🎯연구 동향 파악
1.[간단리뷰] Segment Anything

segment model의 “foundation model”을 만들어 보겠다 > foundation model? 논문 상에서는 두 가지 요건을 설명하고 있다. 새로운 dataset에 대하여 zero-shot 혹은 few-shot learning을 수행해야함 p
2.[간단리뷰] Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP

Adopted vision-language model을 통해 segment image 성능 향상
3.[간단리뷰] MSeg3D: Multi-modal 3D Semantic Segmentation for Autonomous Driving

Camera: scence에 대한 풍부한 정보를 가지고 있지만, object의 크기가 다양할 때, segment 성능이 낮아지고 3D segmentation 적용이 쉽지 않다.Lidar: 3D semantic segmentation이 가능하지만, laser point들
4.[간단 리뷰] Augmentation Matters: A Simple-yet-Effective Approach to Semi-supervised Semantic

Semi-supervised Semantic segmentation(SSS)의 일반화 성능 향상을 위한 Data augmentation 기법을 제시한 논문이다 computer vision을 위한 dataset에서 일일히 labeling시키는 것은 cost가 매우 나가
5.[간단 리뷰] SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields

NeRF는 Multi-view image와 해당 카메라의 방향 및 공간 좌표 정보만으로 3D 장면을 암묵적으로 표현하는 방식이다.실제 데이터가 3D mesh data가 아니고 기하적 구조를 띄우지 않지만 MLP의 가중치에 내제되어 있다는 점에서 '암묵적'이란 표현을 씀
6.[간단 리뷰] Emerging Properties in Self-Supervised Vision Transformers

Link : Emerging Properties in Self-Supervised Vision Transformers이미지를 여러 patch로 나누어 embedding 후, 각 패치를 하나의 token으로 생각하여 transformer 구조에 입력한다.$\\righta
7.[논문리뷰] Anomaly Detection via Reverse Distillation from One-Class Embedding
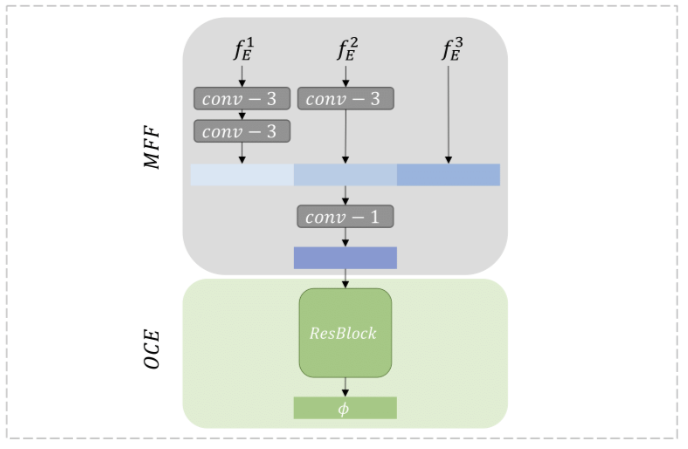
H. Deng and X. Li, "Anomaly Detection via Reverse Distillation from One-Class Embedding," arXiv preprint arXiv:2201.10703, 2022. [Online]. Available: