[간단 리뷰] Augmentation Matters: A Simple-yet-Effective Approach to Semi-supervised Semantic
🎯연구 동향 파악

Semi-supervised Semantic segmentation(SSS)의 일반화 성능 향상을 위한 random intensity based Data augmentation
computer vision을 위한 dataset에서 일일히 labeling시키는 것은 cost가 매우 나가는 문제가 발생한다.
따라서 최근에 object classification/detection 및 segmentation같은 downstream task을 위해 semi-supervised learning 혹은 unsupervised learning에 대한 연구가 많이 진행되고 있다.
해당 논문은 semi-supervised learning에서 data augmentation을 다룸으로써 일반화 성능을 높히는 논문을 제시하고 있다.
Semi-supervised learning은 다음과 같은 가정을 따른다.
1. Smoothing assumption :
인접한 data point들은 그 출력 값 또한 인접할 것
2. Cluster assumption :
Data point들이 같은 cluster에 있다면 같은 class에 속할 것
이로 인해 약간의 data perturbation이 일어나도 일관성이 존잰
3. Manifold assumption :
고차원의 data point는 저차원의 manifold으로 표현가능
SSS에서 Data augmentation problem
기존 SSS data augmentation의 경우, auto-augmentation technique을 사용하는데, 다음과 같은 문제가 발생하게 된다.
-
SSS에서 data augmentation의 경우 하나의 image에 대해서 서로 다른 view를 제공해주는 것이 목적이므로 auto-augmentation이 합리적인 technique이 아님을 지적
-
기존 Copy-Paste 방식은 unlabeled sample간의 혼합에 의존하는데, 이는 pesudo label에 과도하게 의존하여 confirmation bias를 유발할 수 있다
(auto-augmentation 및 RandomAug은 마지막 장 Appendix에 설명해주겠다)
How to slove it? (AugSeg)
