
명절에 본가에 내려가지 않은지도 어언 4년...고3 추석 이후로 거의 가지 않았는데 올해도 역시
정부의 방침을 잘 지킨 모범국민이 되었지만 사실 이번년도는 꼭 가고 싶었다... 왜냐면 친동생이 곧 고3이기 때문에 열심히 놀리려고

서울 사는 바이러스+전자파 덩어리는 오지말라고 했다...
이해는 하는데 엄마딸 슬퍼용...(˚ ˃̣̣̥᷄ω˂̣̣̥᷅ )
설 연휴를 틈타 다시 벼락치기를 시작해보겠따.
아래 내용은 <혼자 공부하는 머신러닝 + 딥러닝>과 숙명여자대학교 소프트웨어학부 <데이터사이언스개론> 수업을 참고하여 작성한 내용입니다.
1. 로지스틱 회귀
생선 럭키백을 만들어 각 생선이 존재할 확률을 구해보자!
럭키백의 확률
7가지 생선의 길이, 높이, 두께, 대각선 길이, 무게를 알려주었을 때 럭키백에 들어간 7가지 생선의 확률을 출력해보는 것입니다.그럴거면왜럭키백만들어 사실 개인적인 생각인데 아무 숫자나 넣어도 사람들은 모르기 때문에 그냥...이라고 하면 실제로는 고소먹겠죵?
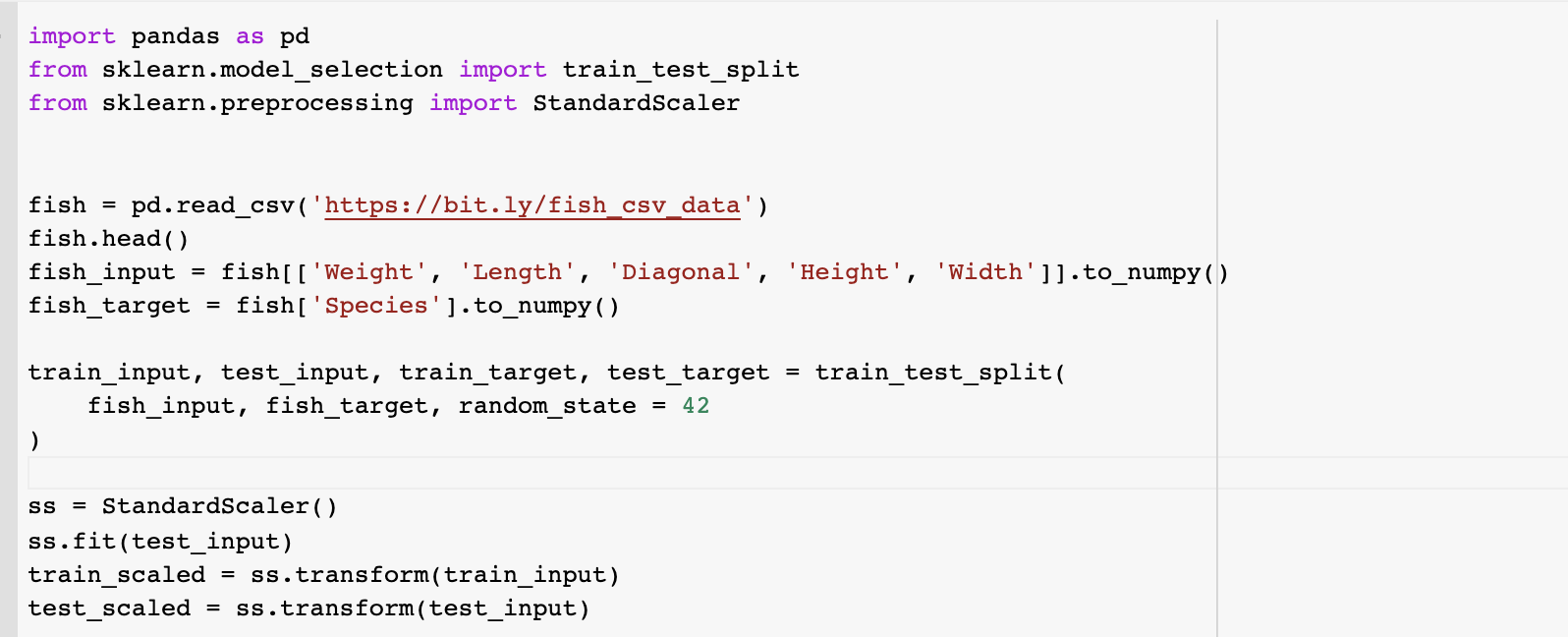
데이터를 준비해봅시다. 데이터를 보러 들어가보니 Bream, Roach, Whitefish, Parkki, Perch, Pike, Smelt 총 7가지가 있네요. 이것을 Google colab으로 불러오겠습니다.
