
📖 학습한 내용
- optimizer
- backpropagation
📖 핵심내용
📌 optimizer
-
손실함수
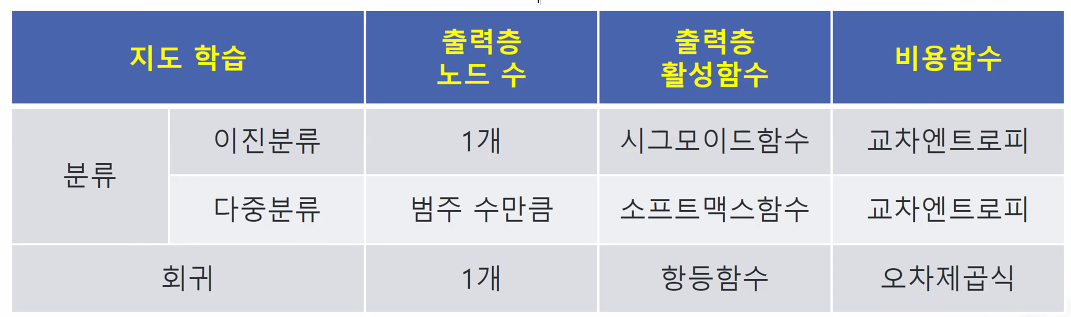
기본적인 손실함수는 이진분류 - 바이너리크로스엔트로피, 다중분류 - 카테고리컬크로스엔트로피, 회귀 - 오차제곱식이 있다. 이외에도 여러 손실함수가 있다. -
딥러닝의 목표
정답과 예측값의 거리를 최소화해주는 하이퍼파라미터, 가중치와 바이너리를 찾는 것이다.
딥러닝에서 다변수 함수를 미분하기 위해 편미분이 필요하다. -
체인룰, 합성함수의 미분
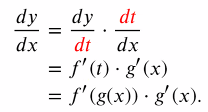
-
신경망의 학습
정답과 출력사이를 가깝게하도록 가중치와 바이어스를 갱신하여 최적의 해를 찾는 것이 신경망의 학습 목표 -
딥러닝에서 최적화 푸는 방법은 수치 최적화 알고리즘 방식
-> 나머지 방법은 너무 많은 변수를 넣어봐야하기 때문에 현실적으로 불가능하다.
수치최적화 알고리즘
-> 손실함수의 최솟값을 찾아가는 방법들 -> 옵티마이저
-> 수치 최적화 방법은 반복법(정해진 방법을 되풀이 하여 값을 업데이트하는 방식)을 사용 하여 문제를 푼다.
-> 방향과 스텝의 크기를 정해준다.
-
모든 수치 최적 알고리즘은 국소 최솟값은 찾아주지만 항상 전역 최솟값을 찾을 수는 없다.
-
최근에 고안된 수치 최적화 알고리즘은 한계점을 완화시킬 수는 있지만 그렇다고 항상 전역 최솟값을 찾아 주는 것은 아니다.
스탭방향 기반 알고리즘
- 방향은 고정하고 학습률을 변화시킨다.
- Stochastic Gradient Descent, Momentum, Nesterov
Stochastic Gradient Descent
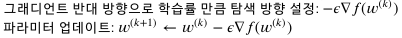
-
최소값을 찾는 것이기 때문에, 가장 가파르게 움직이는 방향의 반대방향으로 이동
-
입실론(학습률)이 learning_rate
-
학습률 민감성 : 학습률에 굉장히 민감하다. 너무 크면 발산하기때문이다.
-
초깃값 민감성 : 초기값에 민감하다. 어디에서 시작했느냐에 따라서 전역 최소값이든 국소 최소값이든 갈 수 있기 때문이다.
-
국소최소값(local minimum), 전역최소값(global minimum)
-> 로스펑션의 글로벌 미니멈을 찾는것
Momentum/네스테로프
- 그래디언트 디센트 방법은 국소 최솟값에 빠지게 되면 빠져나갈 방법이 없다.
- 그래디언트를 찾고 과거의 것도 보는것
- Momentum는 전 단계의 탐색 방향의 누적합에 현재 단계의 그래디언트 디센트를 더해서 탐색 방향을 찾기 때문에 국소 최솟값을 벗어나 전역 최솟값으로 갈 수 있게 해준다.
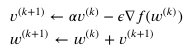
Nesterov가 Momentum보다 그래디언트 계산을 좀 더 정확하게 해주기 때문에 수렴 속도가 더 빠르다.
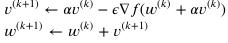
SGD
GD는 샘플이 너무 많기 때문에 계산량이 너무나도 많아진다.
초기 가중치에서 데이터를 섞고 배치사이즈만큼 자른다.
모멘텀에서
과거의 그래디언트에 알파(0~1사이값)가 곱해진 값이다.
스탭사이즈(학습률) 기반 알고리즘
-
학습률을 고정하지 않고 매번 적절한 학습률을 계산 학습률을 고정하는 방법은 학습률에 따라 최솟값으로 수렴이 너무 느리거나 발산할 수는 문제 발생
즉, SDG, Momentum, Nesterov는 이 문제를 피해갈 수 없음 -
로스함수가 커진다면 학습률은 그대로 가지만, 로스함수가 줄어든다면 학습률의 크기를 줄인다.
-
⊙ : 같은 위치의 곱끼리 같은것(넘파이배열의 곱
-
adagard
그래디언트의 제곱의 누적합
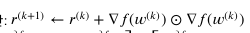
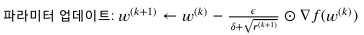
RMSProop
너무 오래된 그래디언트는 반영을 적게하겠다.
학습률과 그래디언트도 반영하지만, 오래된 그래디언트의 영향은 적게 받겠다.
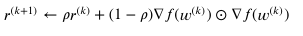
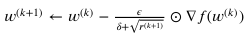
- Adam
Momentum과 RMSProp의 조합. 즉, 탐색 방향도 보고, 학습률도 갱신하는 알고리즘
최소값으로 꽤 잘찾아간다.
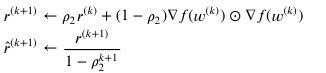
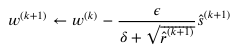
- 어떤 알고리즘도 딥러닝 모델의 최적화 문제를 완벽히 풀 수 없음
- 선호도를 바탕으로 실험을 하면 노하우가 생기게 된다.
- 개인의 딥러닝 모델 구성 능력은 이론과 많은 실험의 결합으로 향상시켜야 한다
은닉층이 있을때
- 단층신경망에서의 출력
📌 backpropagation
역전파
초기
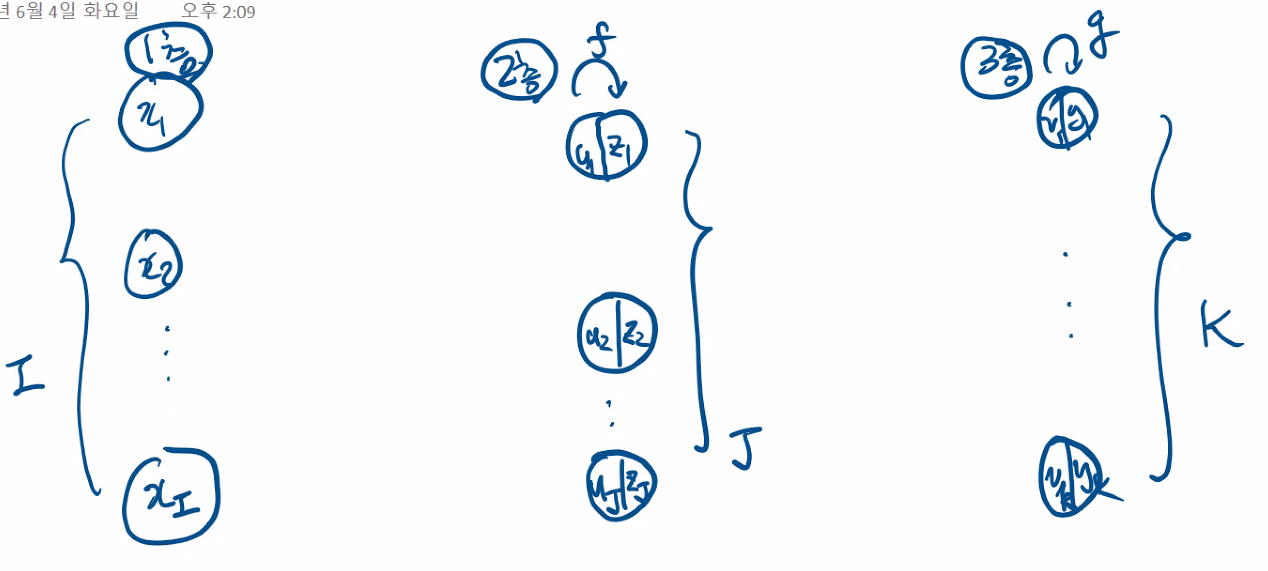
f:1층 활성화함수 g:2층활성화함수
y:출력
순방향
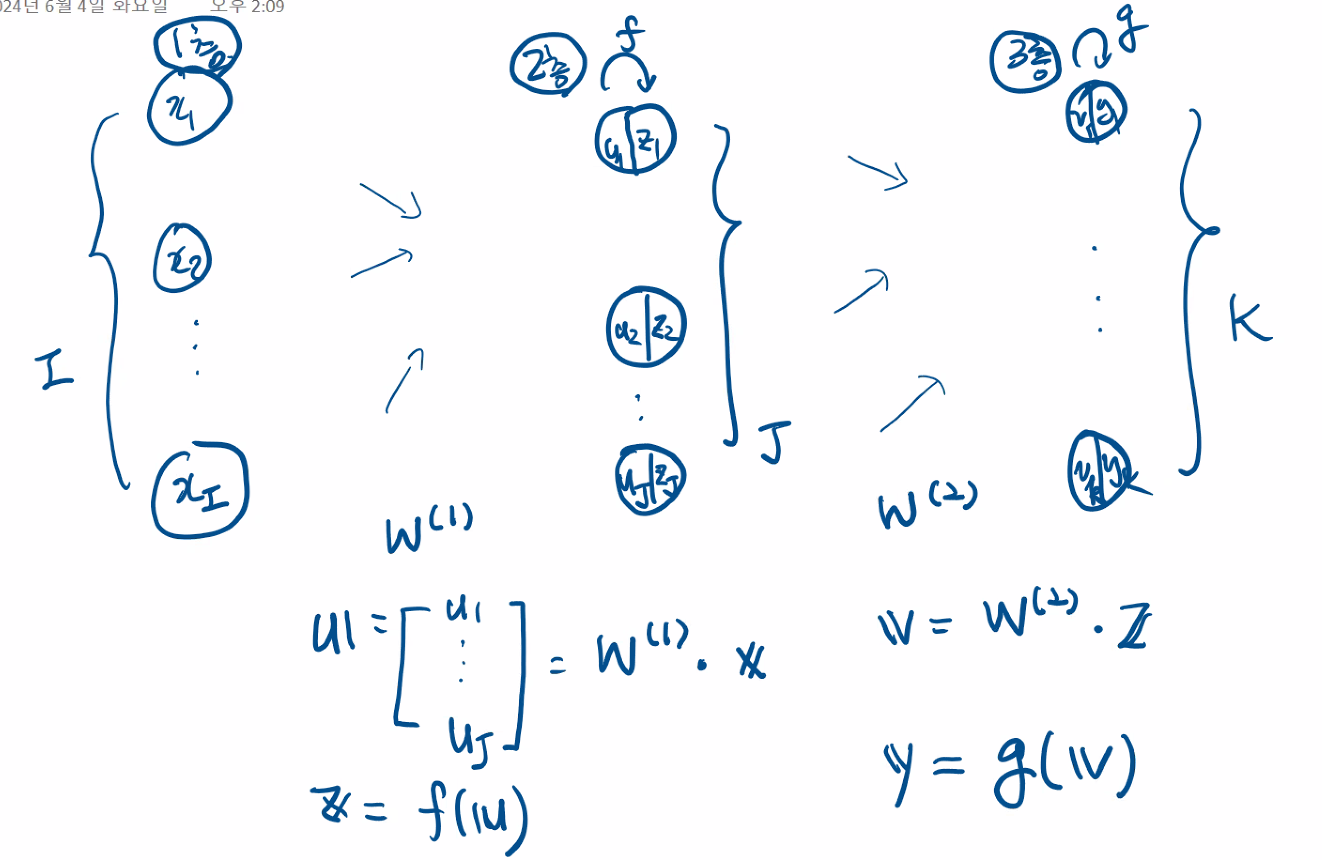
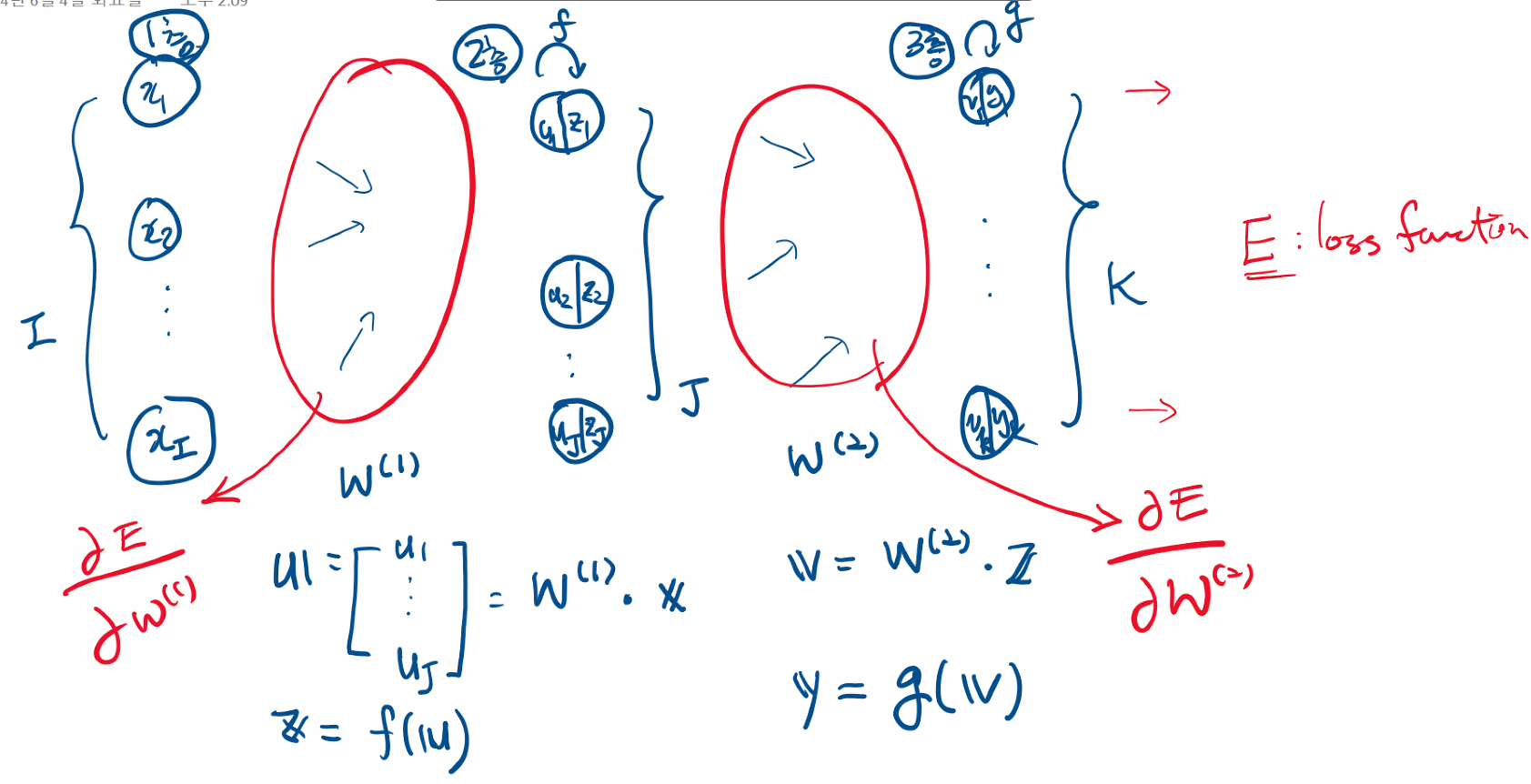
