
📖 학습한 내용
- 데이터를 시각화 이유
- matplotlib 다양한 그래프
- seaborn 다양한 그래프
📖 핵심내용
📌 데이터를 시각화 이유
- 데이터 전처리에 도움(보통 전처리 과정과 동시에 진행)
- 본격적인 분석을 하고 모델을 만드려면 가정이 필요한데, 데이터를 더 잘 이해하여 그 가정을 세우는 데에 도움을 줌
- 최종 결과를 효과적으로 표현, 전달
- 데이터의 기본적인 상태 확인: 통계량, 결측치, 이상치(outlier) 등 확달
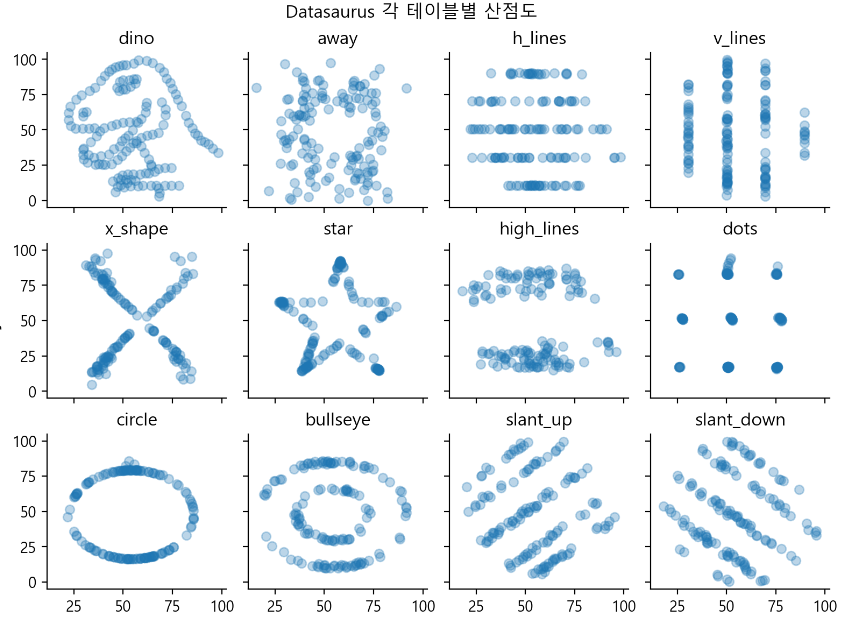
-> 모두 평균과 분산이 같지만 아예 다른 형태이다! 따라서 그려봐야 정확히 알 수 있다.
📌 matplotlib 다양한 그래프
x,y의 데이터로 들어갈 수 있는 자료형 : list/tuple, 넘파이 배열, 시리즈, 데이터프레임 피처, range
기본 시작 형태
fig, ax = plt.subplots(차원,figsize=(크기))
객체.그래프종류(x데이터, y데이터, 라벨) # 그래프 자체에 관련
객체.set(xlabel, ylabel, title, aspect) # 그래프 축에 관련-
plot()
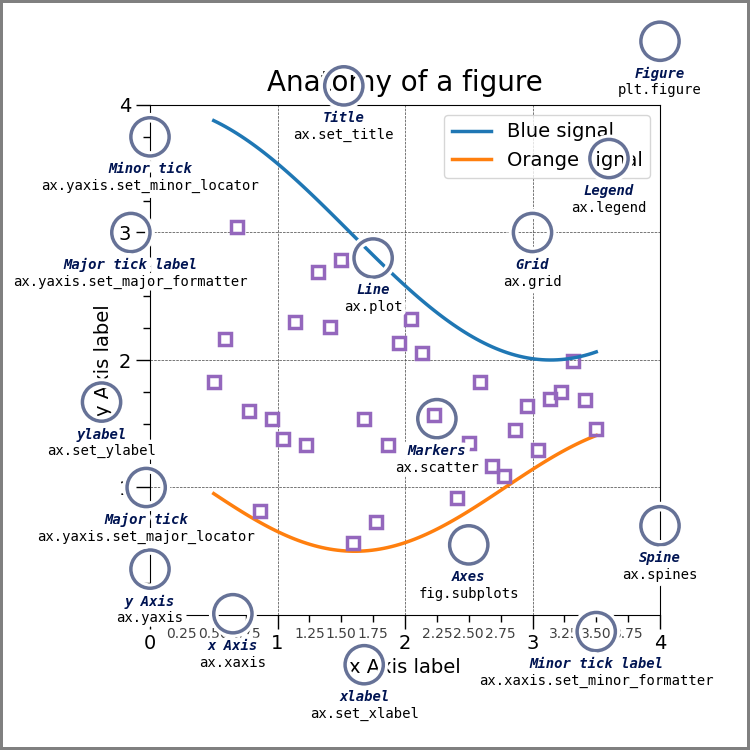
출처 : https://matplotlib.org/stable/gallery/showcase/anatomy.html