무게, 길이, 대각선 길이, 높이, 두께를 input으로 Species를 맞추는 것이기 때문에 각각 input, target으로 나누어주고 train, test 데이터셋으로 또 나눠줍니다. 또 이것을 표준화 전처리를 해줍니다.
 완료되었으니 이제 확률을 알아봅시다.
완료되었으니 이제 확률을 알아봅시다.
1. k-최근접 이웃 분류를 통합 확률 예측
KNeighborsClassifier()로 모델을 훈련하여 2개 이상의 클래스를 분류하는 다중 분류 방식을 사용해봅시다.
3개 이웃을 사용하는 모델을 만들어서 훈련 시킵니다. score가 좀 그렇지만 일단 계속 해줍시다. test datset의 상위 5개 샘플에 대해서 예측을 해보았더니 각각 두번째 줄처럼 나왔습니다. 5개의 확률을 각각 출력해보니 아래와같이 나왔습니다. 0번째 샘플, 4번째 샘플을 가져다가 가까운 클래스들을 출력해보았더니 다음과 같이 나왔습니다. 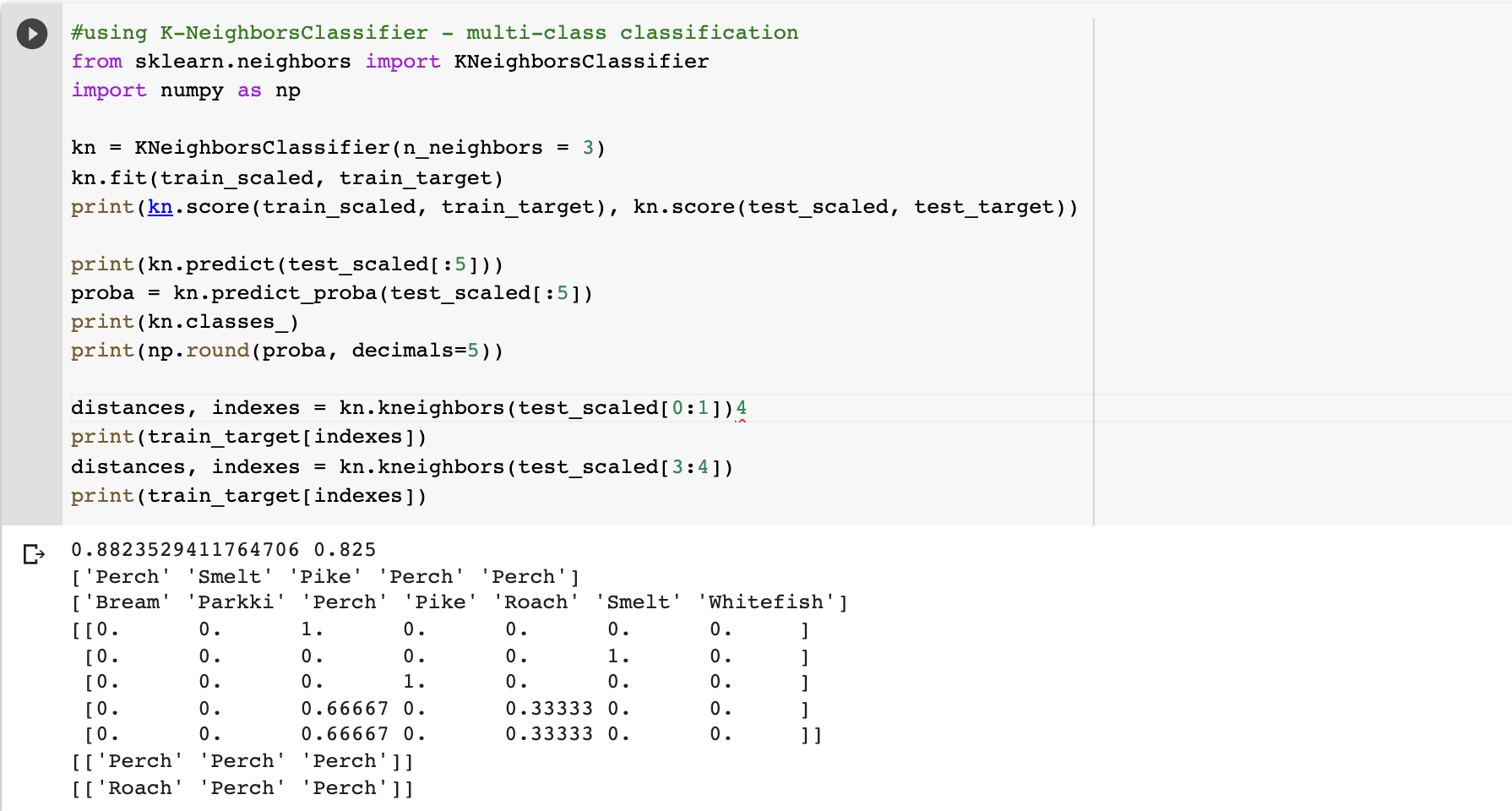 확률이 무조건 0, 1/3, 2/3, 1 밖에 나오지 않기 때문에 예측했다고 말하기 조금 민망할 것 같습니다.
확률이 무조건 0, 1/3, 2/3, 1 밖에 나오지 않기 때문에 예측했다고 말하기 조금 민망할 것 같습니다.
로지스틱 회귀(Logistic Regression)
