
📖 학습한 내용
- Data_Category
- 코랩 환경 세팅
- ML 모델 학습
📖 핵심내용
📌 Data_Category
데이터 유형
-
정형데이터
정형데이터는 테이블 형태로 구성되어 있는 것이다.
대체적으로 양적데이터
분석이 편하고 쉬워서 다양한 분석이 가능하다. -
비정형 데이터
구조가 없다.
전처리가 매우 중요하다. -
정형데이터의 표에서 여러표현
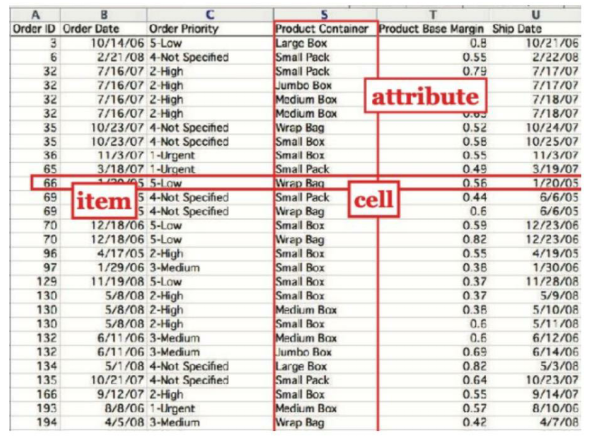
attribute : 속성 row 피처
item : 레코드 튜플 -
시계열 데이터 (시퀀셔널 데이터)
순서가 중요하다. -
비정형데이터
앞으로도 꾸준히 폭팔적으로 늘어날 것이다
빅데이터를 많이 활용한다
비정형데이터만 잘한다고 정형데이터를 잘할 수는 없다.
여전히 전통적인 방법들인 클러스터링 등등 많이 사용하고 있다.
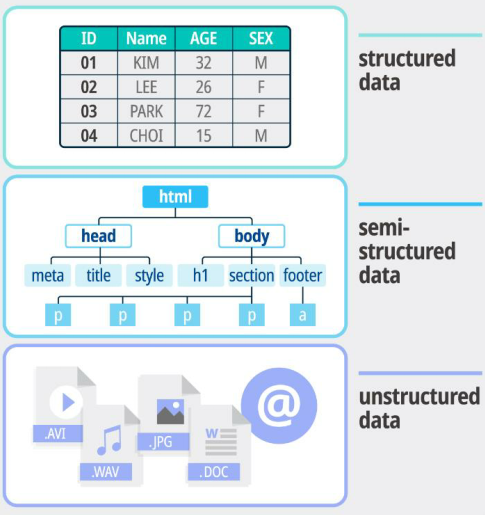
비정형데이터 분석에 방법론 알고리즘 이런것들을 적용하는데 있어서는 정형데이터와 같다. 다만 전처리 방법이 다를뿐이다. 따라서 정형데이터 분석도 매우 중요하다.
