
0. 프롤로그
변명아닌 변명을 하자면 새로운 프로젝트...는 아니고 연구를 기획중이라서 서류들을 쓰느라 바빴습니다(+대전출장). 설 연휴를 맞이하여 아무것도 안하니까 이 때를 틈타 벼락치기로 진도를 다시 따라잡아보려 합니다(족장님 죄송스...)
자 그럼 본론으로 돌아와서,
도미와 빙어를 구분하였지만 이제는 무게를 예측하는 모델이 필요하다. 어떻게 해야할까?
바로 분류(classification)이 아니라 회귀(regression) 모델이다.
아래 내용은 <혼자 공부하는 머신러닝 + 딥러닝>과 숙명여자대학교 소프트웨어학부 <데이터사이언스개론> 수업을 참고하여 작성한 내용입니다.
1. k-최근접 이웃 회귀
k-최근접 이웃 회기
지도학습의 종류 : 분류와 회귀
- 분류 : 샘플을 몇 개의 클래스 중 하나로 분류하는 것
- 회귀 : 샘플을 어떤 특정 값(숫자 등)으로 예측하는 것
- k-최근접 이웃 분류 : 예측하고자 하는 샘플에서 가장 가까운 k개 데이터를 선택하여 그 중 다수의 클래스로 샘플을 예측함.
- k-최근접 이웃 회귀 : 가장 가까운 샘플 k개를 선택하여 해당 속성의 평균을 구함
데이터 준비
농어의 길이와 무게 데이터셋을 가지고 새로운 농어의 무게를 예측해봅시다. 먼저 농어의 길이와 무게를 넣어줍니다.
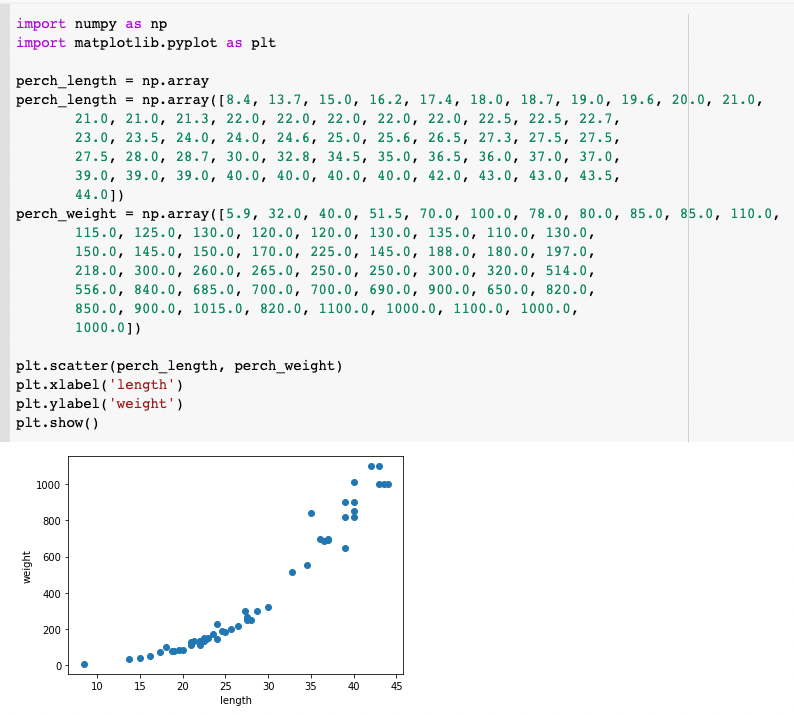 농어도 대체로 우상향 함수 형태를 보이네요. 이제 training set과 test set으로 나누어줍니다.
농어도 대체로 우상향 함수 형태를 보이네요. 이제 training set과 test set으로 나누어줍니다.
단, 주의할 점은 perch_length 가 1차원 배열이었기 때문에 train_input, test_input 모두 1차원 배열입니다. 이를 1개 열 2차원 배열로 바꿔주기 위해서 reshape를 사용합니다. -1은 나머지 원소 개수로 다 채우라는 뜻입니다.

결정계수
k-최근접 이웃 회귀 알고리즘 클래스는 KNeighborsRegressor 입니다. k-최근접 이웃 분류 알고리즘과 비슷하여서 fit()으로 모델을 훈련합니다. score는 '결정계수(coefficient of determination)' 입니다.

