
📖 학습한 내용
- Confusion-Matrix
- Classification-Report
- titanic accuracy mini competition
📖 핵심내용
📌 Confusion Matrix
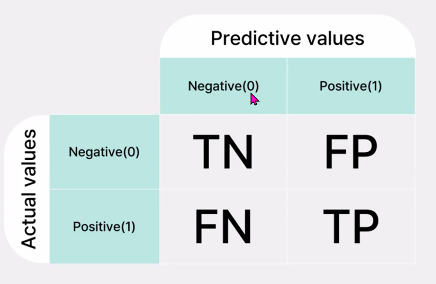
-> 행이 우리가 가진 정답
-> 열이 모델이 예측한 정답
-> predict기준으로 간다
- precision , recall
-> predict 기준으로 볼지
-> 실제 값 기준으로 볼지
-> 문제에 따라 accuracy가 중요할 수도, precision이 중요할수도, recall이 중요할 수도 있다.
-> 문제에 따라서 고려할때의 가중치가 중요하다.
📌 Classification Report
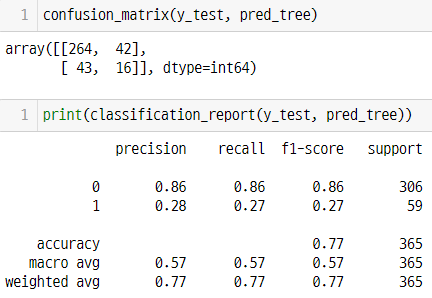
print(classification_report(y_test, pred_tree))
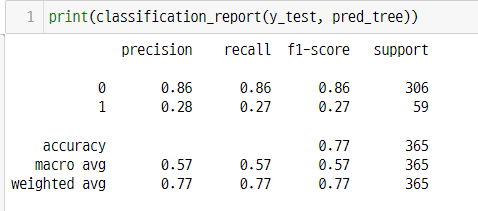

f1-score : 데이터의 불균형이 높을때 사용한다. 조화평균을 사용하여 나왔다.

- 데이터의 불균형을 맞추는 방법
- 적은 데이터의 숫자를 기준으로 많은 데이터 줄이기
- 많은 데이터의 숫자를 기준으로 적은 데이터 늘리기
📖 흥미로운 점 / 새로 알게된 점
-
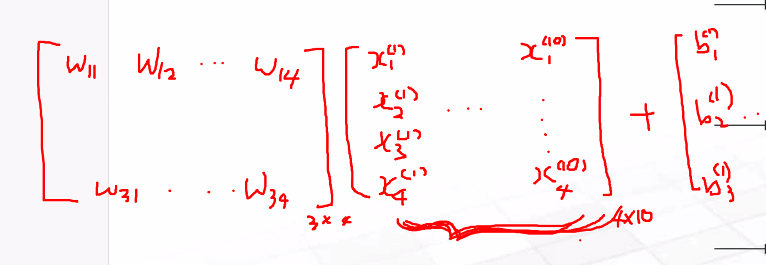
배치사이즈에 따라서 계산식
예) 배치사이즈가 10일때
-
비용함수
다중분류- 카테고리컬 크로스엔트로피
이진분류 - 바이너리 크로스엔트로피 -
dropout 기법
파라미터를 꺼준다. -
결과분석에서는 accuracy 만보면 안된다.
Confusion Matrix
-
accuracy
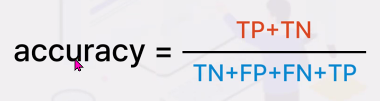
-
정밀도 precision
'예측값'을 기준으로 한 '정답인 예측값'의 비율
precision 값이 낮아려면 fp 값이 커져야한다.
예를 들면 카드 사용자에게 이상감지가 되었다고 자꾸 연락이 가면 신뢰할 수없게되므로 precision을 낮추는게 중요하다. -
재현율 recall
'실제 값'을 기준으로 한 '정답인 예측값'의 비율
recall 값이 낮으려면 FN 값이 커야한다. -
예시
유방암에서 0:악성, 1:양성 일때, FP값이 더 중요하다.
왜냐하면 암이 안걸린 경우 걸렸다고 예측하면, 추가적인 검사를 하면 되지만, 걸렸는데 안걸렸다고 예측하면, 사람의 생명이 달려있기 때문이다.
