러닝 라이브러리 : 텐서플로, 파이토치
2. 코랩과 주피터 노트북
colab.research.google.com 에 접속하여 코랩 노트북을 만듭니다.
텍스트는 마크다운으로 쓰는데 저는 이미 마크다운에 익숙해서 README 의 폐해(?) 넘어가겠습니다.
구글 코랩은 메모리 12기가, 디스크 100기가를 무료로 사용할 수 있지만 12시간 이상 사용할 수 없다는 아쉬운 점이 있어서 구글 코랩도 돌려보고 연구실 서버로도 돌려보려고 합니다.
새 노트북 만들기
실습하라고 하니까 해보겠습니다.
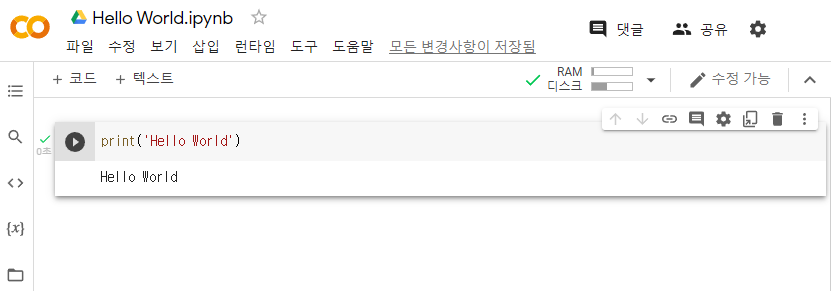
기초 of 기초 'Hello World'
+ Ubuntu 서버컴퓨터 GUI 접속 설정하기
원래는 CUI로 그냥 썼는데 주피터를 편하게 하려면 GUI 접속까지 가능해야할 것 같아서 깔아봤습니다. 교수님 학부연구생이라 쓰고 중생이라 읽는다을 용서하세요. 그러게 왜 학부연구생한테 서버를 맡깁니까.
sudo apt-get install xrdp
systemctl start xrdp
firewall-config해주고 방화벽 들어가서 '영구적' 해서 port를 추가해줍니다. 그리고 학교 정보보안팀에 서버 열기(?)와 방화벽 요청 메일도 넣습니다.
3. 마켓과 머신러닝 (생선분류하기)
한빛마켓에서 파는 생선을 '도미', '곤들매기', '농어', '강꼬치고기', '로치', '빙어', '송어'로 분류해보자! (이 예제가 Chapter4까지 이어지는 것 같으니 뒤에서 하겠다고 생각하지 말고 앞에서부터 차근차근 따라하도록 하자)
1) 도미데이터 준비하기
