
📖 학습한 내용
- HR 데이터로 퇴직자 예측
- 수치데이터(numerical data)
- 범주데이터(categorical data)
- 이상치 해결
- 데이터 타입 변경과 특성 생성
- 타이타닉
📖 핵심내용
📌 HR 데이터로 퇴직자 예측
수치 데이터 (numerical data)
평균 중간값 등의 통계량을 낼 수 있다.
결측치를 통계량으로 채워줄 수 있다.
- 수치 데이터 항목
num_companies_worked, last_year_salary, salary, working_hours
범주 데이터 (categorical data)
명목데이터 (nominal data), 순서데이터 (ordinal data)
명목 데이터 (nominal data), 순서데이터 (ordinal data)
순서가 없다.
- 결측치는 새로운 항목으로 채워주는 방법이 있다.
marital_status
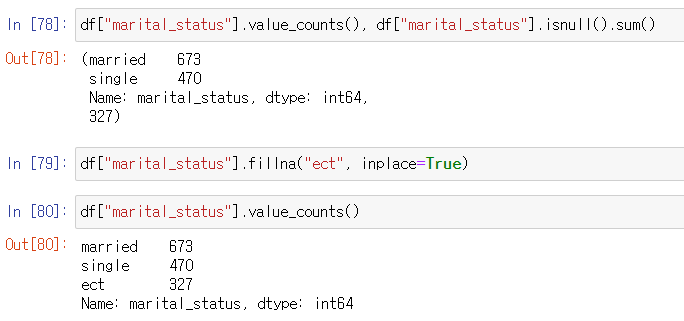
-> 결측치가 ect로 채워진 것을 알 수 있다.
이상치 해결
이상치를 찾아서 해당 index를 알아내고 drop을 행을 이용해 제거한다.
데이터프레임객체.drop(이상치를가진행인덱스, inplace=True)
boxplot()
matplotlib 의 일부
- 박스플랏의 의미
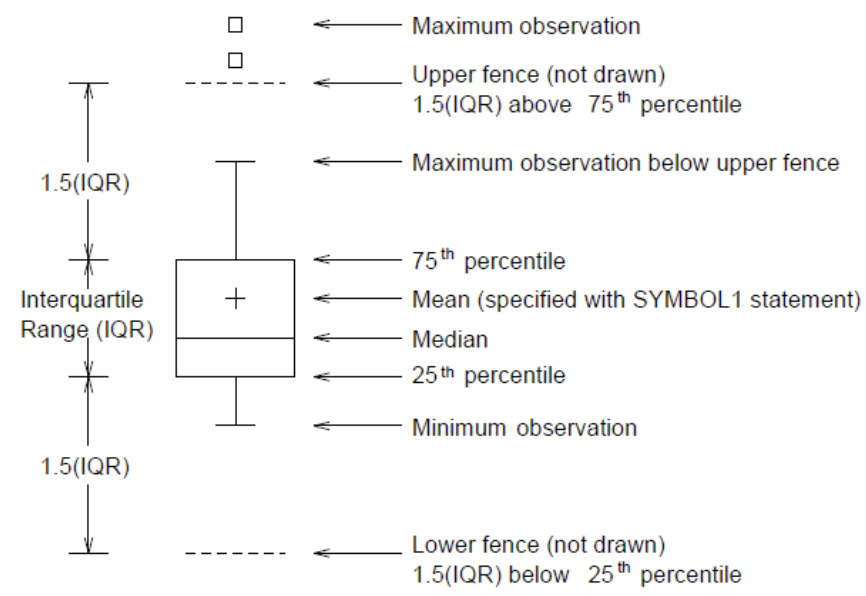
- 구성
boxplot([데이터1, 데이터2...]), set_xticklabels([이름1, 이름2...])
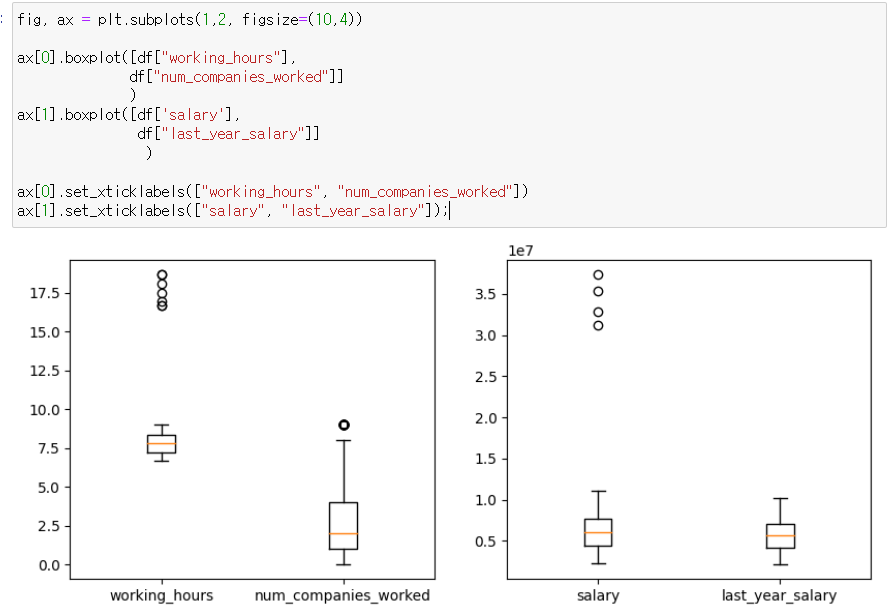
-> working_hours 값이 이상치 발견
IQR
np.quantile() 함수를 이용한다.
q_1 = np.quantile(df["num_companies_worked"], 0.25)
데이터 타입 변경과 특성 생성
-
numerical
- birthday -> age / 생일을 나이로 바꿔서 수치형데이터로 변경!
