
Link : Emerging Properties in Self-Supervised Vision Transformers
Background
ViT
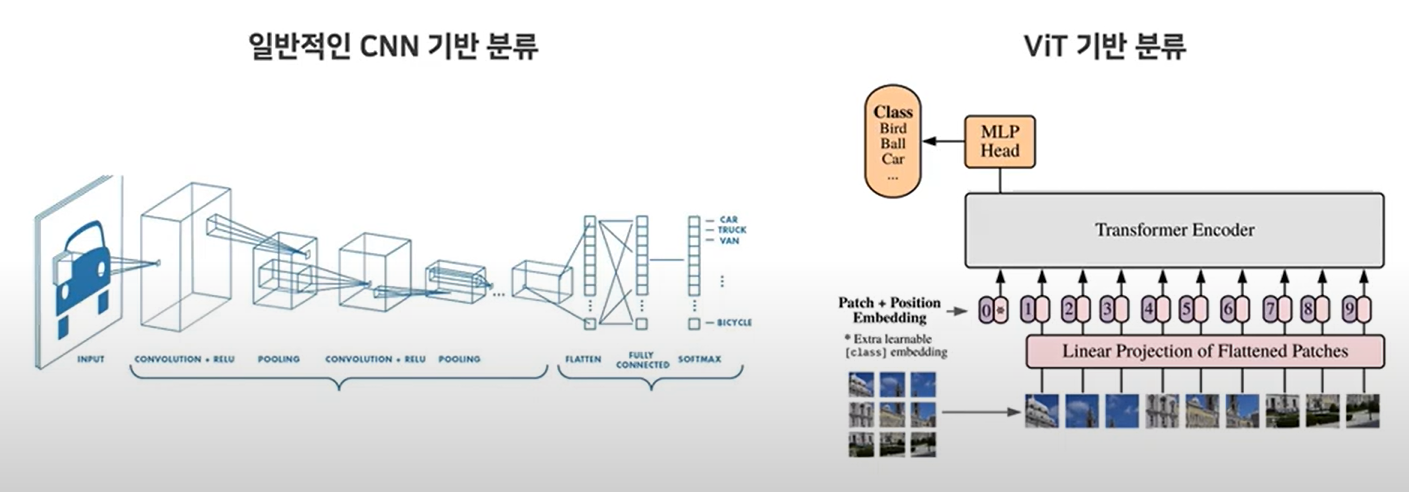
- 이미지를 여러 patch로 나누어 embedding 후, 각 패치를 하나의 token으로 생각하여 transformer 구조에 입력한다.
이후 class token을 추가하여 학습 후, FC layer를 통해 class를 예측하도록 한다. - CNN의 inductive bias (translation invariance 및 locality 같은 가정)을 크게 줄여줘 모델의 자유도가 높다. 대신 학습에 다량의 데이터가 필요하다.
Knowledge Distillation (지식 증류)
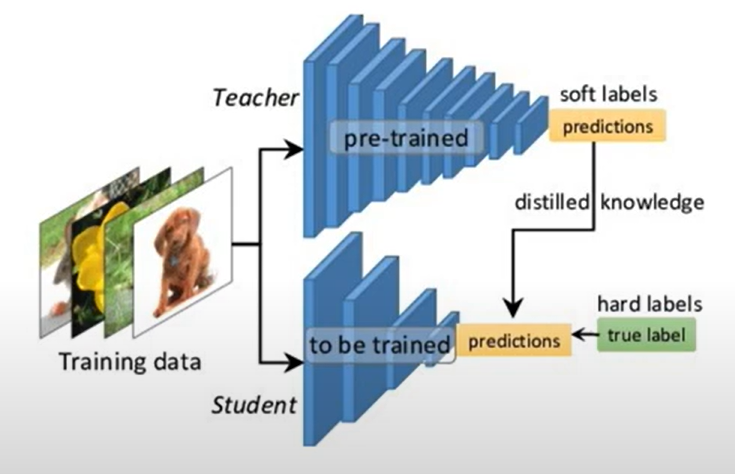
- teacher와 student 모델을 이용해 교사의 예측 분포를 학생 모델에 전이하는 방법론
- Soft/Hard label을 기반으로 큰 모델이 갖는 일반화 능력을 작은 모델에 전이할 수 있다.