-
scatter()
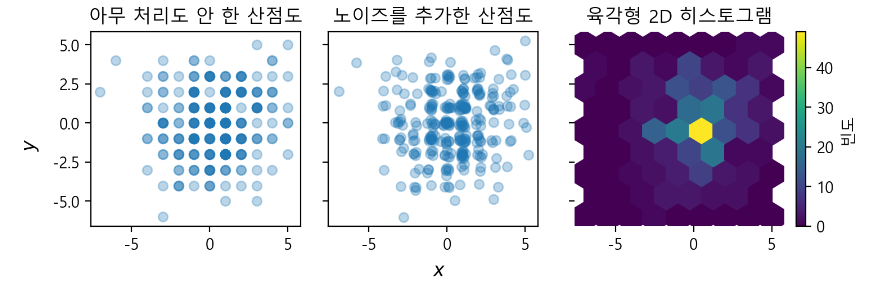
- 선점도 표현시 겹치는 문제가 발생하면
1) 노이즈를 살짝 추가하여 가리지 않게한다.
2) 적합하지 않으므로 아예 다른 그래프를 택한다
3) 겹친 정도에 따라 밝아지는 육각형 2D히스토그램을 그린다
- bar()/barh()
- hist()
- 히스토그램과 막대그래프차이
히스토그램은 끊어지지 않고 옆에 데이터와 붙어있다.
막대그래프는 떨어져있을 수 있다
막대그래프는 항상 0부터 시작한다.
- boxplot()
데이터 분포의 사분위값과 이상치(보통 1.5 IQR 기준)를 표현한 그래프
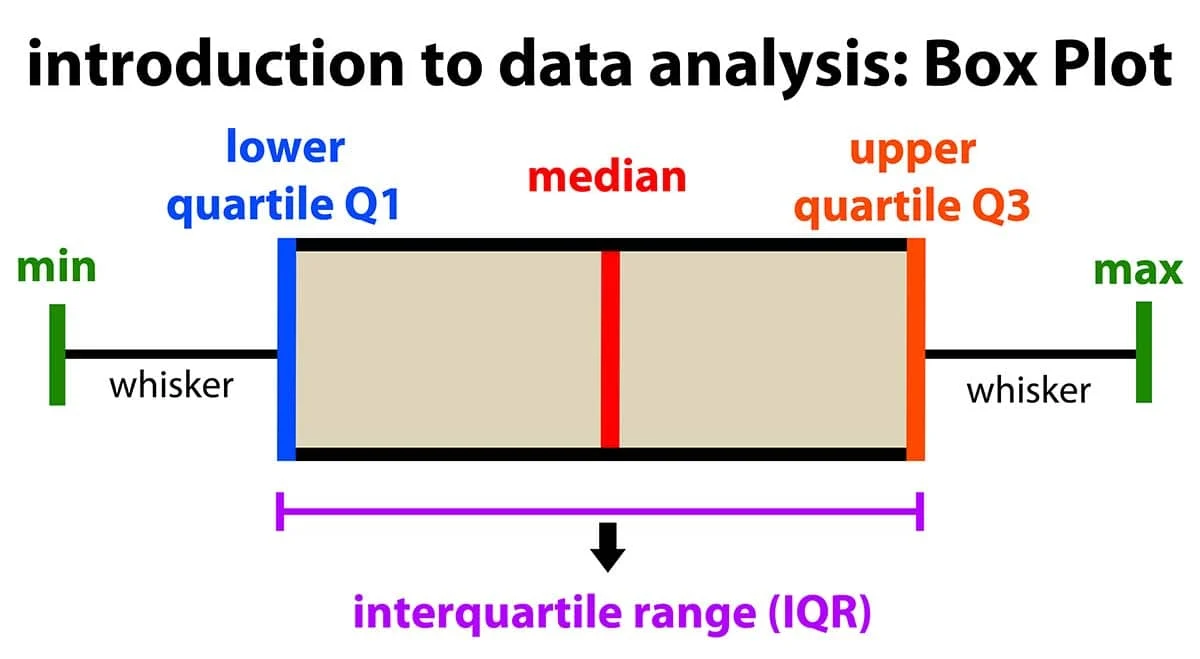
객체.boxplot(x데이터, labels=라벨데이터)
6. 색상선택 - 히트맵
📌 seaborn - matplolib
- 바이올린플랏 violinplot()
기본 형태 :
sns.violinplot(data=데이터프레임, x=컬럼, y=컬럼, ax=ax)
- 객체 지향 방식으로 그려 그래프 수정
1) collection의 정보 알기
