텍스트 데이터 전처리 활용 - 3
자연어 처리

tags = soup.select("#_per") # #은 id를 사용한다는 의미
print(tags) # 배열형태. 결과가 괄호로 되어있음을 확인 [<em>11</em> , <em>12</em>]
tag = tags[0] # tags의 첫번째 값을 받는다.
print(tag.text) # 태그의 값#은 id를 사용한다는 뜻이다.
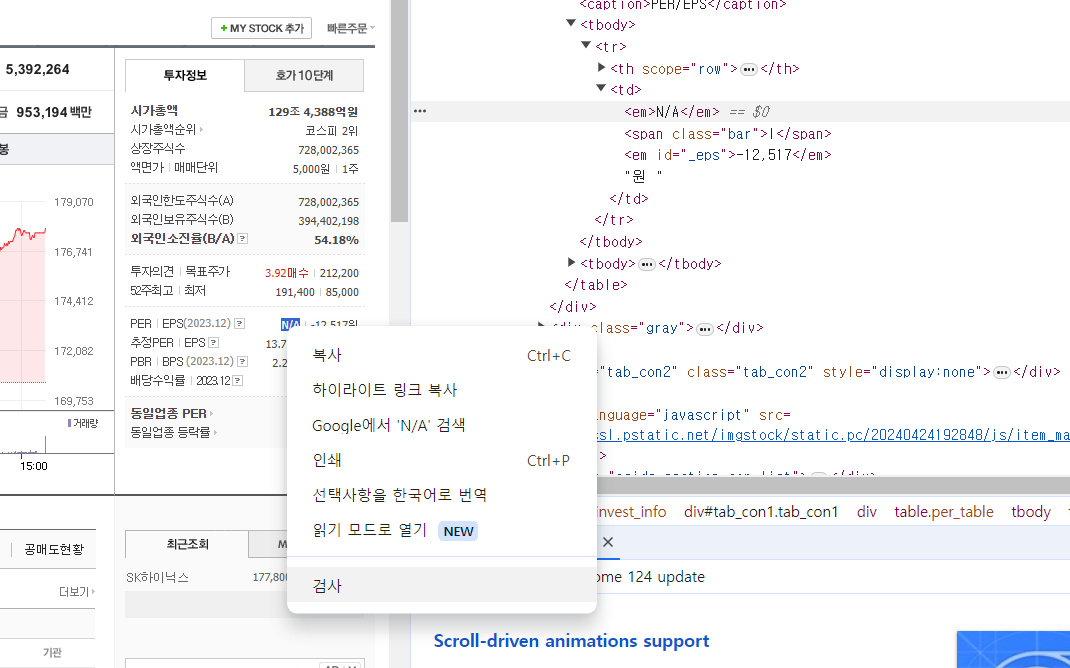
ID가 없는 일반적인 경우에 대한 스크래핑
sk하이닉스 - 외국인소진율 데이터 가져오기
크롬에서 원하는 곳 검사
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/item/main.naver?code=000660"
html = requests.get(url).text
soup = BeautifulSoup(html, "html5lib")
# 직접 만든 CSS 셀렉터
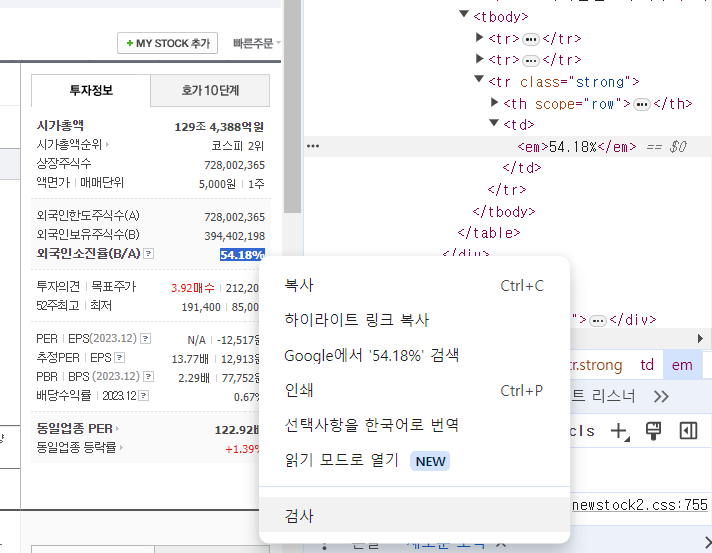
tags = soup.select(".lwidth tbody .strong td em") # .은 class를 불러온다. select함수 차례대로 분석해보면, lwidth클래스 안에 tbody 안에 strong클래스 안에 td 안에 em으로 강조된 데이터