역전파-가중치 갱신
모든 가중치들은 결과에 영향을 줬다. 결과와 정답사이의 오차에 각 가중치가 얼만큼 영향을 줬는지 편미분하고, 오차가 줄어드는 방향(여러 옵티마이저의 방식)으로 가중치를 업데이트한다.

역전파-가중치 갱신 계산
2층
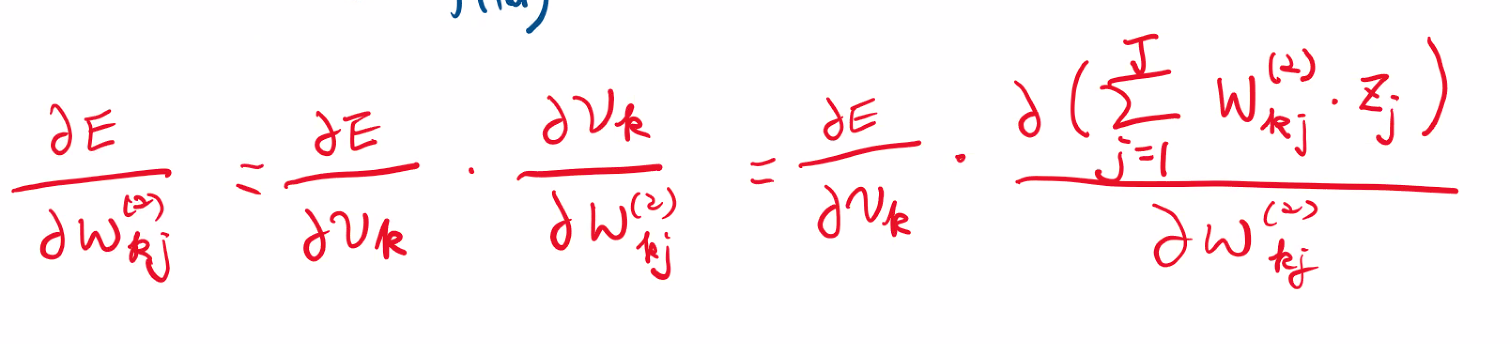
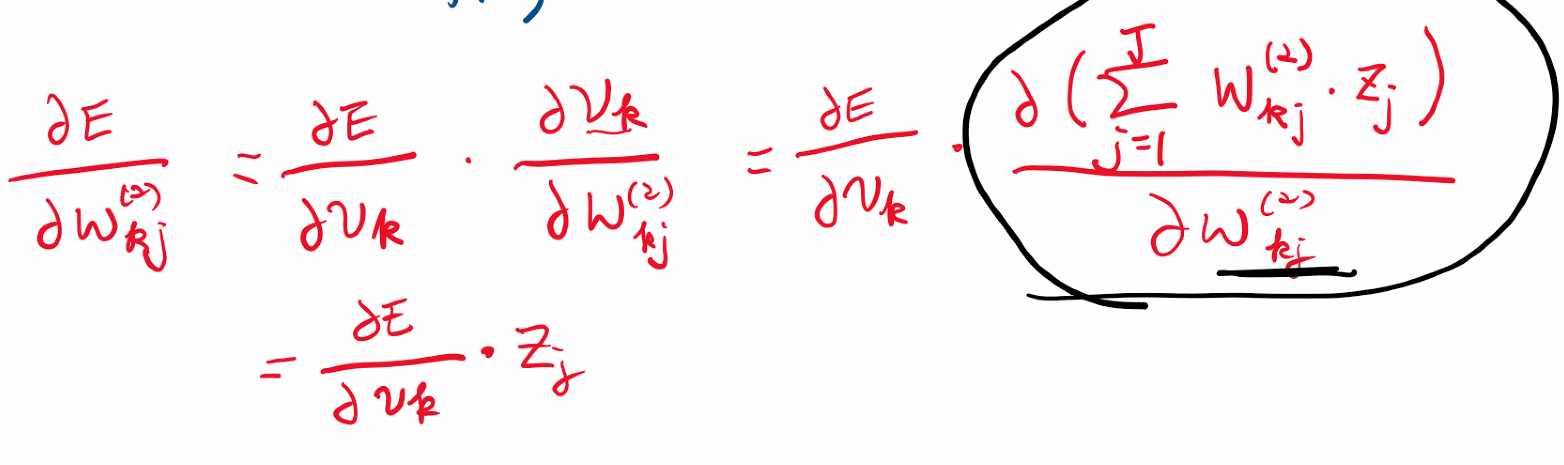
1층
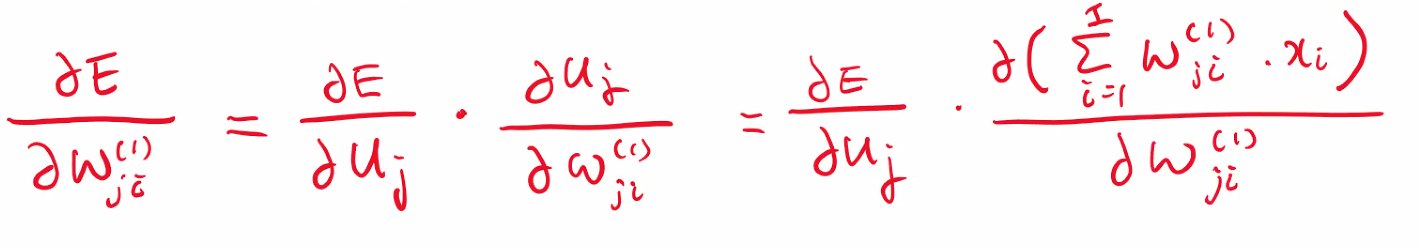