2) ax.lines 정보알기``` for i, obj in enumerate(ax.collections): if i > 1: obj.set_ec(color[0]) obj.set_fc(color[1]) obj.set_lw(1) obj.set_sizes([30])``` if i == 3: line.set_color(color[2])
📖 흥미로운 점 / 새로 알게된 점
- 유용한 그래프 성능 향상 세팅 코드
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib_inline.backend_inline
# 그래프의 폰트 출력을 선명하게 (svg, retina 등이 있음)
matplotlib_inline.backend_inline.set_matplotlib_formats("png2x")
# 테마 설정: "default", "classic", "dark_background", "fivethirtyeight", "seaborn"
mpl.style.use("default")
# 이미지가 레이아웃 안으로 들어오도록 함
# https://matplotlib.org/stable/users/explain/axes/constrainedlayout_guide.html
mpl.rcParams.update({"figure.constrained_layout.use": True})- 한글과 마이너스 깨짐 해결 코드
plt.rc("font", family = "Malgun Gothic")
plt.rcParams["axes.unicode_minus"] = False-
객체 지향형으로 그려야지 디테일하게 그릴 수 있다.
시작을 항상객체.plot()과 같은 형태로하자. -
zip는 각 이터러블에서 동일한 인덱스에 있는 요소들을 하나씩 추출하여 튜플로 묶어주는 방식으로 작동한다.
fig, ax = plt.subplots(figsize=(4, 4))
for s, c in zip(iris["Species"].unique(), ["tab:orange", "tab:blue", "tab:green"]):
ax.scatter(iris[iris["Species"] == s][feature_x],
iris[iris["Species"] == s][feature_y],
color=c,
alpha=0.7,
label=s)
ax.set(xlabel=feature_x,
ylabel=feature_y,
title="Species를 마커 색으로 표현")
ax.legend();-> 인덱스가 동일하면 요소를 하나씩 출력한다.
-
선점도에서 마커 사이즈 :
plt.rcParams["lines.markersize"] -
그래프 옆쪽에 컬러맵 띄우기 :
colorbar = fig.colorbar(pc, label=feature_additional) -
그래프의 경계선 없애기 :
