챗GPT 이후로 최근은 자연어처리의 리즈 시절이라고 불릴 수 있습니다. 이 리즈 시기에 라마, 알파카 등 온갖 동물 이름으로 지어진 귀여운 LLM(Large Language Model)들이 많이 만들어지고 있습니다. 여기에 고릴라라는 이름의 또 다른 귀여운(?) 모델이 올해 5월에 나왔다는 소식에 논문 리뷰를 살짝 진행해보고자 합니다. 살짝 스포 아닌 스포를 하자면 Gorilla가 무엇의 약자인지는 논문을 읽은 입장에서 찾지 못한 것을 보면 고릴라 단어 자체에 큰 뜻이 있는 것 같지는 않습니다.
Abstract & Introduction
Gorilla는 요약하자면 사용자의 요청에 대해 적절한 API를 던져주는 모델이라고 볼 수 있습니다. 사용자가 원하는 작업이 있을 때, 모든 작업을 하나의 모델이 처리하는 것은 멀티모달 모델을 통해 연구가 되고 있습니다. 하지만 그 모든 작업을 하나의 모델이 최고의 결과를 내면서 처리하는 것은 불가능에 가깝습니다. 따라서 사용자는 본인이 원하는 작업에 따라 적절한 모델을 호출해서 사용해야 합니다. 가령 자연어에 대해서는 GPT 계열의 모델을, 이미지에 대해서는 Diffusion 기반의 모델을 사용하는 식으로 말이죠. 이 때, 어떤 API가 이 작업에 대해 사용하기 제일 좋은 모델이다! 라는 것을 정의해주는 역할을 Gorilla가 해 주는 것이라고 보면 됩니다.

최근 GPT-4까지 등장한 상황에서 "GPT가 만능인데 그냥 GPT-4 쓰면 안 되는 건가요?"라고 의문을 가질 수도 있습니다. 하지만 LLM을 그대로 사용하는 것에는 한계가 몇 가지 있습니다. 첫째로는 아무리 거대한 LLM도 저장할 수 있는 정보량에는 한계가 있다는 점이고, 둘째로는 새로운 정보가 들어올 때마다 LLM을 재학습시키는 것은 불가능에 가깝다는 것입니다. 따라서 상황에 맞게 가장 좋은 모델을 호출할 수 있는 모델을 만드는 것이 오히려 더 유리할 수도 있으며, 이러한 관점에서 Gorilla가 등장했다고 볼 수 있습니다.
Related Work
ToolFormer
새로운 API, 즉 툴을 호출하는 모델이 Gorilla가 처음이었던 것은 아닙니다. 이미 LLM을 이용해 툴을 사용하는 방법론들이 꾸준히 제기되고 있고, 논문 상에서는 가장 최근의 모델로 ToolFormer와 GPT-4를 언급하고 있습니다. 즉 API를 호출하는 과정 자체를 툴을 사용하는 과정이라고 볼 수 있는데, Gorilla에서는 툴을 사용하는 성능 자체를 높이기보다는 툴을 쓰는 도구에 대한 평가 방식이나 파이프라인의 기준을 만드는 것에 집중한다고 언급하고 있습니다.
LLM을 프로그래밍에 사용하기
LLM을 이용해 코딩을 할 수 있다는 사실은 이미 널리 알려져 있습니다. 따라서 API 호출 도구에 불과하다고 여겨질 수 있는 Gorilla의 중요성에 의구심을 가질 수도 있습니다. 하지만 General한 코딩이 아니라 API 호출에 중점을 갖고 개발되었다는 점에서 Gorilla는 "코딩하는 모델"보다는 "적절한 툴을 찾아주는 모델"에 더 가깝다고 볼 수 있습니다.