35마리 도미의 길이와 무게를 리스트로 만들어 준비하고 matplotlib 라이브러리르 import 하여 산점도를 그려봅니다.
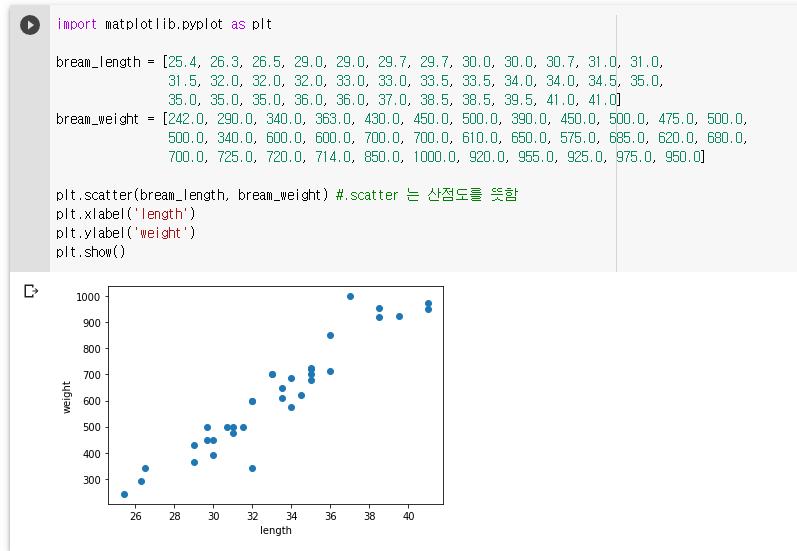
대체로 일차 함수 형태로 나타나는 것을 볼 수 있습니다! (선형적이라고 말함)
2) 빙어 데이터 준비하기
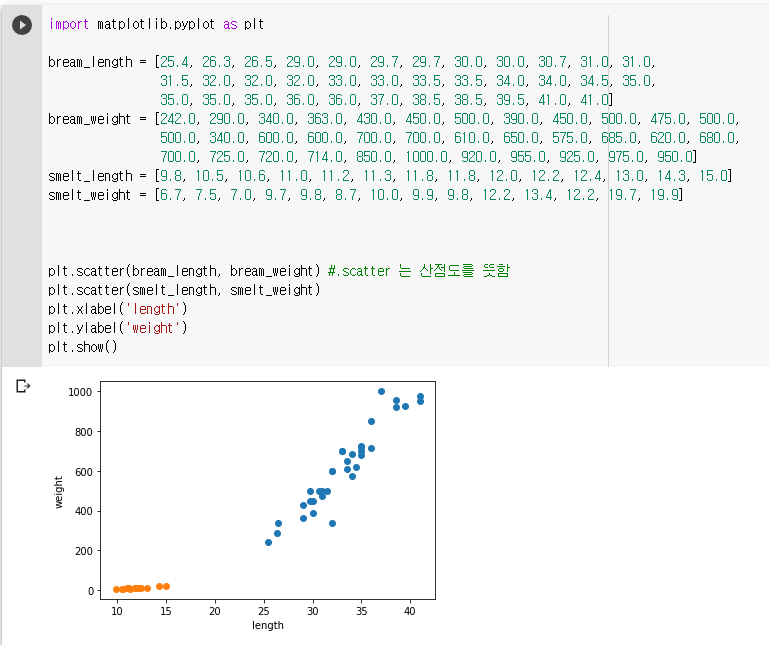
14마리 빙어의 길이와 무게 리스트를 추가하여 산점도에도 나타내줍니다. 주황색 점이 빙어입니다!
3) K-Nearest Neighbors Algorithm(K-NN)
가장 가까운 k개 instance를 이용하는 방법으로 이것은 분류(classification)이기 때문에 voting하는 방법을 사용하는 것 같습니다.
- 거리에 따라 weighted voting을 사용할 수 있습니다.
- 다만 크기가 큰 데이터나 n차원 데이터에서 각 인스턴스에 대해서 유클리드 거리를 구하기는 낭비일 수 있습니다.
- k=데이터개수 일 때 전체 dataset이 사용되기 때문에 데이터의 다수를 차지하는 class로 분류됩니다.
- k는 voting 을 사용할 경우 홀수로 해야 적절합니다.
data를 length, weight를 속성, 데이터를 한 record로 바꿔줍니다. 이후 도미 35마리, 빙어 14마리를 순서대로 넣었기 때문에 도미 = 1, 빙어=0 으로 데이터의 정답(?)을 알려줍니다. 그 후 KNeighborClassifier() 의 fit()메소드와 predict()로 데이터의 분류를 추정해봅시다.
