
📖 학습한 내용
- boosting
- 신경망
📖 핵심내용
📌 boosting
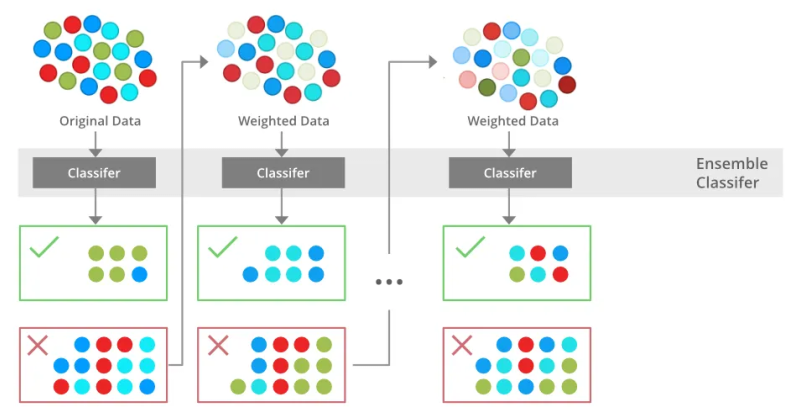
Adaboost
- DT의
max_depth=1를 기반으로 여러번 진행한다. - 오분류된 샘플에 더 많은 가중치를 주는 방식
- 모델이 가장 잘맞출수 있는 가중치를 찾는 것이 학습
- 학습데이터가 들어올때마다 가중치를 업데이트
- 가장 답을 잘맞출수있는 가중치를 찾을 때까지 학습하다 찾으면 끝
- 가중치를 모두 더하면 1
- Adaboost는 약한 학습기(우연보다 조금 나은 성능을 내는 머신러닝 모델)를 통해 반복적으로 오류를 고치는데 초점을 맞춘 모델
-> 따라서 베이스 모델이 강력하면 학습 과정이 제한되어 부스팅 모델의 전략을 약화시킴. 즉, 성능이 올라가지 않을 수 있음
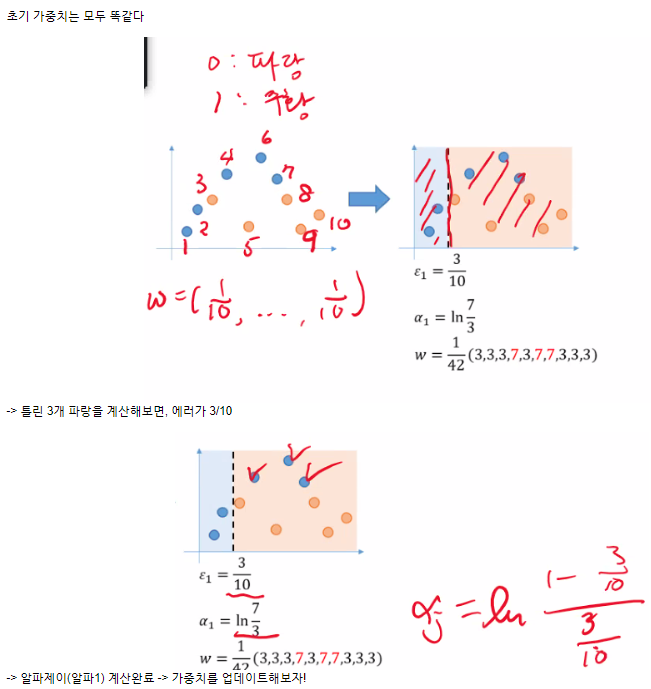
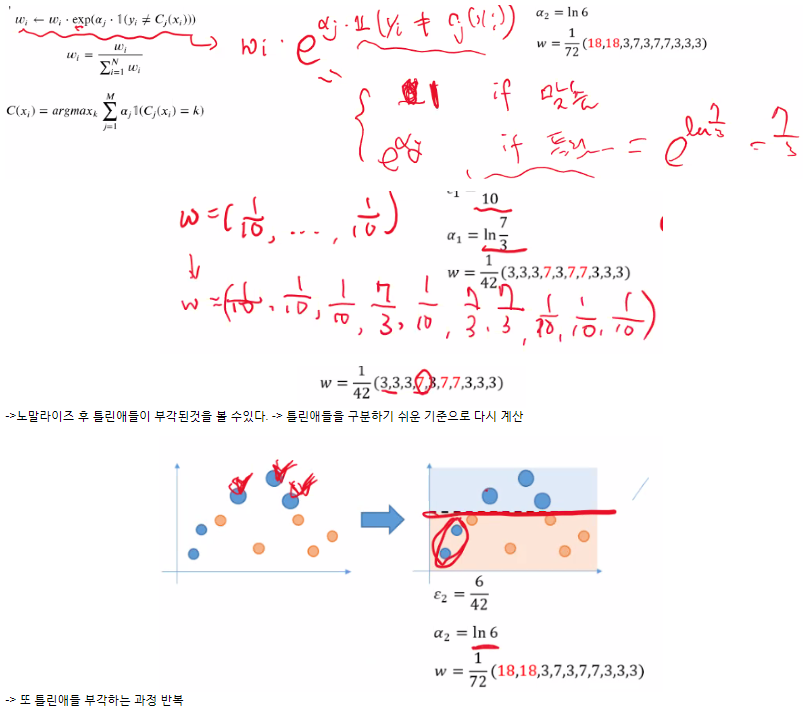
Gradient boosting
- 모델의 error를 예측하여 줄이는 방식
- 과정
1번 트리 잔차 (레지듀얼) : 정답과의 거리
2번트리 잔차를 줄이는 방향으로 학습한다.
