NLP task들은 다량의 라벨링된 데이터가 필요한 경우가 많습니다. 보통은 사람이 직접 라벨링을 하거나, Heuristic한 방법으로 라벨링을 진행하는 경우가 많은데, 만일 이 작업을 GPT로 할 수 있다면 어떨까요? 이번에 리뷰할 논문은 라벨링 작업을 위해 GPT-3를 사용했을 때, 성능이 생각보다 괜찮았음을 보여줍니다.
Introduction
NLP task들은 다량의 라벨링된 데이터로 지도학습되는 경우가 많습니다. 따라서 대부분의 경우 충분한 양의 정확하게 라벨링된 데이터가 필요합니다. 그러나 데이터를 라벨링하는 Data annotation 작업은 노동력, 시간, 비용이 굉장히 많이 들어가며, 그런 만큼 개인이나 작은 규모의 기관에서는 진행 자체가 불가능한 수준입니다.
GPT-3는 zero-shot으로도 사용이 가능한 모델이기 때문에 모든 task들을 GPT로 사용하면 되지 않을까 라고 생각할수도 있습니다. 하지만 GPT를 직접 inference에 사용하기에는 모델 사이즈가 커서 어려우며, 파라미터도 공개되어있지 않기 때문에 자유롭게 사용하기는 어렵습니다. 따라서 산업체에서는 BERT BASE와 같은 작은 Language model을 사용하는 것이 더 이득인 경우가 많습니다.
본 논문에서는 BERT와 같은 작은 ML 모델에 사용될 데이터 annotation에 GPT를 사용하는 방법을 제안합니다. GPT-3가 가지고 있는 지식을 작은 모델로 distilling한다고 볼 수 있습니다.
Methodology
본 논문에서는 3가지 data annotation 방법을 제안합니다. Tagging based 방식인 PGDA와, Generation based 방식인 PGDG와 DADG로 나눠서 설명을 하며, 이 둘의 차이는 라벨을 생성하는지, 라벨의 대상이 되는 문장을 생성하는지의 차이라고 볼 수 있습니다.
PGDA (Prompt-Guided Unlabeled Data Annotation)
PGDA는 GPT를 이용해 라벨링을 한다고 할 때, 흔히 생각할 수 있는 방식입니다. 먼저 프롬프트는 지시문과 함께 예시 N개를 주고, 라벨링이 되지 않은 문장을 보고 라벨링을 하도록 구성되어 있습니다. 즉 예시를 몇 가지 주고 few-shot으로 라벨링시키는 방법입니다.

PGDG (Prompt-Guided Training Data Generation)
PGDG는 PGDA와 반대의 결과를 생성하는 라벨링 방식이라고 볼 수 있습니다. 라벨이 주어진 상태에서 entity를 생성하고, 생성된 entity를 기반으로 문장을 생성하도록 하는 방법입니다.
예를 들어 문장을 보고 문장에 나온 두 entity 사이의 relation을 찾는 task가 있다고 가정합니다. 여기서의 라벨은 relation이 될 것입니다. PGDG에서는 먼저 relation을 보고 relation에 맞는 두 entity를 생성하도록 합니다. 즉 첫 번째 프롬프트는 relation과 relation에 대한 설명, 그리고 entity 예시들이 될 것입니다. 이 상태에서 GPT에게 head entity와 tail entity를 생성하도록 합니다.

두 번째 프롬프트에서는 이렇게 생성된 entity들을 보고 문장을 생성하도록 합니다.

여기서 생성된 문장과 relation (라벨)을 데이터로 사용하는 방식입니다.
DADG (Dictionary-Assisted Training Data Generation)
DADG는 PGDG와 유사한 라벨링 방식입니다. 차이가 있다면, PGDG는 entity를 GPT-3가 생성하도록 시켰다면, DADG는 query를 던져서 dictionary에서 찾는 방식입니다. 논문에서는 dictionary로 Wikidata를 사용합니다 (https://www.wikidata.org). DADG는 GPT를 학습시킨 pre-trained corpus에 도메인 정보가 없을 때 유리한 방식이라고 볼 수 있습니다.
Experiments
논문이 나온 시점에도 이미 ChatGPT가 등장했을 텐데 논문에서는 GPT-3를 사용합니다. 그리고 논문은 모델을 학습시킬 데이터 생성이 목적이기 때문에, 학습시킬 모델로는 BERT BASE를 이용하며 성능도 학습된 BERT BASE의 성능을 기준으로 평가합니다.
