
0. 프롤로그
chapter1에서는 훈련 데이터셋으로 정확도를 측정했다. 이미 답을 알려주고 시험을 보는 것과 같다.

이것이 제대로된 것일까? 조금 더 공부해보자
1. 훈련 세트와 테스트 세트
지도학습과 비지도학습
-
지도학습 : 데이터와 정답을 입력(input), 타겟(target)이라 하고 이 둘을 합쳐 훈련데이터셋이라고 한다. K-NN은 input, target이 있었으므로 지도학습 알고리즘이다.
-
비지도학습 : 타깃 없이 입력 데이터만을 사용하여 데이터를 파악하거나 변형하는데 사용하는 방식
-
훈련 세트(train set) : 모델의 훈련에 사용되는 데이터
-
테스트 세트(test set) : 모델 평가를 위해 준비된 데이터 혹은 이미 준비된 데이터 중에서 떼어낸 일부 데이터
-> chapter1에서는 훈련 데이터로 모델을 평가했으므로 적절하지 않았음!
그렇다면 데이터를 잘라서(slicing) 훈련 세트와 테스트 세트로 나누어 사용해보자
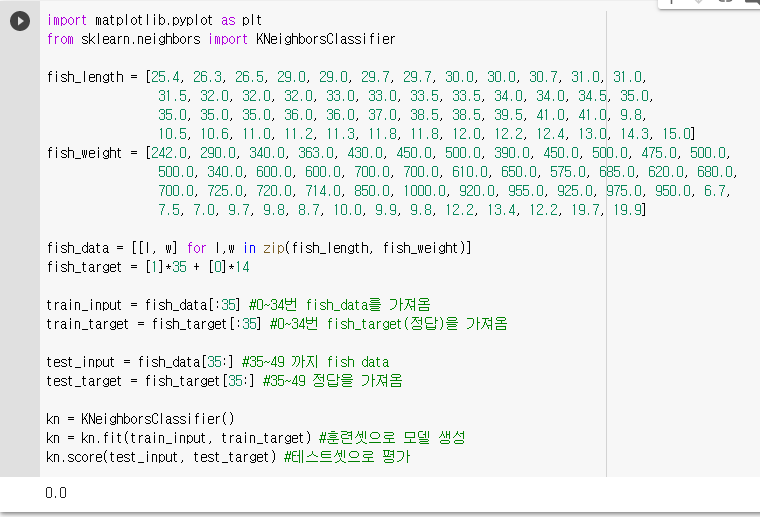

샘플링 편향
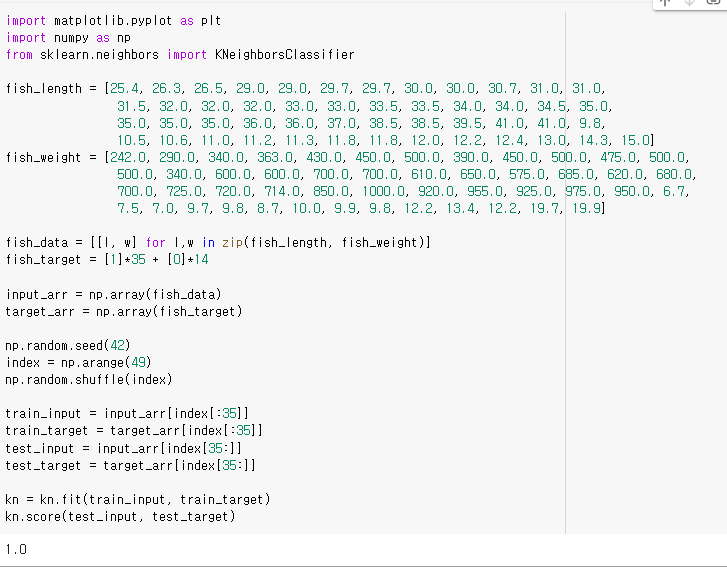
우리는 이미 데이터가 앞의 35개가 도미이고 뒤에 14개가 빙어임을 알고 있습니다. 그런데 앞의 35개 데이터 즉 도미만 넣고 학습시켜놓고 뒤의 14개, 빙어로 테스트를 하고 있었습니다. 출제 범위를 잘못 넣어준 것입니다. 아래의 plot을 봐주세요.
따라서 어떤 데이터가 들어오든 도미로 분류하여 정확도가 0이 나왔습니다. 이렇게 훈련셋과 테스트셋이 골고루 섞여있지 않는 것을 샘플링 편향(sampling bias)이라고 합니다.