# 크롬 브라우저가 지원하는 CSS 셀렉터
# tags = soup.select("#tab_con1 > div:nth-of-type(2) > table > tbody > tr.strong > td > em")
# 그대로 따라가면 된다.
tag = tags[0] # 원하는 값만을 파싱했기 때문에 0번만 인덱싱
print(tag.text) # 50.24%
웹 스크래핑파싱판다스 실습
가비아 라이브러리의 웹 스크래핑과 파싱
전체 게시글의 제목만 가지고 오기
- 제목에서 검사 클릭하여 위치 알아냄
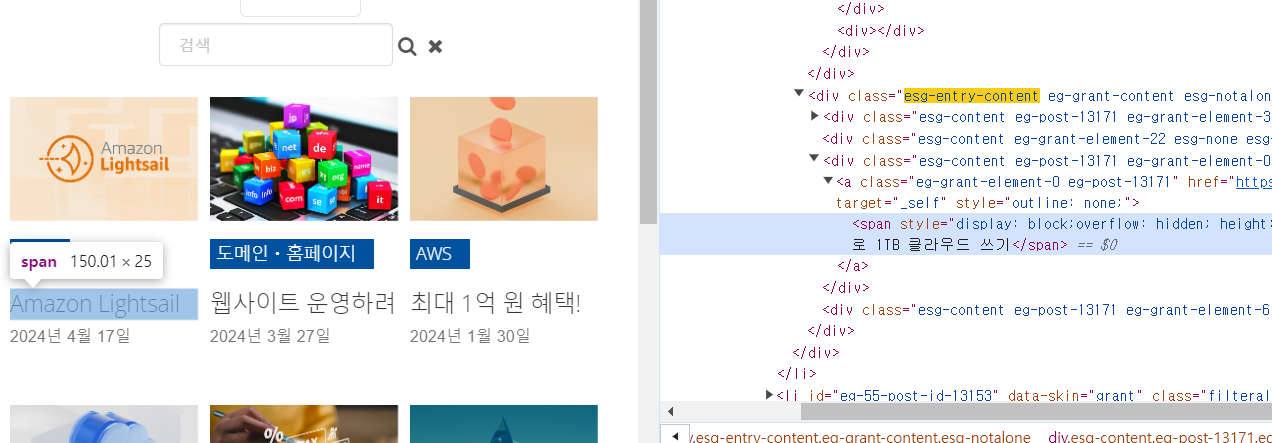
전체 제목 가져오기
import requests
from bs4 import BeautifulSoup as bs
page = requests.get("https://library.gabia.com/") # scrap
# requests.get() : 함수를 통해 url의 html가져옴(페이지 가져옴)
soup = bs(page.text, "html.parser") # scrap conversion
# page 에서 데이터를 유니코드형태로 받음 (text)
# html에 특정되어 있는 parser을 사용해 스크랩
# 응답 받은 내용을 유니코드 형태로 변환하여 soup(변수)에 할당
# soup # 실행하면 html이 쭉 들어와 있음
elements = soup.select('div.esg-entry-content a > span') # parsing
# 페이지에서 확인한 결과 div.esg-entry-content는 여러개가 있다
# 여러 div.esg-entry-content 중 a 를 찾을 수 있다.
# a안에서 span은 여러개 있다. 따라서 원하는 요소를 딱 집어서 가져옴
# 검색해보면 요소들이 모두 배열(array)형태이다.
elements
-> span에 해당하는 데이터를 모두가져왔다.