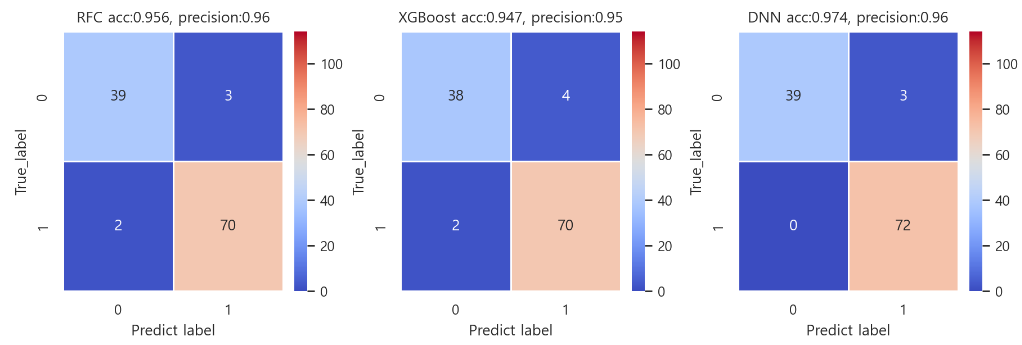
-> 3가지 모델 중 dnn모델이 precision 값이 크고 정답률이 높으므로 선택해야한다.
📖 어려운 부분
-
loss의 개념, 성질과 명칭
-> loss function은 손실함수라고 하고 같은 말로 cost function(비용함수), objective function(목적함수)를 사용
-> 손실함수는 모델의 출력이 나오고 나면 출력값과 정답 사이의 거리를 측정하는 함수이다. 따라서 학습이 진행될수록 train이든 validation이든 loss는 줄어야한다.
-> 반면 학습이 진행될 수록 train이든 validation이든 정확도는 올라가야하므로, 정확도와 손실함수는 반비례하는 경향이 있다. -
epoch-loss, epoch-accuracy 그래프에서 각각 학습데이터와 검증데이터의, 손실함수와 정확도를 볼 수 있다. 이때 학습데이터와 검증데이터 간의 차이가 나면 오버피팅의 신호인 이유
-> epoch-loss에서 학습데이터는 loss값이 줄어드는데 검증데이터는 loss값이 늘어나거나, epoch-accuracy에서 학습데이터는 accuracy값이 증가하는데 검증데이터는 accuracy값이 줄어든다는 뜻은 학습데이터에만 데이터들이 너무 잘맞게 되는 현상이다. 이를 오버피팅이라고한다. 따라서 callback 속성의 earlyStopping을 이용해서 학습을 빠르게 끝낼 수 있다. -
딥러닝 모델만들때 verbose 속성
-> verbose 속성은 학습 하는 동안의 정보를 주는 것이다. 0 일때는 학습과정을 보여주지 않는다. -
근데 네거티브 파지티브를 뭘로 기준으로 잡나
-> 기준이 없다. 사용할 때, 0과 1에 설정한 클래스만 정확하게 알고있다면 문제가 없다. 해석도 상관이 없다.
📖 이후 학습 계획
- 모델 결과 분석 (Sampling의 종류와 기술/AUC-ROC curve)
- ML 모델 이해 (Clustering/Clustering 실습)
📖 기타
미니 대회 - 타이타닉 데이터 모델 적용
타이타닉 데이터를 가지고, 여러 모델에 적용하여 정답률 경쟁을 해봤다.
전처리와 사용한 피처
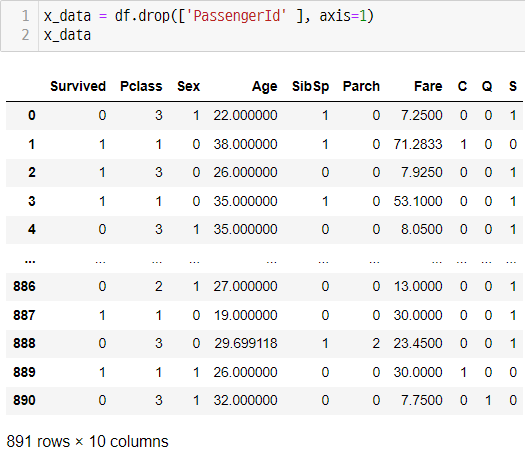
-> Age 피처의 결측치는 Survived=0과 Survived=1로 분류하여, 각각의 평균을 넣어줬다.
-> Embarked 피처의 결측치는 2개 밖에 없고, 티켓번호 기준으로 정렬하였을 때, 위아래로 연속된 경우가 많아 S로 채워 넣었다. Embarked 는 C, Q, S 원핫인코딩했다.
-> 나머지 사용되지 않은 피처는 모두 드랍했다.