반복 - 대표적으로
XGBoost
lightGBM
Catboost
📌 신경망
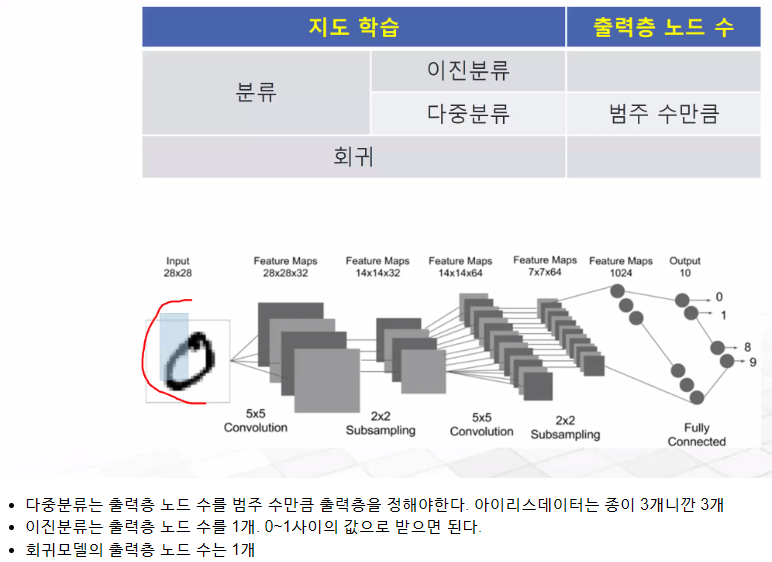
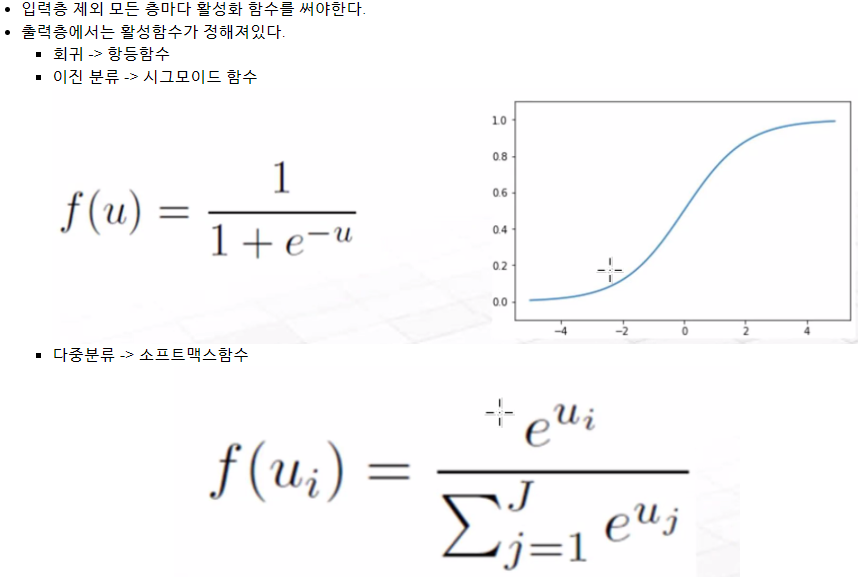
※ 비용함수 : 정답과 출력되는 값 사이에 거리를 나타내는 함수 cost func, lost func, objective func
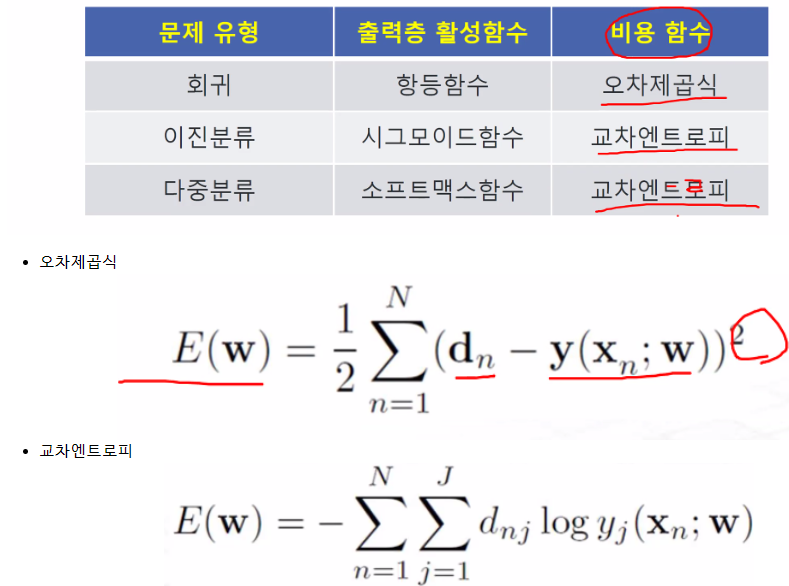
※ 최적화 : 출력으로 나오는 값이 답에 가까워지는게 목적

📖 흥미로운 점 / 새로 알게된 점
- Adaboost의 기본 아이디어가 DT의 max_depth=1 로 고정하고, 오답에 가중치를 곱한뒤 다시 DT를 실행하는 것이 신선했다.
np.c_[cancer["data"], cancer["target"]]배열 합치기 -> 열하나 추가
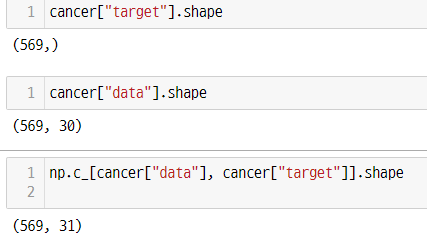
- 데이터프레임 만들때, 컬럼 추가하기 및 카테고리타입으로 만들기
cancer_df = pd.DataFrame(data = np.c_[cancer["data"], cancer["target"]],