으로 계산할 수 있습니다. predict가 target 에 가깝다면(잘 예측했다면) 분자가 0에 가까워지고, 값도 한없이 작아지기 때문에 결정계수가 1에 가까워집니다.
overfitting vs underfitting
만약 훈련 데이터셋들로 score를 계산한다면 어떨까요? 훈련한 데이터로 테스트를 했으므로 거의 1에 가까운 score가 나와야합니다. 하지만 계산해보니까 그렇지 않았습니다. 왜그럴까요?

- 과대적합(overfitting) : 모델이 훈련시킨 데이터셋에만 너무 잘 맞는 모델이라 다른 데이터가 들어와도 제대로 작동하지 않는 경우(훈련셋 평가 점수 >>> 테스트셋 평가 점수)를 말한다. 훈련 데이터셋을 더 general 하게 추가해야한다.
- 과소적합(underfitting) : 모델이 훈련셋으로 평가한 것보다 테스트 셋으로 평가한 점수가 굉장히 높은 경우(훈련셋 평가 점수 <<< 테스트셋 평가 점수). 모델이 너무 단순하여 제대로 훈련되지 않았으므로 훈련 데이터셋을 추가하는 것이 좋다.
현재는 모델이 underfitting이므로 모델을 더 복잡하게 만들어야합니다. 데이터셋을 더 추가하는 방법도 잇지만 k의 개수를 줄여서 예측값을 더 민감하게 만들어줍니다. 결과를 보니, 훈련 데이터셋 평가 점수가 더 높게 나타나서 underfitting 문제는 해결이 되었습니다. test데이터셋 평가 점수가 조금 낮아진 것은 아쉽지만요...

-> k개 이웃들의 평균으로 예측값을 출력해내는데, 회귀 모델 결정 계수로 테스트 셋 평가점수를 구하여 overfitting 이나 underfitting 여부를 알 수 있습니다.
결과보기
농어 5~45cm 일 때 weight를 출력해보자. 그 때 k값을 다르게 해서 하면 어떻게 될까? (확인문제 2)
내용은 다음과 같다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
knr = KNeighborsRegressor()
x = np.arange(5, 45).reshape(-1, 1)
plt.scatter(train_input, train_target)
for i in [1, 3, 5, 7, 10]:
knr.n_neighbors = i
knr.fit(train_input, train_target)
plt.plot(x, knr.predict(x), label='k={}'.format(i))
plt.xlabel('length')
plt.ylabel('weight')
plt.legend()
plt.show()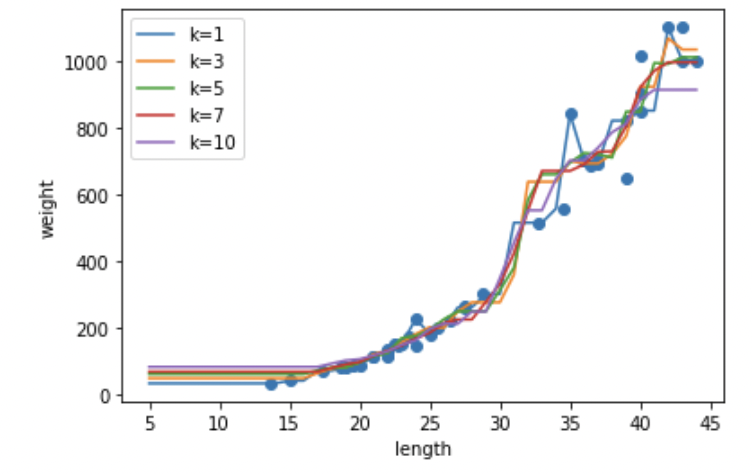
성능 차이가 잘 안보이니까 차라리 점수를 확인해봅시다. k에 따른 score를 모아서(?) 출력해봅시다.