ax.spines[["top","bottom", "right", "left"]].set_visible(False) -
seaborn 사용시 더 깔끔하게 그래프 표현하기
#font, line, marker 등의 배율 설정: paper, notebook, talk, poster
sns.set_context("paper")
#배색 설정: tab10, Set2, Accent, husl
sns.set_palette("Set2")
#눈금, 배경, 격자 설정: ticks, white, whitegrid, dark, darkgrid
# withegrid: 눈금을 그리고, 각 축의 눈금을 제거
sns.set_style("whitegrid") 📖 기타
과제
타이타닉 데이터 전처리 및 그래프 그리기
데이터 확인
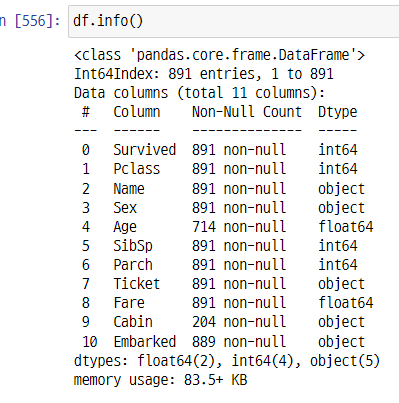
-> Age, Cabin, Embarked 결측치 확인

-> 결측치 시각화
수치형데이터 / 범주형데이터 - 명목데이터 / 순서데이터 구분
결측치 처리
-
Cabin 피처 드랍
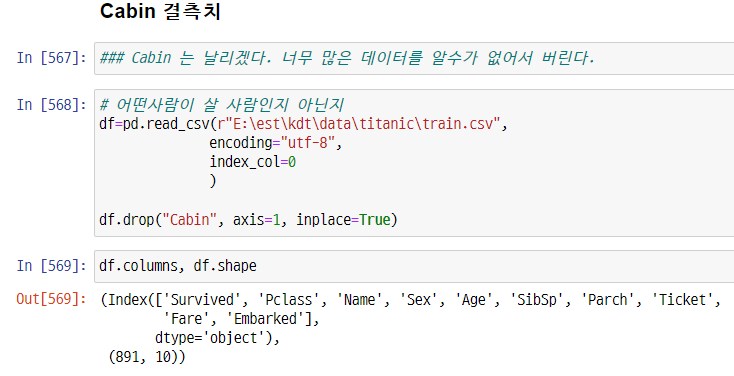
-> 너무 수가 많아서 채울 수가 없다. 버리는게 낫다 -
Embarked 채워넣기
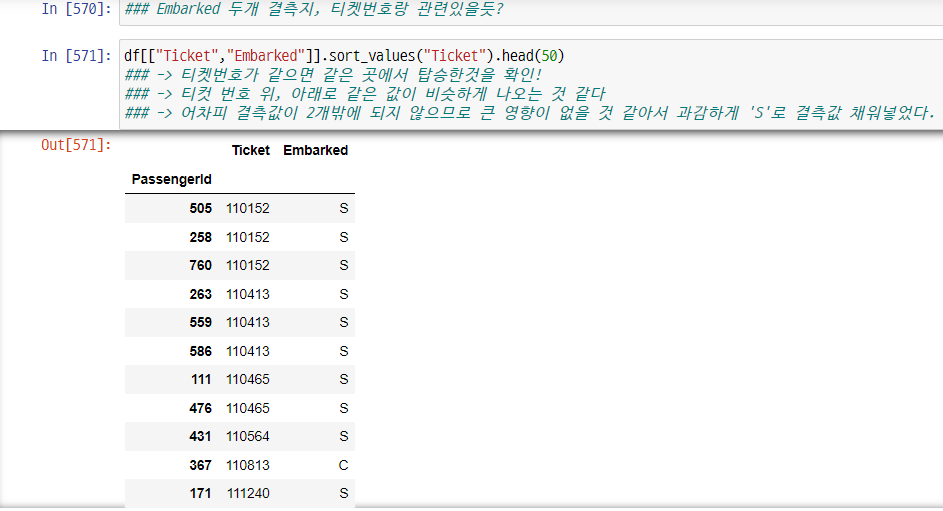
-> 티켓번호 기준으로 조회해보니, 티컷 번호 위, 아래로 같은 값이 비슷하게 나오는 것 같다