- 자료형
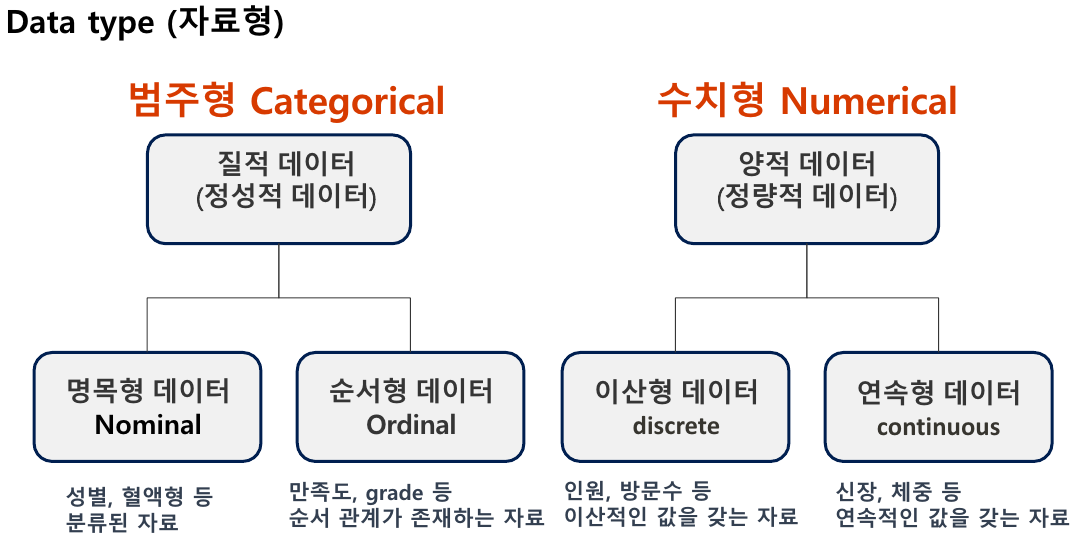
-> 어떤 데이터 타입이냐에 따라서 적용되는 방법론이 다르다. 따라서 내가 다루는 데이터가 무슨 타입인지 먼저 파악하는게 가장 중요하다. 용어와 개념을 매우 잘 기억해두자
-> 이산형데이터 : 정수타입으로 저장되는 것
-> 연속형데이터 : 플롯타입으로 저장되는 것
-> 순서형데이터(ordinal) : 순서적인 의미가 있는 것. 학점 성적(A B C..), 만족도(10 9 8..)
-> 명목형데이터(norminal) : 성별 혈액형
📌 코랩 환경 세팅
데이터 분석
use industry knowledge -> 도메인 지식
통계적인 지식은 현업에서 상당히 중요하다.
- 데이터 분석 프로세스
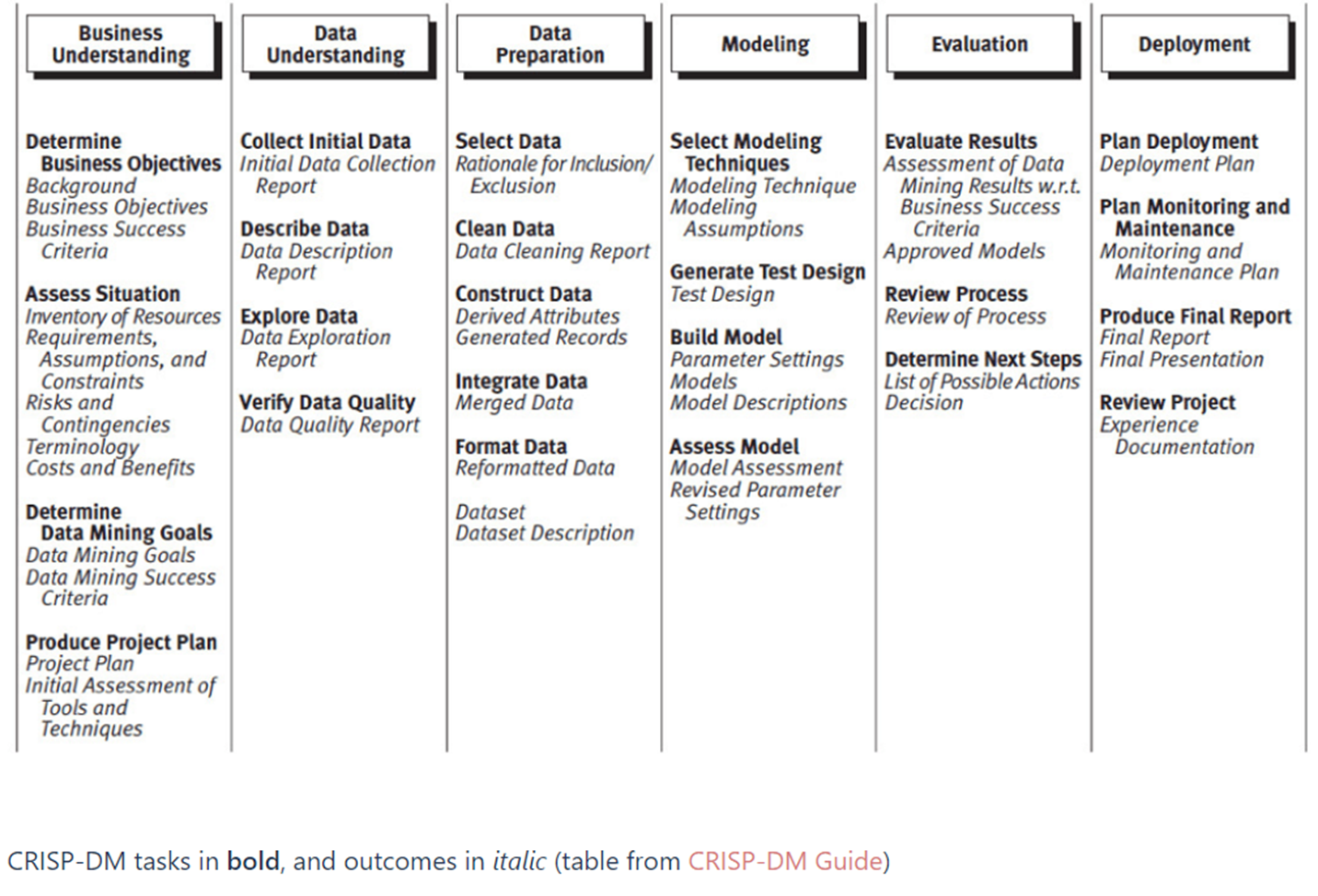
