[4장: 분류]
균일도 기반 규칙 조건
정보 균일도 측정 방법
1) 정보 이득
..앤트로피 개념
정보이득 지수 = 1-엔트로피 지수
2) 지니계수: 불평등 지수
지니계수 낮을수록 균일한 데이터
결정트리의 규칙노드 생성 프로세스
If true/ else결정트리 장점
쉽고 직관적
결정트리 단점
과적합(overfitting)
sol) 트리크기를 사전에 제한
결정트리 주요 hyperparameter
- max_depth, max_features..Graphviz이용한 결정트리 모델의 시각화(실제 나무 모양 그림으로)
- 각 노드에는피처의 규칙 조건 gini samples: 현 규칙에 해당하는 데이터 건수 value: 클래스 값 기반의 데이터 건수
ex) [41,4,10] 이면 해당 조건을 만족하는 a품종은 41개 b품종은 4개
class: value리스트 내에 가장 많은 건수를 가진 결정값
결정트리의 feture 선택 중요도
중요한 feature들만 선택해서 학습,예측하는게 나을 수도
- feature_importance: 중요한 feature 찾아내기
결정트리 실습: 사용자 행동 인식 데이터 세트
* 스마트 워치끼고 어떤 행동을 하는지 찾아낸다
앙상블 학습
다양한 분류기의 예측 결과를 도합
이질적인 모델들을 섞는 게 전체 성능에 도움이 될 수 ㅇ
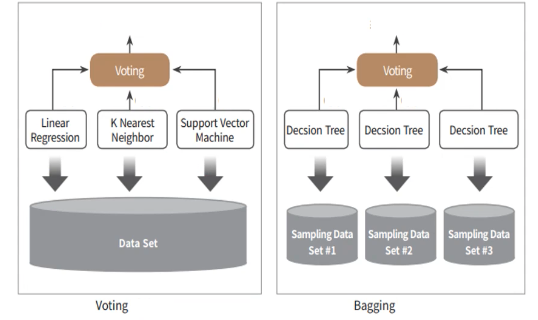
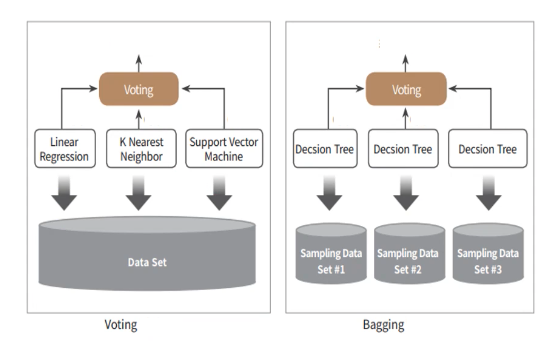
1. 보팅
하드 보팅: 다수의 classifier 간 다수결
소프트보팅: class별 확률 결정 by predict_proba()
* 위스콘신 유방암 데이터 예측
(cf) kNeighborsClassifier에서 n_neighbors는 내 주변의 몇개의 이웃들을 참조해서 이 데이터를 예측할 건지
{kind=link}
2. 배깅 | 랜덤 포레스트가 대표적
여러개의 결정트리 분류기가 전체 데이터에서 배깅방식으로 각자 데이터를 샘플링해 개별적으로 학습 수행
-> 이후 모든 분류기를 보팅으로 예측 결정
비교적 빠른 수행속도
bootstrapping: 전체 데이터 세트를 중첩되게 분리하는 것
한 서브세트에 [1233346889]와 같이 한 데이터가 여러개씩 들어있음
* 사용자 행동인지 데이터 예측
(cf) 개별 피쳐들의 중요도 시각화
Random forest의 feature_importances_: 중요도 순서로 ndarray로 반환
-> series로 변환 3. 부스팅
여러개의 학습기를 "순차적"으로 학습,예측하면서 "잘못 에측한 데이터"에 가중치 부여해 오류를 개선해나가며 학습시키기
-> 수행시간 오래걸림
-
GBM (Gradient Boost Machine)
가중치 업데이트에 경사하강법을 이용
GradientBoostingClassifier 클래스learning_rate: GBM 학습 진행시에 적용되는 학습률
