
📖 학습한 내용
📖 핵심내용
📌 인공지능이란 무엇인가?
-
인공지능 종류
딥러닝, 머신러닝, 롤베이스 기반 서비스
-> 머신러닝 딥러닝 뿐만이 아니다 -
머신러닝이란?
데이터를 통해서 모델이 학습을 하고 결과를 도출하는 것 -
딥러닝이란?
사람의 뇌를 모티브로한 모델
데이터 관련 이론은 있었는데 gpu가 발전하면서 급속도로 더욱 발전하기 시작했다.
📌 머신러닝이란?
머신러닝
1. 지도학습
-> 정답이 포함되어있음
- 분류 - 클래스로 나뉘어지는것
ex) 고양이 표범 호랑이 사진 학습해서, 새로운 고양이과 사진 정답으로 분류하기
- 회귀 - 어떤값이 있을때 다음 값을 예측하는 것 - 시계열 관련
2. 비지도학습
-> 정답이 없다. 데이터를 뿌려넣고 서로 비슷한 특성끼리 묶어주는 것.
-> 현업에서는 보통 많이 쓰지 않는 것 같다.
- 강화학습
-> 정답이 있는데, 범위형 목표가 있다.
📌 데이터의 종류?
- 정형데이터
- Tabular data - 데이터 테이블에 잘 정리가되어있는 것
- 예시 인사과 데이터로, 어떤 사람이 퇴사할지 안할지 예측
- 비정형데이터
- 텍스트
- 메뉴얼 작성 - 이미지
- 패트병 분리수거 자판기 - 영상
- 멧돼지 객체인식 - 음성
- 아이 목소리로 니즈판별
📌 프로세스
- 문제 파악 및 목표 설정
- 데이터 수집 및 전처리
- AI 모델 적용
- 결과분석
📌 TM & PIC
teachable machine
가위 바위 보 한번 해봤다.
-
수행 목표
지도학습의 분류 -> 플라스틱 분류

분류해보자 -
프로세스
- 데이터수집
- 모델 학습
- 디자인
- 블록코딩
- classifier 사용
모바일넷
많은 층을 쌓아서 만든 모델이다.
CNN 모델이 이미지 모델은 모두 평정했다.
- 특정필터로 특정 부분만 본다는 아이디어
- 사람보다 이미지 잘맞춘다
hyperparameter -> 사람이 지정해줘야하는 값
한번 전체를 학습하면 1 Epochs
정답하고의 거리 -> 로스트펑션
로스트 펑션으로 나온 정답이 가까워지게하는 펑션이 optimizer-Adam
정답에 가까워지는 보폭을 learning rate
traning data fraction : 들어오느 학습 데이터 중 얼만큼 테스트 데이터로 넘길 것인지. 보톤 전체량의 20%~30%
📌 앱인벤터 - 앱 만들어보기
플라스틱 종류 구분해보기
디자인
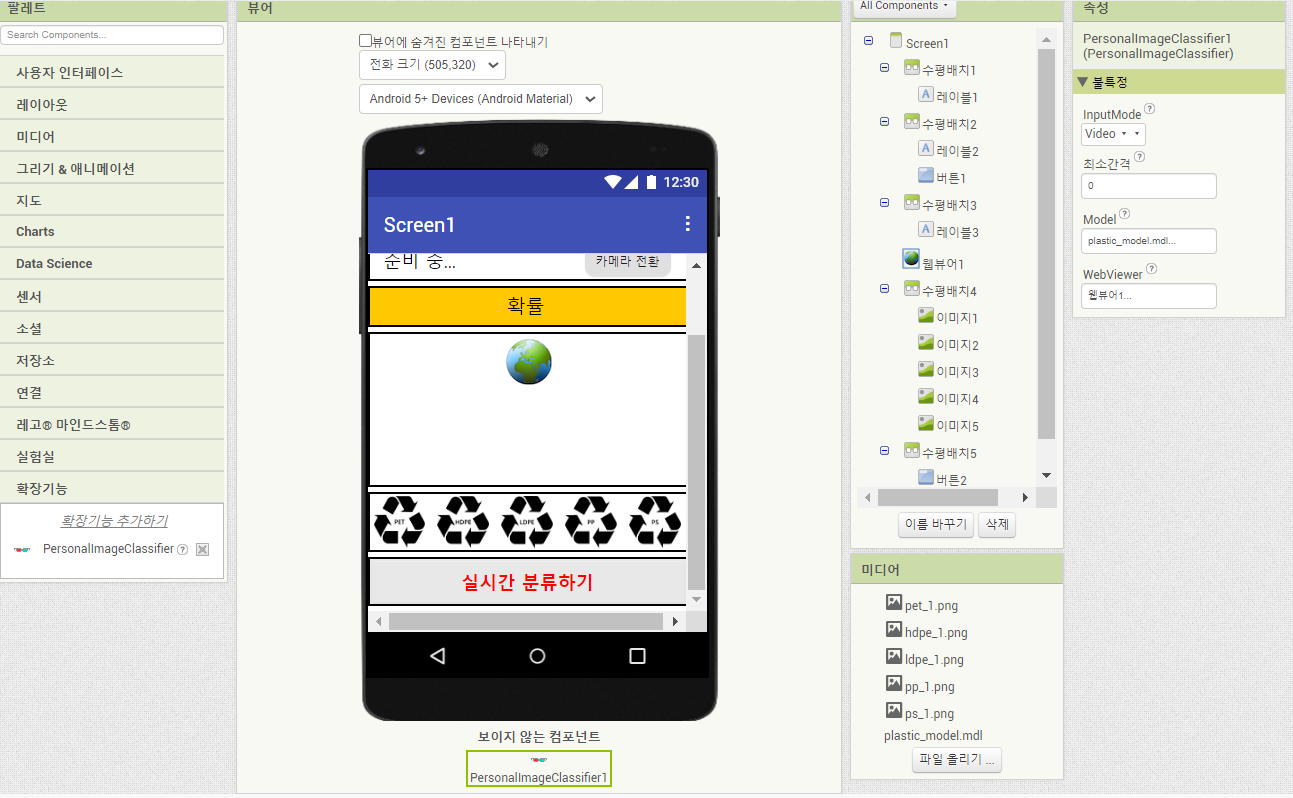
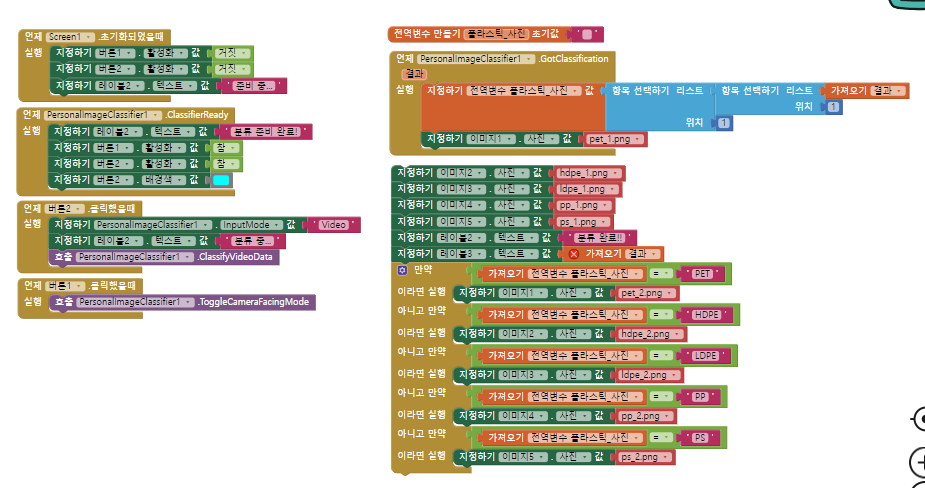
블록코딩
📌 지도시각화
folium : 파이썬에서 사용할 수 있는 지도 시각화 라이브러리
프로세스
- csv파일 -> DF 생성
- 위도 경도 정보가 담긴 json 파일 load
-> 예시에는 id 키에 구의 이름 값이 담겨져있었다. - folium.Map 위도 경도 입력하여 구글 맵 불러오기
- folium.Choropleth
-> 제이슨파일의 데이터를 가져오고 영역을 그린다. 이때 데이터를 받아서 값의 크기에 따라 색상을 달리한다. 불러온 구글 맵 위에 추가하여 표기한다.
예시
df = pd.read_csv(r"E:\est\map_vison\busan.csv",
