
📖 학습한 내용
- Sampling
- AUC-ROC Curve
- Dropout
📖 핵심내용
📌 sampling
imblearn
파이썬에서 클래스 불균형 문제를 다루기 위한 라이브러리입니다.
훈련 데이터의 크기를 맞추는것이다.
실무에서는 대부분 데이터가 불균형하다.
라벨의 균형을 맞춰주면 모델이 개선될 수 있다.
- 프로세스
x, y =sampler객체.fit_resample(x_train, y_train)
under_sampling
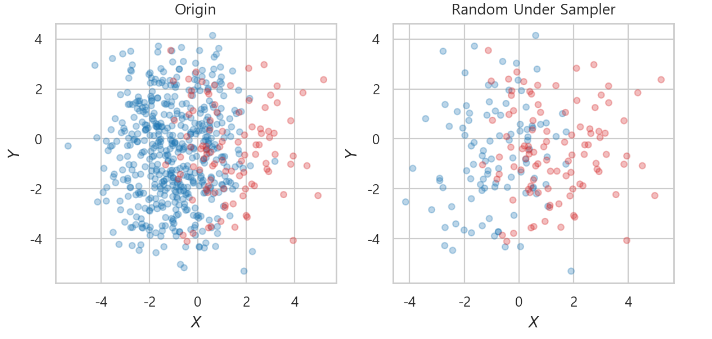
- RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
x_rus, y_rus = rus.fit_resample(x_train, y_train)-> 다수 class 데이터에서 random하게 제거하여 소수 class 데이터량에 맞춤
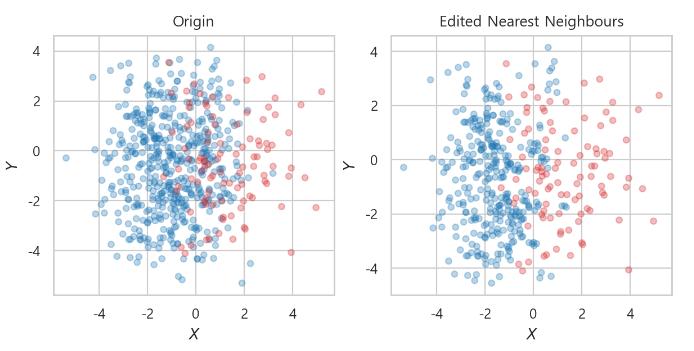
- EditedNearestNeighbours
enn = EditedNearestNeighbours(kind_sel="all", n_neighbors=5)
x_enn, y_enn = enn.fit_resample(x_train, y_train)-> 다수 class 데이터에서 𝑘개(n_neightbors)의 Euclidean distance가 가까운 점을 찾고, 소수 class가 많이 섞여있으면 제거
-> kind_sel="all"이면 주변에 모두 소수 class일 경우 제거
-> 소수의 class 주변에 다수의 class가 제거됨
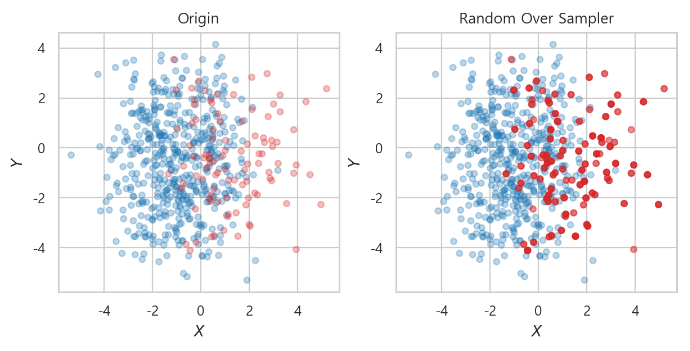
over_sampling
- RandomOverSampler
ros = RandomOverSampler(random_state=0)