그렇다면 데이터를 잘 섞거나 골고루 뽑아낼 수 있는 방법을 알아봅시다.
넘파이(Numpy)
넘파이는 고차원 배열을 쉽게 사용하기 위한 라이브러리입니다. 이 친구는 매우 똑똑하기 때문에 대갈(not NCT 천러's dog)을 열심히 돌리지 않아도 됩니다.
 리스트를 넘파이 배열로 바꾸고 레코드와 속성 개수를 출력해보았습니다.
리스트를 넘파이 배열로 바꾸고 레코드와 속성 개수를 출력해보았습니다.
이제 배열에서 무작위로 샘플을 골라보겠습니다. 이때 input과 target을 함께 선택해야함을 잊지 말아야합니다. 잘못된 만남이 될 수 있으므로...
random index를 만들어서 해당 index로 훈련셋과 테스트셋을 만듭니다. 잘 분산되어 있는지 plot으로도 확인해봅시다.
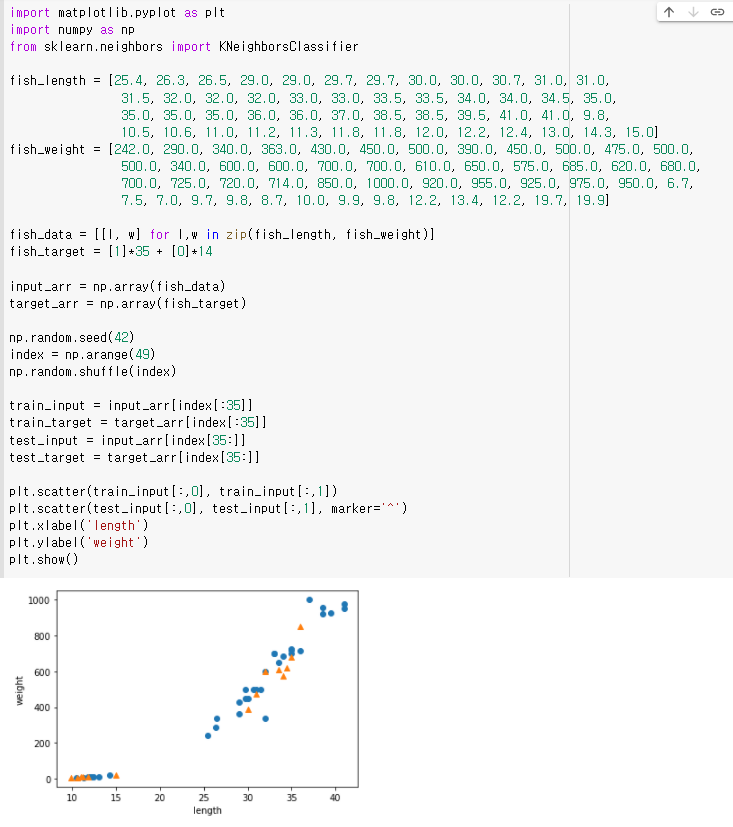
그럼 score함수로 얼마나 정확한지 봅시다.

2. 데이터 전처리
모든 데이터가 잘 나뉘면 좋겠지만 가끔 이상한(?) 데이터가 들어올 때가 있습니다. 이것을 그냥 모른다고 틀리고 지나간다면 그것은 인공지능이 아닐 것입니다. 이런 이상한(?)데이터를 어떻게 처리할 수 있을지 배워봅시다.
넘파이와 사이킷런으로 세팅하기
numpy를 이용하여 list를 쉽게 우리가 원하는대로 세팅하고 사이킷런에서 제공하는 train_test_split()함수로 편하게 훈련셋과 테스트셋을 나누어줍니다.
train_test_split()의 옵션
- test_size : 테스트 셋 구성 비율 default = 0.25
- shuffle : split 이전에 shuffle을 할 것인지를 나타냅니다. default = True
- random_state : random suffle seed 값
- stratify : 데이터를 훈련, 테스트로 나눌 때 데이터 비율의 유지 여부. default = None. 설정하고자 할 때에는 target 데이터를 넣어주어 비율을 알려줘야함.