사용한 모델
1) 머신러닝
def grid_search(params, model):
model_grid = GridSearchCV(model,
params,
cv=5,
return_train_score=True,
n_jobs = -1
)
model_grid.fit(x_train, y_train)
print('최상의 매개변수: ', model_grid.best_params_)
print('훈련 데이터의 최고 정확도: ', model_grid.best_score_)
model_best = model_grid.best_estimator_
pred_best = model_best.predict(x_test)
print('테스트 데이터의 최고 정확도: ', metrics.accuracy_score(pred_best, y_test))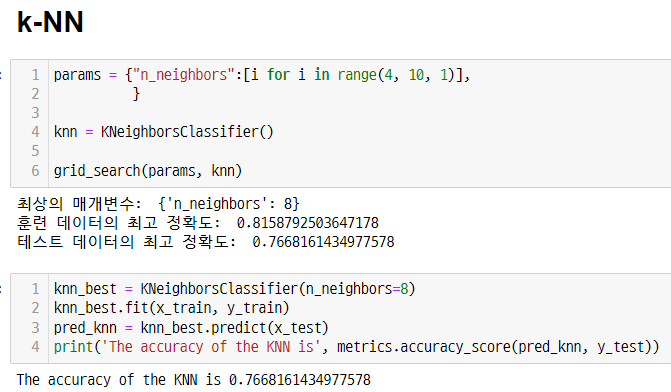
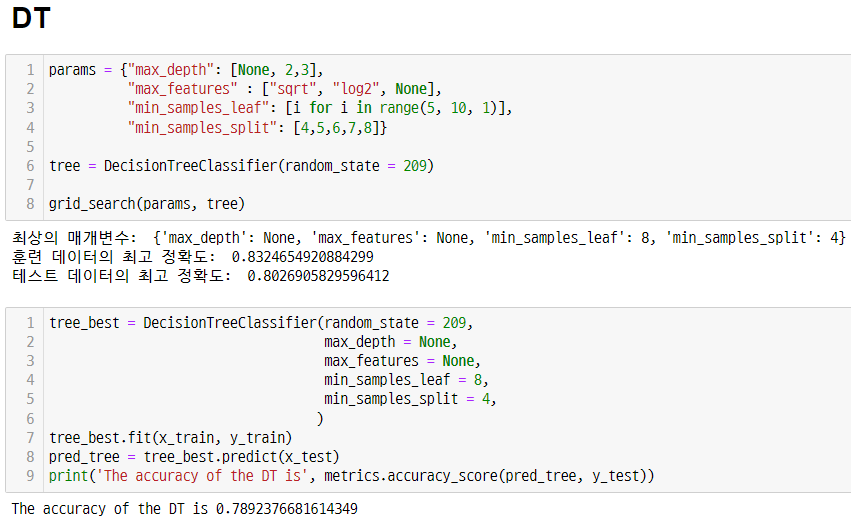
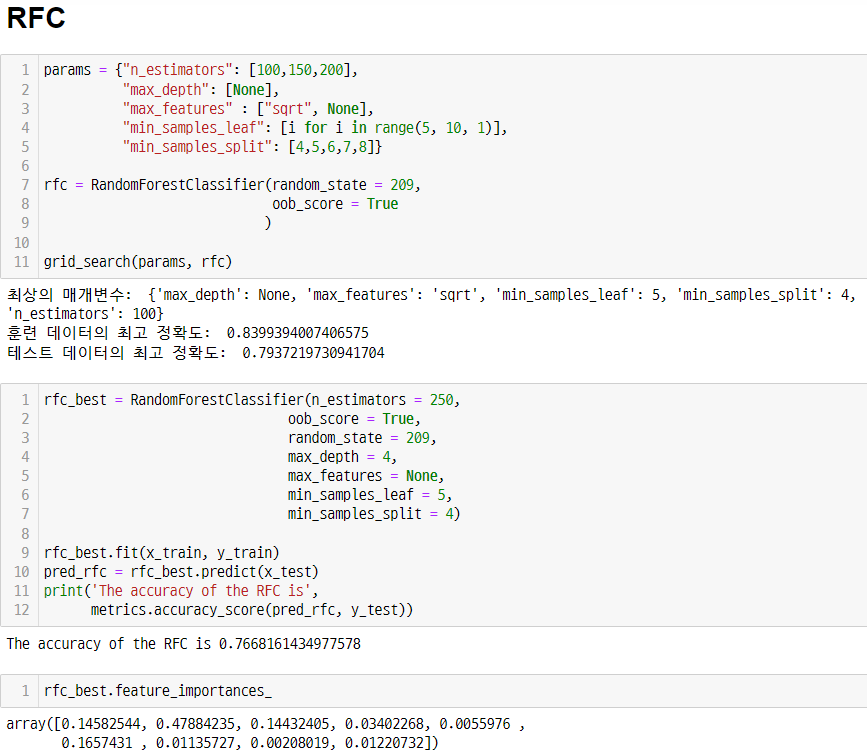

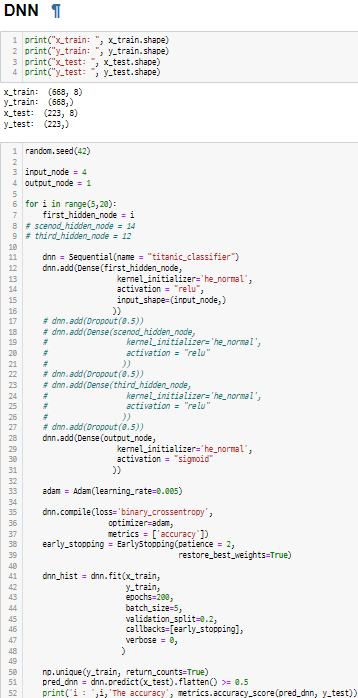
2) 딥러닝
결과
1) 먼저 머신러닝의 여러 모델을 적용하고 grid-search로 속성의 최적화를 했다. 가장 높게 나온 모델이 RFC의 0.784
2) 이후 DNN 모델의 층의 개수, 그때 노드의 수, Dropout, learning_rate, epochs, batch_size 를 조정하면서 accuracy를 올렸다.
