
📖 학습한 내용
- boxplot
- 통계수치의 이해
- scaling
- PCA
- HR 데이터 전처리
📖 핵심내용
📌 통계수치의 이해
- 분산을 𝑛−1로 나누어야 한다.
-> 평균과 분산은 서로 관련이 있다. 근데 분산을 구하는 식에 이미 평균이 들어가므로 자유도가 하나 떨어지므로, n-1로 나눠져야한다
-> 직관적으로 표본에서 뽑힌 데이터들은 평균에서 들쭉날쭉하게 멀리 있는 값이므로, 데이터-평균 제곱의 합이 모집단보다 크게 된다. 따라서 분모를 작게하여 크기를 맞춰준다.
📌 correlation
-
피어슨 상관계수
-> 서로의 값이 얼만큼 연관이 있는지 알 수 있다.
-> 1이면 양의 상관관계, -1이면 음의 상관관계
-> -0.3 ~ 0.3 : 아무관련 없다고 판단
-> -0.7 ~ 0.7 : 약한 상관관계
-> -1 ~ 1 : 강한 상관관계 -
기울기를 반영한 것이 아니다. 기울기의 방향만 반영한 것이다.
-
스피어만 상관계수
-> 두 데이터사이의 순위에 대한 상관계수
-> numerical이나 ordinal 데이터에 대한 상관 관계를 분석할 수 있다.
📌 scaling
-
수치의 크기에 영향을 받는 모델은 특성의 데이터 분포 범위가 다를 경우 수치가 큰 특성에 영향을 많이 받을 수 밖에 없다
-
종류
-> Min-Max scaling (거의 이거를 쓴다)
-> Standard scaling
-> Robust scaling (튀는 값이 많아서 평균이 영향을 받을때 가끔쓴다)
- 코드
import sklearn
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler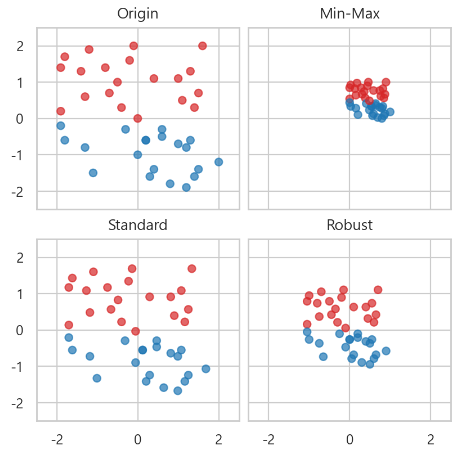
-> 오리진에 비해서 조금더 값들이 모여진 것을 알 수 있다. 하지만, 워낙 수가 적고 값이 크질 않아서 스탠다드는 비슷한 형태이다.
- 스케일링은 본인의 열에서만 작용한다. 전체에 적용되는 것이 아니다
📌 PCA
- 차원 축소는 데이터를 가장 잘 표현하는 특성을 선택하여 데이터의 크기를 줄이고 모델의 성능을 향상 시킬 수 있음
- 주성분 분석 전에 반드시 스케일링을 해준다
- 즉, 분산(데이터가 퍼져있는 정도)이 가장 큰 방향을 찾자. -> 이 방향 벡터가 데이터를 가장 잘 대변하는 것이다.
📌 HR 데이터 전처리
훈련데이터와 테스트 데이터로 나누기
- 학습시킬 데이터를, 데이터베이스에서 넣을 데이터(피처) 선택
```feature = [피처1, 피처2...] - 정답으로 넣어줄 컬럼 선택
- train_test_split()
-> 훈련데이터와 테스트데이터 나누기
-> test_size : 테스트데이터의 비율
-> random_state : 발생한 난수 중에서 항상 동일한 훈련 세트와 테스트 세트로 분할한다.
-> stratify : 각 클래스의 비율을 유지하도록 한다. 피처의 데이터에서 테스트/훈련데이터로 나눌때 서로 정답구성의 비율이 비슷하게 나눠준다.
스케일링
- 나눈 데이터를 스케일링한다.
- 훈련데이터
- 전처리할때 기존처럼fit_transform()사용- 전처리한 데이터를 데이터프레임으로 만든다
- 데이터프레임에 훈련 정답 컬럼을 벙합한다.