-> 도메인에 대한 이해
-> 데이터이해 - EDA 시각화는 많이 하므로 굉장히 중요하다.
분석가로서 우리가 데이터를 이해하기 위한 시각화. 주요피처를 변별해내는 과정이 매우 중요한데, 이때 시각화가 매우 매우 중요하다.
프레젠테이션 할때, 시각화 이미지를 잘 활용해야한다. 크고 작은 발표 경험이 있는데 시각화가 매우 유용하다. 타부서나 상사한테 설명하기 좋다
-> 평가후에 이전과정 어디론가로 돌아간다.
데이터 분석을 위한 도구 - 파이썬은 매우 많은 사람들이 쓰고 간결하다.
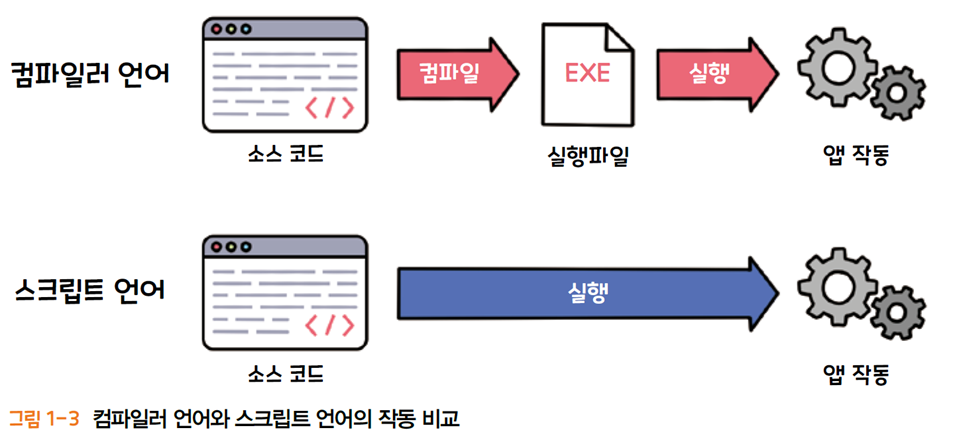
- 컴파일언와와 스크립트 언어
컴파일언어 : 코드를 기계어로 번역하고 실행한다.
-> C, C++, Java, C# 등
스크랩언어 : 인터프리터, 결과를 바로 해석한다.