살펴보면 우리가 필요한 것은 텍스트 데이터이므로 .text 활용
for index, element in enumerate(elements, 1): # enumerate 배열의 인덱스와 값을 가져옴
print("{} 번째 게시글의 제목: {}".format(index, element.text))
# 원하는 인덱스(몇번째)와 제목을 모두 가져오는 결과
-> enumerate 를 이용하여 인덱스 1부터 끝까지 넣어주고 해당하는 인덱스와 elements요소 매칭
*참고 : enumerate(데이터, 인덱스 시작값)
가비아 라이브러리 홈페이지에 존재하는 포스터들의 제목과 링크를 동시에 추출하기.
import requests
from bs4 import BeautifulSoup as bs
page = requests.get("https://library.gabia.com/")
soup = bs(page.text, "html.parser")
elements = soup.select('div.esg-entry-content a.eg-grant-element-0')
# div.esg-entry-content에서 a태그의eg-grant-element-0를 배열형태로 불러옴
elements
-> 속성을 살펴보면, class, href, target이 있다. 여기서 href에 링크가 적혀있는 것을 볼 수 있다. 따라서 이를 고려하면 아래와 같다.
배열명.attrs['속성']
- 해당 속성 값을 가져온다.
for index, element in enumerate(elements, 1):
print("{} 번째 게시글: {}, {}".format(
index, element.text, element.attrs['href']))
# a anchor 태그이 있는 attribute(속성은 추가 정보를 제공하는 역할) 중 herf 값을 가져온다.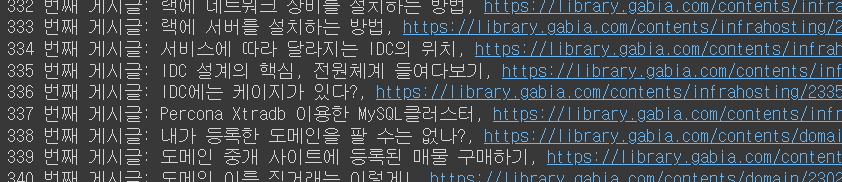
-> 1부터 시작한 인덱스, 텍스트, 링크가 나온것을 알 수 있다
웹 스크래핑은 아주 쉬워서 더 배울 필요는 없어 보인다.
판다스
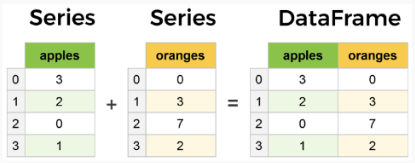
- 시리즈(series) - 테이블 형태에서 열(column) 형태
- 데이터프레임을 엑셀에 쉽게 넣을 수 있다.
- 아래의 그림처럼 이 여러 시리즈(series)을 결합하면 데이터프레임(DataFrame)이 된다. 데이터프레임은 2차원 데이터 구조. 즉, 데이터는 행(row)과 열(column)로 테이블(tabular) 형식으로 정렬된다.
pandas.DataFrame.to_excel()
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
page = requests.get("https://library.gabia.com/")
soup = bs(page.text, "html.parser")
elements = soup.select('div.esg-entry-content a.eg-grant-element-0')
# elements
titles = [] # 열로 지정할 빈 리스트 생성
links = [] # 열로 지정할 빈 리스트 생성
for index, element in enumerate(elements, 1):
titles.append(element.text)
links.append(element.attrs['href'])
# 판다스 데이터 프레임으로 Excel로 저장하는 방법
df = pd.DataFrame()
df['titles'] = titles
df['links'] = links
df.to_excel('./library_gabia.xlsx', sheet_name='Sheet1')-> 엑셀 파일 생성 완료
다 아는거라 매우 쉽다
xpath와 셀레니움을 사용한 웹스크래핑/파싱 실습
- 파싱 : 문자열을 의미있는 토큰으로 분해하는 과정
- XML(Extensible Markup Language) : 마크업 랭귀지 중하나. 데이터 관리를 위해 많이 쓰인다.
