
📖 학습한 내용
- 1주일 학습 복습
📖 핵심내용
📌 이번주 복습
-
Confusion Matrix
Predict를 기준으로 생각하자
-> 1이라고 예측했는데 얼마나 맞았는지 : precision 정밀도
-> 0이라고 예측했는데 얼마나 틀릴지 : recall 재현율
이렇게 생각하면 그나마 덜 헷갈린다.
-
precision 과 recall
결과 정확도가 돌이킬수 없게 중요하면, recall을 정답율과 함께 보자
결과 정확도보다 다른 것이 중요하다면, precision을 정답율과 함께 보자.
모델을 학습시키고 그 결과를 평가할 때는 문제에 따라 accuracy, precision, recall의 수치를 중요하게 보며 모델의 결과를 분석해야한다. -
f1-score
모델의 정밀도와 재현율을 모두 고려한 평가 지표. 모델의 정밀도, 재현율을 종합한 성능을 수치화하고 싶을 때 주로 사용되며, 모델의 균형 잡힌 성능을 측정하는 데 사용된다.
최소 0, 최대 1의 값을 가지고, 높을수록 좋은 성능을 나타낸다.
-
batch size
총 100개의 문제가 있을 때, 20개씩 풀고 채점한다면 Batch 크기는 20입니다. 사람은 문제를 풀고 채점을 하면서 문제를 틀린 이유나 맞춘 원리를 학습하죠. 딥러닝 모델 역시 마찬가지입니다. Batch 크기만큼 데이터를 활용해 모델이 예측한 값과 실제 정답 간의 오차(conf. 손실함수)를 계산하여 Optimizer가 parameter를 업데이트합니다. 아래의 그림 1처럼, 전체 데이터가 3,000개이고 Batch 크기가 300이라면, 데이터를 300개씩 활용하여 모델을 점차 학습시켜 나갑니다.

-
Epoch
Epoch는 '에포크'라고 읽고 전체 데이터셋을 학습한 횟수를 의미합니다.
사람이 문제집으로 공부하는 상황을 다시 예로 들어보겠습니다. Epoch는 문제집에 있는 모든 문제를 처음부터 끝까지 풀고, 채점까지 마친 횟수를 의미합니다. 문제집 한 권 전체를 1번 푼 사람도 있고, 3번, 5번, 심지어 10번 푼 사람도 있습니다. Epoch는 이처럼 문제집 한 권을 몇 회 풀었는지를 의미합니다.