-> 결측값이 2개밖에 되지 않으므로 큰 영향이 없을 것 같아서 과감하게 'S'로 결측값 채워넣었다.
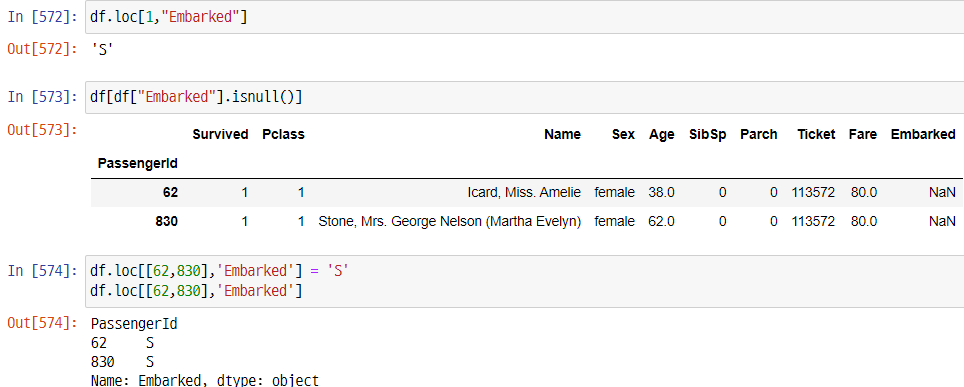
-
Age 채워 넣기
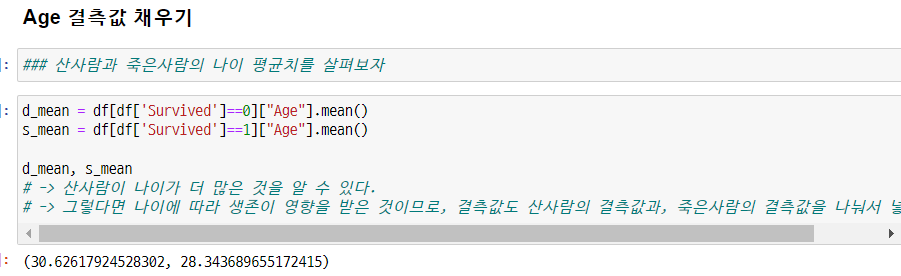
-> 생존/사망이 나이에 영향을 받으므로, 결측치도 생존/사망으로 나눠서 채워준다


데이터 변경 및 버리기
-
nominal 데이터 변경1 - sex
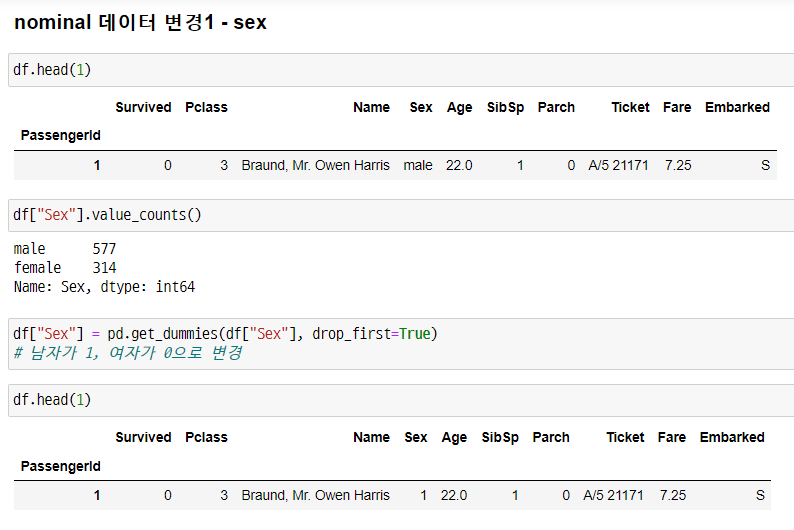
-
nominal 데이터 변경2 - Embarked
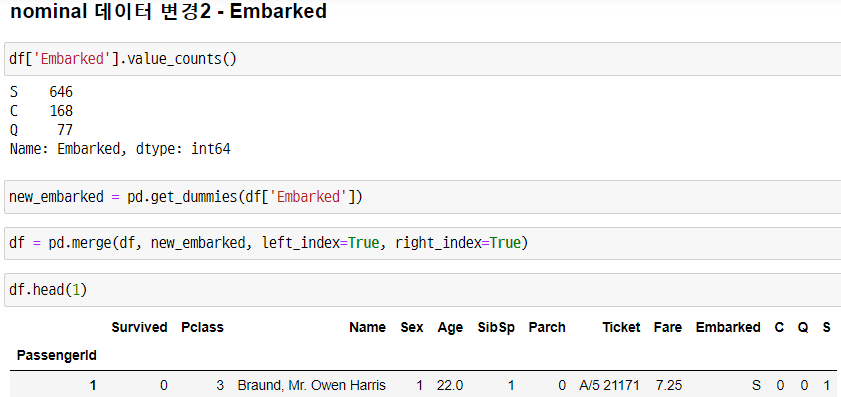
-
안쓰는 피처 버리기

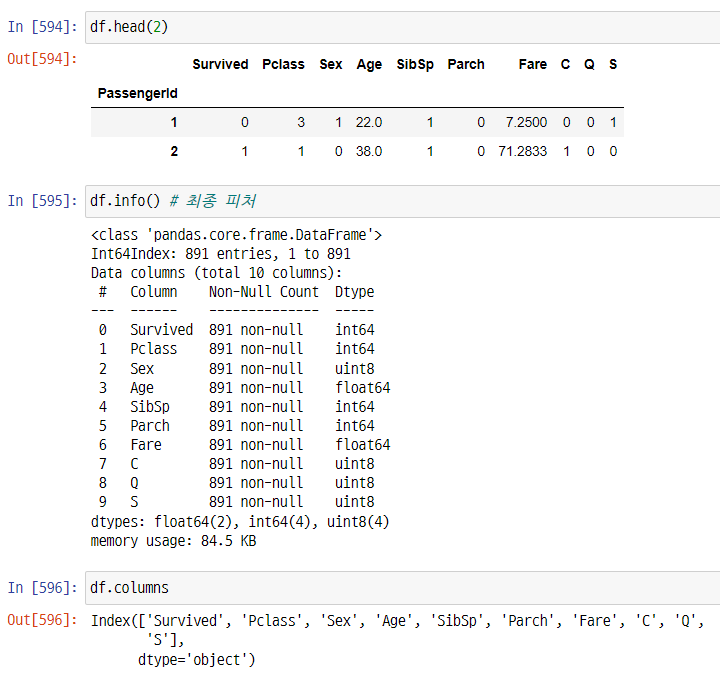
최종 사용 데이터프레임
히트맵 작성
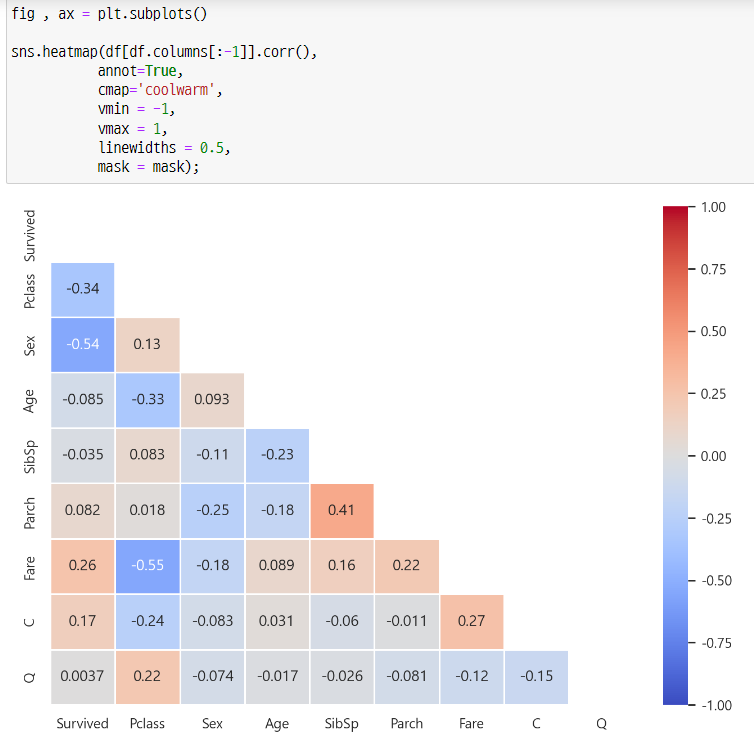
-> 그나마 눈에 띄는 것은 Survived-Sex, Pclass-Fare, Parch-SibSp
-> 서로 영향을 주고 있겠다고 추측
스케터 작성
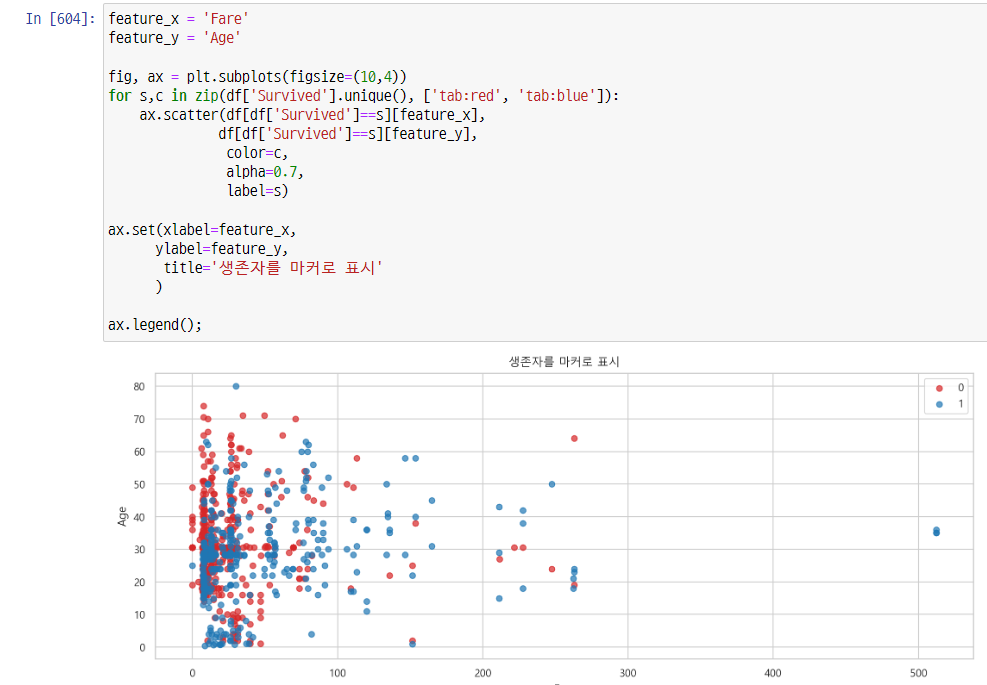
-> 여러 피처를 바꿔가며 스케터 그려봤지만, 범위가 다양하지 않아서 크게 알아낼 수 있는 것이 없었다.