columns = list(cancer["feature_names"]) + ["label"]).astype({"label": "category"})- 딕셔너리 for문으로 생성하기
# 예시
a = [1,2,3,4]
b= [5,6,7,8]
{i:j for i, j in zip(a,b)}-> zip을 활용하면 이런 식으로 활용 가능하다.
- items 활용
dic = {'a':3,'b':2,'c':1}
sorted(dic.items(), reverse=True)-> 딕셔너리를 키와 벨류가 함께 튜플로 묶인 리스트 생성한다
-
앙상블은 개별 모델 개수가 짝수보다 홀수가 좋으므로, 랜덤포레스트의 n-estimators의 값을 홀수로 설정하자!
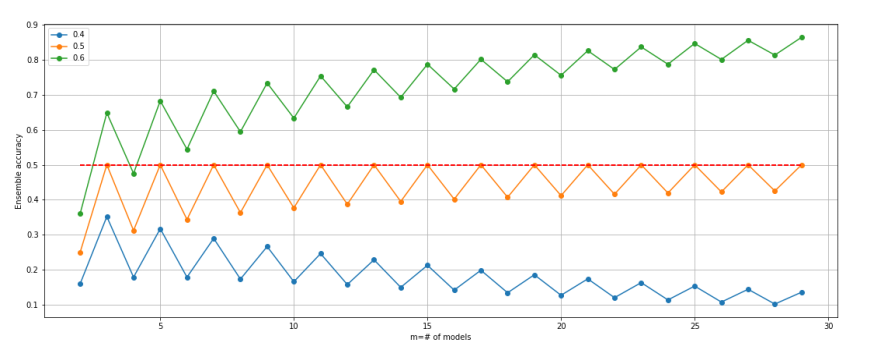
-
앙상블의 개별모델은 최소 3개 이상으로 주어야한다.
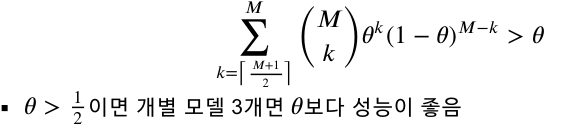
-
렌덤포레스트는 부트스트랩 샘플링을 하므로 샘플의 데이터가 100개면 100번 복원 추출한다.