Soft labels : 교사 모델의 예측 분포
Hard label : 정답
Self-supervised model
- 정답이 없는 상황에서 데이터 자체가 갖고 있는 특성을 기반하여 레이블이 없이 학습하는 방법론
- Unsueprvised learning의 한 방법론, downstream task를 잘 수행할 수 있도록 하는 representation을 얻기 위함 (Representation learning)
DINO 전체 모델

DINO 모델의 학습 과정을 보여주고 있다.
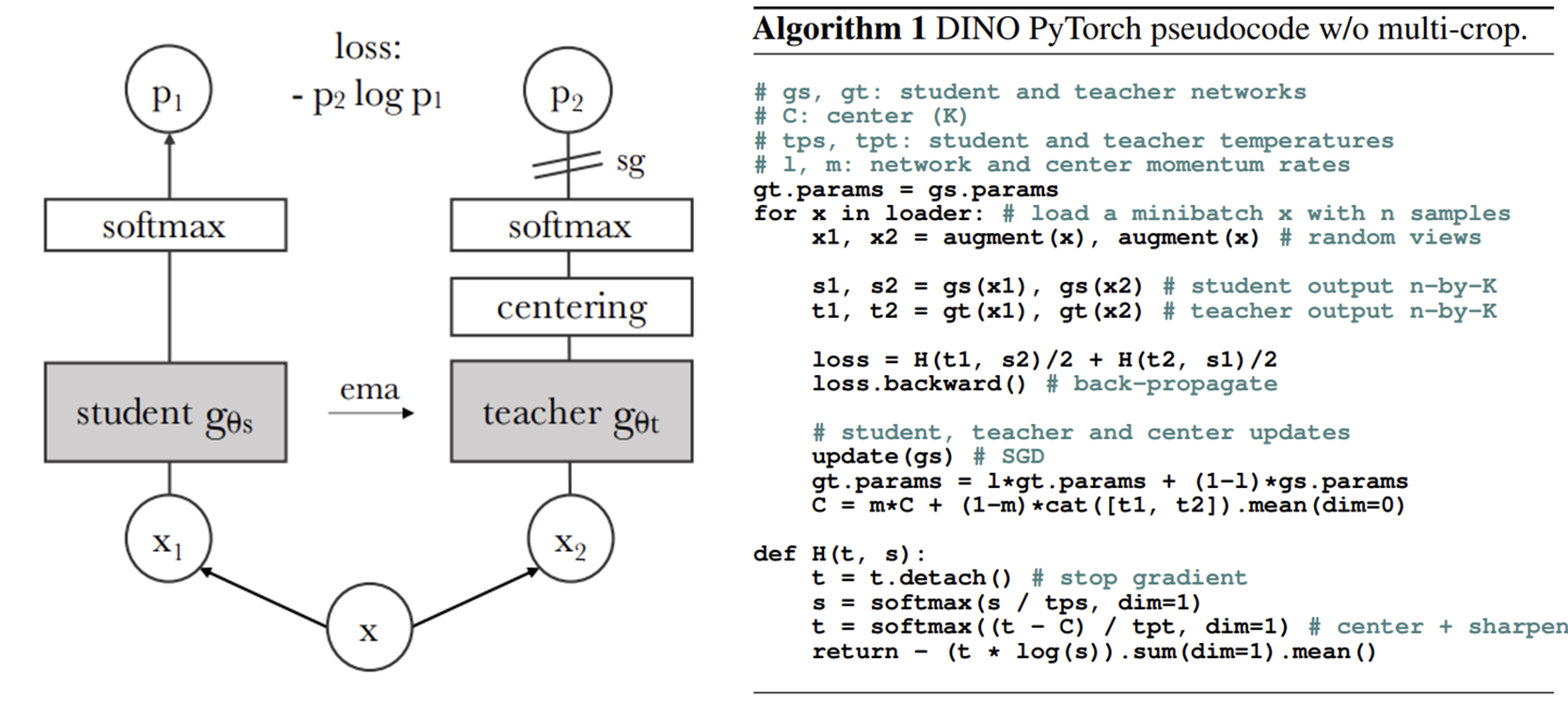
Fig1. Self-distillation with no labels
- 와 은 각각 Anchor data 그리고 positive or negative data이다.
