H. Deng and X. Li, "Anomaly Detection via Reverse Distillation from One-Class Embedding," arXiv preprint arXiv:2201.10703, 2022. [Online]. Available: https://arxiv.org/abs/2201.10703 (2022 CVPR)
INTRODUCTION
Unsupervised Anomaly Detection(UAD)에서 Knowledge Distillation(KD)은 Teacher-Student 모델을 활용하는 접근 방식이다. 이 기법은 사전 학습된 Teacher 모델의 지식을 Student 모델로 전이(transfer)하는 데 초점을 맞춘다.
UAD 관점에서 일반적인 Teacher-Student(T-S) 모델 전략은 다음과 같다:
학습 과정에서는 Normal 데이터만 제공하고, 추론 과정에서는 Anomalous 샘플이 입력되었을 때 Teacher와 Student 모델에서 생성한 Representation의 차이를 계산한다. 이는 Teacher 모델이 Anomalous 샘플에 대한 Representation을 생성할 수 있지만, Student 모델은 그렇지 못하다는 점에서 착안한 방법이다.
하지만 기존의 t-s model method는 다음과 같은 한계점을 가지고 있다.
- Teacher와 Student 모델의 아키텍처가 동일한 경우, 샘플을 처리하는 논리 또한 동일하기 때문에 Anomaly를 발견하기 어려울 수 있다.
- Data Flow가 Teacher와 Student 모델에서 동일하게 구성되므로 차별화된 표현이 어렵다.
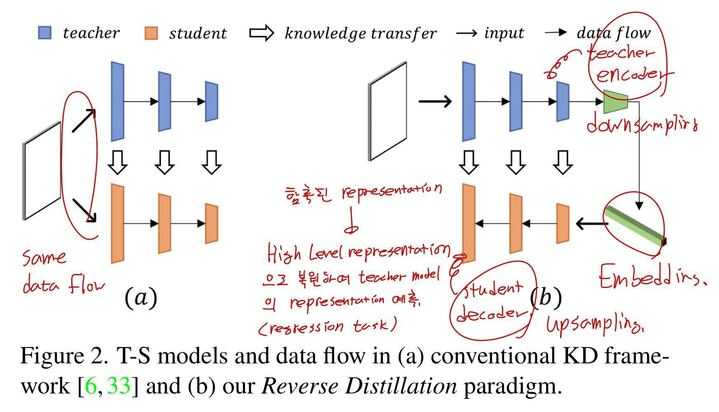
이러한 문제점을 해결하기 위해서 본 논문은 Reverse Distillation이라는 knowledge distillation에 대한 새로운 paradigm을 제시하고 있다.
구체적으로, Teacher Encoder와 Student Decoder를 결합하여 Heterogeneous 아키텍처를 구성한다. 이 구조에서 Student 모델은 Low-Dimensional Embedding을 입력받아 Teacher 모델의 Representation을 예측하도록 설계되었다. Regression Task 관점에서 이는 Low-Level Embedding 입력값을 통해 Teacher Representation을 재현하는 행위로 볼 수 있다.
reverse structures는 다음과 같은 장점을 가지고 있다.
- 동일한 아키텍쳐를 가지지 않는 대칭성을 가지고 있다. teacher model을 down-sampling filter으로, student model을 up-sampling filter으로 삼고 있다.
- Compact한 Embedding Vector를 생성하여 Normal 패턴을 복원한다. 이를 통해 Anomalous 요소를 제거하고 Reconstruction된 Representation이 Teacher 모델과 구별되도록 한다.
- Autoencoder 기반 방법이 Pixel 단위 계산으로 높은 연산 비용을 요구하는 반면, Reverse Distillation은 Dense Feature 수준에서 Region 단위로 계산하여 효율성을 높인다.
Reverse Distillation의 효과를 극대화하기 위해, 논문에서는 One-Class Bottleneck Embedding(OCBE)을 제안한다. OCBE는 Multi-Scale Feature Fusion(MFF) 블록과 One-Class Embedding(OCE) 블록으로 구성되며 Student Decoder와 함께 학습 가능한 구조이다. 이를 통해 High-Level Feature와 Low-Level Feature를 결합하여 풍부한 Normal 패턴 정보를 포함한 Embedding을 생성한다.