-> 파이썬, 자바스크립트(JavaScript), 펄(Perl)
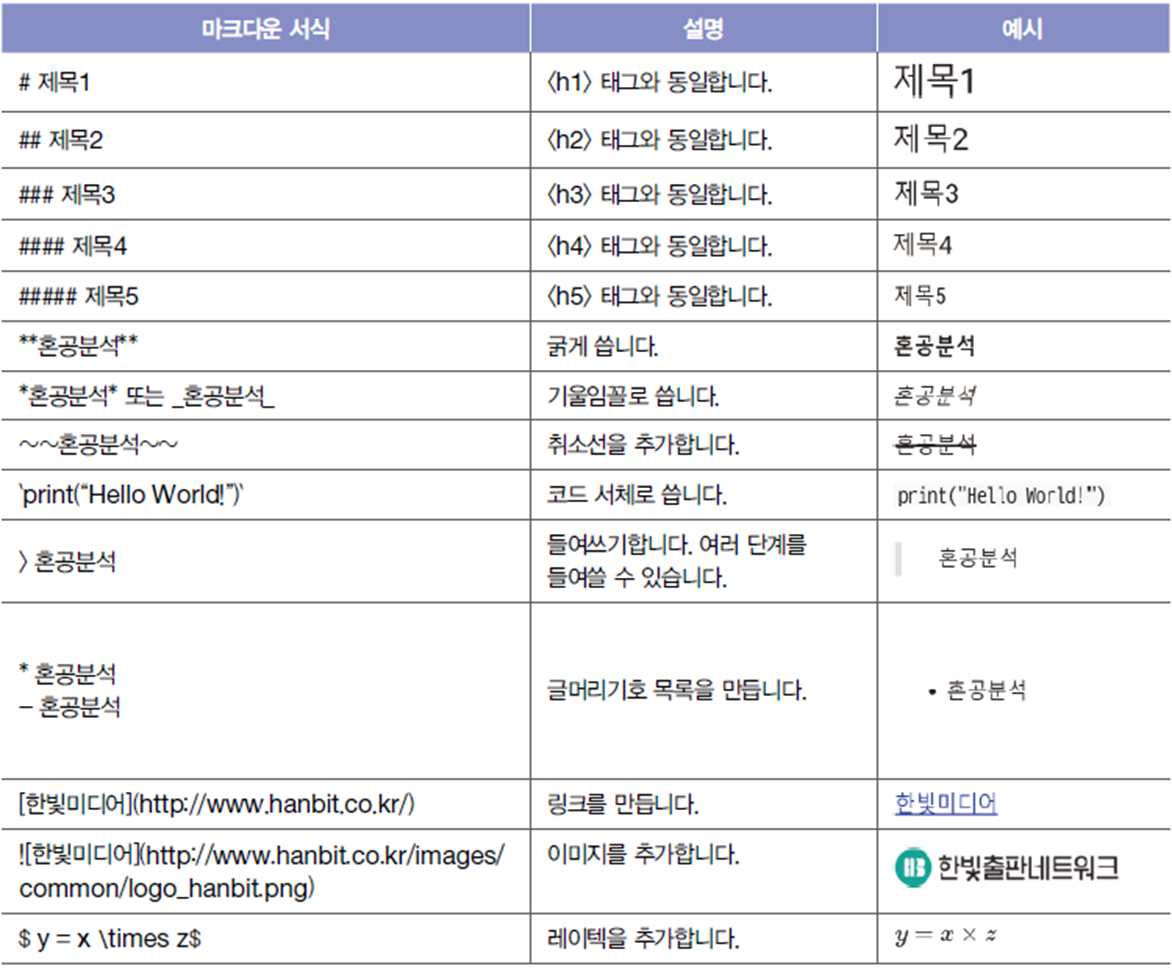
마크다운언어
구글 코랩
텍스트 셀에는 HTML(Hypertext Markup Language)과 마크다운(Markdown)을 혼용해서 사용 가능
- 구글드라이브에 저장하기
from google.colab import drive
drive.mount('/content/drive')코드를 이용해서 경로를 가져와야한다.