-> 스케터가 적합하지 않은 데이터.
박스플랏 작성
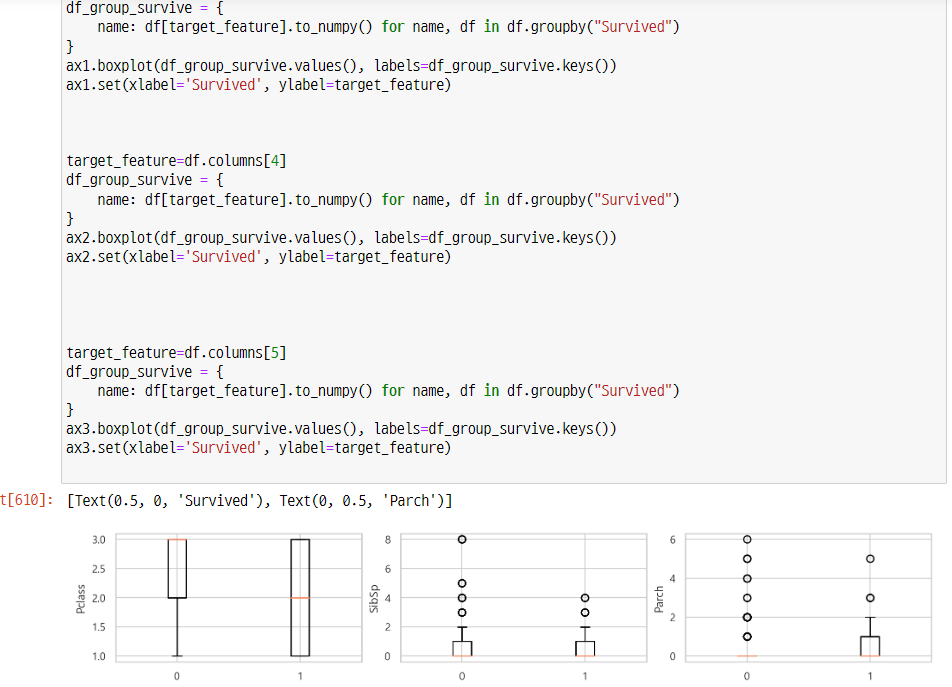
-> 객실등급이 높으면 조금 더 생존 확률이 올라가는 것을 확인 했다.
-> Parch 많은 쪽이 좀 더 생존 확률이 올라가는 것을 확인 했다.