METHOD
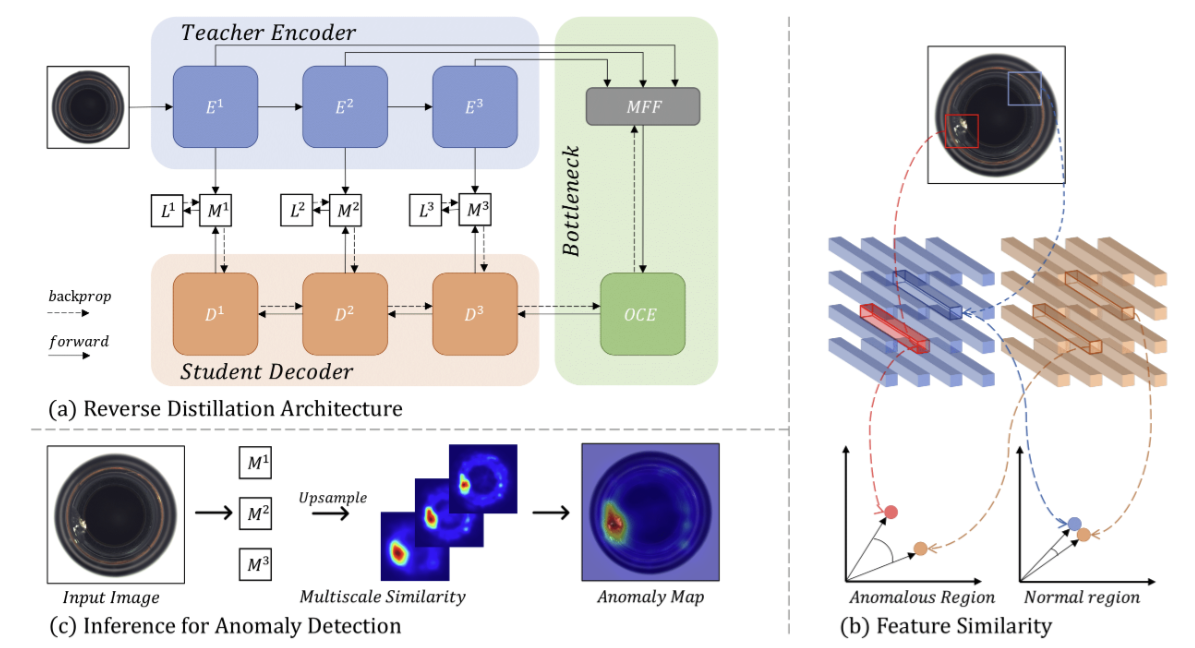
Reverse Distillation
WideResNet을 backbone으로 설정하여 Teacher encoder 와 Student decoder 는 서로 symmetric이면서 reverse한 구조를 가진다.
다운샘플링은 Convolutional layer를 사용해 kernel size를 1, stride를 2로 설정하여 구현하며, 업샘플링은 Deconvolutional layer를 사용해 kernel size를 2, stride를 2로 설정하여 구현한다.
Encoder의 feature를 decoder에서 효과적으로 학습하도록 하기 위해 multi-scale feature-based distillation을 적용한다. Neural network의 shallow layer는 color, edge, texture와 같은 low-level 정보를 담고 있으며, deep layer는 local/global semanic, structural 정보를 포함하고 있다. Teacher-Student(T-S) 모델에서 low-level 및 high-level feature 간 유사성이 낮다면, 이는 local abnormality와 지역적/전역적 구조적 이상(outlier)이 존재함을 나타낸다.
주어진 문장의 내용은 Teacher-Student(T-S) 모델에서 지식 전이를 수행 방법을 수학적으로 정의해보자면 다음과 같다:
-
: 입력 데이터 를 one-class bottleneck embedding 공간으로 투영하는 함수.
-
Teacher와 Student 모델의 k번째 계층에서 활성화(activation) 텐서를 매칭하는 방식으로 지식 전이를 수행.
- Teacher 모델의 번째 계층 활성화:
- Student 모델의 번째 계층 활성화:
- ( ): 채널 수
- ( ): 높이 (Height)
- ( ): 너비 (Width)
-
( h, w ) 위치에서의 Cosine Similarity:
- Anomaly Map :
- Teacher와 Student의 벡터 간 유사성을 기반으로 ( k )번째 계층에서의 이상 탐지 맵을 생성.
multi-scale knowledge distillation을 고려할 때, multi-scale anomaly map을 축적하여 student의 loss function을 얻도록 한다.
One-Class Bottleneck Embedding
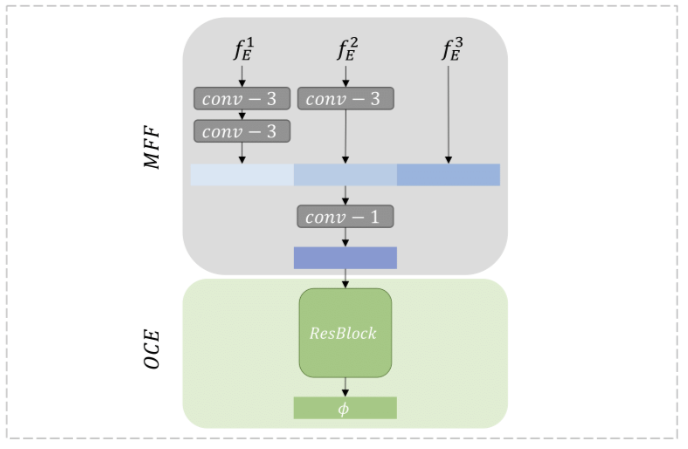
Encoder의 마지막 embedding block에서 출력된 벡터를 바로 Decoder의 입력 벡터로 사용할 경우 다음과 같은 문제가 발생한다.
- Teacher 모델의 고차원 표현은 풍부한 정보를 포함하지만, redundancy와 high freedom으로 인해 Student 모델이 anomaly-free feature를 정확히 학습하지 못하게 만든다. 이러한 문제는 Student 모델이 필요하지 않은 anomaly-related feature까지 학습하게 하여, Knowledge Distillation의 효과를 저하시킬 수 있다.
- 마지막 layer에서 출력된 embedding 벡터는 high-level information을 포함하고 있기 때문에, Decoder가 이를 기반으로 low-level information(예: color, edge, texture)을 추정하는 것이 어렵다.
논문에서는 이러한 문제를 해결하기 위해 학습 가능한 One-Class Embedding Block(OCBE)을 도입하여 Teacher 모델의 high-dimensional representation을 low-dimensional space로 투영하도록 한다. 이와 함께, low- 및 high-level feature를 MFF(Multi-scale Feature Fusion) block에서 concatenation하여 high-dimensional representation을 생성하도록 설계한다.
One-Class Embedding을 위해 다음과 같은 구조를 제안한다:
- 하나 이상의 Convolutional Layer(stride = 2)와 Convolutional Layer(stride = 1)를 포함하여 down-sampling을 구현.
- 각 Layer를 통과할 때 ReLU Activation Function을 적용하며, Convolutional Layer에는 추가로 Batch Normalization을 적용.
OCBE를 통해 얻을 수 있는 주요 이점은 다음과 같다:
- High- 및 low-level feature 정보를 포함하면서도 compact한 표현이 가능하다.
- Student 모델이 샘플의 정상 패턴(normal pattern)을 효과적으로 학습할 수 있다. 즉, Teacher 모델에서 추출한 feature를 정확히 추정할 수 있다.
Anomaly Scoring
실제 추론 과정에서 teacher model은 anomality에 대한 feature를 원활하게 추출해준다. 하지만, student model은 anomaly-free representation을 생성하도록 학습했기 때문에 teacher model과 다른 형태가 될 것이다.
T-S representation pair로부터 얻은 anomaly map 의 집합을 얻을 수 있다. 여기서 map안의 크기들은 k번째 feature 텐서의 point-wise anomaly를 의미한다.
query image에서 anomality를 localize할려면, 을 image size에 맞춰서 up-sampling이 진행되어야 한다. 를 bilinear up-sampling operation으로 정의한다면, 모든 anomaly map들에 대한 pixel-wise accumulation 는 다음과 같이 표현된다.
up-sampling된 score map의 noise를 제거하기 위해 Gaussian filter를 적용한다.
에 모든 value를 평균값을 취하면 anomalous region의 value들은 score map에 대한 response가 가장 높다는 것을 확인할 수 있다. 따라서 에 최댓값을 sample-level anomaly score 로 정의한다.
