
CLIP (Contrastive Language-Image Pre-training)
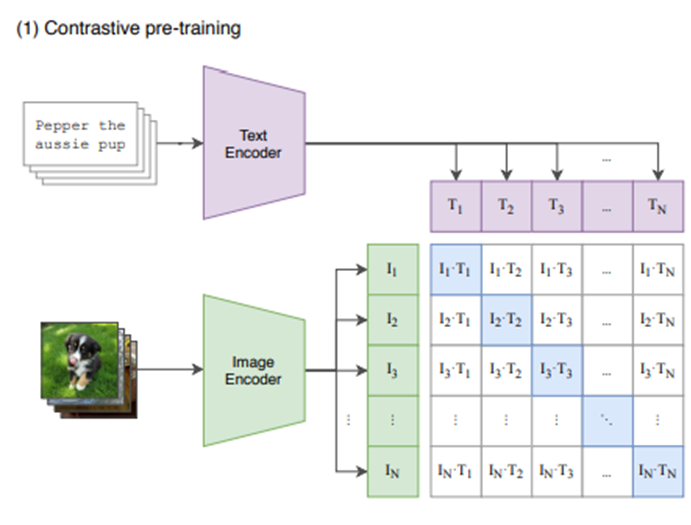
Contrastive learning 기반 ConVIRT 모델에서 간략화된 버전이 CLIP이라고 한다.
image & text encoder를 Jointly training하도록 한다.
- Positive한 개의 pair 요소들에 대해 Cosine 유사도가 최대가 되도록 (Pulling)
- Negative한 개의 pair 요소들에 대해 Cosine 유사도가 최소가 되도록 (Pushing)
Zero-shot learning
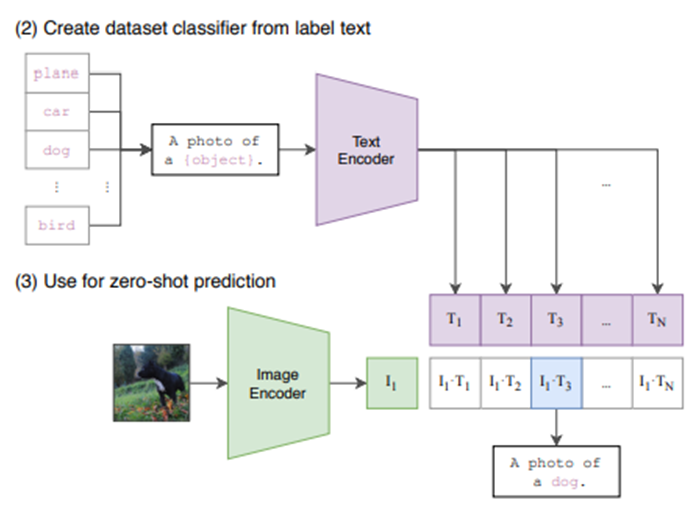
Ex) CIFAR-10 dataset을 예측하려 한다.
Image와 문장화된 label을 Embedding하여 representation한다면 별도의 fine-tuning없이도 바로 예측이 가능하다!
Adopted vision-language model을 통해 segment image 성능 향상
bilion-scale의 image-text pair으로부터 multi-modal feature들을 학습하는 model을 vision-language model이라고 한다.
image - text pair pretrained model을 fine-tuning을 한 Adopt CLIP을 제시했다.
기존 pre-trained vision-language model의 문제점
Generalization Problem
CLIP과 같은 Pre-trained model을 이용하여 인간 수준의 segment 능력을 달성할 수 있었다.
여기서 말하는 "인간 수준의 segment 능력"이란
수 천개의 category들을 가지고 segmentation 할 수 있는 수준
즉, 단어 사전을 열어보고 (Open-Vocabulary) 인지하는 수준이다.
이를 위해선 two-stage approachs가 필요하다
- model에서 class agnostic mask를 생성
- pre-trained CLIP의 classification 능력을 masked image에 전이하도록 함
class agnostic mask : object의 종류는 무시하고, 영역만을 mask로 표시하는 것
즉, 이미지에 있는 foreground object으로 보이는 object를 추출하는 방식
여기서 model의 mIoU의 성능을 결정 짓는 요소는 두 가지이다.
- mask를 생성해주는 mask generator
- classifier
CLIP은 매우 훌륭한 mask generator를 갖고 있지만 classifier 성능은 보통인 model이다.