x_ros, y_ros = ros.fit_resample(x_train, y_train)-> 소수 class를 랜덤하게 증가시킴
-> 같은 데이터를 반복 생성하여 다수 class에 맞춤
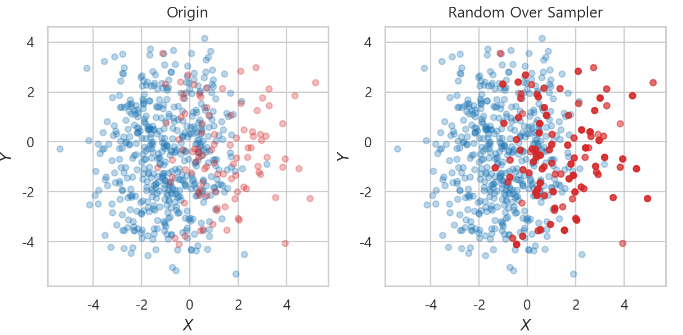
-> 같은 지점이 반복되므로 붉은 색이 진해짐
- SMOTE
smo = SMOTE(random_state=0)
x_smo, y_smo = smo.fit_resample(x_train, y_train)-> 소수의 class에서 임의의 점 𝑎를 택하고 𝑎와 같은 class에서 Euclidean distance가 가까운 5개(k_neighbors)의 점찾아 임의로 𝑏를 택함
-> 𝑎와 𝑏사이에 새로운 데이터를 생성
-> ENN과 반대개념
SMOTEENN
-> 다수의 class는 SMOTE 방식으로 줄이고,
-> 소수의 class는 ENN 방식으로 늘림
smoenn = SMOTEENN(random_state=0)
x_smoenn, y_smoenn = smoenn.fit_resample(x_train, y_train)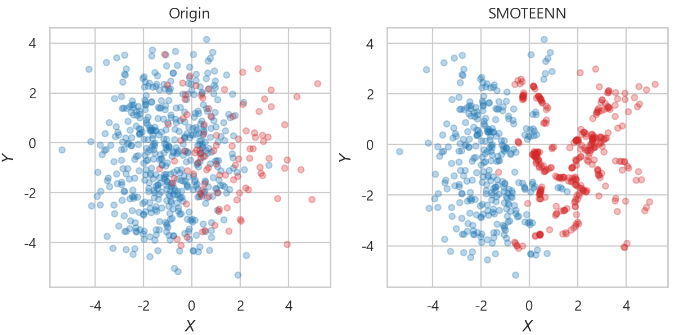
📌 AUC-ROC Curve
-
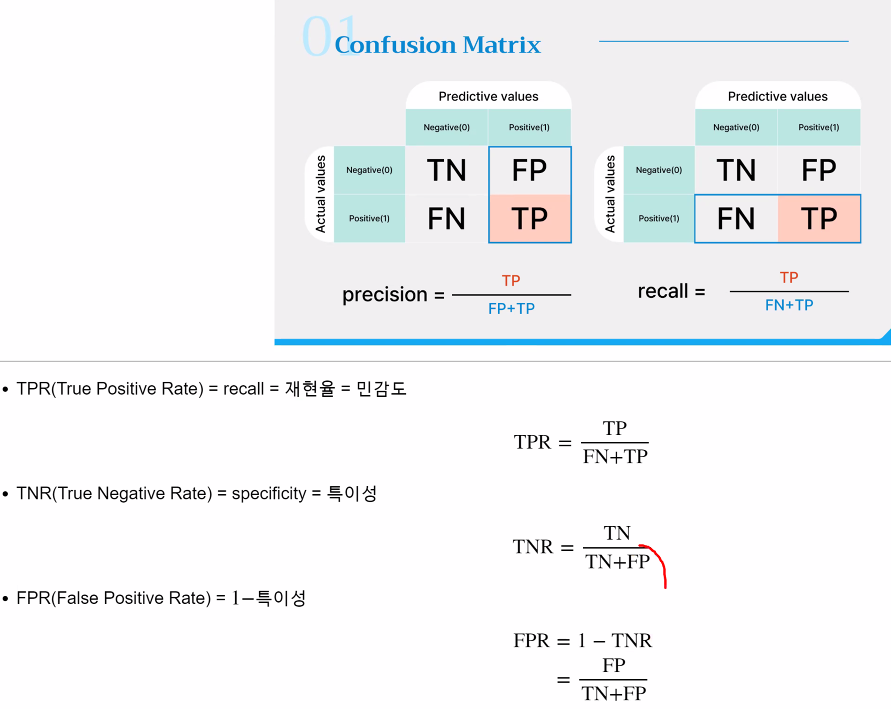
컨퓨전 매트릭스 중요요소
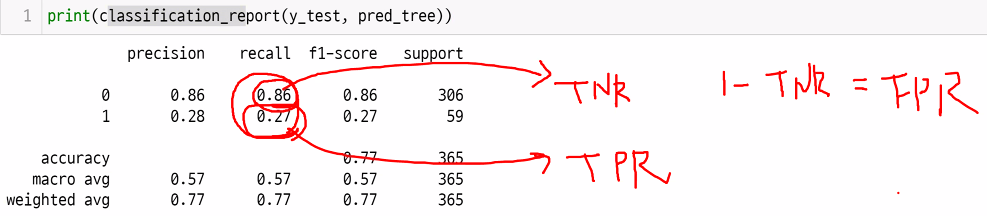
민감도,재현율 : sensitivity,recall : 실제 1 중에, 1로 예측한 것 TPR
특이도 : specificity : 실제 0 중에, 0으로 예측한 것 TPR -> TPR = 1 - FPR
정밀도 : precision : 1로 예측한 것 중에, 실제 1인 것
정확도 : 전체에서 얼만큼 예측과 사실이 맞는지 -
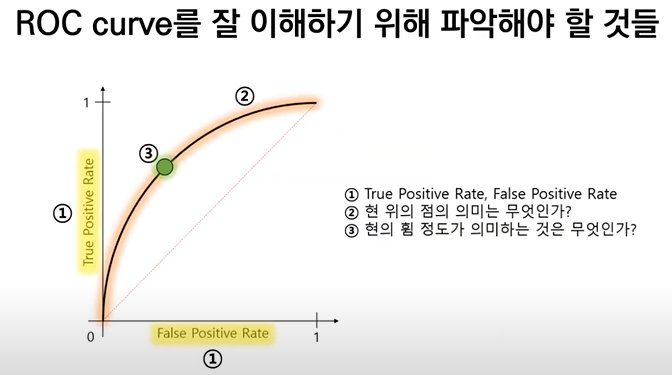
ROC Curve
이진분류기의 성능을 표현하는것.
