이 글은 https://www.promptingguide.ai/ 에 나온 내용의 일부를 요약했습니다.
이전글
(1) Prompt Engineering이란?: https://velog.io/@boyunj0226/GPT%ED%95%9C%ED%85%8C-%EC%9E%98-%EB%AC%BC%EC%96%B4%EB%B3%B4%EB%8A%94-%EB%B2%95-Prompt-Engineering-%EA%B0%80%EC%9D%B4%EB%93%9C
(2) Prompt Engineering 방법 1: https://velog.io/@boyunj0226/GPT%ED%95%9C%ED%85%8C-%EC%9E%98-%EB%AC%BC%EC%96%B4%EB%B3%B4%EB%8A%94-%EB%B2%95-2-%EB%8B%A4%EC%96%91%ED%95%9C-Prompt-Engineering-%EB%B0%A9%EB%B2%95
Prompt Engineering을 더 잘하기 위한 방법론은 점점 진화해가고 있습니다. 이번 글에서는 Prompt Engineering을 더 효과적으로 하기 위한 몇 가지 예시들을 더 가져와보았습니다.
Active-Prompt
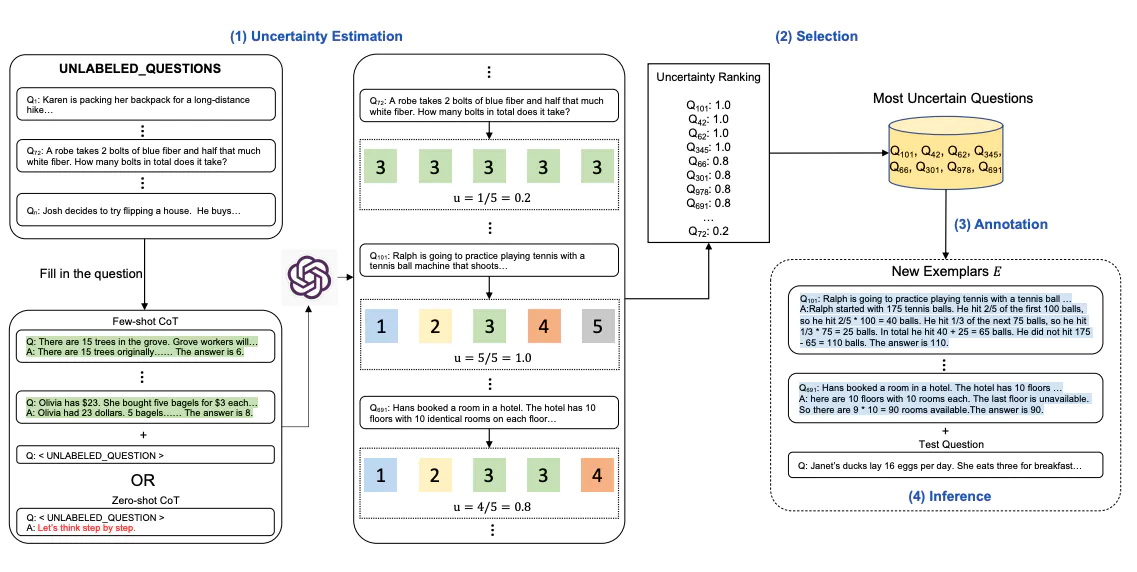
Few-Shot CoT에서 "어떤 예시를 사용할지"에 따라서도 답변은 달라지게 됩니다. 일반적으로 예시가 질의-응답 쌍으로 구성되어있다고 할 때, 조금 더 어렵고 모호한 질문과 이에 대한 답을 예시로 줄 경우 모델은 조금 더 복잡한 질문에도 답을 잘 하게 됩니다. 일반적으로는 사람이 직접 질의-예시 쌍을 만들지만, 다소 어려운 질의를 직접 만드는 것은 어려울 수 있습니다. 이를 해결할 수 있는 방법이 Active-Prompt입니다. 방법은 다음과 같습니다.
- 질의 예시를 여러 개 만듭니다.
- CoT를 통해 라벨링되지 않은, 즉 답변이 없는 상태에서 질의를 주고 답을 하게 만듭니다.
- CoT가 만든 답변에 대해 Uncertainty(모호성) 평가를 합니다.
- Uncertainty가 높은 질의들, 즉 모델이 느끼기에 어려운 질문들을 선택합니다.
- 채택된 질의들에 대해 사람이 직접 답변을 만들고, 이를 Few-Shot CoT의 예시로 사용합니다.
모델 결과를 이용해서 어려운 질문 예시를 직접 선택하게 하는 방식이라고 볼 수 있습니다. 모든 질문에 대한 답변을 만드는 것보다는 모델에 사용하면 괜찮을 어려운 질문에만 답변을 만들면 되기 때문에 보다 더 효율적으로 Few-Shot Prompt를 작성할 수 있게 됩니다.