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pyplot as plt
knr = KNeighborsRegressor()
x_test_score = []
x_train_score = []
y_value = []
for i in range(1, 42):
knr.n_neighbors = i
knr.fit(train_input, train_target)
x_test_score.append(knr.score(test_input, test_target))
x_train_score.append(knr.score(train_input, train_target))
y_value.append(i)
plt.plot(y_value, x_test_score, label = 'test_score')
plt.plot(y_value, x_train_score, label = 'train_score')
plt.xlabel('k')
plt.ylabel('score')
plt.legend()
plt.show()
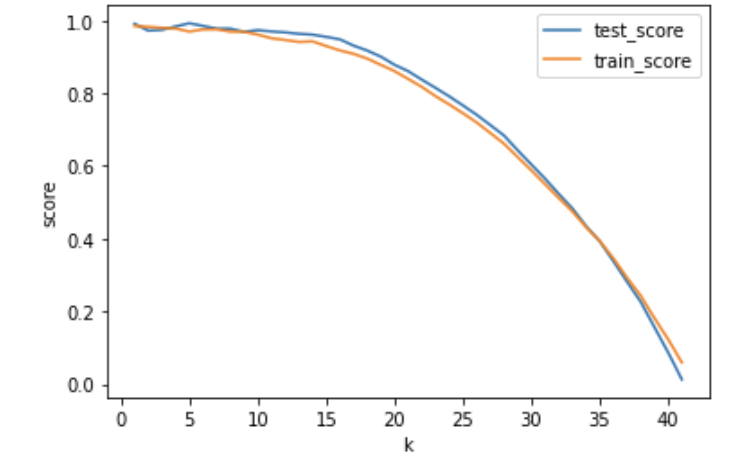
성능이 쭉쭉 떨어지는 것을 확인할 수 있습니다! over/underfitting도 확인할 수 있네요.
여기까지가 간단한(?) k-최근접이웃회귀였습니다.
하지만 k-최근접이웃회귀 같은 경우에는 기존 데이터보다 훨씬 큰 값이 입력되었을 때 k개 가까운 값들의 평균을 내기 때문에 정확한 예측이 어렵습니다.
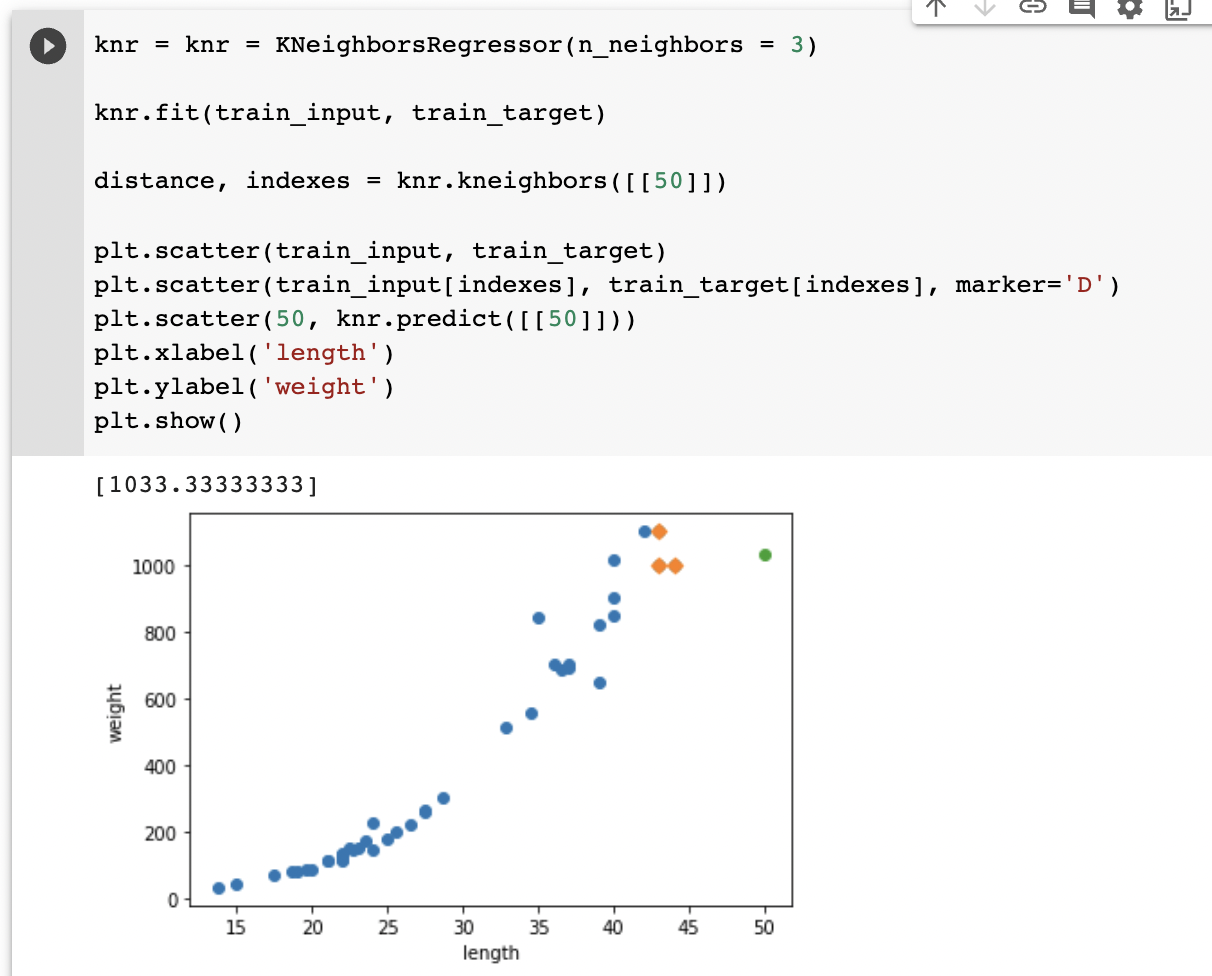 50cm 농어를 넣었을 때 1033g으로 예측하지만 실제 plot을 그려보면 가장 가까운 데이터의 평균으로 예측하기 때문에 실제 50cm 농어의 무게보다 작게 예측할 것입니다. 1000cm을 넣어도 마찬가지일 것입니다. 이런 문제를 해결하기 위한 방법으로 선형회귀(linear regression) 가 있습니다.