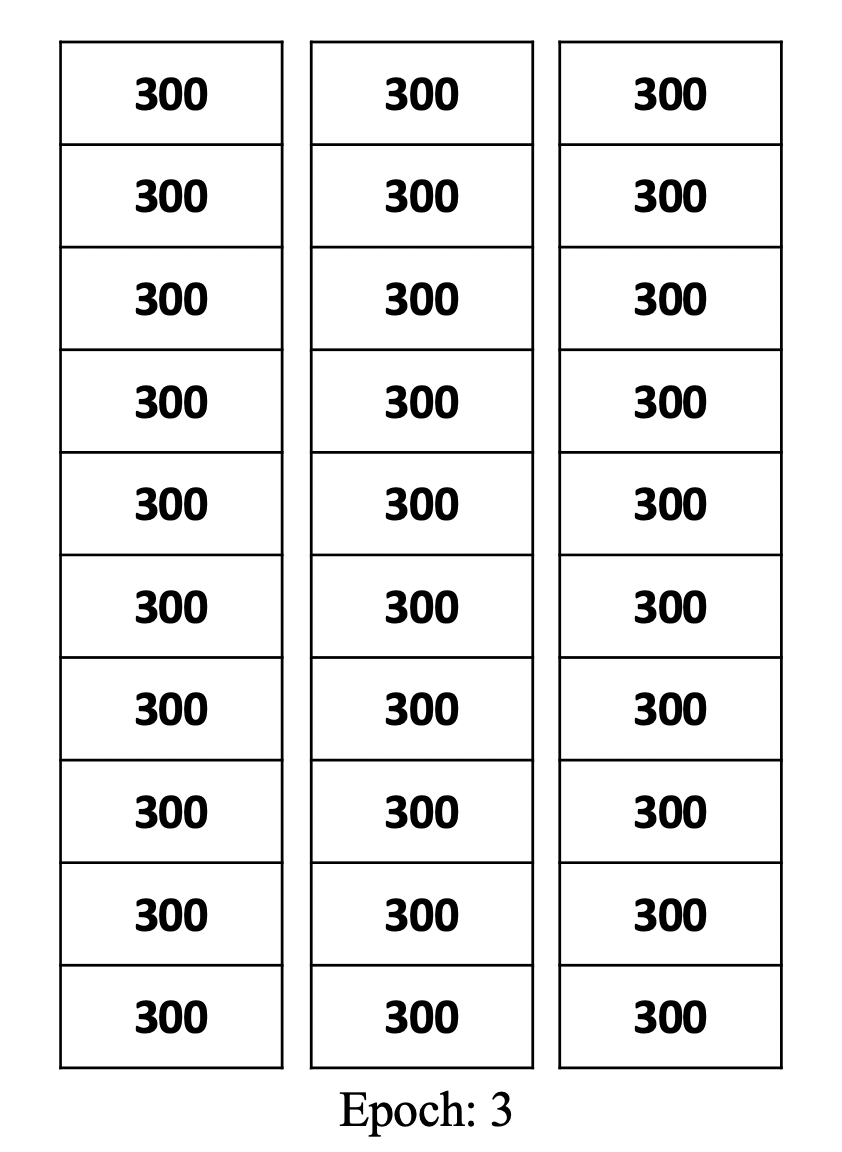
-
딥러닝 지도학습에서 고려해야하는 사항
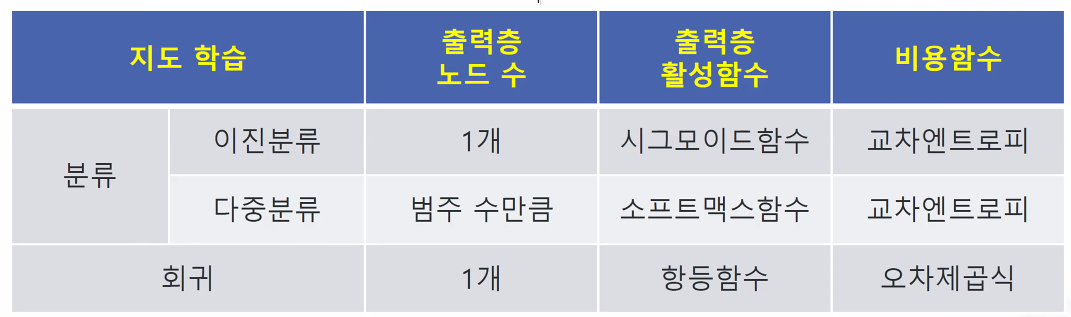
비용함수 :loss='binary_crossentropy' -
순서 헷갈리지 말것
confusion_matrix(y_test, pred_rfc)
metrics.precision_score(y_test, pred_dict[name])
📖 흥미로운 점 / 새로 알게된 점
-
np.unique()
배웠는데 완전히 잊었다
배열에서 중복되지 않은 값을 반환한다.
- 속성
return_index: 처음으로 나온 값의 인덱스를 반환
return_counts: 중복되지 않은 값의 개수를 반환한다. 이것을 쓰면 마치 pandas의value_counts와 비슷해진다.
return_inverse: 값이 작은 순으로 정렬하고 그것을 0과 1로 대체하여 출력. 두 값만 있을 때 마스킹할때 활용할 수 있을 것 같다.li1 = [1] * 6 li2 = [2] * 8 arr = np.array(li1 + li2) a, b =np.unique(arr, return_counts=True) print(a) print(b) -
Optimizer
최적화(Optimization)은 손실 함수(Loss Function)의 결과값을 최소화하는 모델의 파라미터(가중치)를 찾는 것을 의미한다. 그리고 Optimization의 알고리즘을 Optimizer라고 한다.
-> 지금까지 써왔던 Adam도 여기에 포함된다.
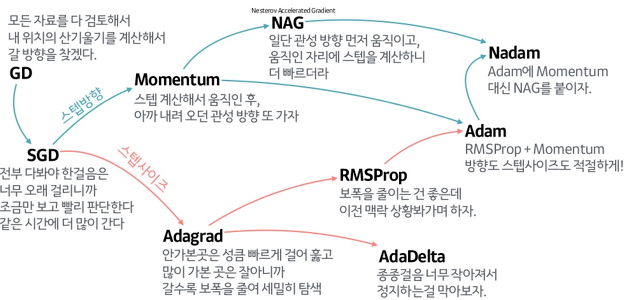
출처 Optimizer|작성자 비전 https://blog.naver.com/another0430/222063836606