Methodology
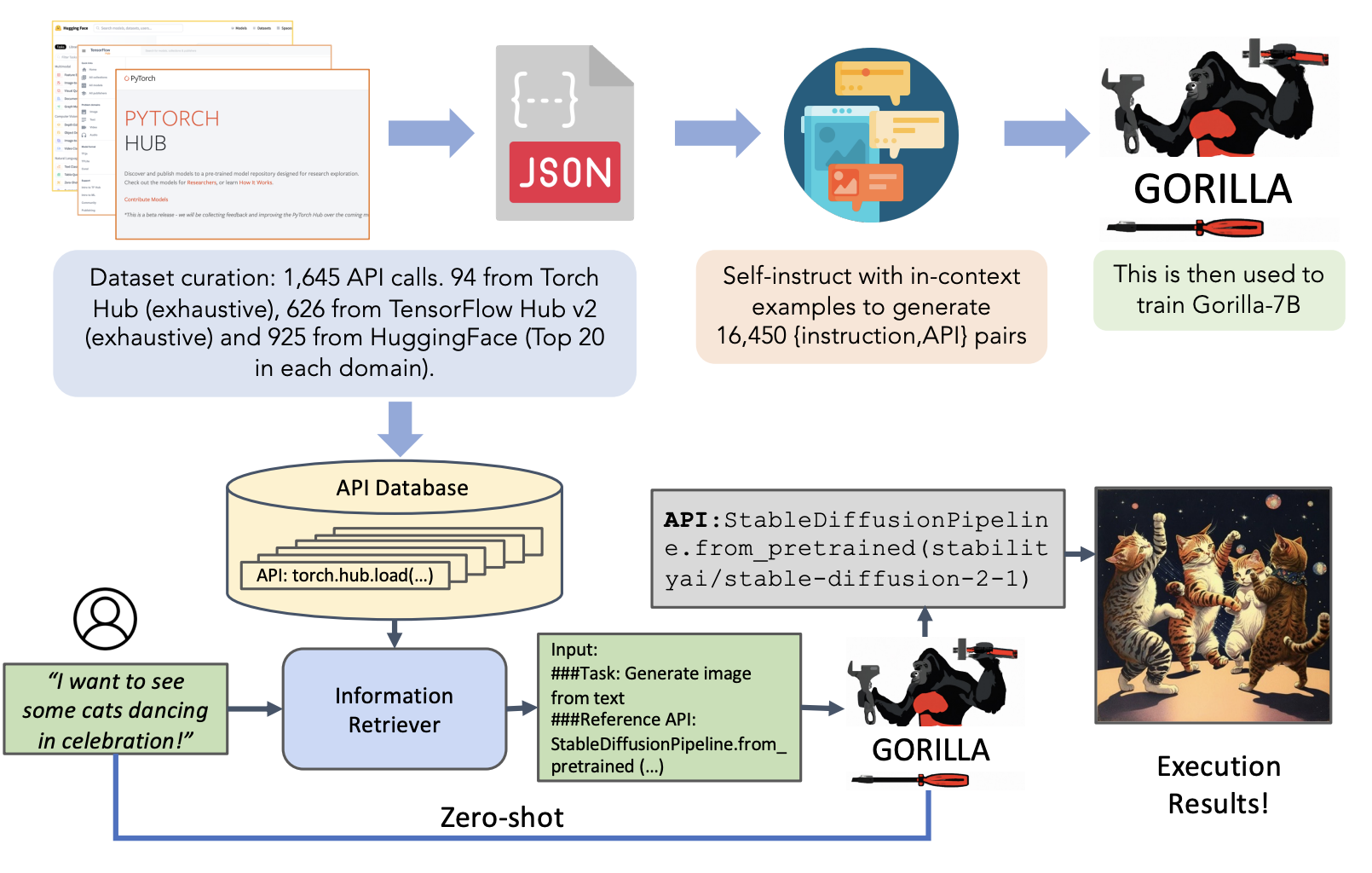
Gorilla의 데이터 및 학습 방식에 대해 언급하기 전, 미리 Gorilla 사용 방법을 크게 두 가지로 나누어 설명하고 넘어가겠습니다. 첫 번째는 Zero-shot으로, 말 그대로 사용자의 요청("나는 고양이가 춤추는 모습을 보고 싶어!")에 대해 가장 적절한 API를 선택해 주는 것입니다. 오히려 Zero-shot은 직관적으로 이해하기 쉬울 것입니다. 하지만 Gorilla에서는 두 번째 사용방법을 추가합니다. 사용자의 요청이 들어왔을 때, 바로 사용하지 않고 Information Retriever를 통해 가장 적절한 API 정보를 미리 수집하고, 사용자 요청과 Information Retriever를 통해 받은 API 정보를 바탕으로 API를 호출하는 코드를 짜는 것을 Gorilla가 하는 방법입니다. 즉 Zero-shot 방법에서 API에 대한 Information Retriever를 추가한 방법이라고 볼 수 있습니다.
Dataset Collection
Gorilla가 사용할 API 데이터는 총 세 곳에서 얻었다고 언급되고 있습니다.
-
HuggingFace's "The Model Hub"
HuggingFace의 경우 20만 개가 넘는 모델에 대한 호출 기록은 있으나, 대부분의 자료 자체가 품질이 많이 떨어진다고 합니다. 따라서 각 도메인마다 가장 괜찮은 모델 20개씩을 선별했고, 총 925개의 모델에 대한 API Document를 얻었다고 합니다.