50cm 농어를 넣었을 때 1033g으로 예측하지만 실제 plot을 그려보면 가장 가까운 데이터의 평균으로 예측하기 때문에 실제 50cm 농어의 무게보다 작게 예측할 것입니다. 1000cm을 넣어도 마찬가지일 것입니다. 이런 문제를 해결하기 위한 방법으로 선형회귀(linear regression) 가 있습니다.
2. 선형 회귀
선형 회귀
을 최소화하는 objective 를 사용하는 회귀 방식이다. 단점은 outlier 때문에 함수가 왜곡되기 쉽다. 데이터의 특성을 가장 잘 보여주는 1차 함수를 찾아내고 이것은 LinearRegression 클래스로 구현되어 있다.
이것으로 50cm 짜리 농어의 무게와 그 함수까지 찾아보자. 1차함수의 기울기를 여기서는 coef, intercept 라 한다고 합니다. 최소길이인 8부터 60까지로 그려보고 그 형태가 농어의 특성을 잘 보여주는지, 해당 함수 위에 50cm짜리 농어의 무게가 있는지 확인해봅시다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
perch_length = np.array
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([[50]]))
plt.scatter(train_input, train_target)
plt.plot([8, 60], [8*lr.coef_ + lr.intercept_, 60*lr.coef_+lr.intercept_])
plt.scatter(50, lr.predict([[50]]), marker='^')
plt.show()
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))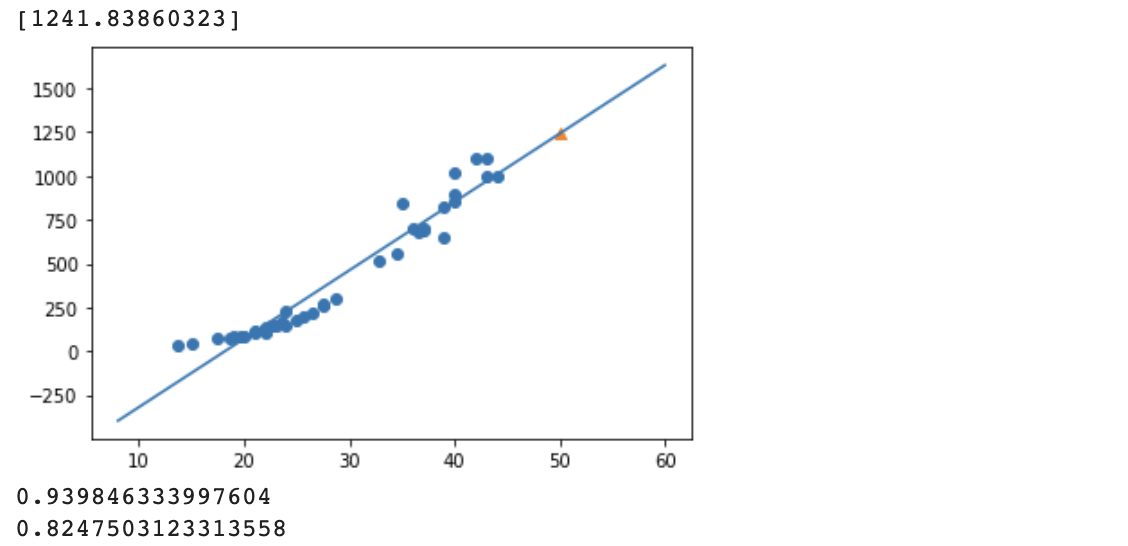
train이 test score보다 많이 크지만, 애초에 train dataset score도 그렇게 높지 않습니다. 그리고 애초에 plot에 20cm 미만인 농어들은 마이너스 무게입니다. 이게 가능하려면 헬륨풍선처럼 농어들이 공중에 떠다녀야 합니다... ㄴㅇㄱ
선형회귀보다는 n차 Object 함수를 찾아야할 것 같습니다.
