[간단 리뷰] SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
🎯연구 동향 파악

NeRF...?

NeRF는 Multi-view image와 해당 카메라의 방향 및 공간 좌표 정보만으로 3D 장면을 암묵적으로 표현하는 방식이다.
실제 데이터가 3D mesh data가 아니고 기하적 구조를 띄우지 않지만 MLP의 가중치에 내제되어 있다는 점에서 '암묵적'이란 표현을 쓴다

inpainting 3D scene은 장면에서 보이는 임의의 object를 제거하고 누락된 pixel를 예측하여 복원해주는 기술이다.
(NeRF를 이용하여 2D 이미지를 3D로 변환한 결과물)

기존 NeRF기술들의 문제점
- NeRF는 3D-mesh와 같이 명확한 형태로 나타나 있지 않고, Network의 weigh에 내제되어 있어 조작이 쉽지 않다.
- inpainting된 3D 장면은 단일 시점에서만 아니라 다른 여러 시점에서도 모형과 기하적으로 그럴듯하게 보여야한다.
- 전문가가 annotation을 지정하기 위해선 3D보단 2D에서 더 많은 직관을 얻을 수 있다.
그러나 다양한 시점에서 object에 대한 annotation을 전부 지정하는 것은 어렵다.
저자는 단일 시점에서 최소한의 annotation만으로도 여러 시점에서 일관된 3D-segmentation mask를 얻을 수 있다고 주장한다.
최소한의 annotation만으로도 일관된 3D-segmentation mask를 얻을 수 있을려면?
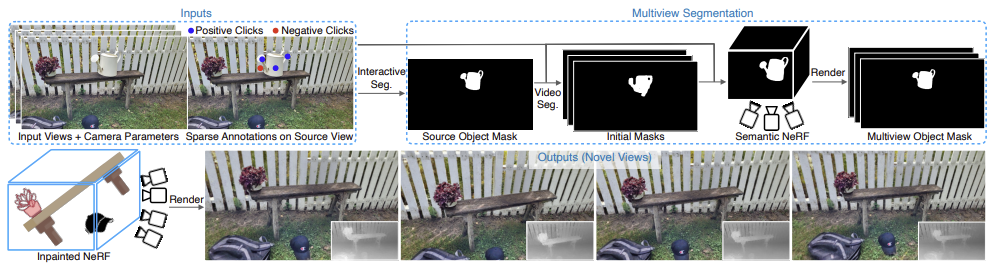
- 전문가가 object 위에 annotation을 지정하면, video-based model(vision-transformer)로 초기 mask를 생성한다.
전문가가 object에 대한 annotation를 지정하면 알아서 Segmentation mask를 만들어주는 것을 interactive segmentation라고 한다.
Positive click : 관심 object에 해당된 point
Negative click : 관심 object가 아닌 point
-
mask를 semantic NeRF에 fitting하여 여러 시점에서도 일관된 semantic segmentaiton mask을 3D로 랜더링한다.
-
multi-view image set에 pre-trained 2D inpainter를 적용하여 2D inpainting image를 생성한다.
-
customized NeRF fitting process
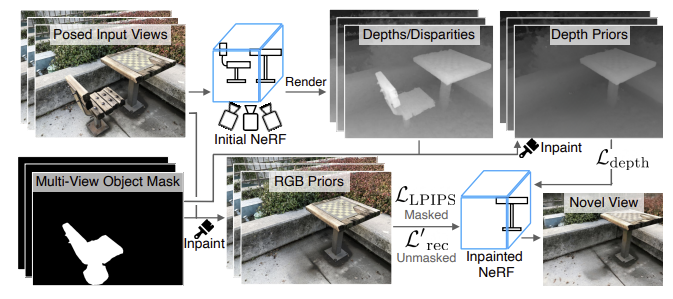
- 2D inpainting image
- mask 영역의 기하학적 구조를 정규화하기 위한 inpainting depth image
두 가지 요소를 perceptual loss(지각 손실)을 통해 3D inpainting scene을 재구성한다.

연구 동향 파악 중간 점검
- Labeling Problem
- 현재 방대한 양의 image dataset을 labeling 시키는 것은 불가능하다고 함
- pre-trained model에 대한 연구가 활발한 만큼, self-supervised learning에 대한 중요도가 높은 것 같음
- Multi-modal
- vision-text modality: pre-trained model을 어떻게 fine-tuning을 할 것인가?에 대한 주제
- Lidar-camera modality:
- NeRF
- 좀 더 진행해봐야 알 듯!