이 경우, ground-truth mask와 비슷한 수준의 mask를 생성한다.
그러나 ADE20K-150 dataset으로 측정한 mIoU 성능은 겨우 20.1%이다.
MaskFormer는 매우 훌륭한 classifier 성능을 가지고 있지만 mask generator 성능은 보통인 model이다.
COCO dataset으로 측정한 mIoU 성능은 CLIP보다 높은 66.5%이다.
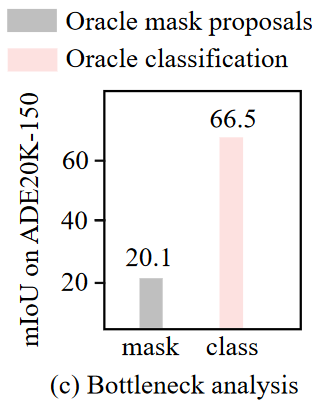
즉, CLIP은 classificaiton의 결함으로 인해 Open-vocabulary segement model로써 한계가 있다.
저자는 CLIP의 낮은 성능의 이유로 CLIP의 원본 image data와 masking된 image의 domain gap에 의해 발생한다고 한다.
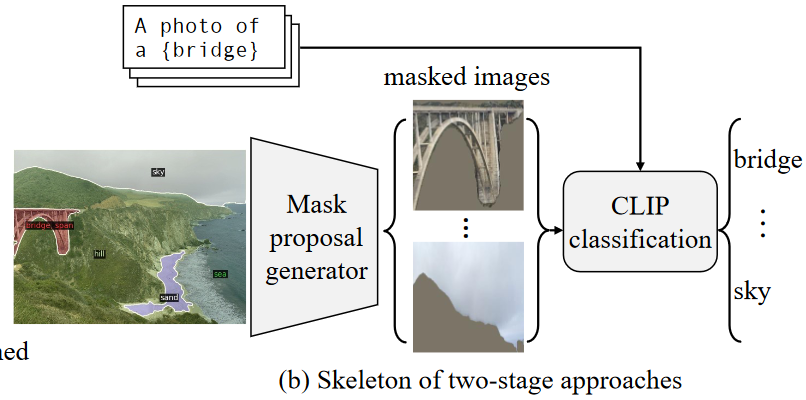
쉽게 말해서 masked image는 crop 및 re-size되었으므로 domain이 원본 이미지와 그 만큼 차이가 난다는 뜻이다.
Zero token Problem
masked image의 background pixel은 CLIP transformer으로 들어갈 때 "zero token"으로 취급한다.
zero token은 아무런 쓸모도 없을 뿐더러 원본 이미지에는
zero token이 존재하지 않으므로 두 이미지의 domain distribution간에 차이(shifting) 문제가 발생하여 성능이 저하됨을 분석하였다.
그래서 Mask-adapted CLIP는 어떻게 만들어지는가?
Generalization
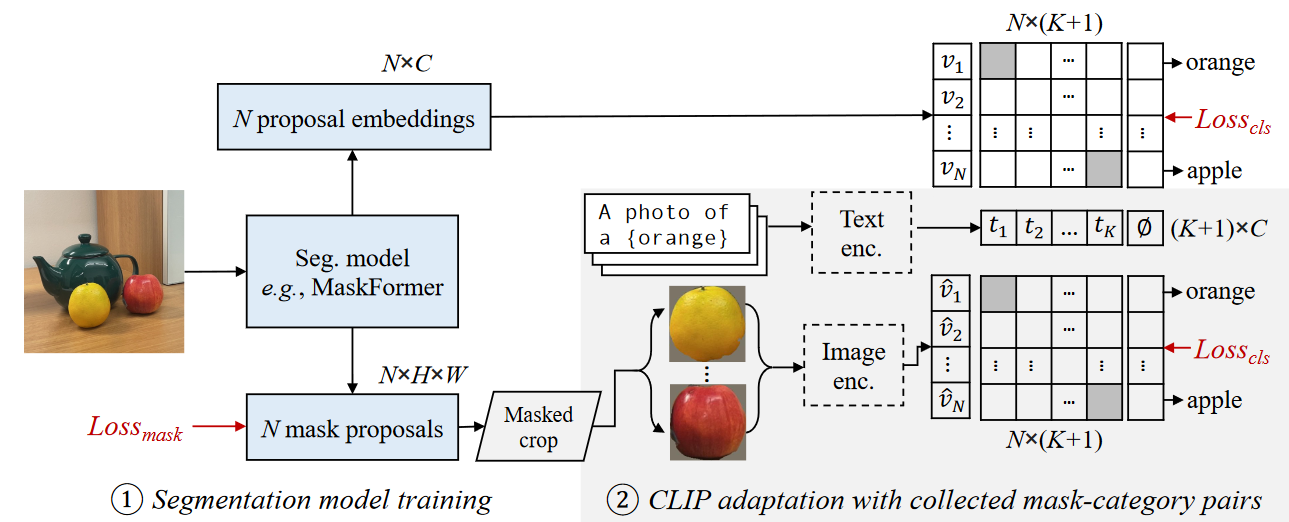
- image-caption dataset을 준비하도록한다. (COCO Captions)
- image-caption pair에서 caption으로부터 명사를 추출하도록 한다.