TPR - FPR 그래프
TPR과 FPR은 어느정도 비례한다.
컨퓨전메트릭스의 특징을 직관적으로 한번에 나타낸 것이다.
출처 https://angeloyeo.github.io/2021/12/13/chi_square.html#google_vignette
- AUC
ROC Curve 의 아래 면적
📌 Dropout
딥러닝 모델의 overfitting을 해결하는 방법
은닉층의 노드를 랜덤하게 꺼서 가중치를 업데이트 하지 않는 방법은 마치 랜덤 포레스트에서 과적합을 피하기 위해 랜덤 샘플링으로 다양한 트리를 만드는 것과 같은 효과로 다양한 딥러닝 모델을 학습시키는 것과 같다
dropout은 batch size마다 바뀌고, Dropout(0.3)이면 해당 층의 30%의 노드를 끈다.(즉, 출력이 없다. 따라서 해당 노드와 관련된 파라미터는 업데이트 되지 않는다.)
📖 흥미로운 점 / 새로 알게된 점
- 데이터 불균형
실무에서는 데이터가 불균형하다.
라벨의 균형을 맞춰주어 모델을 개선한다.
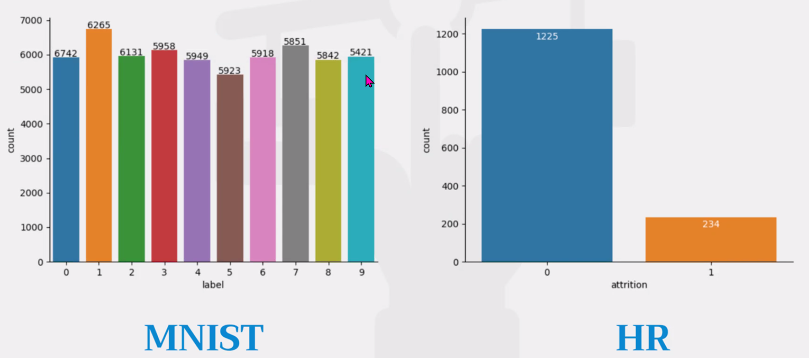
-> mnist는 데이터가 균형있지만, HR은 데이터 불균형이 심하다.
-> 균형을 맞춰줄 필요가 있다.
-
under samlping
-> 다수 클래스에서 랜덤하게 지워가면서 소수 클래스 데이터량에 맞춘다 -
Edited Nearest Neighbours
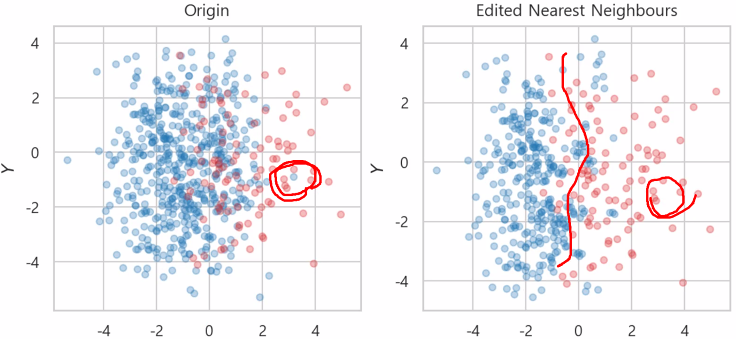
-> 파란점이 많으니깐, 빨간점 사이에 가까운 거리의 5개의 점이 모두 빨간색 (옵션으로주면, 과반수가 빨간색) 이라면, 그 파란점을 제거한다.