이름은 회귀이지만 이진분류에 사용되는 모델입니다. 선형 모델을 통해 해당 Instance가 target class에 속할 확률을 추정합니다. logistic function 은 다음과 같습니다. 입력값 f(x)는 무한히 늘어날 수 있습니다. 따라서 (-무한대~무한대) 입력값을 [0, 1]로 출력해줄 수 있어야 합니다. odds에 로그를 취해서 변환해주어 logistic function을 유도해봅시다.
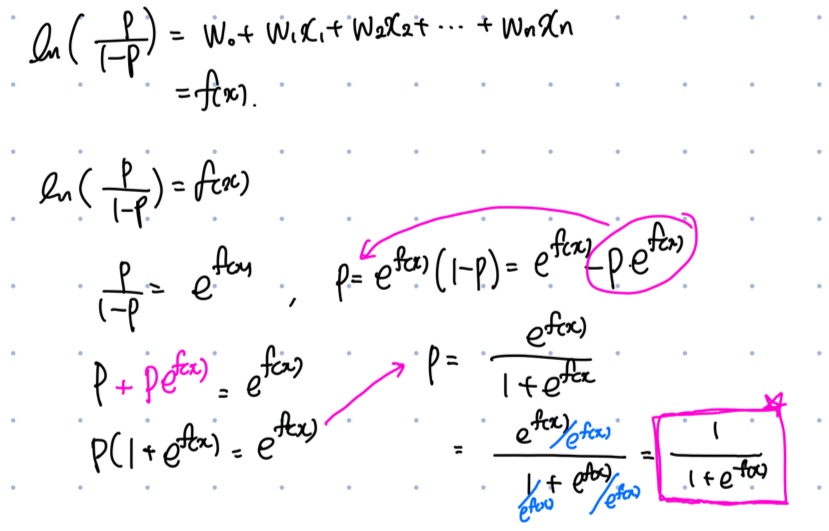
 (출처:창의 컴퓨팅(Creative Computing) - 시그모이드)
(출처:창의 컴퓨팅(Creative Computing) - 시그모이드)
logistic function(sigmoid function)을 통해 다음과 같은 시그모이드 그래프를 그릴 수 있습니다. p>0.5 이면 positive class, p<0.5이면 negative class로 분류합니다.
로지스틱 회귀를 이용하여 다음과 같이 상위 5개 샘플을 분류해봅시다. 먼저 bream, smelt만 추출하여 훈련을 하고 모델을 통해 f(x)를 확인해 시그모이드 함수로 remap을 하면 0~1 사이의 값으로 나옵니다. 그것을 if문을 통해 다시 어떤 생선인지 알려주었습니다.

