
📖 학습한 내용
- hr 데이터 PCA
📖 핵심내용
📌 hr 데이터 PCA
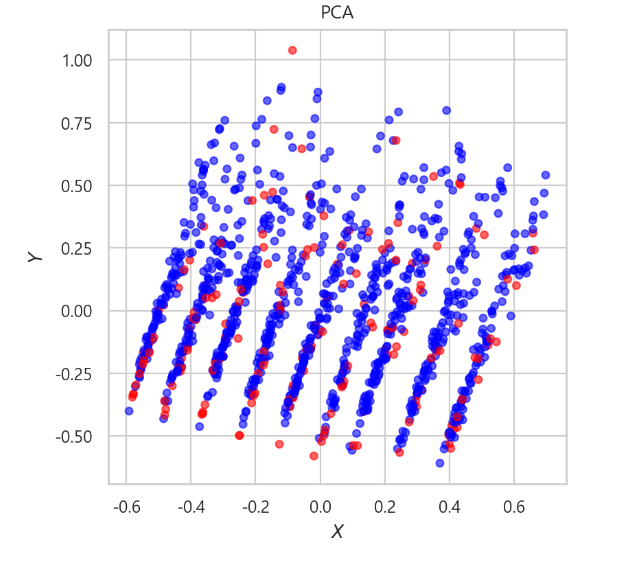
-> 위에처럼 너무 구분이 안될정도면, 보통 피처를 잘못 선택했거나, 결측치를 잘못 채웠다고 판단한다.
-> 피처선택을 다시하고 결측치를 다시 채운다.
📌 아이리스 - 여러학습모델
- 학습모델 기본 프로세스
model = LogisticRegression(max_iter=200)
model.fit(train_X,train_y)
prediction=model.predict(test_X)
print('The accuracy of the Logistic Regression is',metrics.accuracy_score(prediction,test_y))- stratify 의 유무
1) stratify X
# stratify에 아무것도 안줬을때
x_train, x_test, y_train, y_test= train_test_split(x_data,
y_data,
test_size=0.30,
random_state=97,
# # stratify=y_data
)
y_test.value_counts()
-> 테스트 데이터 비율이 종에 따라 다른 것을 볼 수 있다.
1) stratify O
x_train, x_test, y_train, y_test= train_test_split(x_data,
y_data,
test_size=0.30,
random_state=97,
stratify=y_data
)
y_test.value_counts()
-> 테스트 데이터 비율이 골고루 뽑힌 것을 확인
📌 KNN
공식문서 :
- 학습된 데이터와 테스트데이터를 비교했을때, 테스트 데이터중 가장 가까운 것을 기준으로 판단하여 분류한다.
훈련 데이터를 공간에 뿌리고
테스트 데이터가 입력되면
테스트 데이터를 중심으로 정의된 거리(default = Euclidean)에서 가까운 n_neighbors개의 점을 찾는다.
n_neighbors개 점의 라벨을 조사하고 가장 많은 라벨로 테스트 데이터의 라벨을 결정한다.
-
모델 파라미터(일반적으로 말하는 파라미터를 의미): 모델이 학습 하면서 변화하게 되는 값. 딥러닝 모델의 경우 가중치가 파라미터
-
하이퍼 파라미터(매개변수): 모델의 학습 전에 설정해 주는 값. 아무런 설정도 하지 않으면 기본값(default)로 학습하게 됨
-
주요 하이퍼 파라미터
- n_neighbors: 몇 개점을 찾을 것인지 결정한다.