여기서 질문이 하나 생길 수 있습니다. 과연 답변의 Uncertainty를 어떻게 평가할지입니다. 논문에서는 굉장히 단순한 Disagreement라는 방법을 사용합니다. 모델로부터 동일한 질문에 대해 많은 답변을 내놓게 합니다. 답변들 중에 동일한 답변들을 제외하고 unique한 답변의 갯수만 셉니다. 그 갯수를 전체 답변 갯수로 나누는 것입니다. 즉 len(set(답변 리스트)) / len(답변 리스트)라고도 볼 수 있습니다. 논문은 이렇게 단순한 방법을 사용했지만, 답변의 Uncertainty를 평가하기 위해 Entropy나 Variance와 같은 Uncertainty metric을 사용하거나, 모델 스스로 답변이 Uncertain한지 아닌지 판단하도록 질문하는 Self-Confidence 방법도 있다고 Uncertainty 방법에 대한 예시를 주었습니다.
Directional Stimulus Prompting

Directional Stimulus Prompting은 간단히 말하자면, Prompt에 사용할 힌트를 만드는 모델을 하나 더 사용하는 방법입니다. 기사를 2-3문장 정도로 요약하는 테스크가 있다고 가정합니다. 모델에게 답변을 하도록 할 때, 몇 가지 힌트가 되는 단어들을 주면 더 정확한 답변을 할 수 있게 됩니다. 이 힌트를 사람이 직접 만들게 하는 것이 아니라 또 다른 Language Model(LM)을 학습시켜서 힌트 만드는 모델(Policy LM)을 하나 더 만들어 사용하는 방법입니다.
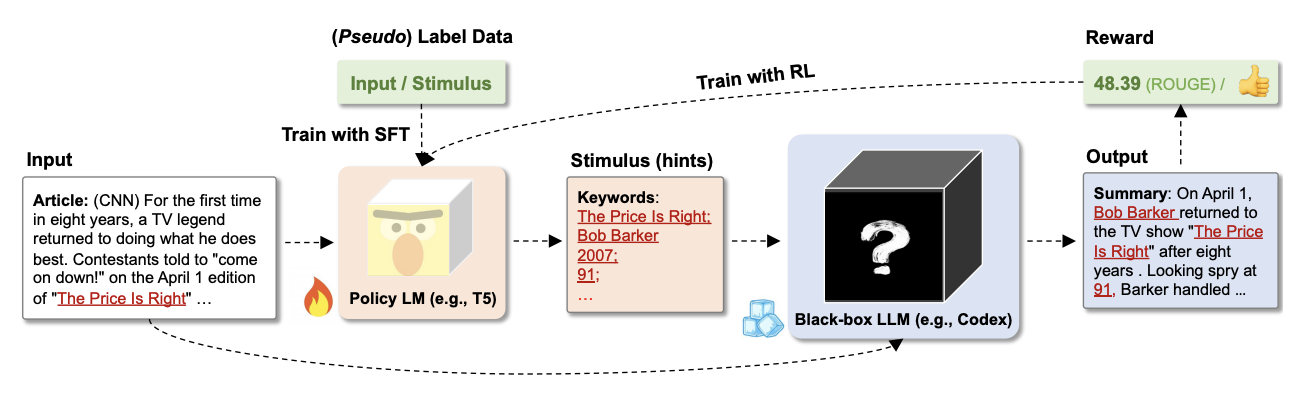
Policy LM은 GPT-4와 같은 거대한 모델이 아니라 T5 같은 간단한 LM 모델을 사용하며, 지도학습과 강화학습을 통해서 학습됩니다. 학습되고 사용하는 과정을 그림과 함께 살펴보면 다음과 같습니다.
- 기사와 힌트(stimulus)가 있는, 힌트가 라벨링된 데이터를 준비합니다.
- 라벨링된 데이터를 이용해서 Policy LM을 학습시킵니다. (Supervised Fine Tuning)
- 기사를 학습된 Policy LM에게 주고 힌트를 생성하게 합니다.
- 기사와 힌트, 그리고 질문(요약해라!)을 prompt를 사용하고자 하는 LLM에게 제공합니다. 논문에서는 일반적으로 우리가 사용하게 되는 LLM이 어떤 답을 줄지 모르기 때문에 LLM을 Black-box LLM이라고 표현했습니다.
- LLM이 output을 가져오면, 답변에 대한 평가를 합니다. 이 때 ROUGE score와 같은 평가 지표를 사용합니다.
- 평가된 결과, 즉 점수를 reward로 사용해서 강화학습으로 Policy LM을 학습시킵니다. (Reinforcement Learning)
- 학습된 Policy LM이 만들어지고, 이를 Prompt의 힌트 부분을 만드는 작업에 활용합니다.