현재까지는 이진분류에 사용되는 로지스틱 회귀에 대해서 구현해보았는데, 우리는 생선이 7개입니다. 다중 분류에서의 로지스틱 회귀는 어떻게 사용할 수 있을까요?
다중분류 로지스틱 회귀
LogisticRegression()은 기본적으로 반복적인 알고리즘은 사용한다고 합니다. max_iter 매개변수를 1000까지 늘리고(default=100), 계수의 제곱을 규제하는 매개변수 c을 20으로 늘립니다(default=1, 값이 클수록 규제가 완화). test dataset의 상위 5개를 샘플로 하여 예측한 클래스와 각각의 확률, 그리고 선형 방정식을 보겠습니다.
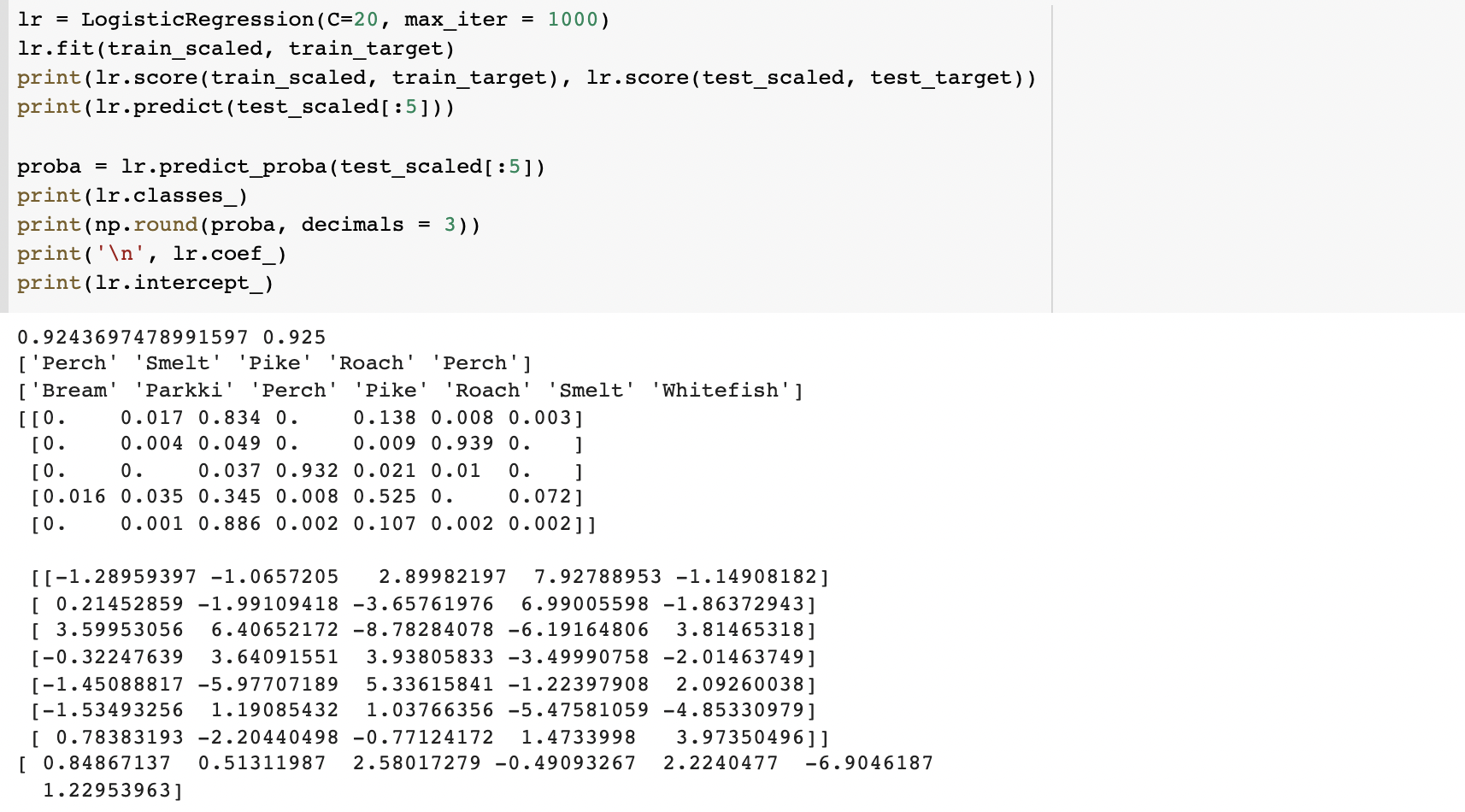 속성이 5개이고 클래스가 7개이므로 엄청난 선형 방정식이 나왔습니다...다중분류에서는 이진분류와 다르게 바로 확률을 알려주었는데요 소프트맥스(softmax) 함수를 사용해서 f(x)를 바로 확률로 변환해줍니다. 소프트맥스는 입력값을 0~1로 모두 매핑해서 출력값의 합이 언제나 1이 되도록 하는 함수로 공식은 다음과 같다.