다항회귀
다항회귀 train data set을 만들기 위해서는 제곱을 한 input을 속성으로 추가해주어야합니다. 예측을 할 때에도 길이의 제곱과 길이를 모두 넣어주어야합니다.
train_poly = np.column_stack((train_input**2, train_input))
test_poly = np.column_stack((test_input**2, test_input))
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
print(lr.coef_, lr.intercept_)
point = np.arange(0, 60)
plt.scatter(train_input, train_target)
plt.plot(point, lr.coef_[0]*point**2 + lr.coef_[1]*point+lr.intercept_)
plt.scatter(50, lr.predict([[50**2, 50]]))
plt.show()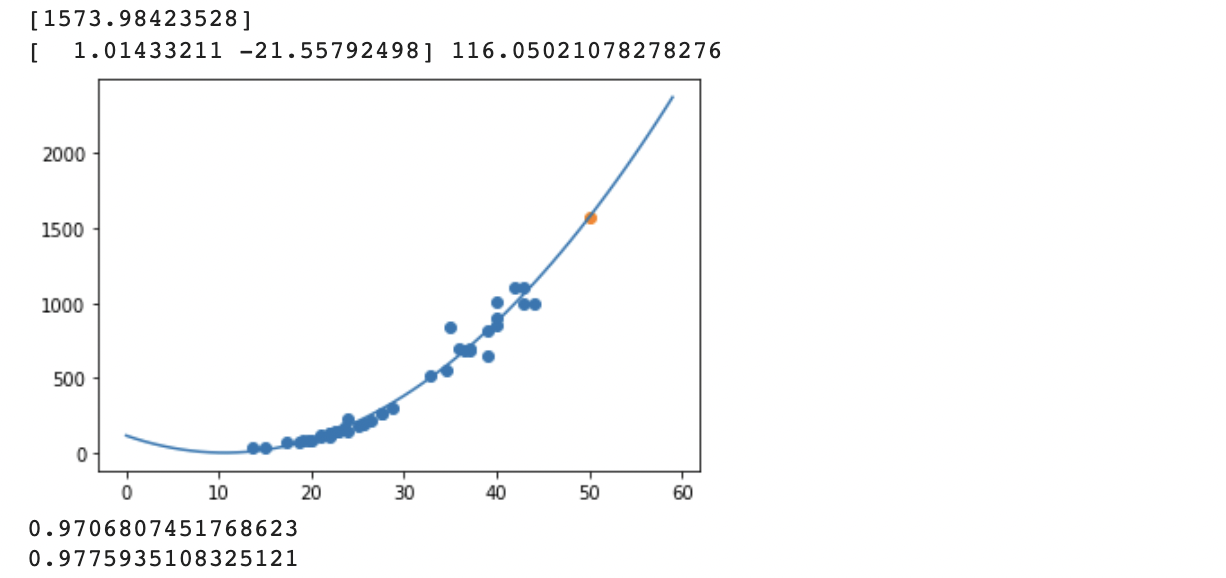
성능이 훨씬 향상된 것을 볼 수 있습니다! 하지만 좀 더 높일 수 없을까요...?