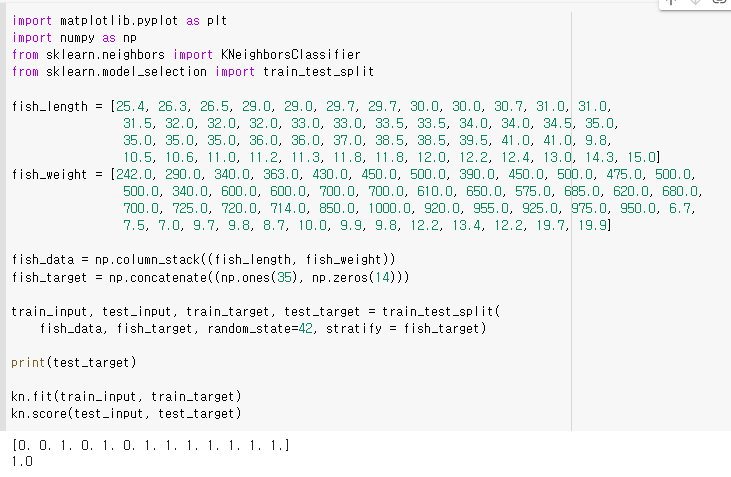 나름 잘 된 것 같습니다 오예~
나름 잘 된 것 같습니다 오예~
수상한 데이터
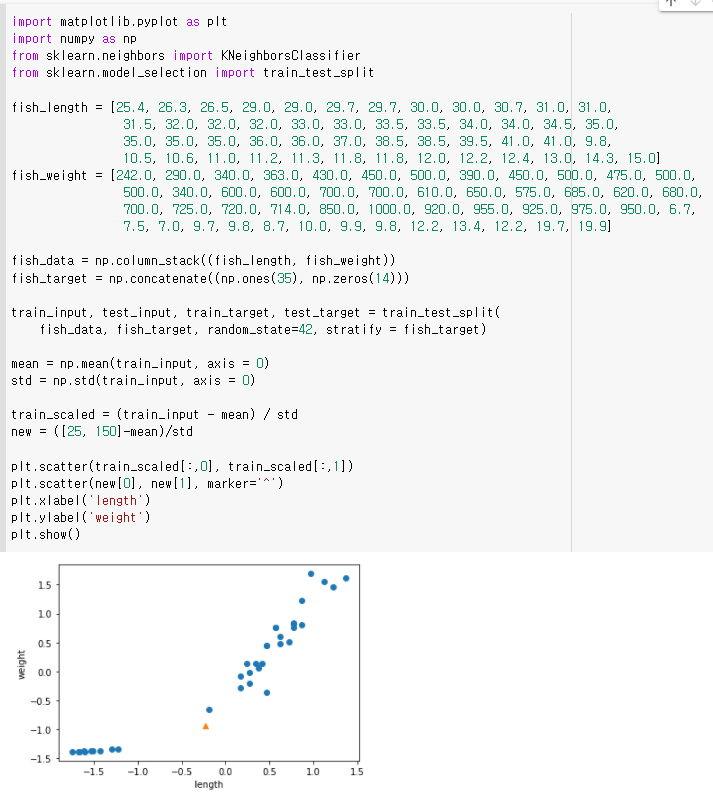
그런데 이 때 [25, 150] 도미 데이터를 입력해보았는데 빙어로 분류가 됩니다. 왜그럴까요?
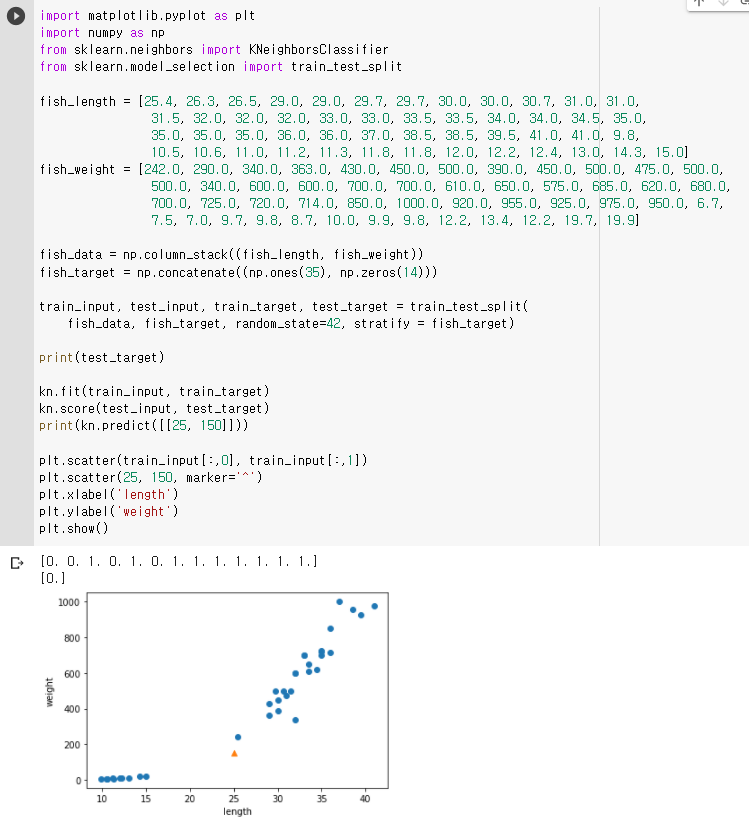
먼저 k-NN에 적용된 샘플을 살펴보도록 합시다.