encoding='cp949',
index_col=0)
geo_path = r"E:\est\map_vison\busan_gu.json"
geo_str = json.load(open(geo_path, encoding='utf-8'))
map=folium.Map([35.179665, 129.0747635], zoom_start=10)
map=folium.Map([35.179665, 129.0747635], zoom_start=10)
folium.Choropleth(geo_data = geo_str,
#data = df['population'],
fill_color = "PuBu",
key_on = "feature.id",
legend_name = "부산 인구 수 (단위 : 명)").add_to(map)
map📖 흥미로운 점 / 새로 알게된 점
-
절대 테스트 데이터는 학습데이터로 구성하면 안된다. 모델의 성능을 테스트하려면 무조건 새로운 것 데이터를 사용해야한다.
-
서로 같은 데이터를 넣었는데, 다른 결과가 다르게 나온다.
-> 가중치 설정을 할 수 없기에, 여기서는 랜덤하게 주어졌기 때문에 모델이 다르게 나온 것이다. -
데이터를 받아오면 어떤 종류의 데이터인지 파악부터하는게 중요하다. 단위 따위 놓치지 말자.
-
key_on : 지리정보와 시각화정보의 공통변수로서 'feature.id'를 설정
load/loads
📖 어려운 부분
- 과제를 하면서 더 좋은 정답을 찾아봤다. 이때 사람들은 리스트 컴프리헨션 사용해서 정답을 풀고 있었다. 표현이 매우 간결하여서 관심이 갔다. 그리고 이게 for문 배울 때 분명 배웠던 것으로 기억이 났다. 그런데 구문이 이해가 안되서 인터넷으로 더 찾아봤다.
[i['properties']['name_eng'] for i in geo_str['features']]
-> 결론적으로 하나의 새로운 리스트를 만드는 구문이다. i로 받은 각각의 원소가 새롭게 연산되어서 리스트에 하나씩 들어가는 표현이였다. for문을 굳이 한줄로 써야하나, 하고 넘어간게 실수였다. 유용하게 써야겠다.
📖 이후 학습 계획
- 붓꽃 판별 모델
📖 기타
- 과제
-
geo_str에서 name_eng를 수집하여 df에 "gu_eng"의 열을 만드시오.
-> for 문을 사용하여 json 데이터에서 영어 관련 딕셔너리를 찾아서 벨류값을 담은 리스트를 만들었다.
이후 새로운 컬럼을 선언 -
부산 구별 인구 밀도를 계산하여 df에 "density"열을 추가하고 인구 밀도 값을 추가하시오.
-> 인구 컬럼 / 면적 컬럼 한값을 신규 컬럼에 담았다. -
인구 밀도에 따른 구별 Choropleth를 그리시오.
map = folium.Map([35.179665, 129.0747635], zoom_start=10)
folium.Choropleth(geo_data=geo_str,
data=df['density'],
fill_color='PuOr',
key_on='feature.id',
legend_name = '부산 구별 인구 밀도 (단위 : 명/㎢)'
).add_to(map)
map