3. 특성 공학과 규제
여러가지 특성을 사용한다면(속성을 추가한다면) 더 정확한 예측이 가능하지 않을까요? 길이 외에도 농어의 높이, 두께까지 안다면 두 가지 특성으로 조금은 복잡하지만 정확도 높은 모델을 만들 수 있을 것입니다!
다중 회귀(Multiple Regression)
n개의 특성을 축으로 n차원 모델을 학습한다고 생각하면 좋을 것 같습니다. 우리는 2개 이상의 특성에 대해서는 상상하기 어렵지만 Euclidean Distance 기반인 것을 알기 때문에 수학적으로는 충분히 가능합니다.
 (예시. 출처 : Mathworks 'regress' Document https://www.mathworks.com/help/stats/regress.html)
(예시. 출처 : Mathworks 'regress' Document https://www.mathworks.com/help/stats/regress.html)
고차원에서는 선형 회귀가 복잡한 모델을 표현할 수 있기 때문에 직선, 평면을 생각하고 무시하면 안됩니다. 기존의 데이터로 새로운 데이터를 뽑아내는 작업(특성공학, feature engineering)을 하는 것입니다.
높이, 두께 데이터를 추가하여 다중회귀를 구현해봅니다.
 underfitting 은 피한 것 같습니다. 클래스를 선언할 때 degree를 지정해줌으로써 특성을 여러개 만들 수 있으나, 이것은 overfitting으로 가는 지름길입니다. 적절한 특성을 구성하는 것이 중요합니다!
underfitting 은 피한 것 같습니다. 클래스를 선언할 때 degree를 지정해줌으로써 특성을 여러개 만들 수 있으나, 이것은 overfitting으로 가는 지름길입니다. 적절한 특성을 구성하는 것이 중요합니다!
규제(regularization)