- weights
- uniform: 모든 점의 가중치가 같음
- distance: 거리의 역수로 가중치 부여
- 기본적인 distance는 유클리디안
- metric='minkowski',
- p=2
- n_jobs: CPU 코어수
- None: 코어 1개 사용
- -1: 모든 코어 사용
- 시각화하여 원리 파악하기
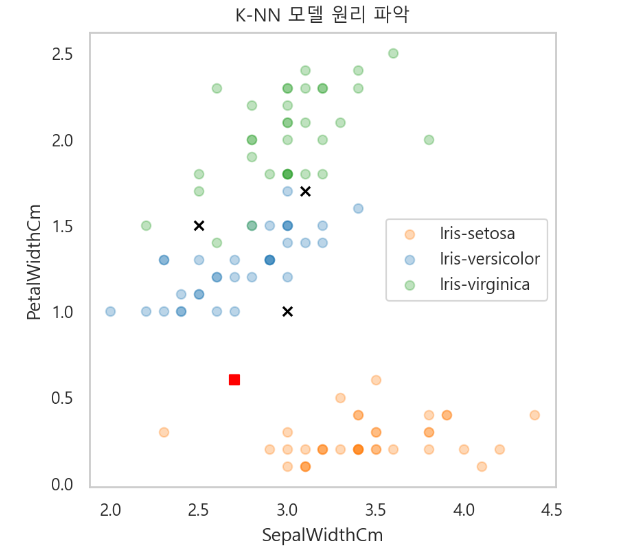
-> 각각의 마커들은 주변에 가장 가까운 4개의 종에 따라서 어떤 종이 될지 결정난다.
📌 DT
공식문서 : https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
-
모든 학습한 피처마다 각각 계산하여 높은 정보획득값을 구한다. 그리고 두갈래로 나눠지면서 엔트로피/지니계수가 낮아지는 방향으로 진행한다.
-
주요 사용 하이퍼 파라미터
- criterion: 불순도를 계산할 함수
- gini, entropy
- 두 함수가 비슷한 결과를 냄
- splitter: 노드를 분할하는 방법
- best: 정보의 이득이 최대가 될 때
- random: 랜덤하게. best 보다 random이 더 효과적일 때도 있음
- max_depth: 몇 층까지 가지를 칠 것인지
- 설정하지 않으면 불순도가 0이되거나 min_samples_split보다 샘플수가 적을 때까지 가지를 침
- max_depth = 1로 준 DT를 스텀프라고 부름. 부스터로 사용하면 강력해 질 수 있음
- min_samples_split: 노드를 나누기 위한 최소 샘플 수
- 최소 2개는 샘플이 있어야 가지를 치기 때문에 default는 2이다.
- min_samples_leaf: leaf의 최소 샘플 수
- leaf노드는 최소 1개의 샘플을 가지고 있어야 함.
- 만약 min_samples_leaf를 4로 준다면 모든 리프 노드가 최소 4개의 샘플을 가지고 있게 된다.
- max_features: 특성의 개수
- input의 특성에서 max_features만큼 랜덤하게 추출
- random_state: max_features만큼 특성을 랜덤하게 선택하기 때문에 필요
- max_leaf_nodes: 리프 노드의 전체 샘플 개수
- min_impurity_decrease: 가지를 치기 위한 최소 불순도 감소
- criterion: 불순도를 계산할 함수
📖 흥미로운 점 / 새로 알게된 점
-
디시전트리는 어차피 기준이 피처의 값으로 들어가기 때문에 스케일링을 안해도 된다.
-
피처 테스트 데이터 스케일링 :
MinMaxScaler().transform(x_test)
-> 헷갈리지 말고 꼭 그냥 transform!!!! -
피처 트레인 데이터 스케일링 :
MinMaxScaler().fit_transform(x_train) -
KNN에서 거리 값이 같다면, 피처의 이름 순서로 포함하게된다.
-> 이것은predict()가predict_proba()의np.argmax()값으로 나타나기 때문이다.
-> 가장 큰 값의 인덱스를 받은다음에 출력하기 때문에 같은 거리라면 이름 순이 우선순위를 가진다. -
튜닝 : 기존 모델의 파라미터를 조정하여 모델의 성능을 향상시키는 행위
-
머신러닝 프로세스
1) x_data 에 넣을 피처를 선택하여 입력한다
2) y_data 는 정답을 넣는다.
