
📖 학습한 내용
- 교차검증
- 그리드 서치(Grid Search)
- bagging
- randomforest
📖 핵심내용
📌 교차검증
- 모델의 최종 평가는 검증 데이터의 평균으로 한다.
cross_validate()는 훈련 데이터를 섞어주지는 않고 인덱스 순으로 한다. 따라서 분류 모델을 만들 때는,cv=StratifiedKFold()로 지정하는게 좋다.cv=StratifiedKFold(): 비율을 맞춰서 분류모델을 만든다.- cv 값을 주면 값만큼 등분한다. ex) cv=3 -> 전체 데이터를 3등분하고, 그중 하나를 검증데이터로 쓴다
- 형태
model_dt.fit(x_train, y_train)
prediction = model_dt.predict(x_test)
print('The accuracy of DT is',
metrics.accuracy_score(prediction, y_test))대신에
cross_validate(estimator = model,
X = x_train,
y = y_train,
cv = StratifiedKFold())cross_validate()는 딕셔너리를 반환한다. 그중 "test_score" 컬럼에서 점수의 평균값을 사용한다.- StratifiedKFold() 에서 n_splits 의 기본값은 10이다.
📌 그리드 서치(Grid Search)
- GridSearchCV는 k-fold cross validation
📌 randomforest
- 여러개의 트리를 랜덤하게 설정해서 모은 값을 평균내서 나타내는 것
- 형식
x_train, x_test, y_train, y_test = train_test_split(x_data,
y_data,
test_size=0.20,
random_state = 209,
stratify = y_data)
cancer_rfc1 = RandomForestClassifier(oob_score=True,
random_state=209)
cancer_rfc1.fit(x_train, y_train)
cancer_pred = cancer_rfc1.predict(x_test)
print('The accuracy of the RFC is',
metrics.accuracy_score(cancer_pred, y_test))📖 흥미로운 점 / 새로 알게된 점
-
일반적으로 max 이름을 가진 하이퍼파라미터는 감소하고, min 이름을 가진 하이퍼파라미터는 증가 시키면 모델의 성능이 향상됨 속설이 있다.
-
교차검증을 해야하는 이유
전체에서 일부를 떼고, 다음에들어가는 훈련데이터는 셈플링 어떻게하냐에따라 살짝 달라지므로 학습을 다양하게 할 수 있다.
조금씩 다른 학습모델에서 많이 학습하기때문에, 오버피팅도 피하고 검증도 할 수 있다.
📖 어려운 부분
- max_depth 를 왜 적게 주지??? 시간때문인가? 많이주면 좋은게 아닌가
- 교차검증에서
splitter = StratifiedKFold(n_splits = 10, shuffle=True, random_state = 42)의미하는바?
-shuffle=True라고 줘야 데이터를 한 번 섞어서 교차검증을 진행한다. 이때 섞을 때 랜덤하게 섞기 때문에random_state를 지정해 줄 수 있는 것이고,random_state를 지정해 주면 항상 같은 shuffle을 하게된다.StratifiedKFold를 의미있게 사용하려면shuffle=True를 해줘야한다.
- 트리의 max_depth 를 조정하는 이유
- leaft 노드가 너무 순수하면 모델이 과적합되기 쉽다. 따라서 max_depth를 정해 줘서 leaf_node가 너무 순수해지지 않도록 할 필요가 있다.
퀴즈
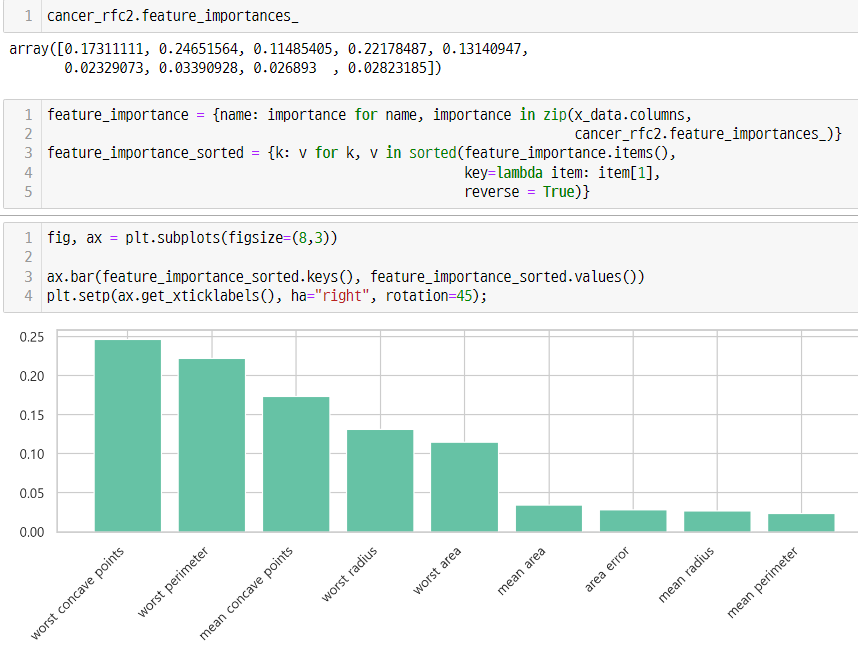
- breast_cancer 데이터의 feature 을 선택하여(30개 모두 넣지말고) 모델의 정확도를 비교해보시오
correlation을 활용해서 피처를 선택
# 상관계수가 높은애들 모음
cancer_df = pd.DataFrame(data = np.c_[cancer["data"], cancer["target"]],
columns = list(cancer["feature_names"]) + ["label"]).astype({"label": "category"})
df_corr = cancer_df[cancer_df.columns[:-1]].corr()
df_c = df_corr[(-0.75 > df_corr) | (df_corr > 0.75)]
corr_cnt = [df_c[col].value_counts().shape[0] for col in df_c.columns]
df_c['corr_cnt']=corr_cnt
rank_corr = df_c['corr_cnt'].sort_values(ascending=False)[:9]
rank_df = cancer_df[rank_corr.index]
x_data = rank_df[rank_df.columns[:]]
y_data = cancer_df["label"]
# 학습과 테스트 데이터 분류
x_train, x_test, y_train, y_test = train_test_split(x_data,
y_data,
test_size=0.20,
random_state = 209,
stratify = y_data)
cancer_rfc2 = RandomForestClassifier(oob_score=True,
random_state=209)
cancer_rfc2.fit(x_train, y_train)
cancer_pred = cancer_rfc2.predict(x_test)
print('The accuracy of the RFC is',
metrics.accuracy_score(cancer_pred, y_test))

설계엔지니어의 변신