XPath(XML Path Language)
- XML을 이용하는데 표준화된 구조로 경로를 나타냄
위치경로
- 노드 이름 : 해당 노드이름과 일치하는 모든 노드를 선택
- / : 루트 노드부터 순서대로 탐색
- // : 현재 노드의 위치와 상관없이 지정된 노드에서부터 순서대로 탐색
- . : 현재 노드를 선택
- .. : 현재 노드의 부모 노드를 선택
- @ : 속성 노드를 선택
예제

-> version은 노드
- 사용 예제
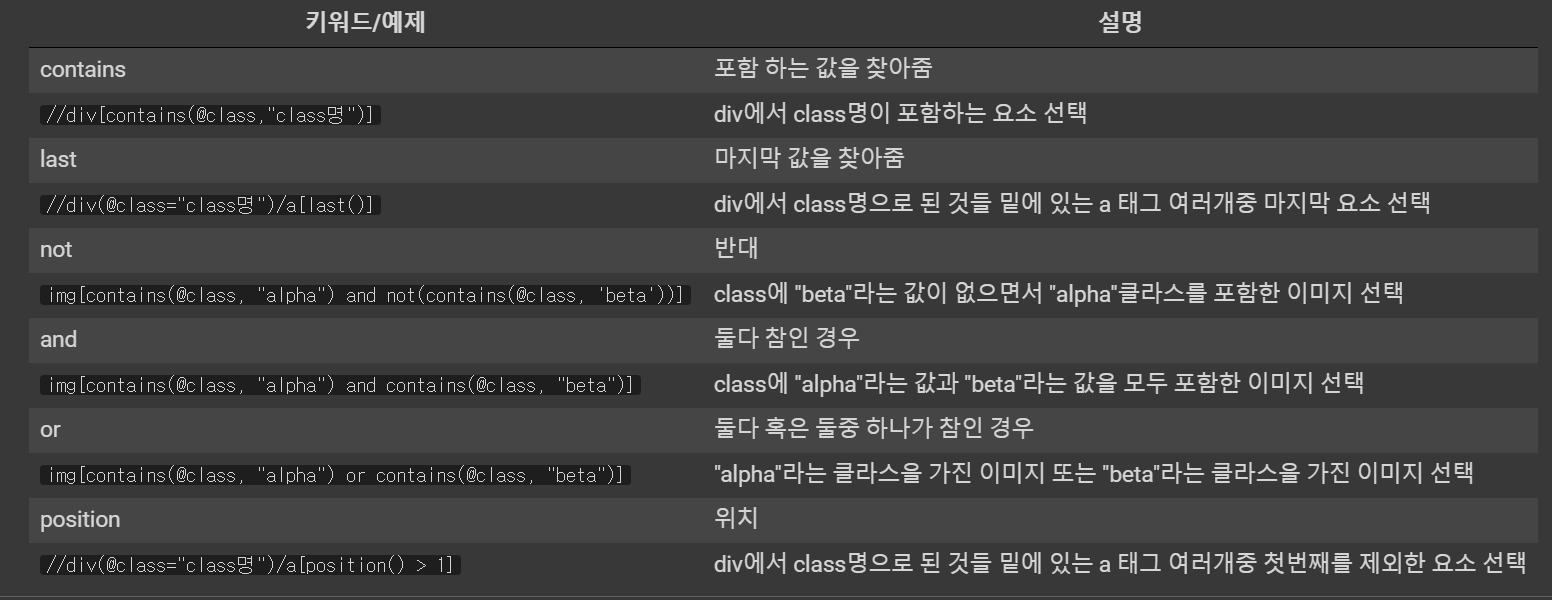
흠.. 보통 필요한 경로를 복사해서 붙여넣는 정도니깐 딱히 암기할 필요 없는 듯하다.
아님 GPT에 물어보면 그때 그때 쉽게 알 수 있는듯?
혹시 코딩 테스트에 나올지도 모르니깐 코태연습할때 잘 봐두자
셀레니움(Selenium)
- Selenium은 프로그램을 이용해 자동화된 웹 테스트를 수행할 수 있도록 해주는 프레임워크
- 무료 오픈소스
- Selenium을 이용한 크롤러는 자동으로 로그인을 수행할 수도 있고, 설문조사에 참여할 수 있게 하기도 하는 등 웹의 많은 작업을 자동화할 수 있음.