속성이 5개이고 클래스가 7개이므로 엄청난 선형 방정식이 나왔습니다...다중분류에서는 이진분류와 다르게 바로 확률을 알려주었는데요 소프트맥스(softmax) 함수를 사용해서 f(x)를 바로 확률로 변환해줍니다. 소프트맥스는 입력값을 0~1로 모두 매핑해서 출력값의 합이 언제나 1이 되도록 하는 함수로 공식은 다음과 같다.
softmax 함수의 결과 arr는 (k번째 클래스에 속할 확률)/전체 라고 생각하면 편할 것 같습니다. 시그노이드 함수에서 소프트맥스 함수를 유도하는 것은 다음에 딥러닝 스터디를 쓸 때로 미루겠습니다...(벼락치기의 슬픔)
4-1 확인문제
Q1. 2개보다 많은 클래스가 있는 분류 문제를 무엇이라고 부르나요?
A1. 다중 분류
Q2. 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 사용하는 함수는?
A2. 시그모이드 함수
Q3. decision_function() 출력이 0일 때 시그모이드 함수의 값은 얼마인가요?
A3. 0.5
2. 확률적 경사 하강법
매출이 껑충 뛰어서 다른 생선들도 추가하고 싶다고 합니다. 하지만 아직 데이터셋 샘플이 만들어지지도 않았는데...데이터가 들어올 때마다 추가한다면 데이터가 너무 많아질테고, 들어올 때마다 이전 데이터를 삭제하고 다시 학습시키는 것도 비효율적입니다. 그렇다면 어떻게 할까용?
점진적 학습
0) 경사 하강법(Gradient Descent) : 손실 함수의 기울기를 구하고 기울기의 절댓값이 낮은 쪽으로 계속 이동시켜 극솟값(일때의 x값)을 찾기 위한 방식이다.
* 에포크 : training set을 한 번 모두 사용하는 과정
* step size : 해당 사이즈만큼 방향을 이동시켜가며 극솟값을 찾는다. 너무 작으면 시간이 오래걸리고 너무 크면 극솟값을 찾지 못하고 값이 발산할 수 있다. 1) 확률적 경사 하강법 : 랜덤한 샘플 하나만 골라 극솟값을 찾는 방법이다. -> 데이터셋 개수만큼 돌아야 1epoch
2) 미니배치 경사 하강법 : 여러개의 샘플을 사용하여 극솟값을 찾는 방법 -> 전체/샘플개수 만큼 돌아야 1epoch
3) 배치 경사 하강법 : 모든 샘플을 사용하여 극솟값을 찾는 방법 -> 한 번 돌면 1epoch
배치 경사 하강법은 많은 컴퓨팅 파워를 필요로 하기 때문에 주로 확률적 혹은 미니 배치를 씁니다.
경사 하강법이 손실 함수를 따라서 내려간다고 하였는데 이 손실함수란 무엇일까요?
먼저 손실함수(loss function, cost function...으로 알고 있었음)란 모델을 평가하는 함수 중에 하나로, 정확도는 classification 에서 비연속적인 함수를 보여주기 때문에 미분하여 기울기를 구할 수 없습니다. 따라서 연속적인 값을 받을 수 있는 손실함수를 사용합니다.
손실함수는 classification, regression 에 따라서 다르고 다양합니다. 주로 많이 사용되는 건 Binary cross-entropy(분류), MSE(평균오차제곱, 회귀)로 알고 있습니다.