- 오직 학생 모델에 대한 backpropagation을 진행하도록 한다.
- 학생 모델에서 하나의 epoch에 끝날 때, mini-batch를 통해 업데이트한 파라미터는 ema(exponential moving average)를 통해 교사 모델에 소폭 업데이트를 반영한다.
교사 모델은 학생 모델들의 앙상블과 동일한 효과이므로 항상 학생 모델에 비해 더욱 높은 성능을 보인다.
-
하나의 입력 이미지에서 큰 패치 (224 224)를 Global view, 작은 패치(96 96)를 Local view이라고 한다.
- 학생 모델 : 모든 패치를 입력으로 활용
- 교사 모델 : Global view 패치만 입력하여 학습 -
각 네트워크로부터 출력된 레이블 간의 Cross-entropy Loss를 활용해 학생 모델의 가중치() 업데이트한다.
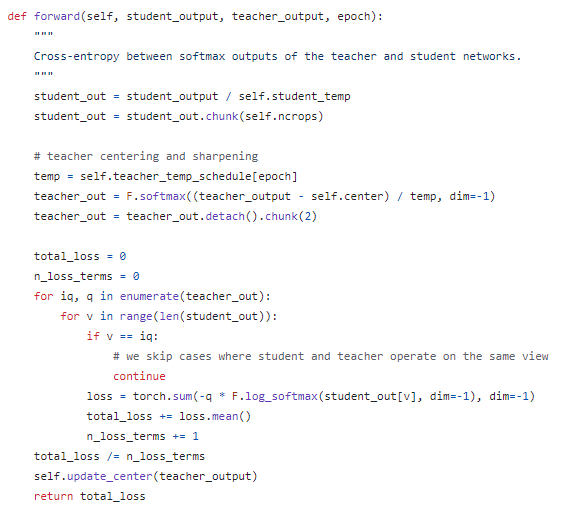
Dino 모델의 forward 구조
ViT를 encoder (backbone)으로 활용하는 경우에는 Batch Normalization을 사용하지 않는다
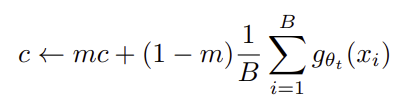
Collapse를 방지하기 위해 centering과 sharpening을 동시에 사용한다
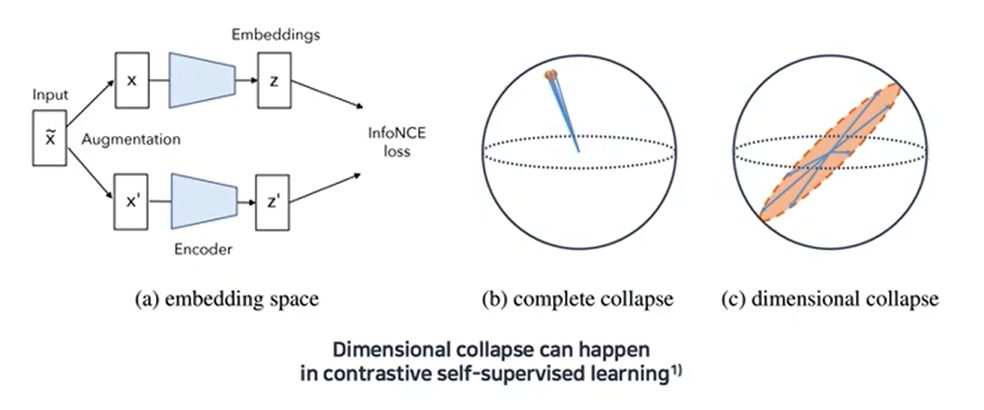
- complete collapse를 없애주기 위해서 교사 모델에 bias를 더해준다. 특정 dismension으로 collapse되는 것을 방지해 주지만 전체 dimension으로 uniform하게 collapse 된다.
- Sharpening을 통해 특정 dimension의 값이 커지도록 조정하면 된다.

semantic한 부분에서 attentation이 잘 되는 것을 볼 수 있다.
Acknowledge

넓은 세상을 올바르게 바라볼 수 있는 날까지!