-
RFC 와 XGBoost 비교
fig, ax = plt.subplots(figsize=(8,3))
ax.bar(train.columns[:-1],
rfc_best.feature_importances_,
color = "tab:blue",
label = "rfc",
alpha = 0.3)
ax.bar(train.columns[:-1],
xgb_best.feature_importances_,
color = "tab:red",
label = "xgb",
alpha = 0.3)
ax.legend()
plt.setp(ax.get_xticklabels(), ha="right", rotation=45);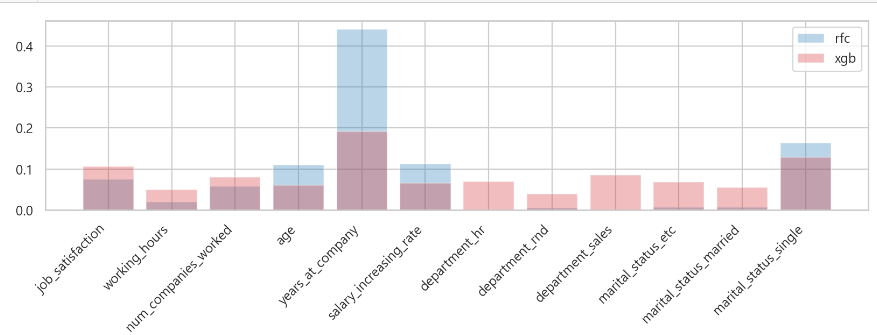
-> RFC가 XGB에 비해서 몇몇 피처에 몰려있다. 그에 비해서 XGB는 쏠림없이 골고르 분포되어 있다.
- 정답률만 고려하면 안되는 이유
예를 들어, 총원이 퇴직자가 10프로, 재직자가 90프로인 경우에 모델을 만들어서 실행한다고 가정한다. 그 모델에서 재직자를 맞추는 확률이 90프로면, 모델을 만들 필요가 없다. 어차피 대충 만든 아무 프로그램이나 돌려도 90프로는 나오기 때문이다.
📖 어려운 부분
나민원 강사님께 질문하여 어려운 부분을 해소할 수 있었다.
- StratifiedKFold() 함수 사용 여부
def grid_search(params, model, core):
model_grid = GridSearchCV(model,
params,
cv=5,
return_train_score=True,
n_jobs= core
)
model_grid.fit(x_train, y_train)
print('최상의 매개변수 : ', model_grid.best_params_)
print('훈련 데이터의 최고 정확도 : ', model_grid.best_score_)
model_best = model_grid.best_estimator_
pred_best = model_best.predict(x_test)
print('테스트 데이터의 최고 정확도 : ', metrics.accuracy_score(pred_best, y_test))-> 여기서는 StratifiedKFold를 쓰지 않았다. StratifiedKFold는 데이터를 받았을때 데이터가 정렬되어 있다면 써야하는 함수이다. cv=값을 줘서 실행하면 인덱스 순서별로 짤라서 들어가기때문에, 만약 데이터가 정렬되어 있다면 제대로 된 결과값을 내기 어렵기 때문이다. 위에 코드에 주어진 데이터는 랜덤하게 기입된 데이터를 받았기에 굳이 StratifiedKFold를 주지 않아도 상관없었다. 하지만, 안전을 위해서라면 StratifiedKFold(random=True) 해주자.
-> 지난 시간에 소화못한 공부량을 다시 훑어보면서 발견했는데, 영문을 모르겠어서 나민원 강사님한테 질문해서 알아낼 수 있었다.
-
RFC는 교차검증이 필요없다. 왜냐하면 OOB score로 샘플링 되지 않은 데이터로 모델을 평가하기 때문이다.
-> gri_search에서 RFC 모델을 적용하는데도 cv값을 주어 의문이 들어 나민원 강사님께 질문하여 알아낼 수 있었다. -
모델의 속성을 출력할 때는 마지막에 _ (언더바)를 써준다. sklearn의 규칙이다.
-
RFC의 원리를 정확하게 이해를 못해서 개념이 헷갈렸었다. 랜덤하게 피처를 뽑아 샘플을 만드는 것을 알았었다. 그런데 RFC는 피처도 랜덤하게 뽑고, 뽑은 피처에서 행의 값도 랜덤하게 뽑는다는 것을 알았다.
📖 이후 학습 계획
- 신경망의 출력과 활성함수/역전파
- 모델 결과 분석 - Confusion Matrix/Classification Report
📖 기타
- 2번의 수업이 지나고서야 이제야 좀 머신러닝에 대한 이해가 오기 시작했다.
프로세스가 거의 비슷하고, 이젠 어떤 머신러닝이 있는지, 개념이 무엇인지, 어떨때 쓰면 좋을지 공부할 차례라고 생각한다. 사용방법은 스스로 해낼 수 있으니 개념에 대해 익히는데 몰두하자