가장 가까운 이웃 인스턴스들이 모두 빙어임을 알 수 있습니다. 하지만 가장 가까운 점은 도미입니다. 현재 그래프상에서 나타난 문제는 x,y축 각각의 속성이 다른 스케일을 갖고 있기 때문에 거리를 일정한 값으로 맞춰주는 작업이 필요합니다.
기준 맞추기
가장 많이 사용하는 방법은 표준 점수입니다. 표준 점수는 데이터가 기준에서 몇 표준편차만큼 떨어져있는지를 나타내는 값입니다. (표준 편차는 데이터가 분산된 정도)
- 평균 : 해당 집단의 데이터를 모두 더해 인스턴스의 개수로 나눈 값
- 분산 : 편차를 제곱하여 평균을 낸 값
- 표준 편차 : 분산의 제곱근
- 표준 점수 : (타겟 인스턴스의 값 - 평균) / 표준편차
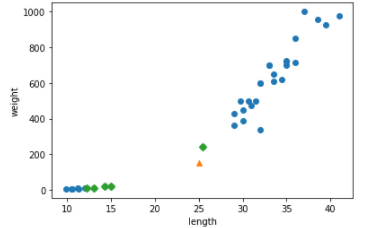
 표준점수로 scale을 다 맞춰주었습니다. 이 데이터셋으로 다시 K-NN을 학습시키고 제일 가까운 인스턴스도 표시해주도록 하겠습니다.
표준점수로 scale을 다 맞춰주었습니다. 이 데이터셋으로 다시 K-NN을 학습시키고 제일 가까운 인스턴스도 표시해주도록 하겠습니다.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
fish_data = np.column_stack((fish_length, fish_weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, random_state=42, stratify = fish_target)
mean = np.mean(train_input, axis = 0)
std = np.std(train_input, axis = 0)
train_scaled = (train_input - mean) / std
new = ([25, 150]-mean)/std
distances, indexs = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexs, 0], train_scaled[indexs, 1], marker = 'D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std
kn.score(test_scaled, test_target)
result = kn.predict([new])
if(result == 1):
print("도미")
else:
print("빙어")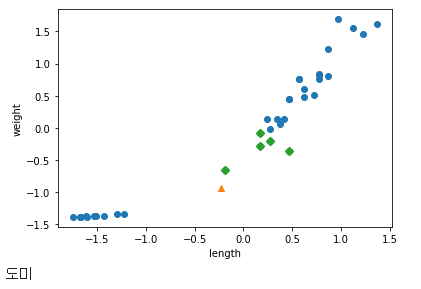
잘 분류되었습니다! 모델이 도미라고 확인도 시켜주네요. 이렇게 표준점수로 스케일이 다른 특성을 어떻게 처리하여 정확도를 높일 수 있는지 배웠습니다.
선택미션 - 확인문제 풀기
Q1. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습방법은 무엇인가요?
A1. 지도학습
Q2. 훈련 세트와 테스트세트가 작못 만들어져 전체 데이터를 대표하지 못하는현상을 무엇이라 부르나요?
A2. 샘플링 편향
Q3. 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
A3. 행 샘플, 열 : 특성
학교에서는 outlier를 어떻게 처리할 것인가를 위주로 배워서 표준 점수를 사용하여 scale을 맞추는 방법은 까먹고 있었습니다. 이런 하나씩 뭔가 해나가는 것이 재밌기도 하고 다음 챕터가 기대됩니다. 오늘은 여기까지 하겠습니다.