훈련 데이터에 overfitting 되지 못하도록 하는 것입니다. 선형 회귀 모델의 경우, coef를 작게 만든다고 합니다. StandardScaler()를 통해 구현해보도록 합니다. 그 중에서도 선형 회귀 모델에 규제를 추가한 모델인 릿지와 라쏘를 사용해봅시다.
릿지 회귀(Ridge Regression)
릿지 회귀는 다음 기회에 증명해볼 수 있었으면 좋겠습니다. 일단 따라해봅시당
 책이랑 test dataset 스코어가 다르게 나왔지만 일단 과대적합은 아닌 것 같습니다. 릿지와 라쏘 모델에서는 알파값으로 성능을 조절할 수 있는데, 알파값이 0에 가까울수록 별 효과를 못냅니다. 그럼 알파값에 대해서 스코어를 구해볼까요
책이랑 test dataset 스코어가 다르게 나왔지만 일단 과대적합은 아닌 것 같습니다. 릿지와 라쏘 모델에서는 알파값으로 성능을 조절할 수 있는데, 알파값이 0에 가까울수록 별 효과를 못냅니다. 그럼 알파값에 대해서 스코어를 구해볼까요
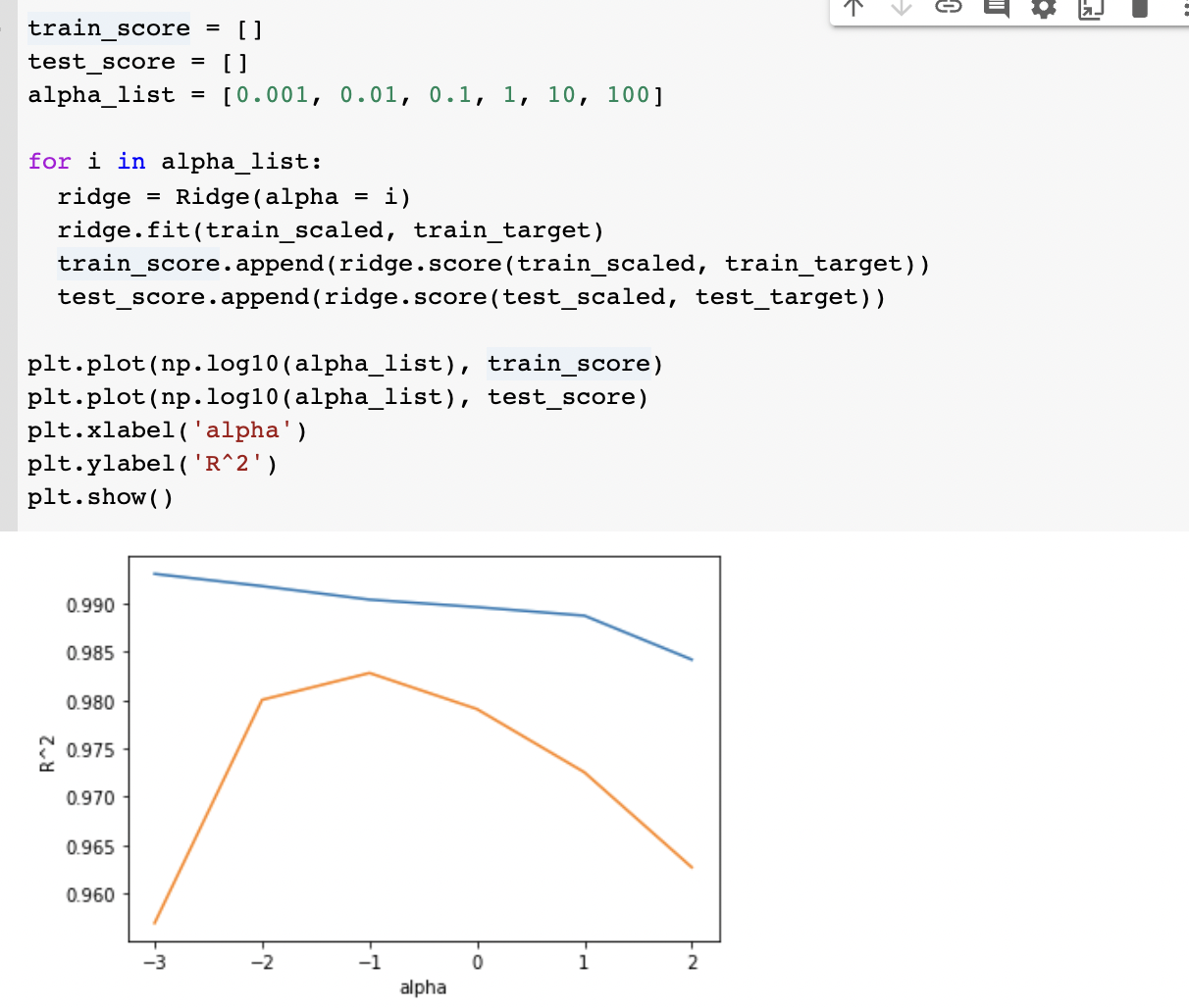 가장 적절한 alpha값은 0.1이군요! 그래프 개형이 책과 다르게 나오길래 위에서부터 쭈욱 살펴보니 제가 Poly degree를 다시 default인 2로 바꿔둬서 그랬네요. regulization은 poly를 많이 했을 때만 사용하는 것인지 좀 더 공부해볼 필요가 있을 것 같습니다.(degree=2 일 때 ridge 를 쓰면 alpha=100에서 성능이 급격히 감소함)
가장 적절한 alpha값은 0.1이군요! 그래프 개형이 책과 다르게 나오길래 위에서부터 쭈욱 살펴보니 제가 Poly degree를 다시 default인 2로 바꿔둬서 그랬네요. regulization은 poly를 많이 했을 때만 사용하는 것인지 좀 더 공부해볼 필요가 있을 것 같습니다.(degree=2 일 때 ridge 를 쓰면 alpha=100에서 성능이 급격히 감소함)
라쏘 회귀(Lasso Regression)
라쏘 클래스도 사용해봅시다.
