
segment model의 “foundation model”을 만들어 보겠다
foundation model?
논문 상에서는 두 가지 요건을 설명하고 있다.
1. 새로운 dataset에 대하여 zero-shot 혹은 few-shot learning을 수행해야함
2. prompting 기술을 이용해 특징 task를 수행할 수 있어야함
Promptable model & pre-trained it on a broad dataset
진정한 foundation model을 구성할려면 세 가지 구성 요소를 고려해야 한다고 한다.
- What task will enable zero-shot generalization?
- What is the corresponding model architecture?
- What data can power this task and model?
먼저 segmentation을 위한 large-scale source가 존재하지 않으므로 “data engine”이라는 기술을 통해 data를 수집하고록 한다.
- data engine을 사용하여 data를 수집한다.
- 새로운 data를 토대로 모델의 성능을 개선시키는 작업을 반복적으로 진행한다.
1. task
✅ the goal is to return a valid segmentation mask given any segmentation prompt
여기서 “promptable하다”는 뭔 말일까?
Query로써 text 혹은 spatial information을 주어졌을 때, 합리적인 segmentation 결과가 나와져야 한다는 뜻이다
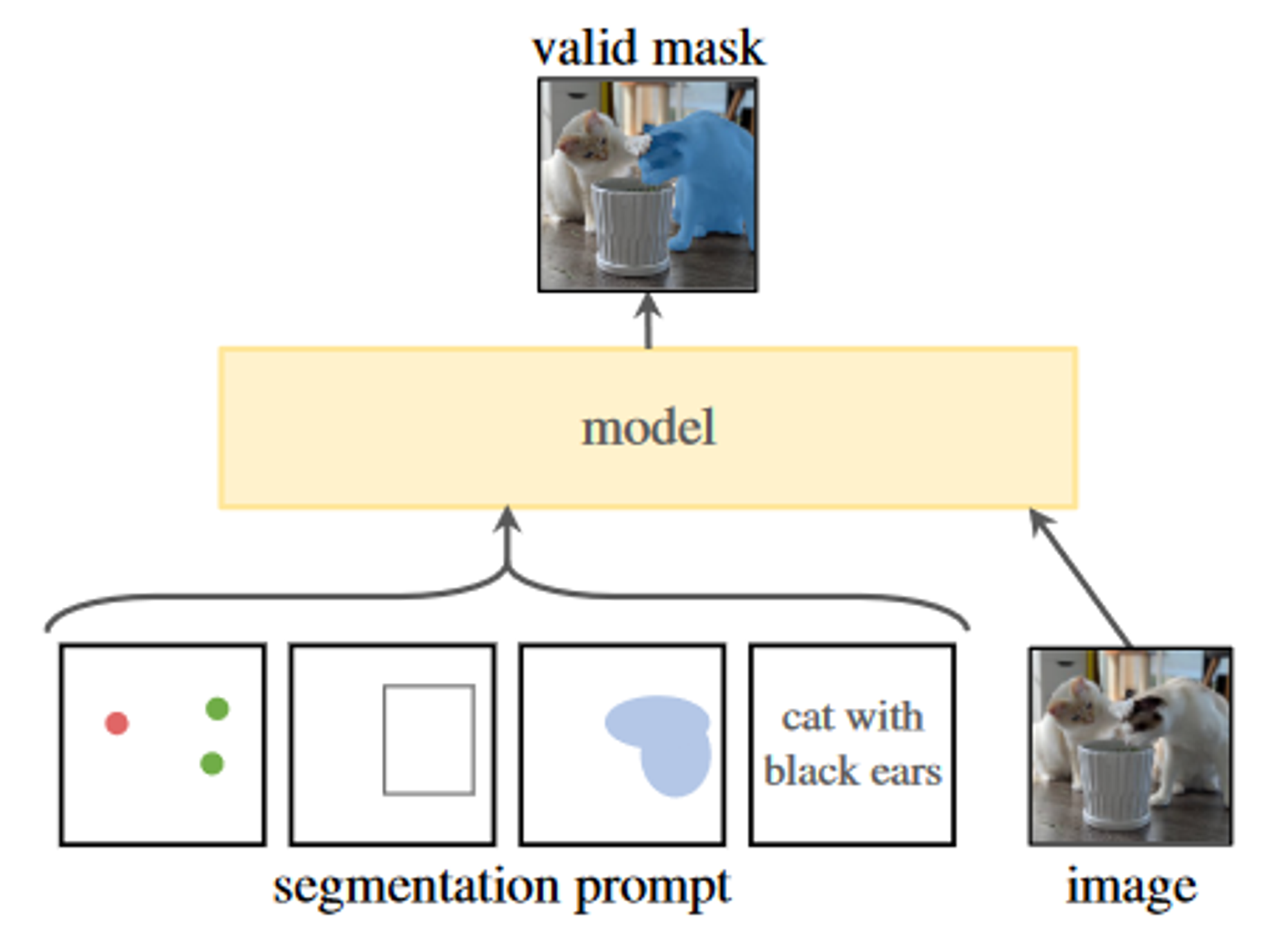
심지어 prompt가 애매모호하거나 여러 조건들을 붙이더라도 masking 결과는 합리적이어야 한다.