3) train_test_split 을 이용하여 훈련/테스트 데이터 생성
-> random_state , stratify, test_size
4) 훈련데이터 스케일링
-> fit_transform()
5) 테스트 데이터 스케일링
-> transform()
6) 머신러닝에 넣고 테스트 데이터와 비교하여 정확도 확인
-> predict(), metrics.accuracy_score()
기여도
- DT나 RF 분류 결과에 영향을 미친 요소를 수치화하여 볼 수 있다
model.feature_importances_
각 노드별로 피처가 얼만큼 분류기준으로 사용되었는지 확인 할 수 있다.
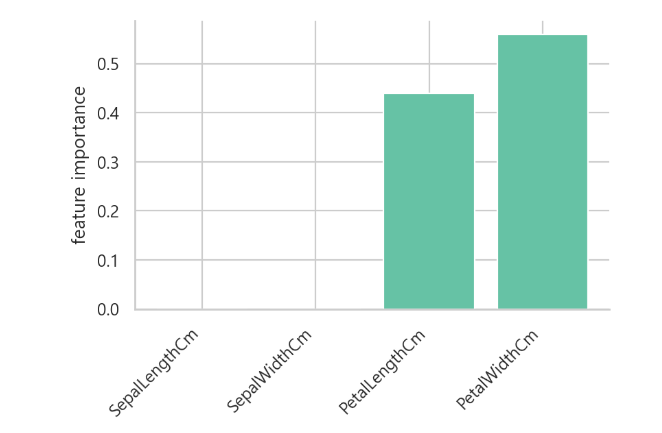
-> 'PetalLengthCm', 'PetalWidthCm' 가 주로 분류 기준으로 사용되었다.
splitter

- 정보의 이득 즉, information gain(IG)이 최대가 되는 특성과 조건으로 기준이 정해진다.
- 각 피처별로 기준치가 최소값부터 최대값까지 변해가면서 최적의 information gain를 찾고, 그것을 기준으로 가지를 친다.
- 자식노드와 부모노드의 지니계수를 알아야 구할 수 있다.
- Decision Tree는 Information Gain이 최대가 되는 feature와 value에서 가지를 친다
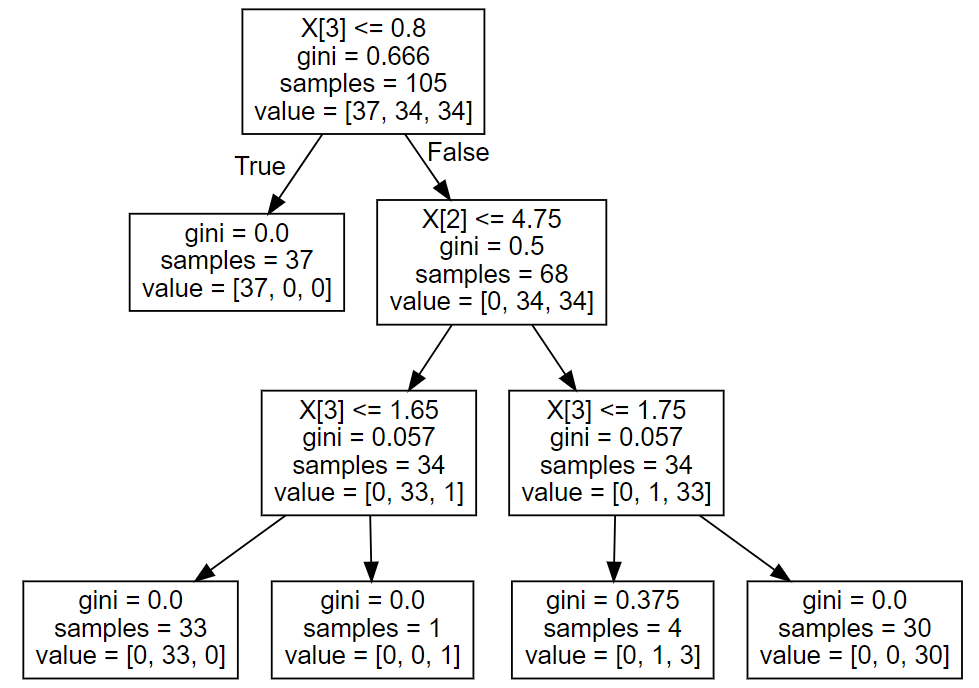
-> iris 데이터를 이용한 예시. 노드별 gini 계수를 이용해서 가장 높은 IG를 계산한다. 계산한 IG를 기준으로 노드의 불순도가 낮아지는 방향으로 가지치기를 진행한다.
