
📖 학습한 내용
- GridSearchCV
- RandomForestClassifier
📖 핵심내용
📌 GridSearchCV
많은 파라미터를 차례대로 비교하여 최선의 파라미터를 찾아내기
일단 파라미터를 드문 드문 텀을 두고 둔다
왜냐하면 높아질수록 결과가 좋아지는지, 낮을수록 결과가 좋아지는지 경향을 파악하기 위해서이다. 그렇게 한 뒤에 좋은 값을 찾아본다.
그런데 보통 2 ~ 1000 까지 그냥 쭉 돌리는 경우가 많다.
하이퍼 파라미터
grid_cv =GridSearchCV(dt_clf,
param_grid=params,
scoring='accuracy',
cv=5,
return_train_score=True)
grid_cv.fit(X_train, y_train)param_grid 파라미터 넣기
scoring : 어떤 것 기준
cv : 몇개로 나눠서 검증할 건지
return_train_score : 테스트데이터는 반환하지만 트레인 데이터는 기본값으로 반환하지 않음으로 되어있다.
-
각 스코어와 파라미터 확인
grid_cv.best_score_, grid_cv.best_params_ -
테스트 데이터에 적용
best_dt_clf = grid_cv.best_estimator_
pred1 = best_dt_clf.predict(X_test)
accuracy_score(y_test,pred1)-> gridcv.fit() 한 값은 괄호 안에 들어온 값을 훈련/테스트 데이터로 나눈 뒤 괄호에 들어온 모델로 돌려보는 것. 한마디로 훈련데이터를 넣고, 검증데이터로 나눠서 검증하는 것이다. 이때 최고의 결과를 냈었던 파라미터를 기억할 뿐이다. 따라서 ```grid_cv.best_estimator``` 로 가장 최고의 어큐러시를 냈던 파라미터를 불러오고, 그 모델을 바탕으로 테스트 데이터를 매칭한다.
📌 RandomForestClassifier
여러개의 의사결정나무로 이뤄져있다.
- 하이퍼 파라미터
params = {
'max_depth' : [6,8,10],
'n_estimators' : [50, 100, 200],
'min_samples_leaf' : [8, 12],
'min_samples_split' : [8, 12],
}max_depth : 디시전트리가 몇번 분기할 것인지
n_estimators : 몇개의 트리를 생성할 건지
min_samples_leaf : 노드수의 최소값
min_samples_split : 노드의 크기가 입력한 숫자 이하면 노드 분기를 억제함
- 중요 특성 확인
랜덤포래스트가 모델 만들때 많은 가중치를 두었던 피처를 반환
내림차순 정렬하여 가장 큰 가중치를 둔 피처 확인
best_cols_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_cols_values, index=X_train.columns)
top20_col = best_cols.sort_values(ascending=False)[:20]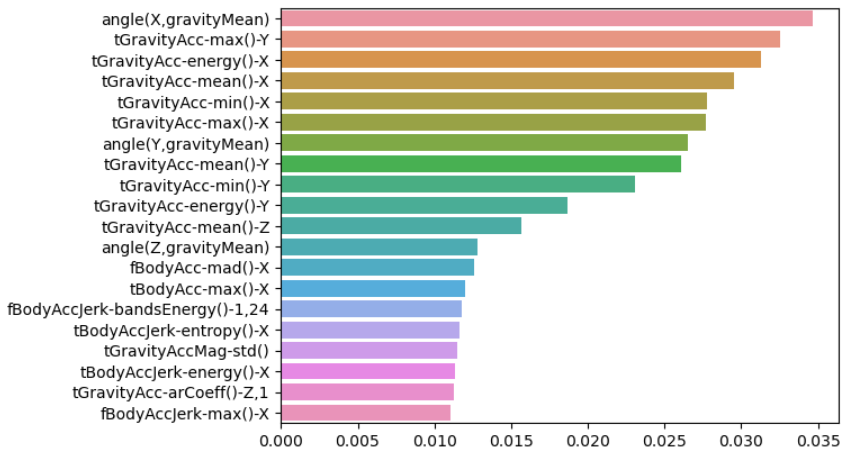
- 중요도 순으로 데이터셋 변경 후 모델 생성
X_train_re = X_train[top20_col.index]
X_test_re = X_test[top20_col.index]
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train.values.reshape(-1,))📖 흥미로운 점 / 새로 알게된 점
-
pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])-
정규표현식 '\s+'
하나 이상의 공백 문자(공백, 탭, 줄 바꿈 등)을 의미
에서 공백을 기준으로 읽는다는 뜻 -
names=
데이터 첫번째 열의 이름 설정한다.header=None과 자주 쓰이는듯
-
-
tolist()
어떤 형태든 리스트형으로 바꾼다. 배열, 시리즈형도 바꾼다.
📖 이후 학습 계획
- KNN, GBM, XGBoost, LGBM