-
SMOTE
소수의 데이터 중 하나를 선택하고, 그 데이터에 가까운 같은 클래스 5개를 선택한다. 그중 1개의 데이터를 선택하고, 직선사이의 어느 한점에 데이터를 생성한다.
-> 소수 클래스 근처에 또 많은 데이터가 생긴다. -
combining
-> 적은 점 하나에서는 늘리고, 많은 애들은 줄인다.
-> SMOTE과 ENN이 한번에 적용된 방식 -
ROC curvee
-
roc_curve()
-> fpr, tpr, thr 3가지를 반환한다.
-> 함수안에모델객체.predict_proba()가 들어가야한다.
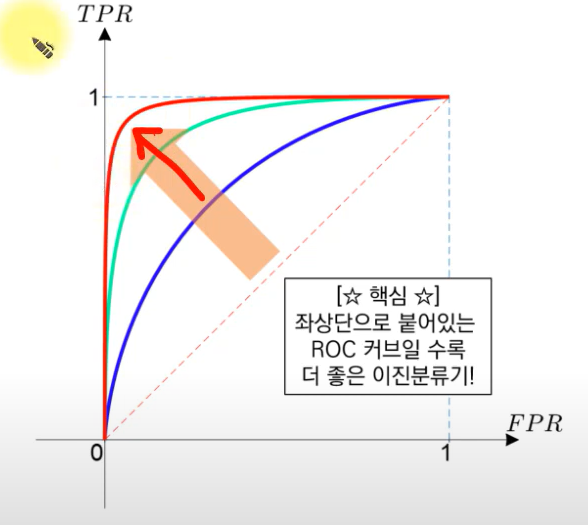
roc커브 아래의 면적이 넓을 수록 좋은 그래프다.
면적을 auc라고한다.
TPR에 가까워지면 좋은 모델이다. 적게 틀리고 많이 맞추는 것이기 때문이다.
fpr -> 클래스0인것중에 틀린것 비중
tpr -> 클래스0인것중에 맞춘것 비중
-> 결국 좋은 모델을 선택하기 위해 roc커브를 그리고 그중 auc가 큰것을 따지는 것이다.
-> 오목하게 그려진 모델은 쓸수가 없는 모델이다
roc_curve(y_test, tree.predict_proba(x_test)[:,1]
-> predict_proba 는 ROC-curve의 값이 0~1 사이이기에 사용한다.
-> [:,1] 은 첫열이 인덱스기에 두번째열을 조회한다.
📖 어려운 부분
-
타이타닉에서 나민원 강사님은 age의 결측치를 등급과 나이를 고려하려 채웠다.
이때 트레인 데이터 먼저 결측을 먼저채우고 그값을 기준으로 테스트 데이터의 결측을 채운다. -
원칙적으로 스플릿을 먼저 한뒤 결측을 채우는 것이 맞다
테스트 데이터는 사실 나중에 들어오기때문에 테스트데이터의 결측은 트레인데이터로 해준다. -
결측치를 잘채웠는지 판단하는 기준 중에 하나가 결측이 있을때의 분포와 결측을 채운 뒤의 분포가 비슷한 경향의 모양인지 보는 것이다. 히스토그램의 빈도로 그리는 방법이나 kdeplot으로 그리거나하여서 판단한다.
-
matplotlib은 결측이 있으면 안그려주고, seaborn은 결측이 있어도 그려준다.
-
머신러닝의 모델 성능을 비교할때 하나의 기준모델로 먼저 돌려보고 성능을 기준으로잡고, 나중에 다른 애들을 돌려보면서 맞춘다.
-
딥러닝 쓰려면 샘플이 적어도 10000개는 되어야한다.
-
가중치는 batch사이즈마다 업데이트 된다. 따라서 dropout도 마찬기지로 이때 랜덤하게 켜졌다 꺼졌다 한다.
-
가중치 값은 정해진건 없다. 0.2 ~ 0.5 정도 준다
-
eopch-loss 그래프는 검증이랑 학습이랑 평행하게 가는게 제일 좋다
📖 이후 학습 계획
- ML 모델 이해 (Clustering/Clustering 실습)
- ML 모델 이해 (선형 회귀/선형 회귀 실습)
📖 기타
알아볼 내용
- dummies 사용방법
- y_data.values 에서 왜하는지 shape차이 없다.