코랩에서 셀레니움 기본 설정
- 1 필요 라이브러리및 패키지 인스톨
!apt install chromium-chromedriver # 크롬을 사용하므로 설치
!cp /usr/lib/chromium-browser/chromedriver /usr/bin # 구글 드라이버를 사용하고 있기에 드라이버에 설치된 패키지를 user bin으로 복사하는 작업
!pip install seleniumapt: APT(어드밴스트 패키징 툴,Advanced Packaging Tool)은 우분투(Ubuntu)를 포함안 데비안(Debian)계열의 리눅스에서 쓰이는 팩키지 관리 명령어 도구
cp:복사하기 명령어
pip: 파이썬으로 작성된 패키지 소프트웨어를 설치하거나 관리하는 패키지 관리 시스템
- 2 셀레니움(Selenium) 설정과 크롬 옵션
from selenium import webdriver #웹드라이버 불러오기(import). 셀레니움에서 가장 많이 사용하는 패키지
options = webdriver.ChromeOptions() # 크롬옵션 객체 생성
options.add_argument('-headless') # virtual randering
options.add_argument('-no-sandbox') # Bypass OS security model
options.add_argument('-disable-dev-shm-usage') # overcome limited resource problems
from selenium.webdriver.common.by import By크롬 옵션 설명
- 브라우저(크롬 등)는 기본적으로 창을 사용. 그 후 HTML과 CSS를 사용해 GUI(Graphic User Interface)를 화면에 표시
- headless란?
'창이 없는'과 같다고 해석
'화면' 자체가 존재하지 않는 경우, 예: 우분투(Ubuntu) 서버, 일반적인 방식으로는 크롬 사용이 불가능
이때, headless 모드를 사용
'창'으로 띄우지 않고 대신 화면을 그려주는 작업(렌더링)을 가상으로 진행- sandbox란?
외부로부터 들어온 프로그램이 보호된 영역에서 동작해 시스템이 부정하게 조작되는 것을 막는 보안 형태- -no-sandbox: 이 보안을 해재시키는 옵션
- disable-dev-shm-usage란?
한정된 자원의 셋팅을 해재시키는 옵션- selenium.webdriver.common.by의 By란
'class name', 'id' 혹은 'name'등 어떤 종류의 로케이터(locator)를 사용할 것인지 지정
실습에서는 XPATH를 사용
- 3 웹 드라이버(크롬)로 웹페이지 가져오기(HTML code)
wd = webdriver.Chrome(options=options)
wd.get("https://www.amazon.com/Dyson-V10-Allergy-Cordless-Cleaner/dp/B095LD5SWQ/")get('페이지')함수를 사용하여 원하는 페이지를 가져옴
find_element()
find_element(by=방법, value=값) 함수
- 제공된 로케이터와 일치하는 HTML 코드의 첫 번째 요소에 대한 참조를 가지고 옴.
find_element()와 find_elements()
- find_element() - 하나의 객체
- find_elements() - 하나이상의 객체
HTML
-
하이퍼 텍스트 마크업 언어(영어: Hyper Text Markup Language, HTML, 문화어: 초본문표식달기언어, 하이퍼본문표식달기언어)는 웹 페이지 표시를 위해 개발된 마크업 언어
-
웹 브라우저와 같은 HTML 처리 장치의 행동에 영향을 주는 자바스크립트, 본문과 그 밖의 항목의 외관과 배치를 정의하는 CSS 같은 스크립트를 포함
-
웹을 생성하고 관리하는 마크업 언어
구조
보통 형태는 아래와 같다.
<html>
<head>
<title>Hello HTML</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>웹크롤링 실습
네이버 영화의 웹 크롤링(Web Crawling)
import requests
from bs4 import BeautifulSoup as bs
page = requests.get("http://movie.naver.com/movie/sdb/rank/rmovie.nhn")
soup = bs(page.text, "html.parser")
pkg_list = soup.findAll("div", "tit3") # css class가 tit3인 모든 div
print(pkg_list)-> 결과로 나온 것 중 하나는 다음과 같다.

find()
- HTML/XML 문서에서 첫 번째로 일치하는 요소를 찾습니다.
find(name, attrs, recursive, string, *kwargs)
- name: 찾고자 하는 태그 이름입니다.
- attrs: 속성과 해당 값으로 요소를 필터링할 수 있습니다.
- recursive: 기본적으로 True로 설정되며, 하위 요소까지 재귀적으로 검색합니다
- string: 태그의 텍스트를 기반으로 요소를 찾습니다.