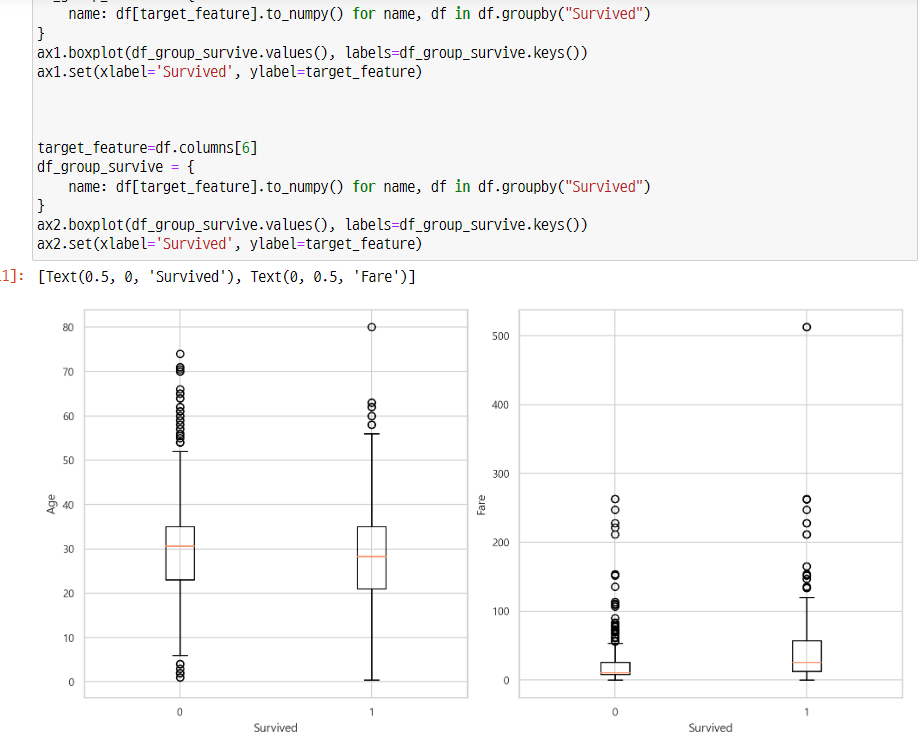
-> 요금을 많이 낸 사람이 평균적으로 더 많이 생존한 것을 확인 했다.
바이올린차트 작성
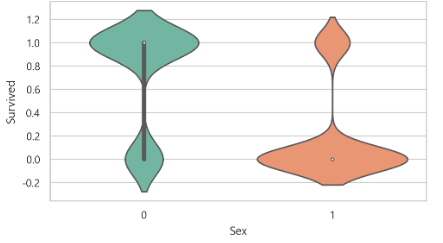
-> 성별이 매우 매우 눈에 띄게 큰 영향을 주고 있으므로 다른 그래프에 성별을 대입
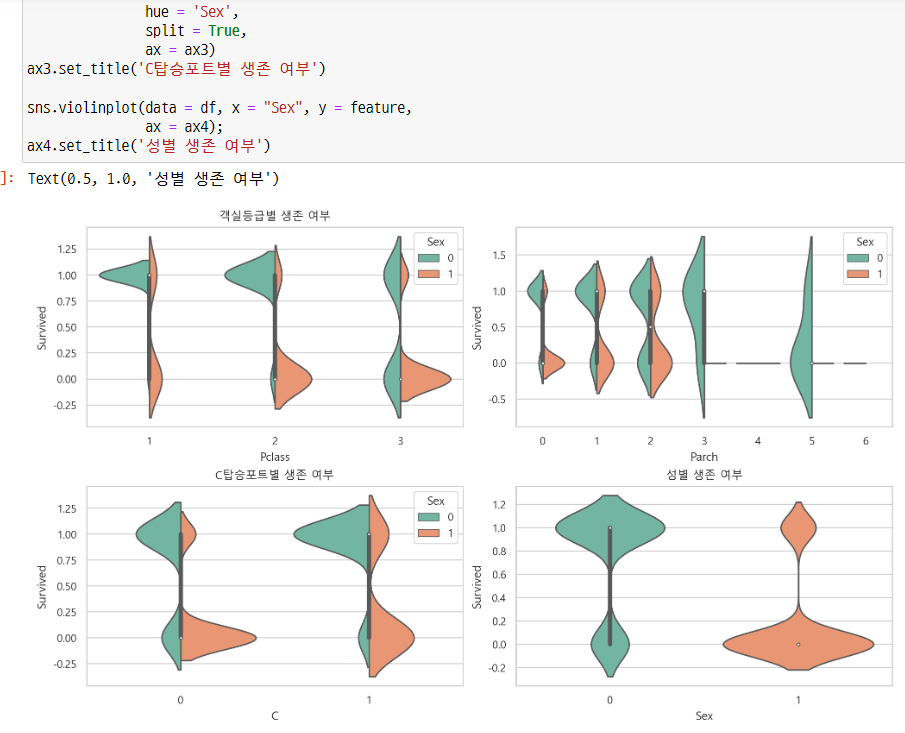
-> Pclass가 높은 등급일수록 생존을 많이한것을 확인, 1등급에 가서는 남성 생존/사망 비율이 비슷해진다.
-> Parch가 1~3일 수록 생존자가 많아지는 것을 확인, 1~2명인 경우 남성 생존/사망 비율이 비슷해진다.
-> Embarked-C 인경우 생존자가 많은 것을 확인할 수 있다.