- pre-trained segmentation model을 이용해 class-agnostic mask를 생성한다.
- pre-trained model인 CLIP으로 masked image와 caption으로부터 추출한 명사와의 best-matching이 되도록 할당해준다.
masked image와 새로운 category들 사이의 weakly-supervied alignment를 통해 Open vocabulary classification에 대해서 adopted CLIP이 더 나은 일반화 성능을 보여준다.
segmentation label를 사용하는 COCO-staff의 경우에는,
category의 종류 수가 제한되어 있어
일반화 성능이 떨어지는 문제가 발생한다.Fine-tuning
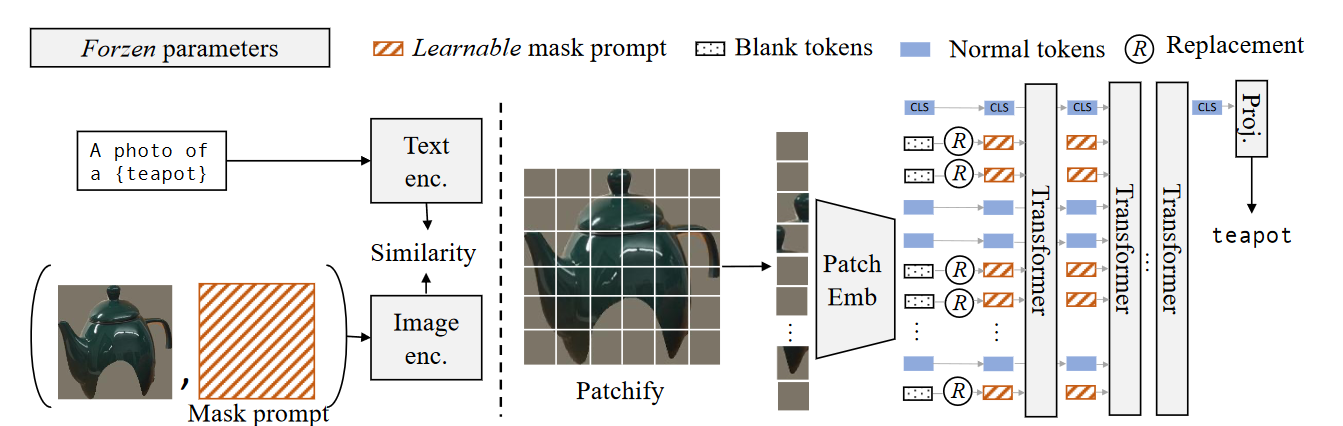
- zero token learnable prompt token으로 변환한다.