평가는 총 4가지 NLP task에 대해서 진행했는데, Sequence-Level task (Sentiment Analysis, Relation Extraction)과 Token-Level task (NER, ASTE)를 대상으로 평가합니다.
Sequence-Level Task
Sequence-level task에서는 문장 단위의 task를 진행합니다. 즉 문장을 보고 라벨링을 하는 task를 진행하는데, 두 가지를 진행합니다.
Sentiment Analysis
첫 번째로는 감성분석 과제이며, 논문에서는 SST2라는 영화 리뷰 데이터셋을 사용합니다. 라벨링은 각각의 방식에서 아래와 같이 진행합니다.
- PGDA: SST2에 있는 train data 중 랜덤하게 10개를 샘플링하여 10-shot으로 학습합니다.
- PGDG: 마찬가지로 SST2에 있는 10개 데이터를 샘플링하여 특정 sentiment에 대한 문장을 생성할 수 있는 예시로 줍니다.
- DADG: Wikidata의 movie domain에서 entity를 가져온 후 SST2 10개 데이터를 예시로 준 상태에서 문장을 생성하도록 합니다.
결론적으로는 PGDA가 SOTA 달성했고, 나머지 Generation based 방식들의 성능은 좋지 못했습니다. 감성분석에서는 문장 내의 각각의 entity보다는 문장 전체의 맥락이 중요한 요소인 만큼 entity에 집중하는 Generation based 방식의 성능이 좋지 못했을 것이라고 논문은 추정합니다. 특히 DADG는 data distribution 자체가 달라서 더 성능이 떨어졌다고 합니다.

Relation Extraction
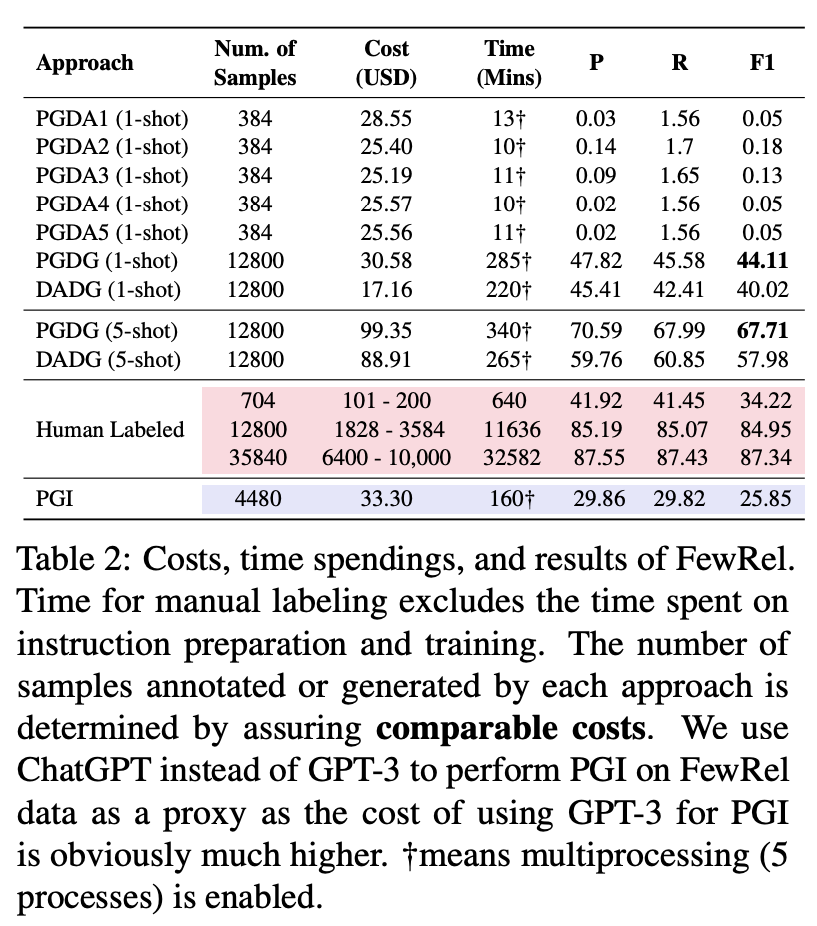
앞서 PGDG 방식을 설명할 때 예시로 들었던 task로, 문장 내 entity들의 relation을 찾는 과제입니다. 감성분석의 경우 label space가 많아야 3가지(긍정, 부정, 중립)로 상당히 적은 편입니다. 이 과제는 label space가 넓을 때의 GPT-3의 annotation 능력을 테스트하기 위함이라고 볼 수 있으며, 64개의 relation이 있는 FewRel 데이터셋을 사용합니다. 라벨링 방식은 아래와 같습니다.