지니계수(불순도)

- sklearn에는 criterion 옵션으로 불순도 함수를 정할 수 있고 default="gini"이다.
- 하나의 노드에 서로 다른 다양한 클래스가 많이 섞여있을수록 지니불순도가 높다.
- 하나의 노드 내에서 구할 수 있다.
📖 이후 학습 계획
- 앙상블에 대한 이해/Random Forest 원리 이해
- 단층 신경망 구현/다층 신경망 구현
📖 기타
지난주 학습 내용 정리
-
데이터의 결측과 수치화
- numerical
- 그 특성의 평균이나 중앙값으로 채우는 것이 가장 간단
- 다른 특성과의 관계를 살펴서 채울 수도 있음
- feature를 줄이기 위해 새로운 feature를 생성할 수 있음
- categorical
- 새로운 카테고리를 만드는 것이 가장 간단
- 다른 특성과의 관계를 살펴서 채울 수도 있음
- norminal(순서없음): one-hot encoding 혹은 특성의 데이터타입을
categorical로 지정 - ordinal(순서있음): 순서가 있는 숫자 즉, 자연수로 변환
- numerical
-
이상치(혹은 노이즈)
- 이상치인지를 판단하려면 해당 데이터의 각 특성에 대한 이해가 중요
- 다른 특성과의 관계를 살펴 정말 이상한 것인지 판단해야 함
-
matplotlib, seaborn 시각화
- 시각화는 내용 전달, 데이터의 즉각적 이해, 가설 확인 및 설정 등을 위해 필요
- 데이터를 가장 잘 설명할 수 있는 그래프, 색상 등을 선택
- 필요에 따라서는 자료에 설명(화살표, 텍스트 등)을 넣을 수도 있음
- 축, 축, title은 넣는 습관을 들이는 것이 필요
-
상관관계
- 두 개의 특성간의 관계를 수치화해서 볼 때 필요
- 수치 데이터라면 피어슨 상관계수(일반적으로 말하는 상관계수는 피어슨 상관계수)
- 순서가 있는 데이터라면 스피어만 상관계수
- 예를 들어 수학과 영어과목 시험 점수에 대한 상관관계는 피어슨으로, 시험 석차에 대한 상관관계는 스피어만으로 분석
-
스케일링
- 데이터의 분포 범위를 균일하게 해 주는 작업
- 대부분의 머신러닝 모델은 스케일링에서 더 잘 학습 됨
- 종류: min-max, standard, robust 등
-
차원축소
- 데이터의 차원이 너무 높아지면(즉, 특성이 너무 많아지면) 학습 데이터는 잘 맞추지만 테스트 데이터에서 맞추지 못하는 과적합 현상이 발생
- 데이터의 정보는 가지고 있으면서 차원을 줄이는 방법이 필요
- 학습에 이용할 데이터의 차원을 줄이거나 데이터를 2D 혹은 3D로 시각화 해 보고 싶을 때 활용
- 종류: PCA, -SNE
- 테스트 데이터의 전처리는 훈련 데이터의 정보로만 해야한다.