2. model
foundation model을 위해 다음과 같은 조건을 만족해야한다.
- flexible prompt
- compute mask in real-time
- must be ambiguity-aware
3. Data
새로이 얻은 data distribution에 대해서 강력한 일반화 성능을 얻기 위해서, SAM에 굉장히 종류가 다양하고 거대한 mask dataset을 있어야한다.
Sgement Anything (SA) project의 이유
model의 성능은 다음과 같은 요소에 의해서 결정됨
- model scale
- dataset size
- total training compare
그러나 Computer vision에는 충분한 dataset이 없다
그래서 CV의 foundation model을 구성하기 위해 어떻게 구성했는가?
Segment Anything Model (SAM)
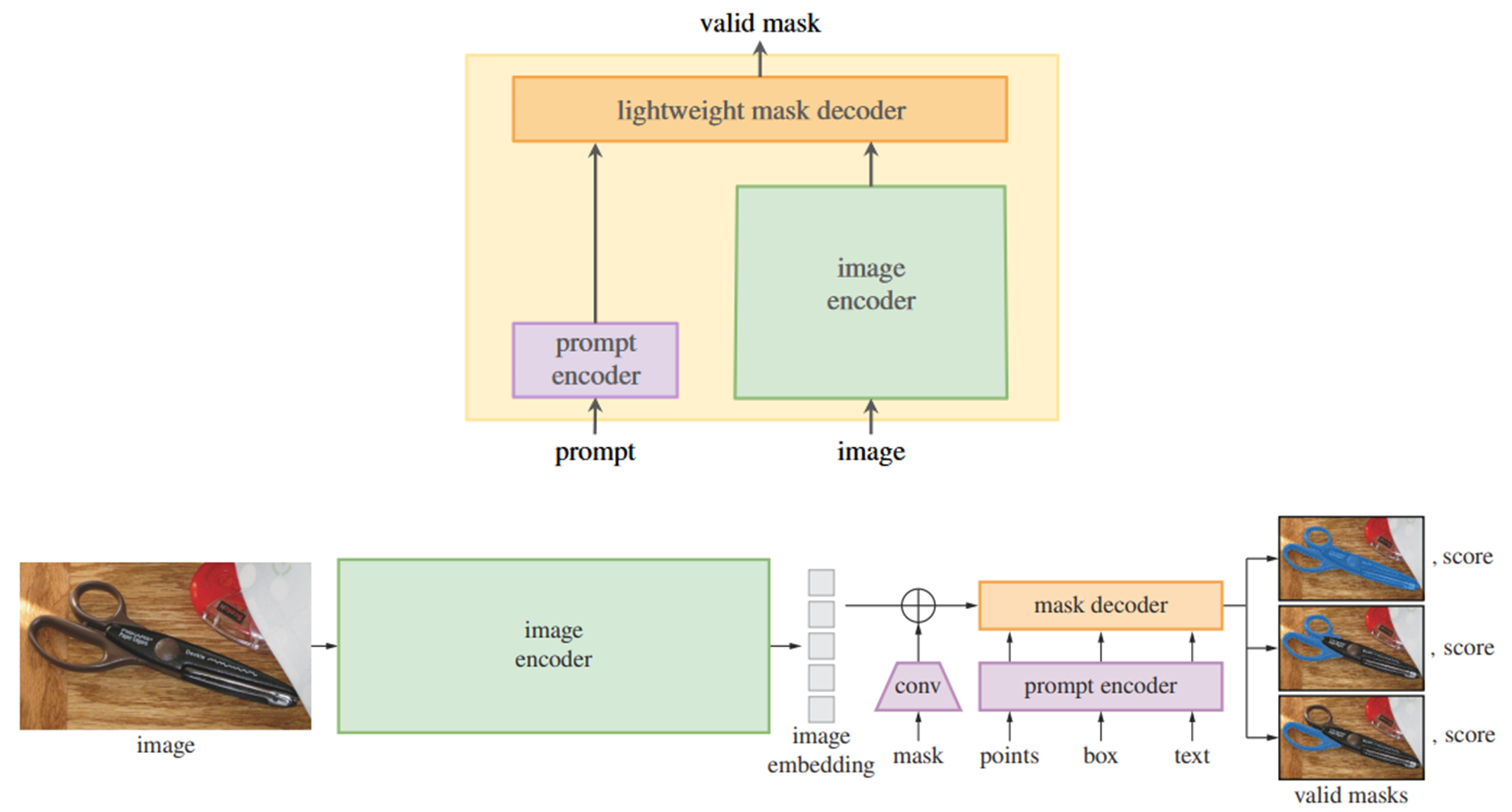
- flexible prompt
- image encoder와 prompt encoder / mask decoder 세 가지로 구성한다.
prompt encoder에 다른 입력이 들어와도 image encoder는 동일한 작업을 하기 때문에
prompt에 굉장히 유연하다.