- PGDA: 64개의 relation을 이용하기엔 prompt 길이 제한이 있습니다. 따라서 논문에서는 임의로 5가지 prompt를 만들어서 테스트해보고 제일 좋은 것을 찾아서 사용했습니다.
- PGDG: 각각의 relation에 대해 head-tail entity pair를 만들도록 하고 (relation 하나당 200개씩), relation, head entity, tail entity 정보를 이용해 문장을 생성합니다.
- DADG: 위에서 head-entity pair 만드는 과정을 Wikidata에서 query하는 방식으로 가져오고, entity와 relation을 이용해 문장을 생성하도록 했습니다.
label space가 너무 크다 보니 예상대로 PGDA는 그리 좋은 성능이 나오지 못했습니다. 대신 entity의 중요성이 큰 task인 만큼 PGDG와 DADG는 좋은 성능이 나왔으며, 그래도 예시를 더 준 5-shot이 1-shot보다는 성능이 더 좋았다고 합니다. 또한 human labeling과 비교했을 때, 비용 측면에서 훨씬 우위에 있었다고 합니다. 즉 동일한 비용을 사용한다는 가정 하에서는 성능이 더 좋았습니다. (물론 비용을 많이 준다면 human labeling이 우위였습니다) 추가로 특정 relation(religion, language)에 대해서는 pretrained data의 영향 때문인지 PGDG의 성능이 DADG보다 우위였다고 합니다.
Token-Level Task
두 번째로는 토큰 단위의 task, 즉 각각의 토큰에 대한 라벨링이 필요한 작업들을 두 가지 테스트했습니다.
NER (Named Entity Recognition)
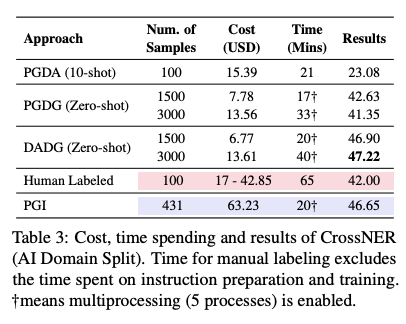
대표적인 entity labeling task인 NER을 진행했고, 데이터셋으로는 총 14개의 entity가 있는 CrossNER을 사용했습니다. 라벨링은 아래와 같이 진행했습니다.
- PGDA: entity를 찾고, 그 entity의 유형이 무엇인지 찾는 방식으로 prompt를 구성했습니다.
- PGDG: 각 entity type마다 entity를 생성하고, entity를 이용해 문장을 생성했습니다.
- DADG: 각 entity type마다 query해서 entity를 찾고, entity를 이용해 문장을 생성했습니다.
결론적으로 PGDA는 좋은 성능을 얻지도 못했고, cost도 human labeling보다 엄청 적지도 않았습니다. 원인을 생각해보자면 일단 GPT가 entity 자체를 잘못 판단하는 경우도 많고, entity로 지정할 토큰 범위도 제대로 못 찾는 경우도 많았다고 합니다. 대신 나머지 PGDG와 DADG는 성능이 좋았고, Wikidata로부터 더 다양한 in-domain entity를 가져올 수 있는 DADG가 더 성능이 좋았다고 합니다.
ASTE (Aspect Sentiment Triplet Extraction)
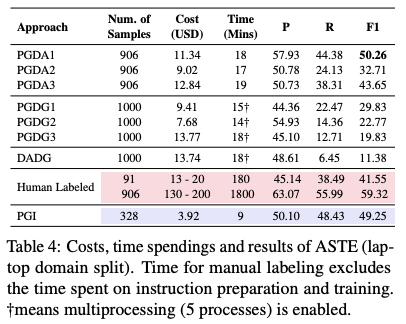
ASTE는 aspect, opinion, sentiment triplet(positive, negative, neutral) 세 가지를 모두 구분해야 하는 task입니다. 예를 들어 "배우들의 연기력은 정말 좋았는데, 연출이 꽝이었다"라는 문장이 있다면, 여기서 {배우들의 연기력, 정말 좋았다, 긍정}, {연출, 꽝, 부정} 두 가지 triplet을 찾아내는 task입니다. 라벨링은 아래와 같이 진행했습니다.
- PGDA: gold train data로부터 랜덤하게 10개를 가져오고, 이들을 예시로 10-shot prompt를 구성해서 사용합니다. 최적의 prompt를 찾기 위해 총 3가지 종류의 prompt를 사용해 테스트를 진행했다고 합니다.