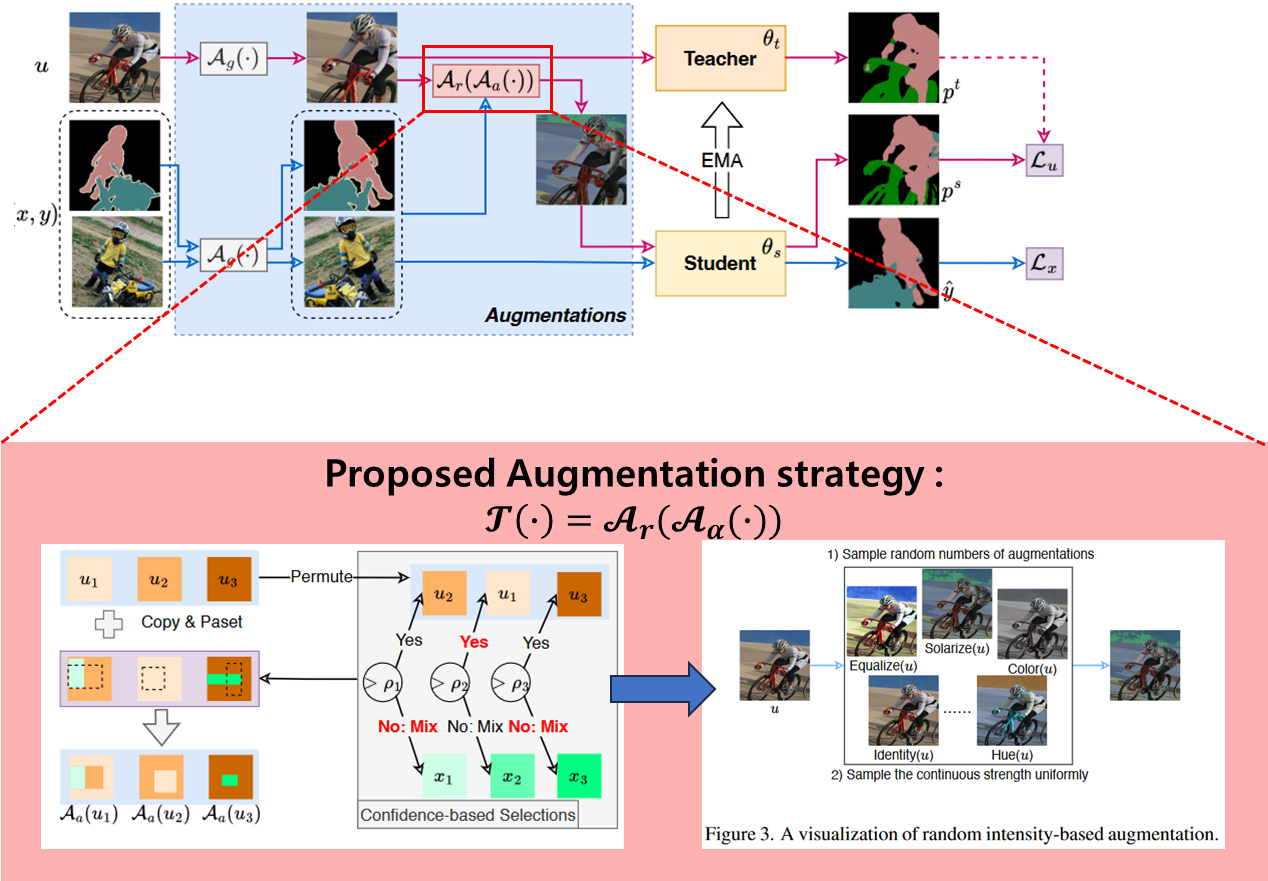
random intensity-based augmentation ()
- discrete space 대신 continuous space상에서 intensity를 균일하게 샘플링한다.
- augmentation pool의 크기를 고정하지 않고 random하게 하여 data diversity를 높인다.
- 제시한 augmentation pool에서 invert같은 strong intensity-based augmentation은 제거하고 RandomAug와 같이 pool을 단순화시킨다.

이렇게 함으로써 data distribution distort는 최소화하면서도 Semi-supervised learning에 적합한 augmentation을 수행할 수 있게 된다.
Adaptive CutMix-based augmentation ()
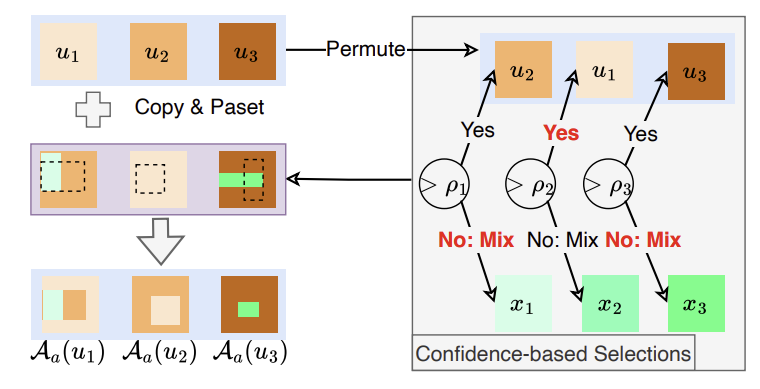
모델의 현재 예측에 대한 신뢰도 점수 를 계산하여, 이를 unlabeled-labeled 혼합 여부를 결정하는 triggering probability로 사용한다.
최종적으로 이렇게 생성된 혼합 후보들과 원래 unlabeled 데이터를 추가로 혼합하여 augmented data를 생성한다.
Appendix
Auto augmentation
Downstream task에 맞는 최적의 augmentation 전략을 찾는 기법이다.
특정 dataset에 대한 augmentation 전략이 맞더라도 다른 dataset으로 전이하는 경우 일반화 능력이 떨어질 수 있기 때문이다.
RandomAug
기존의 Auto augmentation 기법들은 대상 작업에 최적화된 증강 전략을 찾기 위해 복잡한 탐색 과정을 거치는 반면, RandomAug는 이를 단순화하여 임의의 증강 기법들을 조합하는 방식을 취한다.
- discrete space에서 증강 기법들의 조합을 샘플링한다. (각 조합은 하나 이상의 증강 기법으로 이루어진다.)
- augmentation의 magnitude은 사전에 정의된 범위 내에서 랜덤하게 샘플링된다.
- augmentation의 종류와 개수는 미리 정해진 집합(pool)에서 random하게 선택된다.
- 일반적으로 좀 더 약한 augmentation들이 더 자주 선택되도록 Weight를 부여한다.