 과대적합이나 과소적합이라고 보기는 어려운 수치들이 나왔습니다(오예)
과대적합이나 과소적합이라고 보기는 어려운 수치들이 나왔습니다(오예)
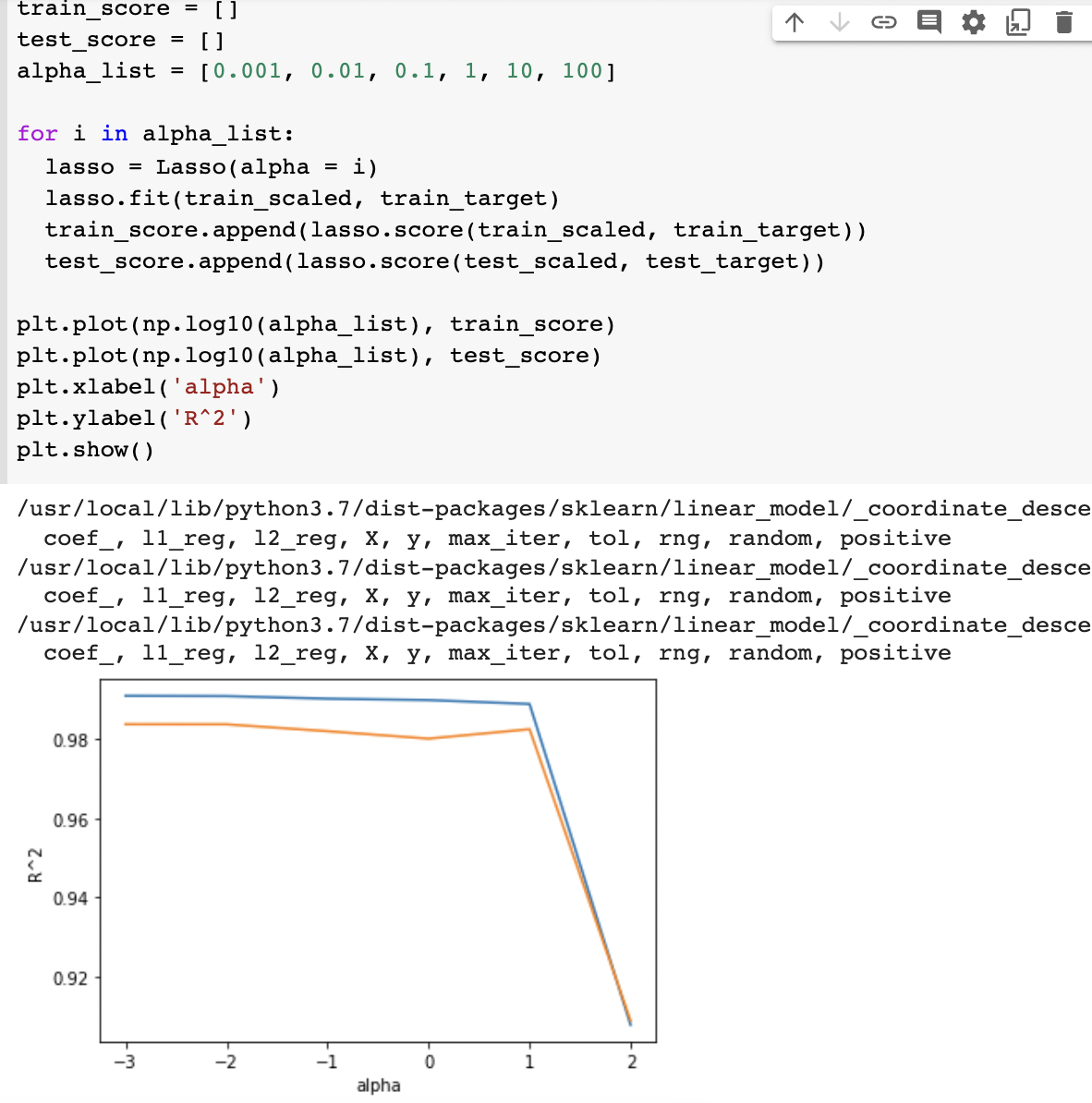 실제로 alpha=10일 때 가장 성능이 좋은 것 같습니다. 라쏘에서는 모델의 계수를 0으로 만들어서 유용한 특성들만 골라낼 수도 있습니다.
실제로 alpha=10일 때 가장 성능이 좋은 것 같습니다. 라쏘에서는 모델의 계수를 0으로 만들어서 유용한 특성들만 골라낼 수도 있습니다.
릿지와 라쏘 모델은 수학적으로 검증을 해보는 것도 좋을 것 같습니다. 뒤로 갈수로 한 챕터가 길어질 것 같은 느낌이 드네요. 출근할 때보다 설 연휴가 더 여유로워서 벼락치기(?)로 챕터4까지 달려보려고 합니다. 모두들 화이팅><