-
PyTorch Hub
총 95개의 모델을 필터링 과정을 통해 선별해냈다고 합니다. -
TensorFlow Hub Models
최근 모델(v2)의 경우 801개의 모델을 가지고 있으며, 그 중 626개의 모델을 필터링해내어 사용했다고 합니다.
이렇게 수집한 1,651개의 API document를 바탕으로 json 형태의 model card를 만들었는데, 다음과 같은 필드명을 가진다고 합니다:
{domain, framework, functionality, api_name, api_call
, api_arguments, environment_requirements, example_code
, performance, description}API document를 바탕으로 사용자 요청에 대한 데이터도 필요한데, 이에 대해서는 GPT-4를 사용해서 사용자 요청 데이터를 생성해냈다고 언급되어 있습니다.
Gorilla
Gorilla는 LLaMA-7B 모델을 API 호출에 최적화되도록 fine-tuning하여 만들어진 모델입니다. {instruction, API} 쌍에 대해 학습이 된 모델이며, fine-tuning을 할 때 이를 대화형으로 바꾸는 작업을 합니다. 앞서 언급되었듯이 Gorilla는 retriever 없이 zero-shot으로 동작할 수 있도록 학습되기도, retriever와 함께 학습되기도 했습니다.
Gorilla를 학습할 때 고려되어야 할 점은 크게 두 가지입니다.
1. 특정 조건과 함께 API 호출하기
사용자가 API를 호출할 때는 특정 제약조건을 두기도 합니다. 이 제약조건은 파라미터가 될 수도, 성능이 될 수도 있는데, 가령 "10M 이하의 파라미터를 사용하면서 ImageNet에 대해서 정확도 70% 이상을 보장하는 이미지 분류 모델을 호출해줘"와 같이 구체적인 제약 조건이 있는 요청이 발생할 수도 있습니다. 즉 사용자의 요구사항과 함께 기능적인 제약조건까지 함께 고려해야 하는데, Gorilla와 같은 API 호출 모델은 일반적인 LLM이 그러하듯 단순히 사용자 요구사항만 고려해서는 대응할 수 없기 때문에 추가적인 fine-tuning이 필요합니다.
2. Retriever-Aware training
또한 Gorilla의 경우 Retriever가 존재하는 상태에서도 학습이 필요합니다. 사용자의 요청이 있을 때, 사용자 요청에 따라 Retriever는 API를 선택하며 Gorilla는 사용자 요청과 함께 "Use this API documentation for reference: <retrieved_API_doc_JSON>"이라는 문장을 같이 받아들이게 됩니다. 즉 Gorilla는 retriever로부터 온 문장을 분석해서 사용자의 요청에 응답할 수 있도록 학습됩니다. 이렇게 학습된 Gorilla는 세 가지 장점을 가지게 되는데, 첫째는 API document가 업데이트되어 새로운 API 정보가 들어오더라도 대응할 수 있다는 것이고, 두 번째는 문맥을 이해하는 능력이 향상된다는 점, 마지막으로 Gorilla가 출력하는 답변의 오류를 줄일 수 있다는 점입니다.
Gorilla를 추론 과정에 사용할 때, 두 가지 방법으로 입력을 줄 수 있습니다. Zero-shot 상황이라면 사용자의 요청만을 가지고 API 호출을 해야 하며, retriever가 존재하는 상황에서는 BM25나 GPT-Index와 같은 retriever가 있는 상황에서 먼저 API를 추려내고, 그 결과를 바탕으로 API 호출 결과를 주어야 합니다.