과제
해당 model이 depth 0에서 𝑋[3]<=0.8 일 때 Information Gain이 최대인지 확인하시오
iris = pd.read_csv(r"E:\est\kdt\data\iris\iris_kaggle.csv",
index_col=0
)
x_data = iris[iris.columns[:-1]]
y_data = iris["Species"]
x_train, x_test, y_train, y_test = train_test_split(x_data,
y_data,
test_size=0.30,
random_state = 97)
model = DecisionTreeClassifier(max_depth = 3, random_state=97)
model.fit(x_train.values, y_train.values)
# np.max(x_train['PetalWidthCm']), np.min(x_train['PetalWidthCm'])
x_train['att']=y_train
def gini(dic):
g = []
for k in dic:
g.append((dic[k]/sum(dic.values()))**2)
return 1-sum(g)
def n_sum(dic):
return sum(dic.values())
p_gini = 0.666
p_num = 105
fig, ax = plt.subplots(figsize=(8,5))
ax.plot([0.8,0.8], [0, 0.35], color="red", ls = "--")
ax.set(xlabel='피처 구분 값', ylabel="정보이득값", title="피처별 정보이득 그래프" )
for col in x_train.columns[:-1]:
ig_list = []
ig=0
max_list = []
max_ig=0
basis = np.arange(x_train[col].min(), x_train[col].max()+0.1, 0.1)
for i in basis:
l_cnt= dict(x_train[x_train[col]<= i]['att'].value_counts())
r_cnt= dict(x_train[x_train[col]> i]['att'].value_counts())
ig = p_gini - n_sum(r_cnt)/p_num*gini(r_cnt) - n_sum(l_cnt)/p_num*gini(l_cnt)
ig_list.append(ig)
max_ig=max(ig_list)
if ig == max_ig:
max_i = i
for j in range(len(ig_list)):
if ig_list[j] == max_ig:
max_list.append(round(basis[j],2))
sns.lineplot(x=basis,
y=ig_list,
label=col
)
print('{}의 크기{}에서 Information Gain 값은 {:.3f}입니다.'.format(col,max_list,max_ig))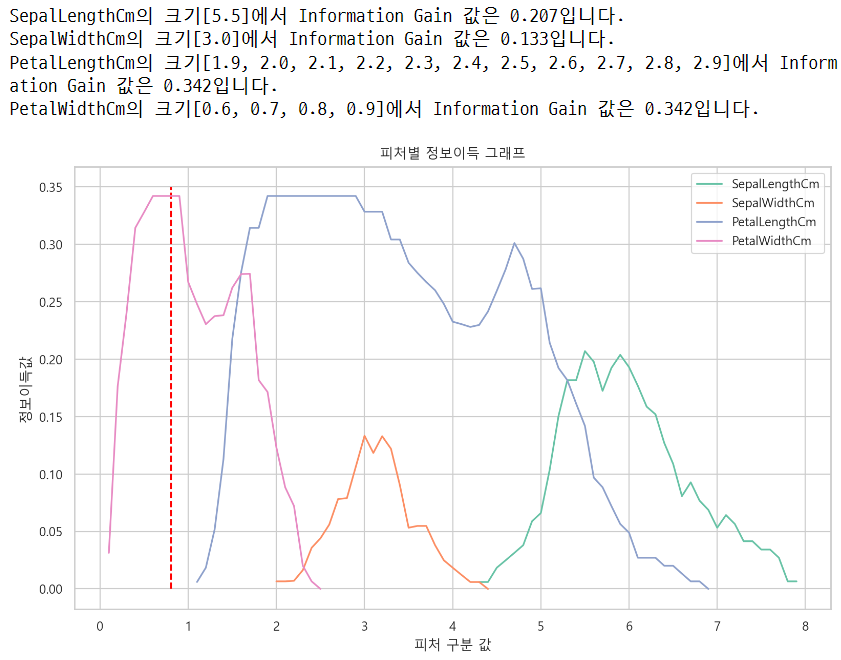
느낀점
생각보다 만만하지 않았다. 머릿속으로 구현한 것이 두루뭉실해서, 마음만큼 쉽게 그려지지 않았다. 구상을하면 바로 코드가 떠올라서 시작해야하는데, 구상을 잡기가 매우 어려웠다. 이렇게 저렇게 시도를하면서 가닥을 잡아나가다보니, 코드가 생각보다 더러웠다. zip, enumerate, iterrow, item 따위의 함수를 썼으면 좀더 깔끔하게 썼을 것이라고 생각한다.
하면서 이미 적은 것을 활용하여 하려다보니, 주먹구구식으로 작성자인 나도 쉽게 알기 어려운 코드가되었다. 좀더 부단히 연습해서 알아보기 쉽게, 빠르게 구상할 수 있는 실력이 되어야겠다.