로지스틱 손실 함수(logistic loss function)
로지스틱 함수처럼 [0, 1]로 결과가 나오는 경우에 사용할 수 있습니다. 다음과 같이 함수를 정의하였습니다. target=1일 때에는 로그를 취해서 -를 붙여준 손실값을, target=0일 때에는 target=1인 것처럼 변환하여 손실값을 구해주었습니다.
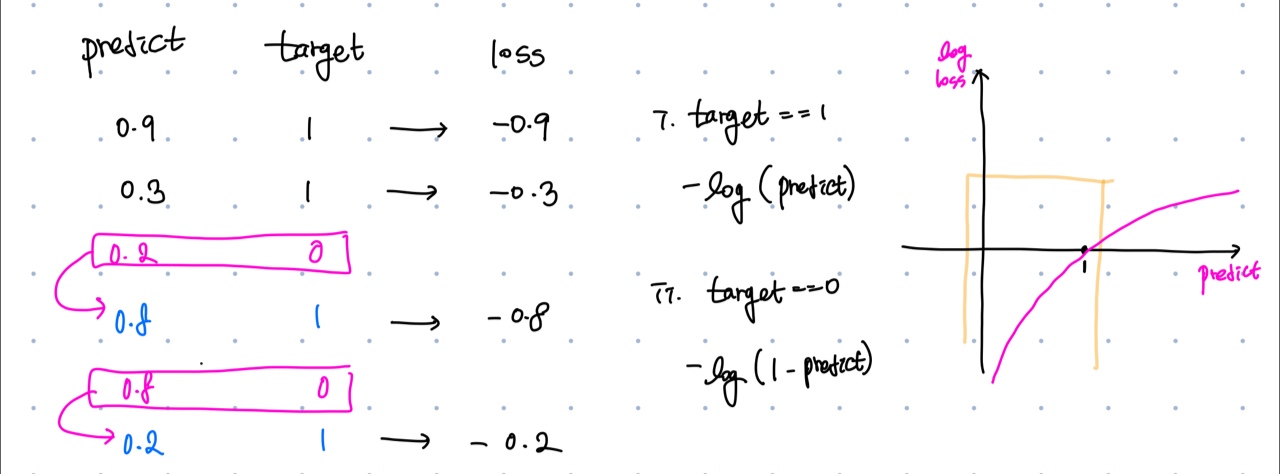
SGDClassifier
Stochastic Gradient Descent로 배치사이즈가 1이다(확률적 경사하강법). 확률적 경사 하강법으로 점진적 학습을 시켜봅시다.
*SGDClassifier의 default loss='hinge(SVM사용)', max_iter=1000이다. 이 챕터에서 자세히 다루진 않음
 정확도가 올라간 것을 알 수 있습니다. 그럼 몇 번이나 돌려야할까요?
정확도가 올라간 것을 알 수 있습니다. 그럼 몇 번이나 돌려야할까요?
에포크와 overfitting/underfitting
에포크가 적으면 적절한 최솟값을 찾지 못했을 수 있으니 underfitting이 일어납니다. 반대로 많은 에포크 동안 훈련한 모델은 training dataset에만 적합한 overfitting일 가능성이 높습니다. 따라서 테스트셋의 점수가 감소하기 시작하는 타이밍에 학습을 조기종료(Early Stopping) 해야합니다.
정확도 plot을 통해 이를 확인해봅시다.