- compute mask in real-time
- Embedding된 image은 Web-browser에서 ~10ms로 searching을 통해
prompt encoder와 mask decoder prediction을 진행한다.
- must be ambiguity-aware

- single prompt에 대해서 multiple maks를 예측함으로써, 모호성을 잡아낼 수 있다.
- 가령 타조 머리에 annotation 했다면, 이것이 타조 머리인지? 타조 몸통인지? 타조 전체인지?에 대한 여러 task를 잡아내고, G.T.와 비교하여 score를 매기도록 한다. 이를 통해 prompt의 모호성을 잡아낼 수 있다.
data engine
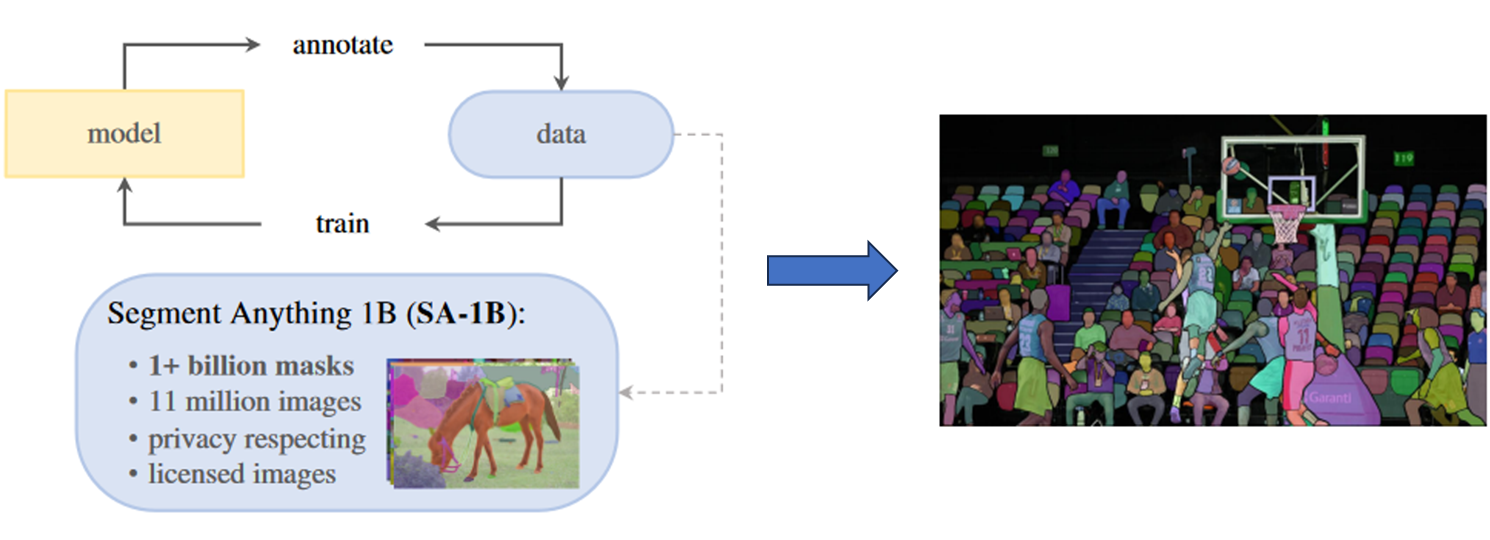
data engine에는 3단계로 이뤄짐
assisted-manual / semi-automatic / fully-automatic
assisted-manual
- 전문가들이 mask를 직접 annotate시킴 (전통적인 대화형 segmentation 설정과 유사)
semi-automatic
- SAM은 prompt을 통해 object에 대한 mask를 자동으로 생성시킨다. 예측한 mask는 전문가가 추가적으로 보정을 해준다.
fully-automatic
- foreground point의 규칙적인 그리드를 prompt하여 평균적으로 이미지당 약 100개의 고품질 mask를 생성
conclusion


✔️ SAM이 segment에 실패해도 하나의 prompt에 multi-task (point)를 수행함으로써 정확성을 올릴 수 있었음
✔️ SAM는 pretrain model로써, downstream task에 맞춰서 적용하면 되는데, fine-tuning을 위해서 self-supervied learning의 중요성이 커질 듯
⚠️ SAM은 아직 고쳐야할 점들이 많음
- 미세한 구조에 대해서는 놓치는 부분들이 많고, 작은 구성 요소들이 hallucination를 일으킬 수 있
- image encoder가 무겁나면 real-time processing이 어려움
- text-to-mask task가 아직 완벽하게 강인하진 않음
- 더욱 뛰어난 segmentation을 위한 prompt 디자인은 아직 몰루?
