LLM에게 "잘 물어보는 방법"을 연구하는 Prompt engineering 방법 중 대표적인 것이 CoT (Chain of Thought)입니다. 모델에게 "단계적으로 생각해보자"를 지시할 뿐인데도 바로 답을 내게 하는 것보다 좋은 성능을 가져오게 됩니다. 하지만 CoT는 상대적으로 큰 모델들에게 좋은 방식이지, 100B 이하의 작은 모델들에게는 그리 좋은 성과를 가져오지 못한다고 합니다. 따라서 이번에 리뷰할 논문에서는 CoT용 대용량 학습데이터를 별도로 만들어 small LM(Language Model)을 학습시키고, small LLM도 좋은 CoT 성능을 낼 수 있게 만드는 방법을 제안합니다.
Introduction
앞서 말했듯이, CoT를 이용한 prompting이 LLM output의 hallucination을 줄이고 성능을 높였다는 연구는 많으나, 대부분은 100B 이상의 큰 모델에 대해서였습니다. 작은 모델에서는 큰 모델에서만큼의 성능이 CoT를 통해 나오지 않았으며, rationale(CoT 추론 과정에서 사용되는 중간 단계의 정보들)을 작은 모델에 fine tuning시켜 특정 task들에서의 성능을 높이려는 시도는 있었으나 task에 한정적이었습니다. 특히 CoT를 위한 학습데이터도 그리 많지 않은 상황이었는데, 본 논문에서는 직접 CoT를 위한 학습데이터인 COT COLLECTION을 만들었음을 알리면서 COT COLLECTION을 만드는 방법을 제안합니다. COT COLLECTION은 1,060개의 task에 대해 1.84M 개의 rationale을 포함하는 새로운 대규모 Instruction dataset입니다. 이를 이용하여 Flan-T5라는 작은 모델을 fine tuning하여 CoT-T5을 만들었는데, 기존의 Flan-T5보다 CoT zero-shot, few-shot 성능을 올렸습니다. 즉 작은 모델에서의 CoT 성능을 높일 수 있는 데이터셋 구축 방법을 제안한 논문이라고 보면 될 것 같습니다.
Related Works
CoT Prompting
그럼 논문에서의 데이터셋을 보여주기에 앞서, CoT Prompting에 대해 좀 더 자세히 설명해보겠습니다. CoT란 Chain of Thought의 약자로, 모델에게 정답을 내기 전 rationale을 이용한 추론 과정을 거치도록 하는 방법입니다. 아래의 그림과 같이 수학 문제를 풀 때에도 바로 답을 내게 하는 방식보다 추론 과정을 거치도록 해서 더 정확한 답을 낼 수 있도록 만드는 것입니다. CoT는 few-shot으로는 추론을 하는 예시를 주는 방식이 있지만, zero-shot으로 하고 싶다면 "Let's think step by step"라는 문장 하나를 프롬프트에 추가하는 것만으로도 모델이 CoT를 하게 된다고 합니다.
계속 언급했듯이, 이 방식은 Large LM에서만 좋은 성능을 가져왔지 작은 모델에서는 효과가 그리 크지 않다는 것을 논문에서는 강조합니다.
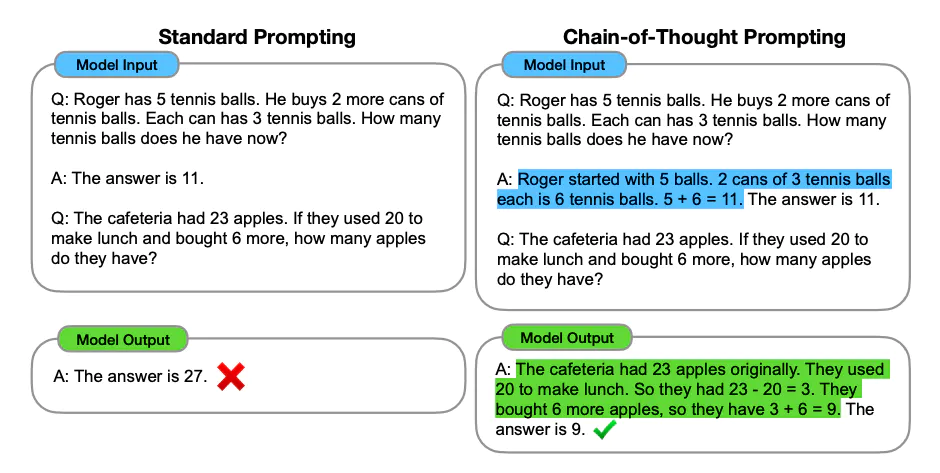
CoT Prompting에 대해서는 이전 글에서 소개한 적이 있으니 참고하셔도 좋을 듯합니다. (https://velog.io/@boyunj0226/GPT%ED%95%9C%ED%85%8C-%EC%9E%98-%EB%AC%BC%EC%96%B4%EB%B3%B4%EB%8A%94-%EB%B2%95-2-%EB%8B%A4%EC%96%91%ED%95%9C-Prompt-Engineering-%EB%B0%A9%EB%B2%95)
The COT COLLECTION
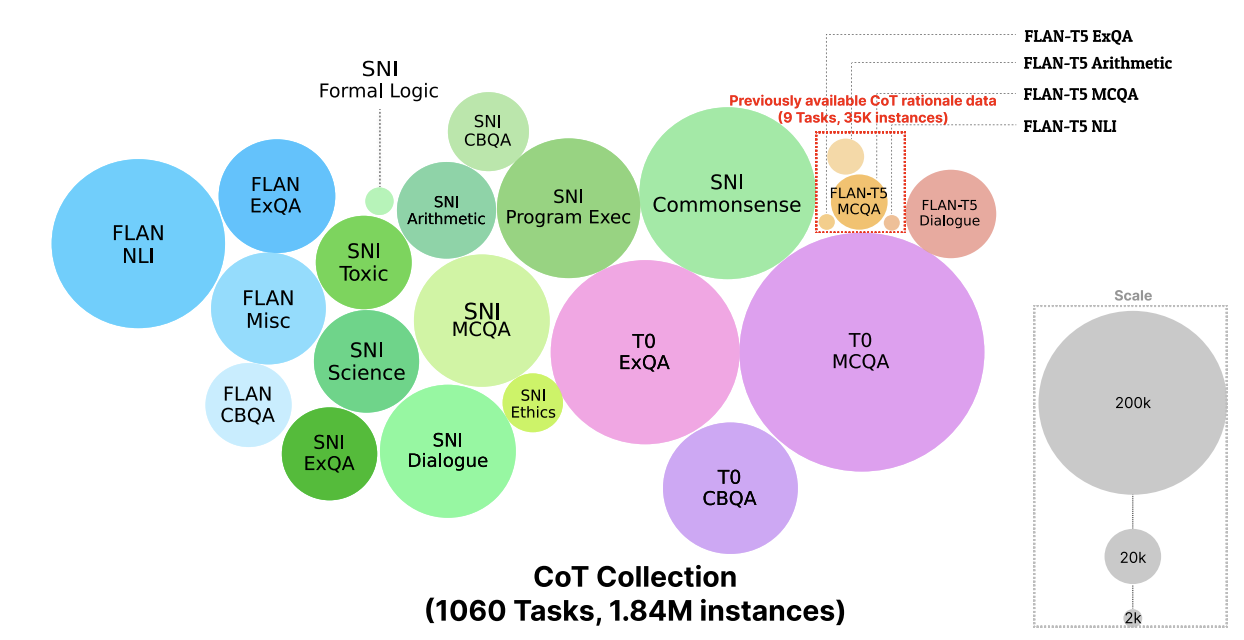
기존에 CoT를 위한 데이터가 존재하기는 했었는데, 많이 희박했다고 합니다. Task 수도 9개였고 양 자체도 많이 적었다고 합니다. 그래서 본 논문에서는 직접 대규모의 COT COLLECTION을 만든 과정을 소개합니다.
Source Data Selection
COT COLLECTION의 특징은 rationale을 포함하고 있다는 것이고, 이 rationale을 만들어내기 위한 sourse dataset이 필요합니다. Source dataset으로는 아래의 데이터로 구성된 Flan Collection으로부터 가져왔습니다.
- P3
- SuperNaturalInstructions
- Flan
- 기타 dialogue + code datasets
Source dataset들을 가지고 아래의 기준에 따라 총 1060개의 task를 선택합니다.
- 긴 output을 가지는 generation task는 제외 (학습 시 maximum output token length가 512인 것을 고려한 결과입니다.)
- 공개되지 않은 데이터는 제외 (DeepMind Coding Contest 등)
- 동일한 데이터가 여러 데이터셋에 있다면, P3 SNI Flan 순으로 선택
- 감성 분석과 같은 Task들은 rationale이 짧으면서 그리 큰 정보를 주지 못하기에 제외
Creating Demonstrations for ICL
LM에게 선택된 task를 rationale과 함께 풀어내도록 하기 위한, In-context learning(ICL)을 위한 프롬프트가 필요했습니다. 즉 rationale을 만드는 prompt를 위해 demonstration(지시문)이 필요했던 것이죠. 하지만 각각의 task에 대해 demonstration을 모두 만드는 것은 task가 많아질수록 더욱 어려운 일이 됩니다. 따라서 논문에서는 유사한 task들을 task family T로 묶고 demonstration을 생성하도록 했습니다. T 하나는 6~8개의 demonstration을 공유하게 되며, 각각의 demonstration은 세 명의 연구원분들께서 직접 제작했습니다. 최종적으로 26개의 demonstration이 만들어졌고, 이를 이용해 rationale 생성을 위한 prompt를 작성했습니다.
Rationale Augmentation
마지막으로 앞서 만든 데이터셋과, 직접 만든 demonstration을 이용한 Prompt를 통해 rationale을 생성했는데, OpenAI Codex을 이용했습니다. Rationale을 만드는 부분 직전에 answer 라벨을 제시해서 모델이 rationale 생성에만 집중하도록 했다고 합니다. 산술 추론과 같은 테스크에서 저품질의 rationale이 나오기도 했는데, 이를 해결하기 위해 filtering phase도 추가했습니다.

Experiments
Experiment setting
실험을 위한 base model로는 Flan-T5를 사용했습니다. 논문에서의 모델로는 Flan-T5를 COT COLLECTION으로 학습시킨 CoT-T5를 사용했습니다. 또한 CoT를 평가하는 것이 목적이기 때문에 Training과 Evaluation 과정에서 프롬프트에 "Let's think step by step" 문구를 추가했습니다.
Evaluation
평가는 크게 두 가지로 나뉘어집니다.
- Direct Evaluation
- Classification task에서는 accuracy를, Generation task에서는 EM score를 측정합니다.
- CoT Evaluation
- 우선, LM이 최소 8토큰 이상의 rationale을 생성하도록 제한시킨 상태에서 평가를 진행했습니다.
- classification task에서는 ANSWER라는 phrase 다음에 오는 것을 답으로 생각하고 accuracy를 측정했습니다.
- generation task에서는 indicator phrase 다음에 오는 것을 답으로 생각하고 EM score를 측정했습니다.
Zero-shot Generation
모델의 Zero-shot Generation 성능을 테스트하기 위해 총 3가지의 실험 세팅을 했습니다.
CoT Fine Tuning with 1060 CoT Tasks
첫 번째는 전체 COT COLLECTION에 있는 1060개의 task로 학습시켜서 BBH(BigBench Hard) 벤치마크로 평가한 결과입니다. COT COLLECTION으로 학습을 시킨 CoT-T5의 성능이 더 우세하다는 것을 알 수 있습니다.

Task별로 나누어서 성능평가 결과를 보았을 때에도 다수의 Task에서 CoT-T5가 성능이 우세했다는 것을 알 수 있습니다.
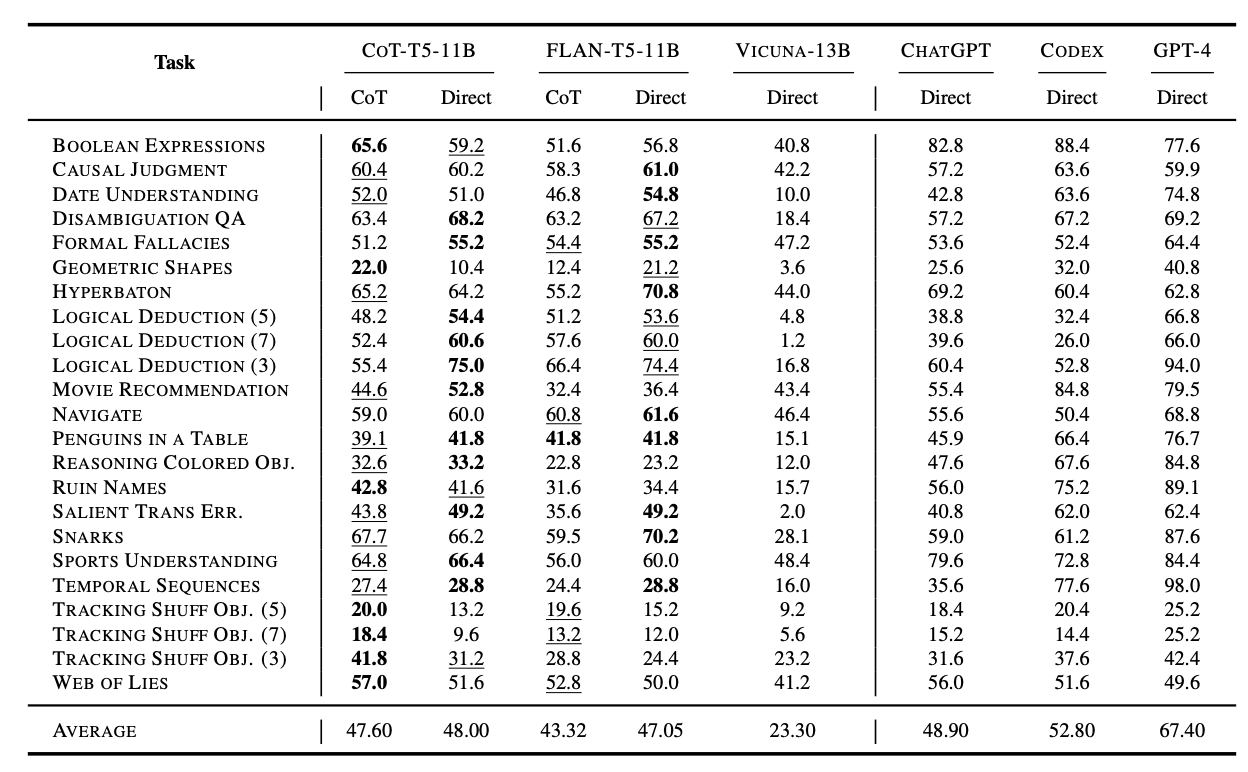
CoT Fine-tuning with 163 CoT Tasks
하지만 의문을 가질 수 있는 것은, COT COLLECTION은 어찌 되었든 대용량 데이터이고, 대량의 자연어로 학습시켰기 때문에 성능이 좋은 것이 아니냐는 의문점을 제기할 수도 있습니다. 따라서 논문에서는 CoT fine-tuning이 큰 수의 task와 instance에 의존적인지 확인하기 위해 데이터의 일부(P3로부터 얻은 데이터)만 사용해서 fine tuning한 모델도 비교합니다. P3 데이터를 이용했기 때문에 평가는 P3 evaluation benchmark를 사용했는데, 적은 수의 데이터를 사용해서 학습시키더라도 성능 향상은 가져왔음을 볼 수 있습니다.

Multilingual Adaptation with CoT Fine-tuning
Flan-T5 자체가 다국어 모델은 아닌 만큼, 논문에서도 토이프로젝트 형태로 테스트를 해본 것이 Multilingual 상황에서의 효과입니다. 그런 만큼 기존 모델을 보면 데이터가 상대적으로 적은 한국어, 일본어, 중국어 데이터에서는 성능 자체가 전혀 나오지 못했습니다. 하지만 CoT-T5의 경우 그래도 조금이라도 성능이 올랐는데, 여전히 적은 수치이지만 함부로 무시할 수는 없는 결과를 가져왔습니다.
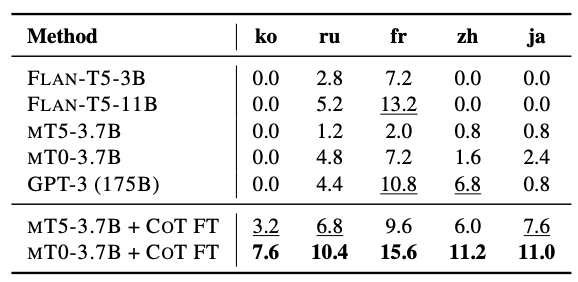
Few-shot Generation
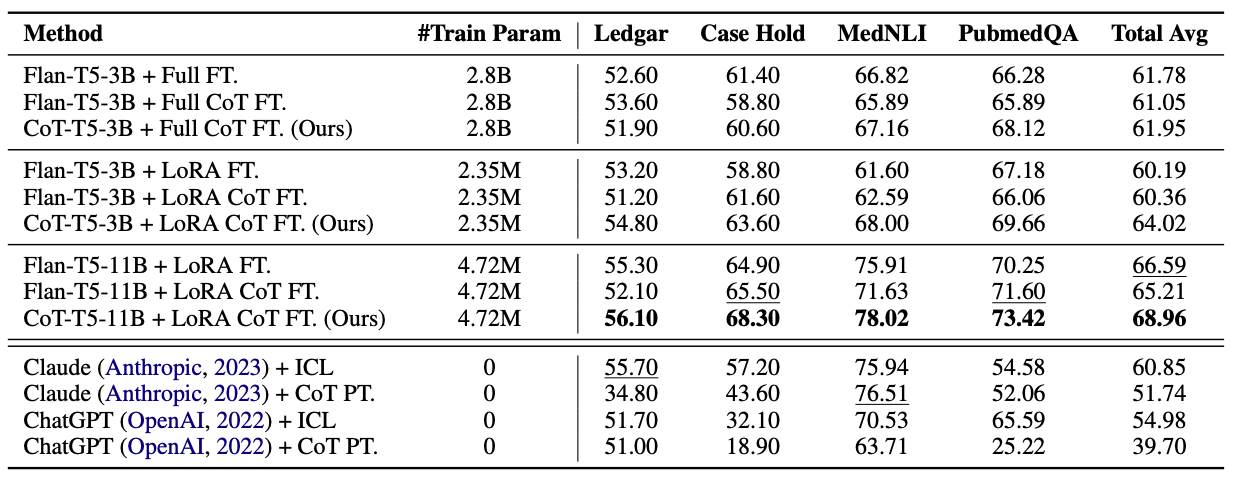
다음으로는 Target task에 대해 제한된 수의 Instance만 사용할 수 있는 경우에 대해 평가했다고 합니다. 이 부분은 제가 정확히 이해한 것은 아니지만, LoRA로 COT COLLECTION을 적용해 학습시켰을 때를 평가한 것으로 해석했습니다. 데이터셋은 legal, medical domain으로부터 온 데이터셋 4가지를 사용했습니다 (LEDGAR, Case Hold, MedNLI, PubMedQA).
Analysis of CoT Fine-tuning
추가적인 실험을 진행했는데, 모델의 성능을 평가하는 관점보다는 2가지의 research question의 답을 내기 위한 experiment로 보면 됩니다.
- 다양한 task를 위한 rationale 생성이 유용할지, instance가 많은 게 더 유용할지
- CoT 과정에서 catastrophic forgetting 없이 LM이 성능을 유지할 수 있는지
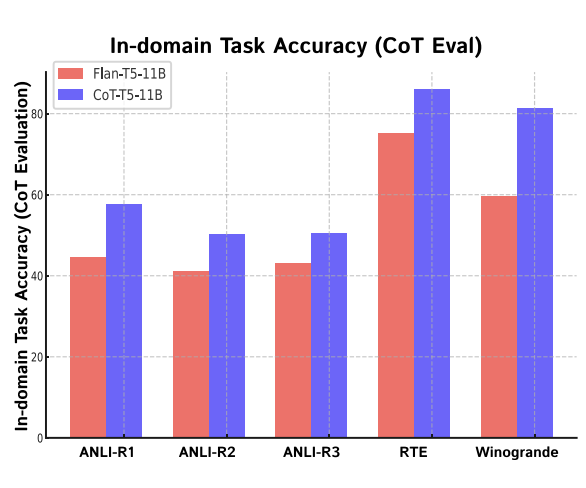
먼저, rationale 생성 과정에서 Task의 수가 중요할지 Instance의 수가 중요할지 확인해보았을 때, 압도적으로 Instance 수보다 Task 수가 중요했다고 합니다.

또한 CoT-T5가 in-domain accuracy를 높였으나, 이는 학습과 평가에서 동일한 task를 사용했기 때문으로 추정된다고 합니다.
Conclusion & Limitation
논문은 rationale을 활용한 instruction tuning data가 CoT 성능을 올릴 수 있음을 증명했습니다. 특히, COT COLLECTION이라는 추가적인 대용량 학습 데이터를 생성해냈습니다.
하지만 논문에서 언급한 한계점들은 아래와 같습니다.
- output의 길이를 제한시킨 학습데이터를 사용한 만큼 dialogue with long-form output에 대해서는 효과가 적었다고 합니다.
- CoT-T5는 multilingual로 학습되지 않은 Flan-T5으로부터 만들어졌기에 다양한 언어에 적용시키기 어렵다는 한계가 있습니다.
- 비록 small LM의 성능을 올린 것은 맞으나, 여전히 large LM에 비해서는 한계를 보였습니다.
- rationale 생성 시 Codex을 사용했는데, 다른 LLM을 사용해 데이터를 생성하는 것도 확인해봐야 한다고 했습니다.