- 테스트데이터
- 전처리할때transform()사용한다.- 전처리한 데이터를 데이터프레임으로 만든다.
- 데이터프레임에 테스트 정답 컬럼을 벙합한다.
📖 흥미로운 점 / 새로 알게된 점
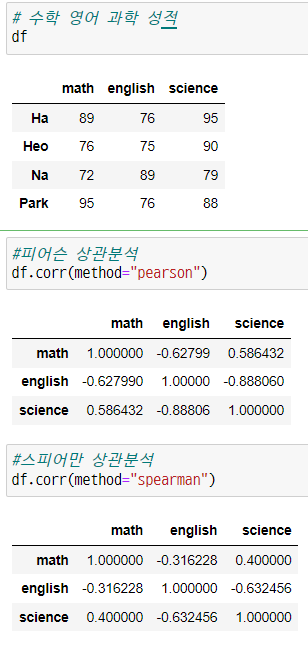
-> 같은 값이여도 서로 다른 상관분석 결과값이 나온다.
-> 피어슨은 점수 자체의 상관관계를 나타내는 것이고, 스피어만은 등수의 상관관계를 나타내는 것이다.
- StandardScaler(), MinMaxScaler(), RobustScaler() 따위의 데이터 스케일링은, 반환을 배열로 한다.
- countplot
- patches : 막대 그래프의 막대를 나타내는 객체들의 리스트- sorted(딕셔너리, reverse=True) : 딕셔너리의 키값을 기준으로 내림차순한다. 반환값은 리스트형이다.
-
dict() : 자료형을 딕셔너리형태로 바꾼다
->dict(df[feature].value_counts())
-> 시리즈형 데이터를 딕셔너리 형태로 바꾼다
-> 데이터프레임도 변환가능하다.
-> 배열은 의외로 안된다. 인덱스 컬럼이 있어야하는 것 같다.
-> 만약 이것을 리스트형으로 바꾸면 키값만 살고, 벨류는 모두 사라진다. -
annotate() : 그래프에 텍스트 주석을 추가하는 함수
📖 어려운 부분
- 데이터프레임 여러 컬럼 선택
->df\[\['열1','열2'....]]
-> 이방법 말고는 없다 제발 헷갈리지 말자
- .values 는 배열을 반환한다.
scaling_data=[df[['x','y']].values, df_minmax, df_std, df_rob]
scaling_name=["오리진", "민맥스", "스탠다드","롭"]-> df[['x','y']].values처럼, DF나 시리즈의 값을 배열로 반환한다.
- df[컬럼]과 df[[컬럼]] 차이
-> df[컬럼] 은 시리즈 데이터형이고, df[[컬럼]]은 데이터프레임형이다.
- 그래프 그리기
1) 시리즈 데이터
data = peng[peng["species"] == 'Gentoo']["bill_depth_mm"]
ax.boxplot(data,
labels=[target_species])-> 데이터프레임의 컬럼은 시리즈! 박스 플랏에는 시리즈 데이터가 들어갈 수 있다.
2) 배열
fig, ax = plt.subplots(figsize=(4,4))
ax.scatter(x=cancer_pca[:,0], # 배열이 들어올때는 data=~~ 넣으면 안되는 것 같다.
y=cancer_pca[:,1],
alpha=0.5,
color=c
);-> 배열이 들어올때는 첫번째열(배열객체[:,0]), 두번째열(배열객체[:,1])을 넣어줘야한다.
📖 이후 학습 계획
- 앙상블에 대한 이해/Random Forest 원리 이해
-단층 신경망 구현/다층 신경망 구현
📖 기타
- 크게크게 큰틀은 알겠다. 대략 써먹을 수 있을 정도로 훈련하는게 먼저라고 생각이든다. 그리고 그후 디테일한 부분을 좀 더 연습해야되겠다고 생각했다. 너무 자유도가 높고 표현할 수 있는 부분이 많아서 처음부터 다 하려고 마음 먹으면 할 수 없을 것 같다. 그때 그때 필요한 것을 빠르게 찾아서 적용할 수 있는 능력을 기르자