- CLIP의 weight를 고정시켜 learnable prompt token을 학습할 수 있도록 한다. (내가 생각한 이유는 아래에 적었당)
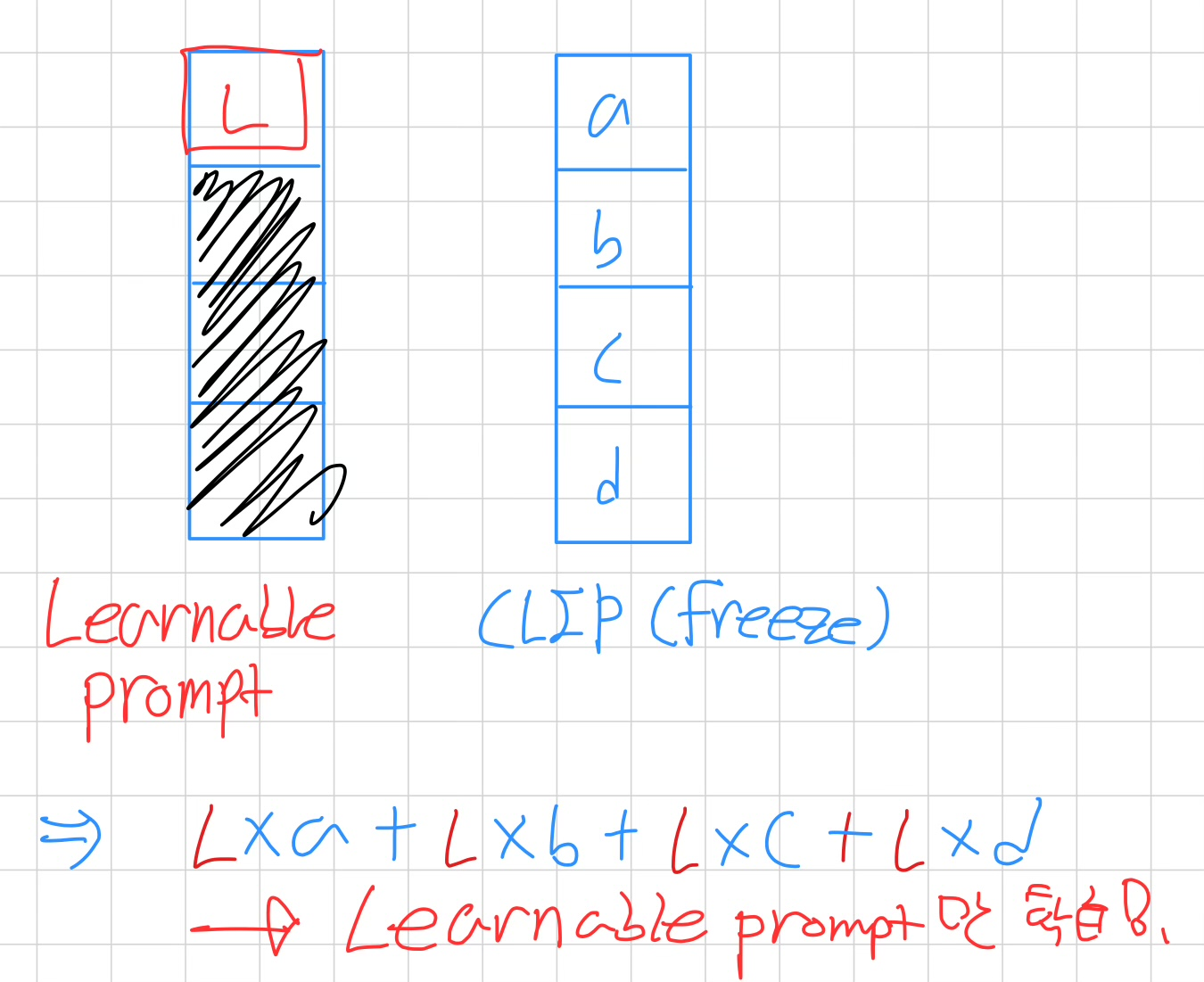
이를 통해 masked image의 CLIP 성능이 대폭 증가된다고 한다.

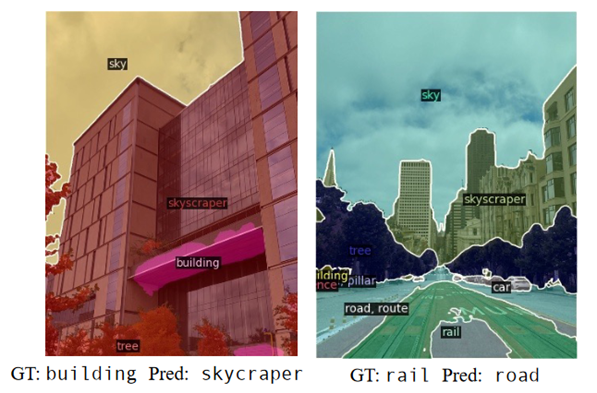
✔️ 제시한 Query에 따라 segmentation이 매우 잘 됨을 확인할 수 있다.
⚠️ 참에 해당하는 카테고리는 Building & Rail인데 예측한 문장은 skyscraper & road
- 의미는 동일하나 엄밀히 틀린 예측에 해당함
이러한 뜻은 비슷하나 다른 단어들을 구별하는 능력에 한계가 있다는 것으로 논문은 마무리를 하였다.
