
📖 학습한 내용
- 단층신경망
- 복층신경망
📖 핵심내용
단층신경망
활성함수는 층마다 한번 정해주면 모두 똑같은 활성함수가 적용된다.
출력층의 활성함수는 분류모델 이진분류 - 시그모이드함수, 다중분류 - 소프트맥스함수, 회귀모델 - 항등함수
바이어스란 모델성능에 영항을준다. 학습데이터를 통해서 모델이 가중치를 갱신하고, 바이어스도 갱신한다. 결국 딥러닝은 학습마다 가중치와 바이어스를 갱신하며 답을 찾는 것이다.
단층신경망 식
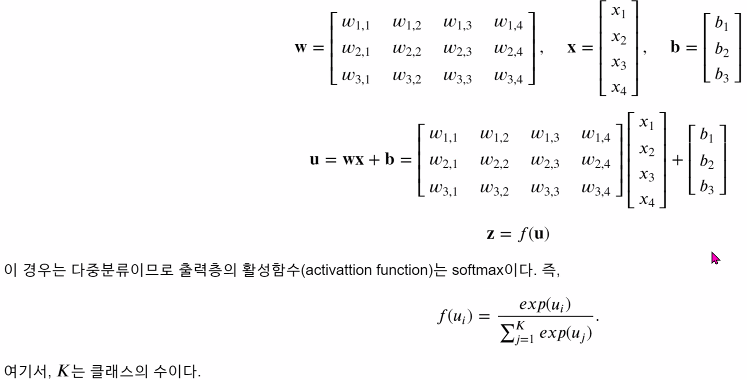
-
model.get_weights(): 랜덤하게 초기 가중치를 준다. -
np.matmul(data, w) # np.matmul(w.T, data)
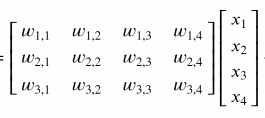
-
초기가중치 문제
랜덤하게 주어지는데 여러 랜덤하게 주는 방법들이 있다. ex)he_uniform -
모델.summary(): 구조를 대략 볼 수 있다. -
이진 분류에서 손실함수는
binary_crossentropy을 사용한다.
model_cancer.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']
)-
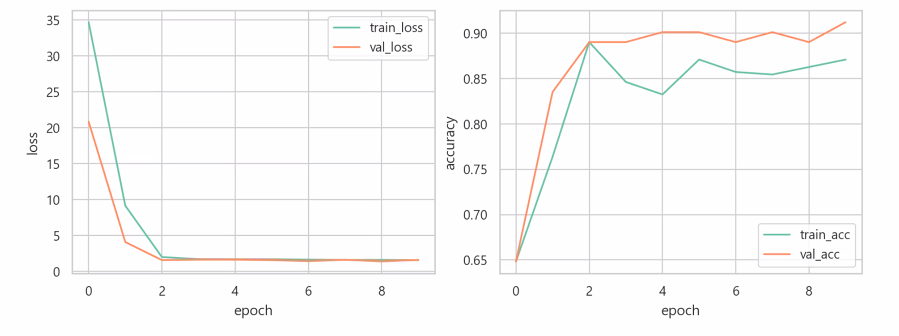
epoch-loss 그래프에서 validation 이 train 데이터와 같이 쭉 내려가다가 validation만 증가하는 순간이 오는데 그러면 오버피팅 된 것이다.
따라서 중간에 끊어줘야한다. -
딥러닝에 넣으려면 (ㅁ,ㅁ)형태를 맞춰줘야한다.
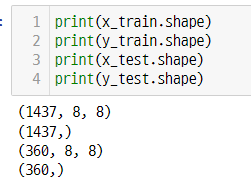
-> (1437,8,8) -> flatten을 사용해서 (1437,64) 로변경해야한다. -
모델을 만들었으면 컴파일을 반드시 해줘야한다. 어떤 로스, 옵티마이저 쓸지 정해야한다.
다층신경망
-
ReLU function : 시그모이드 함수는 역전파하며 앞으로 갈수록 기울기가 소실되는 현상이 있었다. 은닉층이 많을수록 현상이 심해졌다.
-> 이것을 해결하기 위해 ReLU 함수를 사용하여 해결했다
-> 은닉층에 활성화 함수는 ReLU함수를 준다.
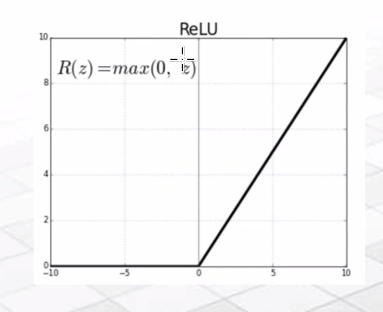
-
Dropout : 은닉층이 계속 쌓이면 오버피팅이 되는 현상이 발견된다. 파라미터가 너무 많아서 발생하기 때문이다.
-> 이것을 해결하기 위해 Dropout기법을 준다. 한 에포크마다 은닉층의 노드가 일부만 학습하고 일부는 학습하지 않는 방식으로 한다. 랜덤하게 선택이 된다.
model_cancer.add(Dense(frist_hidden_node, # input_node연결
activation="relu",
input_shape=(input_node,) # frist_hidden_node와 연결
))
model_cancer.add(Dense(output_nide,
activation="sigmoid",
# 두번째 레이어부턴 input_shape을 써줄필요가 없다. 알아서 이어진다.
))-> 두번째 레이어부턴 input_shape을 써줄필요가 없다. 알아서 이어진다.
-> 출력층의 활성함수는 이진분류이므로 시그모이드
📖 어려운 부분
- loss 손실함수가 뭐?? 왜 accuracy와 반비례??
- epoch-loss 그래프에서 정확도 비교할때, 왜 6쯤에서 끊는건지?
- grid_search에서 FRC할때 왜 cv?
- verbose 가 뭐