- PGDG: PGDA에서 사용한 10개 예시를 이용했는데, aspect-opinion-sentiment triplet을 먼저 생성하고, triplet을 이용해 문장을 생성하도록 했습니다.
- DADG: laptop, computer hardware domain에서 query해서 entity를 찾아 aspect로 사용하고, aspect로부터 opinion과 sentiment를 생성하도록 한 뒤 이들을 이용한 triplet으로 문장을 생성하도록 했습니다.
ASTE의 경우엔 PGDA의 성능이 좋으며, 어떤 prompt를 사용하는지에 따라 성능 차이가 발생했다고 합니다. 마찬가지로 문장을 생성하는 entity가 sentiment analysis에 중요한 요소는 아닌 만큼 PGDG와 DADG의 성능은 낮았다고 합니다. 앞선 감성분석 task와 비슷한 결과가 나왔다고 볼 수 있습니다.
Further Analysis
논문에서는 추가적인 분석을 진행했고 그 결과를 보여주었습니다. "최적의 라벨링 상황"을 찾아보려고 했다고 생각됩니다.
Impact of Label Space
Label Space가 적을 때는 (감성분석처럼 라벨이 두세가지 정도) tagging-based approach(PGDA)의 성능이 더 좋았으나, Label Space가 커질수록 prompt 길이가 길어지면서 catastrophic forgetting을 유발하고 annotation cost가 커지기 때문에 generation-based approach(PGDG, DADG)가 더 좋았다고 합니다.
Comparison with Human Annotators
human annotator의 단점은 명확합니다. domain-specific data annotation을 위해 사람들을 교육시켜야 하며, annotation 속도는 기계(GPT-3)를 따라잡을 수가 없습니다. 또한 labeling space가 클수록 사람도 라벨링에 어려움을 겪습니다. 그 외에도 비용 등 다양한 단점들이 있는데, 이 모든 것을 해결하는 방법이 GPT-3를 이용한 annotation이라고 볼 수 있습니다.
그 외에도 여러 가지 테스트를 진행했는데, 몇 가지만 보여주자면 아래와 같습니다.
-
Tagging approach(PGDA)에는 예시를 늘릴수록 좋은 성능이 나오지만, 나머지의 경우는 크게 중요하지 않았습니다.
-
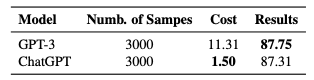
GPT-3와 ChatGPT를 비교해 보면 성능차이가 의외로 크지 않았다고 합니다. 대신 ChatGPT를 사용했을 때 비용이 더 저렴했다고 합니다.
(그럴 거면 실험은 왜 GPT-3로 했는지는 의문이긴 하네요...)
-
다양한 언어에 대해서도 테스트를 했는데, target language에 대한 사전정보가 부족하더라도 어느 정도 효율적으로 annotation을 진행했다고 합니다. 논문에서는 중국어와 프랑스어로 라벨링한 결과 예시를 보여주었는데, 개인적으로는 두 언어 모두 데이터가 충분한 언어이기 때문에 괜찮은 성능이 나온 것이 아닌가 싶기도 합니다.
Conclusion
GPT-3는 상대적으로 적은 cost를 이용해 어느 정도 괜찮은 annotation 성능을 보여주었습니다. 하지만 분명한 한계점들이 존재합니다.
- 논문에서는 비용 문제로 인해 모든 라벨링 테스트를 진행해보지는 못했다고 합니다.
- GPT-3 기반 라벨링이 비용을 절감한 것은 맞으나, 절대적인 성능 자체가 아직 완벽한 수준은 아니었으며 개선점이 여전히 존재했습니다.
- GPT-3 자체가 black-box 시스템이기 때문에 결과를 해석할 수 없다는 단점이 있습니다.
- 어느 정도 bias를 가지고 있는 데이터로 사전학습된 모델이기 때문에 annotation 시에도 bias가 존재하며, 이를 해결할 방법이 필요합니다.
그럼에도 다량의 데이터를 라벨링하는 것에 대한 현실적인 이슈는 언제나 존재하기 때문에, GPT를 이용한 데이터 생성 능력을 조금씩 더 보완하다보면 데이터로 인한 불평등은 어느 정도 해소할 수 있지 않을까 싶었습니다. 특히 개인적인 연구나 작은 기관에서 테스트해보기에는 괜찮은 방법론을 제안한 논문이라고 보여집니다.