ReAct
ReAct는 모델이 추론 과정과 함께 행동을 지시하면서 답을 찾아갈 수 있도록 만드는 prompting 방식입니다. 설명만으로는 이해하기 힘드니 예시를 가져오겠습니다.

위 예시는 "Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with? (Apple Remote 외에 Apple Remote에서 가능한 상호작용 기능을 할 수 있는 다른 장치는 무엇입니까?)" 라는 질문에 대한 답변인데, 답은 "Keyboard function keys"이지만 이를 찾아가는 추론 과정을 추가했습니다. 추론 과정이라고 하면 CoT(Chain-of-Thought) prompting을 생각해볼 수 있지만, ReAct에서는 약간의 차이를 보입니다. 바로 Thought와 Action 과정을 추가한 것입니다. "~하기 때문에 이제 ~한 행동을 해야겠다"라고 생각하는 과정과, 생각을 통해 행동하는 과정을 단계적으로 수행하는 것입니다. 위 예시도 먼저 질문에 대한 생각을 하고, 무엇을 찾아볼지 고민을 한 다음 찾아보고, 그 결과를 분석해서 또 생각을 하고 행동을 하는 예시를 prompt에 추가시켰습니다. 즉 원인 분석과 행동을 하는 예시를 모델에게 주어 모델이 생각하고 행동하는 추론 과정을 거칠 수 있게 만드는 것입니다.
Multimodal CoT
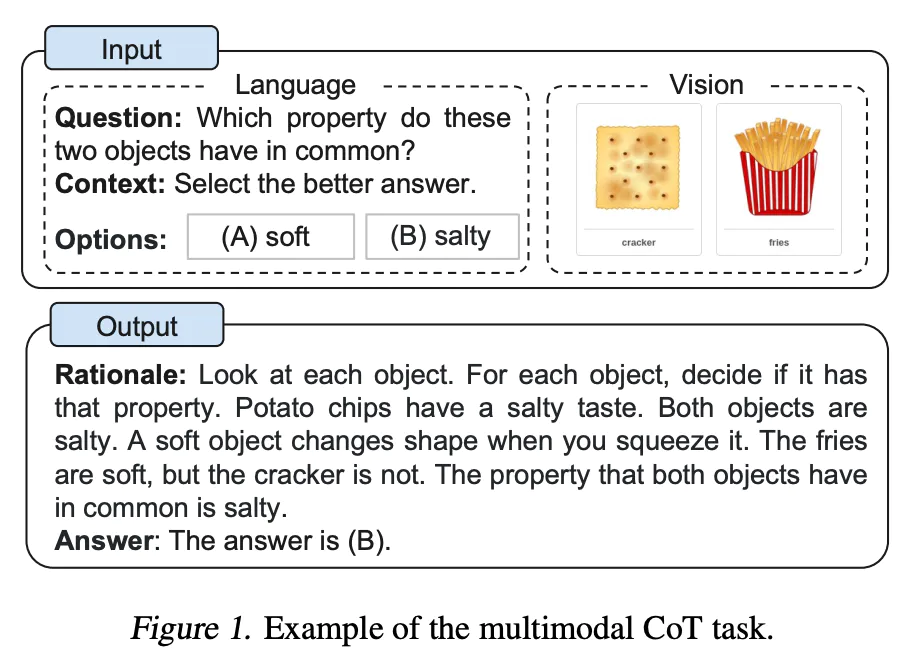
이름에서도 알 수 있듯이, multimodal이 가능한 CoT 방식입니다. 예시에서처럼 텍스트로 된 입력만을 주는 것이 아니라 이미지 정보도 같이 prompt로 제공합니다. 그 상황에서 Rationale이라는, 모델이 이미지를 분석하는 과정을 추가하고 그 과정을 통해서 답을 도출하게 합니다. 논문을 자세히 읽어본 것은 아니지만, 이미지 입력값도 받아들일 수 있어야 하기 때문에 multimodal CoT를 제안한 논문에서는 기존의 모델을 활용하는 것이 아니라 모델 자체를 직접 구성해서 학습시켰고, 적은 파라미터로 학습시켰음에도 기존의 GPT-3.5를 능가하는 성능을 가져왔다고 언급하고 있습니다. 이미지 입력이 가능한 GPT-4와 같이 이미지 입력이 가능한 모델에서 사용할 수 있는 prompting 방식이라고 볼 수 있습니다.
언급한 예시들은 모두 2022년 이후 논문에서 제안된 prompting 방식입니다. prompting 방식 자체는 여전히 계속 등장하고 있으며, 단순히 모델뿐만이 아닌 prompting 성능도 LLM을 활용할 때 평가 대상이 되고 있습니다. 직접 LLM을 만들기는 어렵지만, LLM을 활용하는 입장에서 prompting engineering은 성능이 좋은 LLM을 조금이라도 더 잘 이용하기 위해서 고민해볼 수 있는 부분이라고 생각됩니다.