Verifying APIs
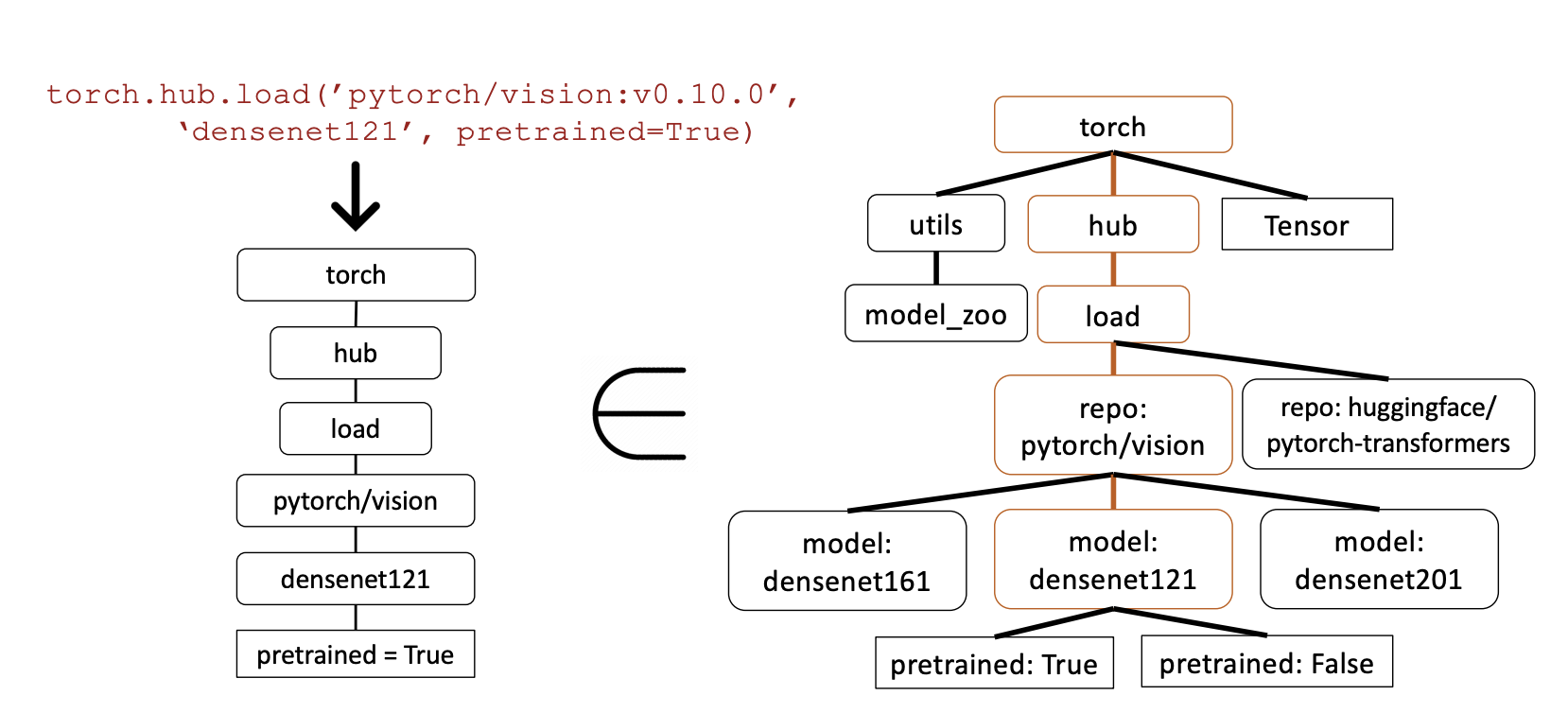
그렇다면 Gorilla가 만들어낸 호출이 과연 맞는지는 어떻게 평가할 수 있을까요? 논문에서는 AST Sub-Tree Matching 방식을 언급합니다. 간단하게 언급하자면, 사전에 API document로부터 모델을 호출하는 과정을 tree 형태로 구축해 둡니다. Gorilla가 특정 API를 호출하게 된다면, 호출에 사용된 파라미터 등을 모두 tree 형태로 만들어두고, 해당 tree가 전체 모델에 대한 tree의 subtree로 들어갈 수 있는지를 판단합니다. subtree가 될 수 있다면 API는 정확하게 호출된 것이고, 이를 통해 모델의 출력값에 대한 오류를 찾아냅니다.
Conclusion
사실 Evaluation에 대한 부분까지 자세히 적으려고 했으나, 추후에 글을 업데이트하도록 하겠습니다. Evaluation 결과를 간단하게 요약하자면, 좋은 retriever를 사용할 수 있는 상황이 아니라면 Zero-shot이 좋은 성능을 가져왔으며, 테스트 과정에서 API document가 변경되는 상황에서도 Gorilla는 다른 모델들보다 좋은 성능을 가져왔다는 것입니다.
사실 Gorilla에도 한계점이 있는 것은, 사용 방법 자체가 서로 유사한 ML API에서만 테스트가 진행되었다는 점입니다. 따라서 저자들은 보다 더 확장된 API 셋을 이용해서도 실험을 진행하고 있다고 밝혔습니다. 단순히 좋은 모델을 만드는 것보다도, 좋은 모델이 수없이 쏟아지는 상황에서는 "어떤" 모델을 사용할지도 고민이 될 수 있습니다. 이 상황에서 오히려 작은 API 호출 모델을 사용하는 쪽이 더 좋은 성능을 가져올 수도 있고, 이 또한 또 다른 경량화 방법이 아닐까 생각해보게 됩니다.