- entry_year -> years_at_company / 입사일을 근속년수로 바꿔서 수치형데이터로 변경!
- salary&last_year_salary -> salary_inceasing_rate / 두개의 피처가 들어가므로 비율로 변경!
-
categorical ordinal -> values / 순서형 범위 데이터는 값으로 변경!
- performance_rating
- job_satisfaction
-
categorical nominal -> one-hot encoding / 명목형 데이터는 원핫인코딩!
- department
- marital_status
- attrition
📖 흥미로운 점 / 새로 알게된 점
-
msno.matrix(df);
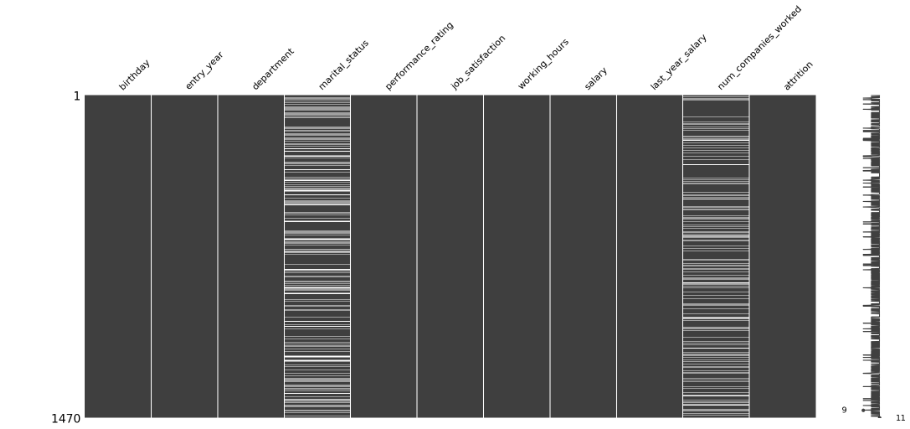
-> 센서와 연결하면 바로바로 동작을 시각적으로 알 수 있다. -
DF객체.isnull().sum()
DF의 결측치의 목록과 개수를 바로 알 수 있다. -
a.union(b)
a와 b를 중복없이 하나로 합친다.
두개의 컬럼을 가져와서 |로 합치려고하니, 앞으로 | 사라진다고 경고가 뜬다. union을 왠만하면 쓰자! -
평균값과 중앙 값이 크게 다르지 않다면 분포가 비슷한 것이고 NaN값을 중앙 값으로 채울 수 있다.
-
np로 평균값을 구하는 것은 NaN값을 제외하고, 중앙값은 NaN이 나온다. 모듈에 포함된 mean()과 median()은 NaN을 제외하고 한다
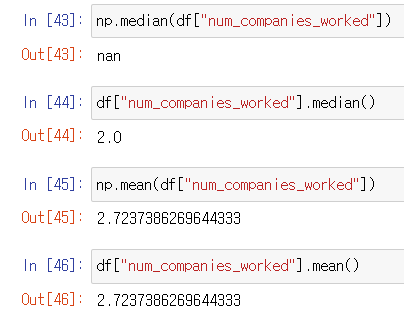
-
결측치와 이상치를 해결하는 정확한 방법은 없다. 다만 도메인의 지식을 가지고, 결측치를 어떻게 채우는 것이 맞을지, 정말 이 값이 이상치인지에 대해 판단하는 것이 데이터 분석의 실력이다.
-
데이터를 수치로 바꾸는 아이디어가 매우 중요하다.
날짜 관련된 값은pd.to_datetime(, format="%Y-%m-%d")로 데이터타입을 datetime으로 변경 후에 년DF객체.dt.year/ 월DF객체.dt.month/ 일DF객체.dt.day/ 요일DF객체.dt.day_name
-
범주형 데이터에서 순서형 데이터는 점수와 같이 값으로 변환시킨다.
피처.value_counts()를 이용하여 종류를 확인하고 종류에 맞게 숫자를 딕셔너리형식으로 지정해준다.level= {'종류1' : 점수1, '종류2' : 점수2....}이후피처.replace(level)로 바꿔준다. -
one-hot encoding에서
pd.get_dummies()을 사용한다.
피처의 값에 따라서 하나의 새로운 피처를 만들어준다.
pd.get_dummies(df[["department", "marital_status"]],
prefix=["dep", "ms"],
prefix_sep="+",
)- 범주형 데이터에서 순서형 데이터가 yes/no 같이 두개로 나눠지는 것은 1,0 숫자 값으로 바꿔준다
get_dummies() 사용하여서 처음 것을 드랍시키면 된다.
df["attrition"] = pd.get_dummies(df["attrition"], drop_first=True)
📖 어려운 부분
- 어떤 문제가 파악하는지 그래프를 그리면서 확인해야하는데,
그래프 그리는 실력이 너무 부족해서 타이타닉과제에서 뭘 분석해야할지 파악하기 힘들다.
📖 기타
- 느낀점, 응시한 테스트, 퀴즈, 과제