- 반환 값은 첫 번째로 일치하는 요소입니다.
findAll() / find_all()
- HTML/XML 문서에서 일치하는 모든 요소를 찾습니다.
findAll(name, attrs, recursive, string, limit, **kwargs)
- 매개변수는 find()와 동일하며, 추가적으로 limit 매개변수를 지정하여 반환할 요소의 최대 개수를 제한할 수 있습니다.
- 반환 값은 일치하는 모든 요소를 담은 리스트입니다.
2. 커스텀 Crawler 클래스를 사용한 크롤링
URL(Uniform Resource Locator)
- 인터넷에서, 어느 사이트에 접속하기 위해서 입력해야 하는, 주소를 포함한 일련의 문자. 맨 앞에 `http://'를 입력하고 다음에 해당 사이트의 주소를 표시함. (Definitions from Oxford Languages)
Queue(큐)
- 리스트(list), 스택(stack), 해시 테이블(hashtable)등의 데이터 구조의 한 종류
- 큐는 한쪽에서는 데이터가 추가되고 한쪽에서는 데이터가 삭제되는 구조를 가지고 있다.
- FIFO(First-In First-Out) 선입선출
웹 크롤러 작업절차
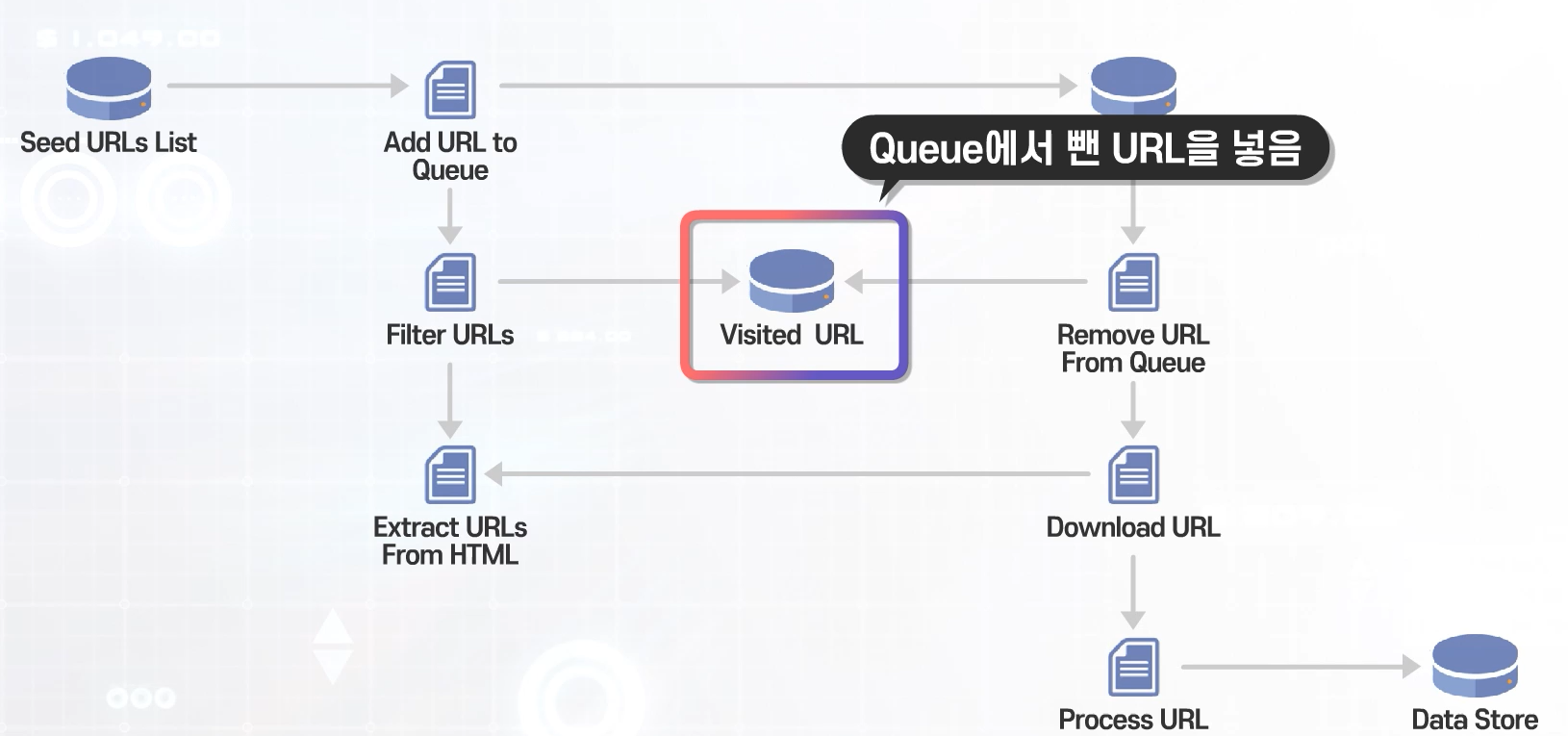
- Seed URLs list (시작할 URL를 만든다)
- Add URL to Queue (큐에 넣는다)
- URL Queue (큐에서 URL를 빼고 작업을 시작한다)
- Remove URL from Queue
1) Visited URL (큐에서 뺀 URL은 Visited URL이란곳에 넣는다) - Download URL
1) Extract URL from HTML
2) Filter URLs >> Visited URL - Process URL >> Data Store
기본 구조 코딩
# crawler.py에 저장
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(
format='%(asctime)s %(levelname)s:%(message)s',
level=logging.INFO) # 로그(로깅) 메세지를 표시
class Crawler:
def __init__(self, urls=[]):
self.visited_urls = [] #이미 처리한(visited) URL 리스트
self.urls_to_visit = urls #처리해야할 URL 리스트
def download_url(self, url):
return requests.get(url).text
def get_linked_urls(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for link in soup.find_all('a'): # a 태크를 모두 찾는다
path = link.get('href') # href를 골라낸다
if path and path.startswith('/'):
path = urljoin(url, path)
yield path
def add_url_to_visit(self, url): # url를 add한다
if url not in self.visited_urls and url not in self.urls_to_visit:
self.urls_to_visit.append(url)
def crawl(self, url): # page의 모든 링크를 리스트에 저장한다
html = self.download_url(url)
for url in self.get_linked_urls(url, html):
self.add_url_to_visit(url)
def run(self): # 크롤링 시작
while self.urls_to_visit:
url = self.urls_to_visit.pop(0)
logging.info(f'Crawling: {url}')
try:
self.crawl(url)
except Exception:
logging.exception(f'Failed to crawl: {url}')
finally:
self.visited_urls.append(url)
if __name__ == '__main__':
Crawler(urls=['http://movie.naver.com/movie/sdb/rank/rmovie.nhn']).run()-> 코드를 파이썬 파일로 저장 후 실행해줘야한다.
- 파일명을 crawler로 했을 경우 실행
!python crawler.pyScrapy를 사용한 크롤링
Scrapy란?
- 웹사이트에서 필요한 데이터를 추출하기 위한 오픈 소스 및 협업 파이썬 프레임워크
- 웹 스파이더(web spider)를 사용하여 쉽게 크롤링을 빌드(build)하고 배포(deploy)한다
설치
!pip install Scrapy # 인스톨 scrapy
!scrapy startproject tutorialscrapy 설치 후 폴더 생성(tutorial 임의로 파일명 정할 수 있다)
- 설치된 폴더 설명

-> 우리는 스파이더(spiders) 폴더 -> 클래스 파일을 생성해야 하는 곳을 사용함
스파이더 폴더에 스파이더 만들기
- 스파이더 폴더에 quotes.py 파일 생성
- 하기 코드붙여넣기
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes" # 실행할때 사용하는 이름
def start_requests(self):
urls = [
'https://quotes.toscrape.com/page/1/',
'https://quotes.toscrape.com/page/2/'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response): # 파일로 만들어내는 기능
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f'Saved file {filename}')-> 여기서 https://quotes.toscrape.com/page/1/는 임의로 만들어진사이트
스파이더 실행하기
import os
# working 디렉토리(directory)로 이동(change)
os.chdir('/content/tutorial/tutorial/spiders')
!scrapy crawl quotes-> 현재의 폴더 말고 다른 공간에서 파일을 실행시키려면 os 가 필요하다.
os의 체인지디렉토리 함수(chdir())를 이용하여 실행한다.