EXPRIMENTS
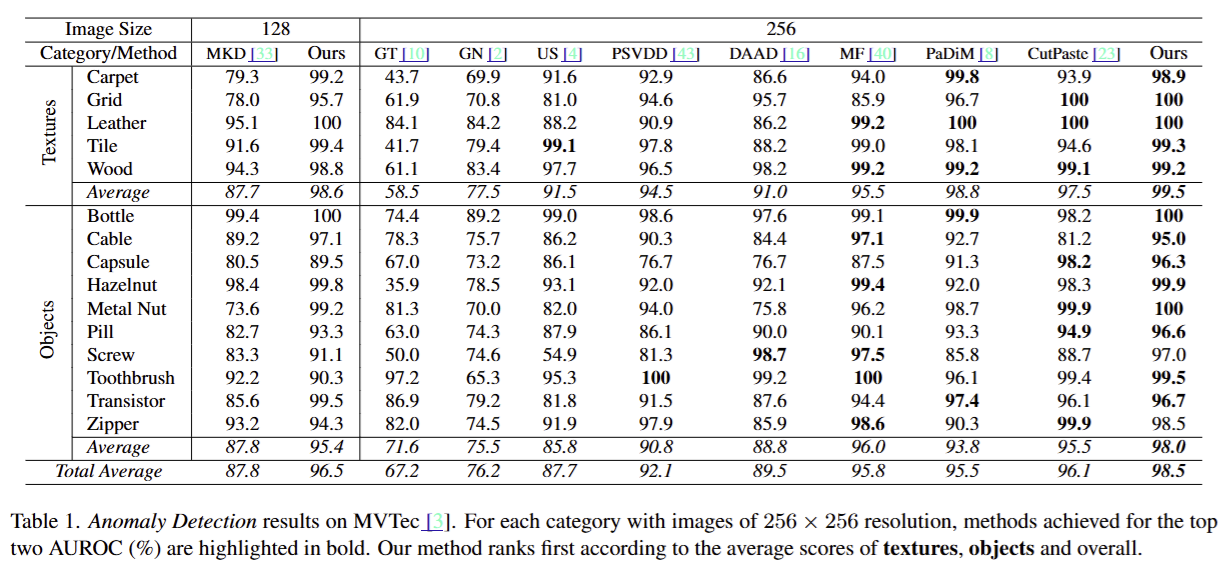
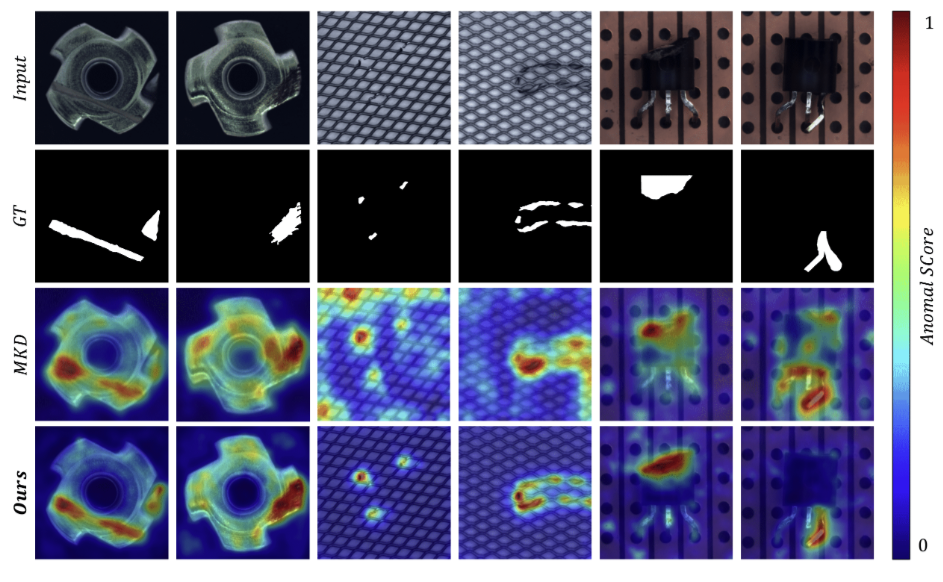
의 anomality dataset에 대한 실험 결과를 TOP-2 AUROC(%)로 나타낸 것이다. Reverse Distillation method가 모든 threshold에서 높은 binary classification performance를 보여준다.