n_estimators: weak learner의 개수
subsample: weak learner가 학습에 사용하는 데이터 샘플링 비율 -
XGBoost(extra gradient boost)
빠른 수행시간
다양한 성능향상기능: 규제, tree pruning(가지치기)
다양한 편의기능: 조기 중단, 자체 내장된 교차검증, 결손값 자체 처리- 조기중단기능
더이상 비용함수가 감소하지 않으면, 수행을 종료
early_stopping_rounds(더이상 비용평가지표가 감소하지않는 최대 반복횟수), eval_metric, eval_set
- 조기중단기능
-
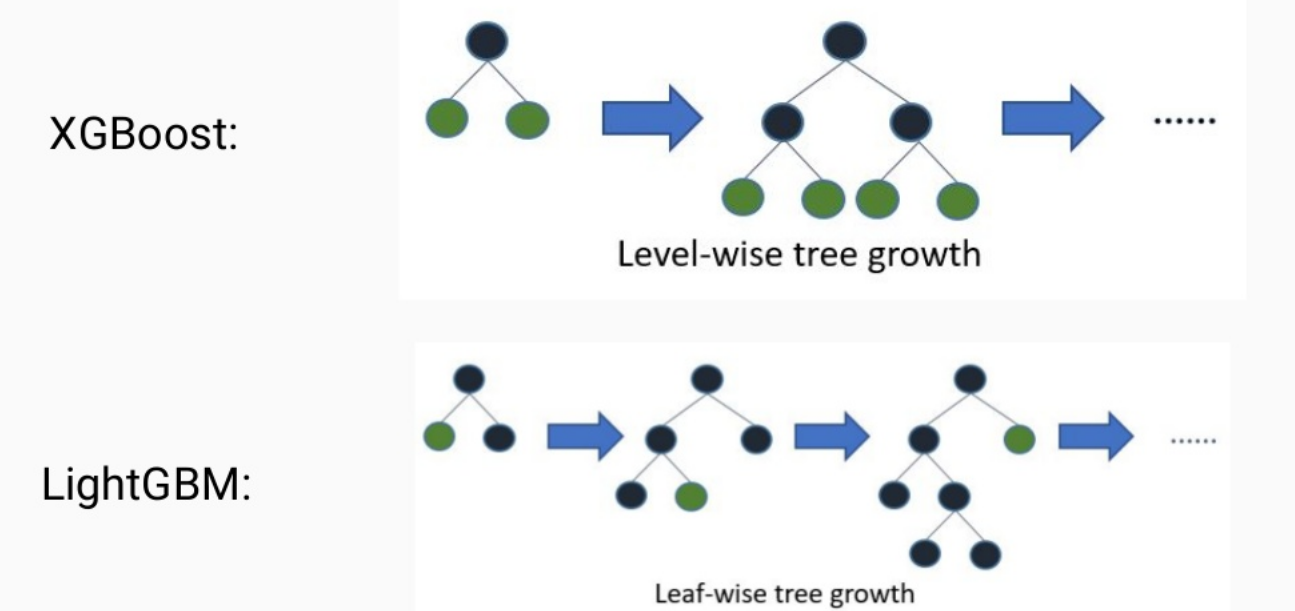
LightGBM
더 빠르고 더 작은 메모리 사용
카테고리형 feature의 자동변환, 최적분활leaf 중심트리 분할 방식(leaf wise(<->균형트리분할방식))
https://miro.medium.com/max/2590/1*5gY5IdU6PO4JCqQoEDtdMA.png
{kind=link}
* 분류 실습1: 캐글경연대회의 산탄데르 은행 고객 만족 예측
* 분류 실습2: 신용카드 사기 예측 실습
IQR과 박스플롯
언더샘플링, 오버샘플링
언더샘플링: 많은 레이블을 가진 데이터 세트를
적은 레이블을 가진 데이터 세트 수준으로 감소 샘플링 SMOTE
원본데이터-> k최근접 이웃으로 데이터 신규증식 -> 신규증식하여 오버샘플링 완료정리
데이터 로그 변환: 약간식 성능 좋아짐
이상치 데이터 제거: 정밀도 up, 재현율 up
SMOTE 오버 샘플링: 정밀도 down, 재현율 upStacking Model
기반 모델들이 예측한 값들을 Stacking 형태로 만들어서
메타 모달들이 이를 학습하고 예측하는 모델교차 검증 세트 기반의 스태킹
step1: 각 기반 모델 별로 학습하고, 학습/테스트 데이터를 예측한 결과값을 기반으로
메타 모델을 위한 학습용/테스트용 데이터를 생성한다
step2: 스텝1에서
(신규)
Feature Selection
모델을 구성하는 주요 피처들을 선택
불필요한 다수의 피처들로 인해 모델 성능을 떨어뜨릴 가능성을 제거
설명가능한 모델이 될 수 있도록 피처들을 선별
피처값의 분포, Null의 개수, 피처간 높은 상관도(겹치는거 제거), 결정값과의 독립성 등을 고려
모델의 피처중요도 기반사이킷런 Feature Selection 지원
RFE
모델의 최초학습 후 feature 중요도 선정
feature중요도가 낮은 속성들을 차례대로 제거, 반복적으로 학습.평가 수행하여
최적의 feature추출
수행시간이 너무 오래걸린다..
SelectFromModel
모델 최초 학습 후 선정된 피처 중요도에 따라 평균.중앙값의 특정 비율 이상인 피처들을 선택
ref: "파이썬 머신러닝 완벽가이드", 권철민, 위키북스