3) 하지만 결과값이 RFC를 넘지못하였고, 78% 정답률은 너무 낮다고 판단하여서 피처를 조정하였다.
4) RFC의 feature_importances_를 보고
Sex, Fare, Pclass, Age 이외 다른 피처는 영향을 덜 준다는 것을 판단
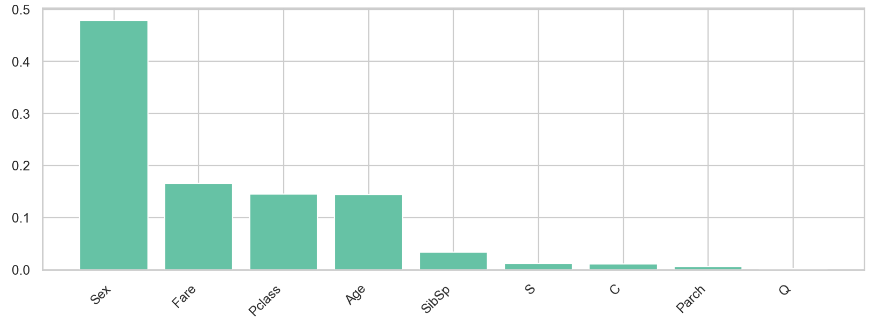
5) XGBoost의 feature_importances_를 보고 RFC와 더불어 하위에 있는 Parch 와 Q는 학습에 영향을 주지 않는다는 것을 의심
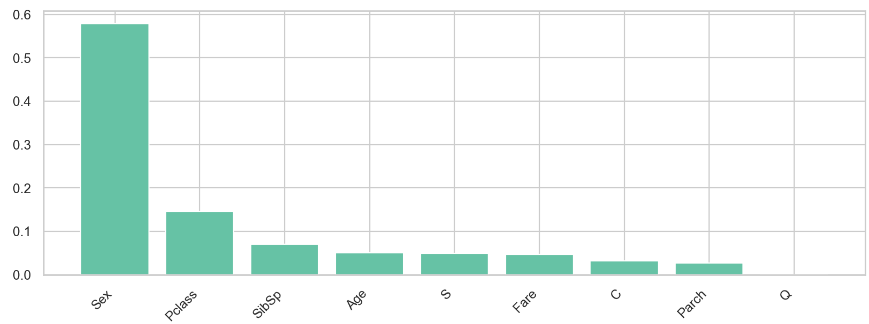
6) Pclass, Sex, Age, SibSp, Fare, C, S 피처로 모델을 돌려봤지만, 모든 모델에서 성능이 하락한 것을 확인하였다.
7) 그래서 가장 영향이 컸던 Pclass, Sex, Age, Fare 만 모델을 돌렸더니, DT에서 가장 높은 0.842 정확도가 나왔다.
그리고 RFC의 성능도 올라왔다. 하지만 DNN의 성능이 많이 떨어진 것을 확인했다.
8) 여러 조건을 바꿔보면서 했지만 더이상 올릴 수 없었고, 이 이상 accuracy를 올리려면 전처리 과정을 살펴봐야겠다고 생각했다. 하지만 컴퓨터 성능의 부족과, 시간이 부족하여 정답을 제출하였다.
인사이트
- 모델을 전처리하는 과정이 매우 중요하다는 것을 느꼈다. 아무리 조건을 바꿔도 성능이 눈에 띄게 좋아지지는 않았고, 한번 모델에 넣고 돌리는데 시간이 오래 걸렸기 때문이다. 시간과 나의 부족한 실력을 최대한 매꾸려면 전처리를 섬세하게 해야한다는 것을 알았다.
이상치와 결측치를 좀 더 섬세하게 관찰하고 채워 넣기 위해서는 도메인에 대한 지식이 필요한데, 한 분야에 대해 오랫동안 근무하는것이 중요하다고 생각을 했다.