- 마크다운
📌 ML 모델 학습
Linear Regression with Pytorch
-> 평균으로 회귀한다는 것이 어원
언어모델은 다음 단어 중 가장 높은 확률로 나올 것을 반환하는 분류모델이다.
소프트맥스 함수는 답이 될 수 있는 것들 중에 가장 높은 확률인 것이 증폭되어서 반환된다.
-
인공지능에서 학습이란?
패턴을 인식하고 이를 기반으로 예측 수행하는 것
회귀모델은 출력노드가 1개이다
옵티멀 벨류를 찾아가는 과정 -
독립변수와 종속변수 간의 최적의 관계를 파악하는 것
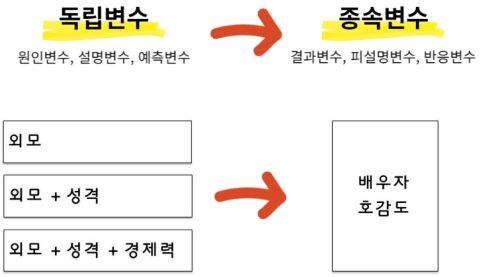
-> 이외에도 피처 타겟 x,y 등 용어에 익숙해져야한다.
기계학습 알고리즘 종류

-> 비지도학습의 가장 대표적인게 클러스터링(비슷한 것끼리 분류하기)
-
머신러닝이란, 명시적으로 규칙을 프로그래밍하지 않고, 데이터로부터 의사결정을 위한 패턴을 기계가 스스로 학습하는 것이다.
-
뉴럴네트워크 구조
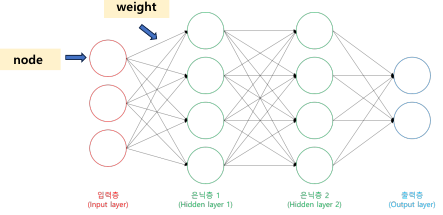
네트워크 구조에서 임의로 설계할 수 없는 것 -> 입력과 출력
은닉층을 깊게하면 더 정교하게 답을 예측할 수 있다.
하지만 너무 많이 늘리면 과적합과 어큐러시가 떨어진다
trade off : 모델성능, 오버핏, 학습속도 간에 최적점/균형점을 잡는 것 -
손실함수
손실함수는 정답과 예측값의 차이를 계산한다. -
옵티마이져
손실함수를 통해 얻은 손실값으로부터 모델을 업데이터하는 방식
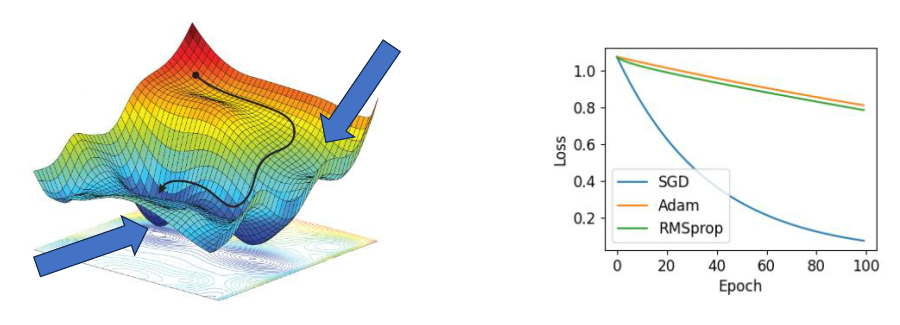
-> 글로벌미니멈을 찾아가는 방식이다.
📖 흥미로운 점 / 새로 알게된 점
- 강의 중 y 예측값을 y헷이라고 부르는 것을 알았다
📖 이후 학습 계획
- ML 모델 적용 및 이해 (DT, Clustering/Logistic, SVM)
- DL 모델 적용 및 이해 (활성화 함수, 경사하강법/오차역전파, optimizer, 과적합)