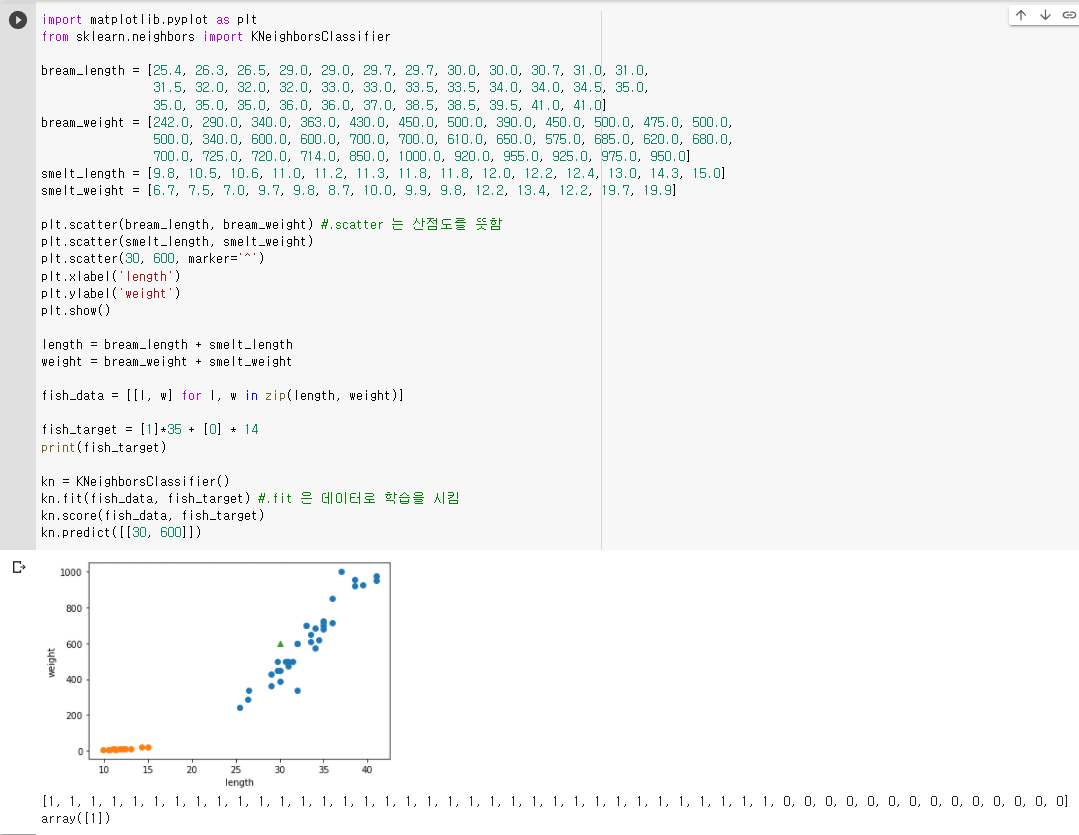
초록색 세모로 표시한 것이 predict()한 30, 600입니다. KNeighborClassifier()의 기본값이 5이므로 가장 가까운 5개 중에서 voting하여 도미(=1)이라는 결과가 나왔습니다.
전체 데이터셋을 사용하면 항상 도미가 나오겠죠? 그럼 k의 갯수를 5~49까지 늘려가면서 score() 메소드로 accuracy를 출력해봅시다. 더해서 k가 얼마일 때 score가 바뀌는 지, k값에 따라서 score가 어떻게 변화하는지 그래프도 그려보겠습니다.
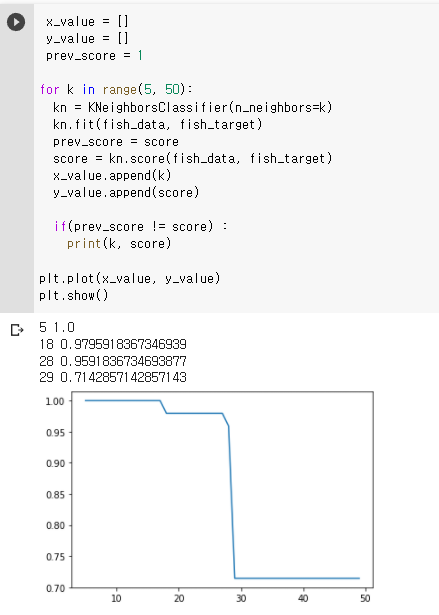
5~17일 때에는 정확도가 1이지만 k가 커질수록 정확도가 낮아지고 전체를 할 때에는 35/49(전체 도미의 비율)과 같아짐을 알 수 있습니다.
Chapter1의 내용은 여기까지 입니다. 책이 상당히 직관적으로 써진 것 같습니다. 아직 1장인데 쉽다고 말하기 좀 그래서... 천천히 따라가다보면 재밌거나 도전할 내용이 있을 것 같습니다. 저도 머러천재가 될 수 있겠죠?

기대하면서 마무리하겠습니다.