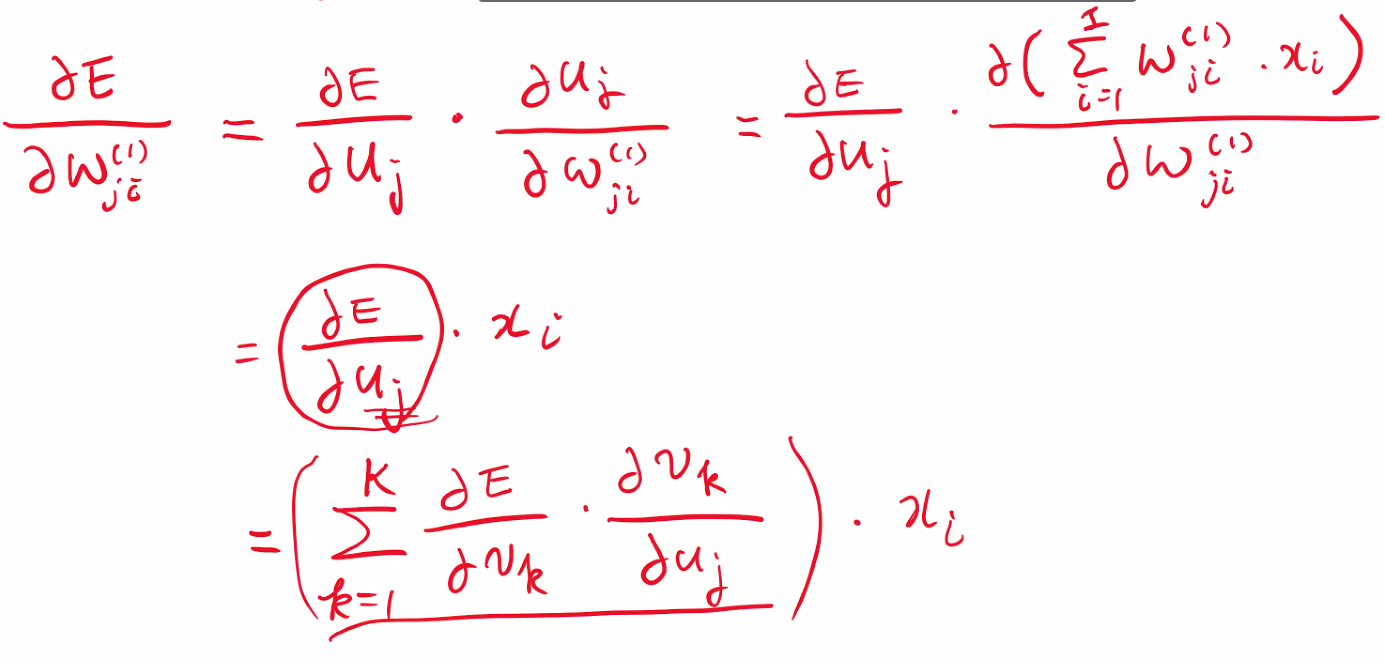
-> 썸k가 생긴 이유가 모든 u가 v에 관여 했기 떄문이다.
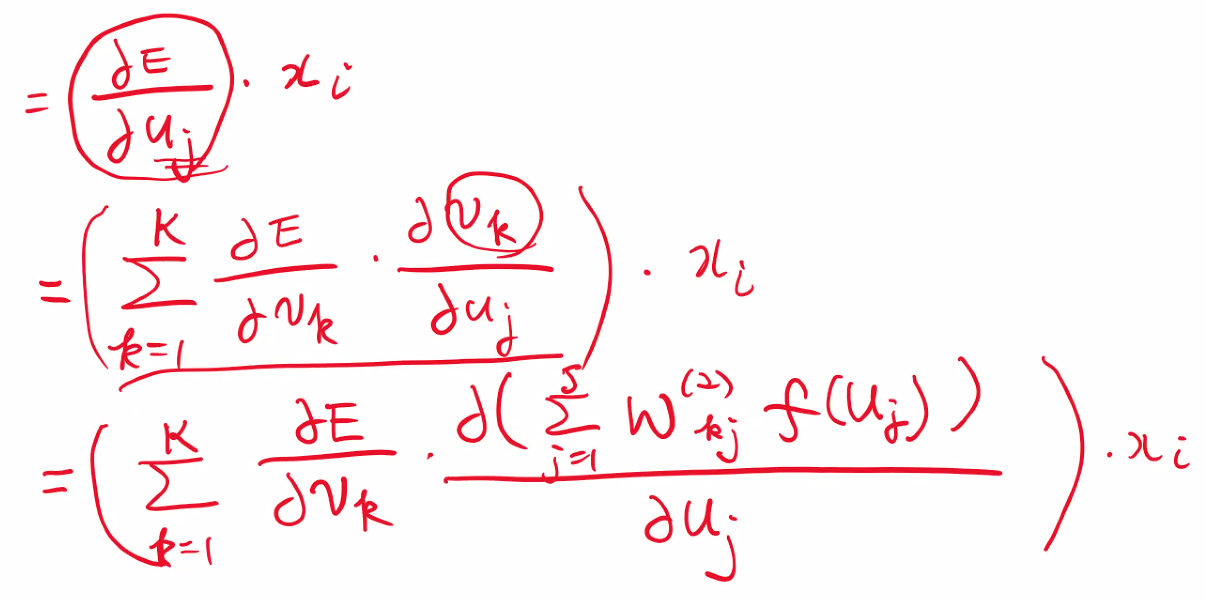
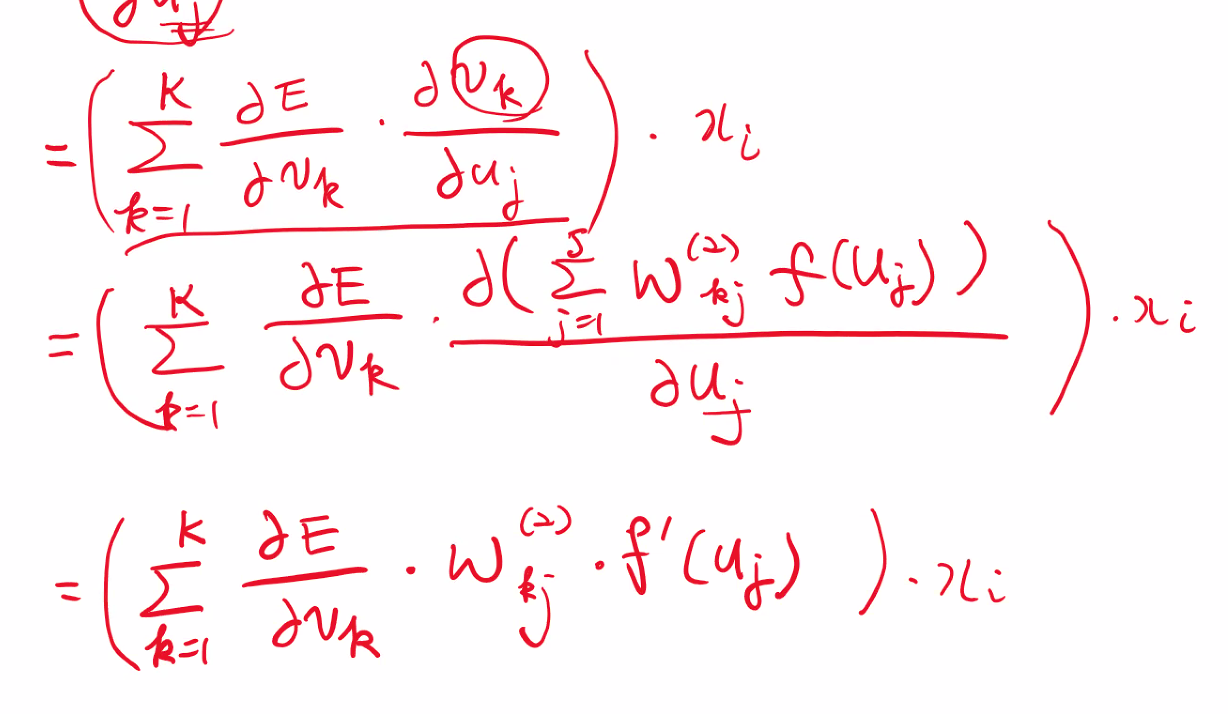
📖 어려운 부분
- 로스트 펑션은 미리 몇가지중에 선택하여 정하는 것이고, 옵티마이저는 러닝레이트나 기타 방법과 로스트펑션의 미분값으로 진행하는 것이다.
📖 이후 학습 계획
- 취업 특강
