-
NLP vs 텍스트 분석
-
텍스트 분석 주요 영역
텍스트 분류(어떤 카테고리에 속하나)
감성 분석(텍스트에서 나타나는 주관적인 기분 등의 요소를 분석)
텍스트 요약
텍스트 군집화와 유사도 측정 -
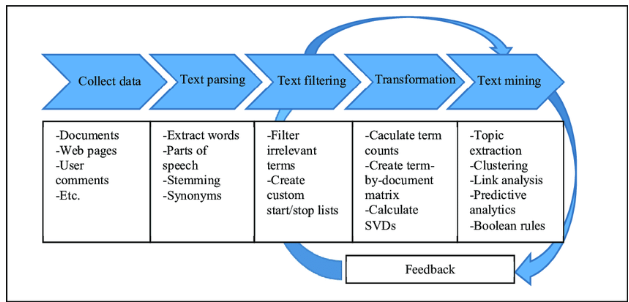
텍스트 문석 머신러닝 수행 프로세스
데이터 사전가공-> Feature Vectorization -> ML 학습/예측/평가
-
파이썬 기반의 NLP, 텍스트 분석 패키지
NLTK, Gensim(토픽모델링), SpaCy -
텍스트 전처리: 텍스트 정규화
클렌징: html, xml 태그나 특정 기호 제거
토큰화: 문장/ 단어 토큰화
필터링/ 스톱워드 제거/ 철자 수정: 관사 제거
Stemming/ Lemmatization: 단어 원형 추출 -
N-Gram
문장을 개별 단어로 토큰화 하면 문맥적인 의미가 무시됨
-> n개의 단어를 하나의 토큰화 단위로 분리하는 것
n개 단어 크기의 윈도우를 만들어 토큰화 수행
-
텍스트의 피처 벡터화 유형
BOW(Bag of Words)
Document Term Matrix
단어들의 등장 횟수를 매트릭스로Word Embedding
개별 단어를 문맥을 기준으로 N차원 공간에 벡터로 표현 -
BOW
문맥이나 순서를 무시하고
일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 모델
(문서 내 모든 단어를 bag아넹 넣고 흔들어서 섞는다는 의미) -
BOW 구조
column은 단어로, row는 문장을 기준으로 각 column의 단어들이 몇번 등장했는지름 적음장점: 쉽고 빠른 구축
예상보다 문서의 특징을 잘 나타내서 전통적으로 여러분야에 활용도가 높음
단점: 문맥 의미 반영을 못함
희소 행렬 문제(값의 없는 null이 너무 많다) -
BOW 피처 벡터화
-
단순 카운트 기반의 벡터화
각 문서에서 해당 단어가 나타나는 횟수를 부여 -
TF-IDF 벡터화
단어에 가중치를 주어서, 모든 문서에서 많이 나타나는 단어에는 패널티를 줌특정 문서에만 나타나는 단어를 해당 문서를 잘 특징짓는 중요 단어일 가능성이 높다고 여김.
TF(Term Frequency): 그 문서에서 몇번 나왔니
DF(Document Frequency): 그 단어가 전체 몇개의 문서에서 나왔는지
IDF: 전체문체수/DF
-
-
CountVectorizer를 이용한 피처 벡터화
사전데이터가공->토큰화->텍스트정규화->피처 벡터화 -
희소행렬의 저장 변환 방식
COO형식: 0이 아닌 데이터만 별도의 배열에 저장
CSR형식: COO형식이 위치 배열값을 중복적으로 가지는 문제를 해결한 방식
-
20 Newsgroup 분류하기 *
18846개의 뉴스 문서를 20개의 카테고리로 분류하기텍스트정규화 -> 피처벡터화 -> 머신러닝 -> pipline 적용 -> GridSearchCV최적화
-
감성분석
지도학습 기반의 분석감성 어휘 사전을 이용한 분석
SentiWordNet: Synset별로 3가지 감성지수(긍정감성지수, 부정감성지수, 객관성지수)
CADER: 소셜미디어의 텍스트에 대한 감성분석
Pattern- IMDB의 영화 review에 대한 긍부정 예측
-
SentiWordNet의 감성지수
가로: 긍정부정, 세로: 객관성 정도문서를 문장단위로 분해
-> 단어를 토큰화, 품사 태깅
-> synset객체, senti_synset객체 생성
-> senti_synset에서 긍정 부정 감성지수 구하고 역치값 기준으로 판별 -
VADER
SentiIntensityAnalyzer 클래스 사용
-
토픽 모델링
문서들에 잠재돼 있는 공통된 토픽들을 추출해 내는 기법- 행렬 분해 기반 토픽 모델링(LSA. NMF)
- 확률 기반의 토픽 모델링
- 행렬 분해 기반 토픽 모델링(LSA. NMF)
-
LDA(Latent Dirichelt Allocation)
문서내의 단어들을 이용해 베이즈 추론을 통해
잠재된 문서내 토픽분포와 토픽별 단어분포를 추론하는 방식 -
베이즈 추론 켤레 사전 분포
이항 분포 -> 베타 분포
다항 분포 -> 디리클레 분포 -
LDA 구성요소
-
LDA 수행 프로세스
count 기반 행렬
토픽의 개수 설정
임의 주제를 최초할당 후, 문서별 토픽분포, 토픽별 단어분포가 결정됨
특정 단어를 추출.제외 하고 두 분포를 재계산
모든 단어들의 토픽 할당분포를 재계산
- 문섭 군집화