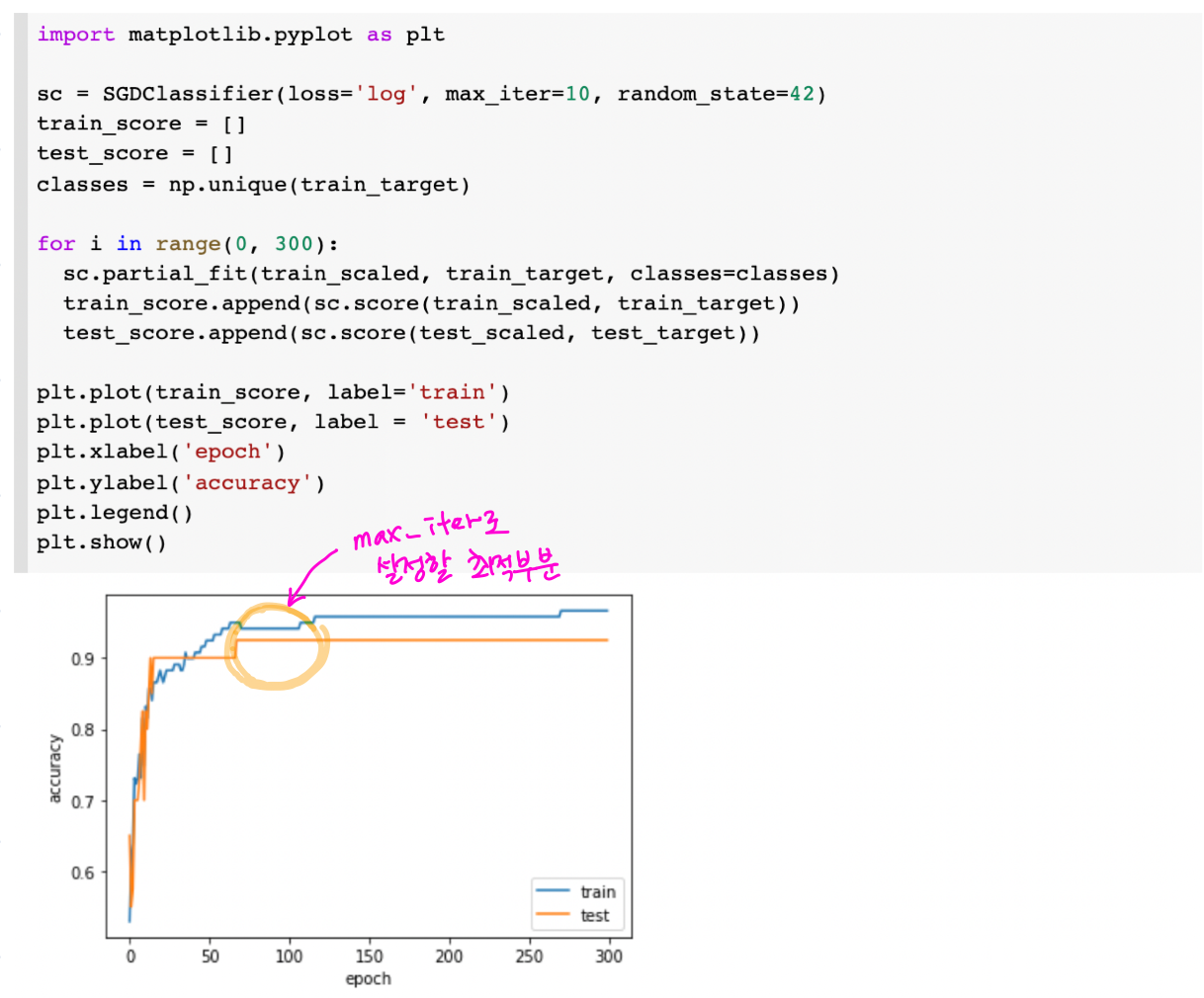 70~100 사이가 가장 적합한 것 같으므로 다음과 같이 정확도를 계산해봅니다.
70~100 사이가 가장 적합한 것 같으므로 다음과 같이 정확도를 계산해봅니다.
확인문제
Q1. 표준화 같은 데이터 전처리를 수행하지 않아도 되는 방식으로 구현된 클래스는?
A1. SGDClassifier
Q2. 경사하강법 알고리즘의 하나로 훈련 세트에서 몇 개의 샘플을 뽑아서 훈련하는 방식은 무엇일까?
A2. 미니 배치 경사 하강법
 연휴가 끝나기 전에 벼락치기를 완료했습니다아아아아ㅏ 한 번 더 출장이 남아있지만...그 때는...그때의 내가 알아서 잘 할 거라고 믿고 설을 즐겨야겠습니다
연휴가 끝나기 전에 벼락치기를 완료했습니다아아아아ㅏ 한 번 더 출장이 남아있지만...그 때는...그때의 내가 알아서 잘 할 거라고 믿고 설을 즐겨야겠습니다(아직 나에겐 3개의 코테문제풀이와 모두의 딥러닝 스터디가 남아있다)
다음주도 화이팅><