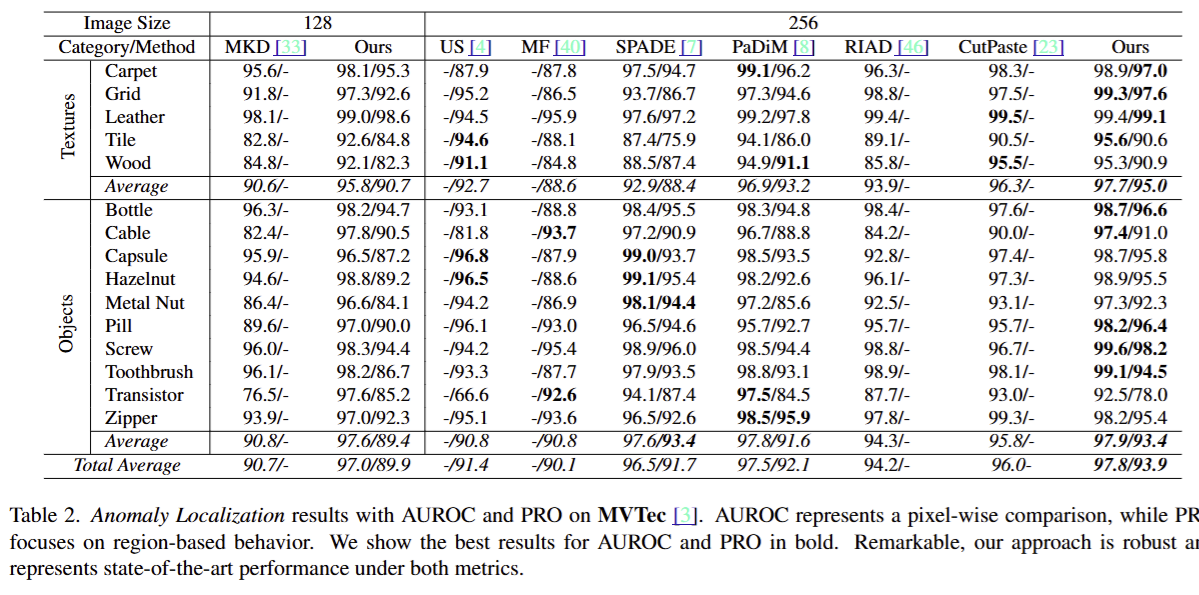
anomaly localization에 대한 정량적 평가는 위와 같다. AUROC와 PRO average score 두 가지 평가 지표를 사용한 것으로 보인다.
PRO score: anomaly regions과 예측된 이상 영역 간의 영역 기반 비교를 수행.
- 픽셀 단위가 아니라, 이상이 존재하는 특정 region의 크기와 위치가 얼마나 잘 예측되었는지를 평가.
- 실제 이상 영역 과 예측 영역의 Intersection over Union (IoU) 계산.
AUROC는 픽셀 단위로 one-classification performance를 평가, 큰 anomality에 편향될 위험 존재.
PRO score는 IoU를 통해, localize performance 평가
AUROC - pixel 단위로 평가한 결과, 전반적으로 매우 좋은 성능을 냄을 확인
PRO score - transistor dataset에서 localization performance는 매우 poor함을 확인
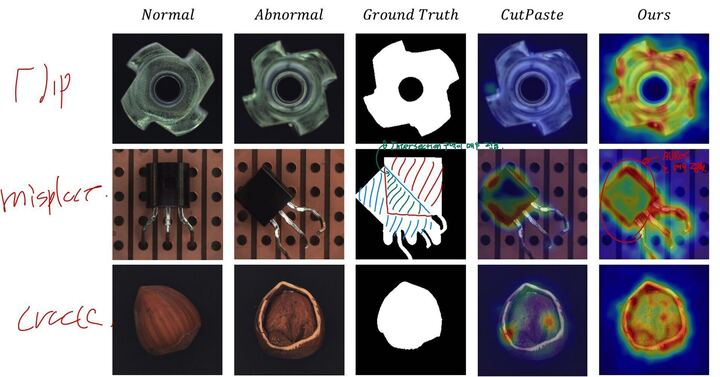
공간적으로 크게 틀어지는 경우에 detection이 힘든 것을 확인
- student model에 들어오는 sample은 anomality이기 때문에 detection은 되지만, localization이 안되는 것을 확인
- higher-level layer의 feature를 MFF에 넣을 때 더 높은 AUROC를 달성
- 128 128 으로 resizing 시킨다면 resolution이 감소하여 높은 AUROC를 달성
