논문 출처: https://arxiv.org/pdf/2303.17580.pdf
데모 출처: https://huggingface.co/spaces/microsoft/HuggingGPT
LLM(Large Language Model)을 포함한 성능이 너무나 좋은 모델들은 끊임없이 쏟아지고 있습니다. 이 상황에서 오히려 모델 자체의 성능을 높이기보다는, 모델을 다른 도구를 사용하는 툴로 사용하자는 아이디어도 제시되고 있습니다. 대표적으로는 Toolformer가 있을 것입니다.
Toolformer: https://arxiv.org/abs/2302.04761
논문 제목에서 이미 유추가 되겠지만, Hugging Face에 있는 모델들을 "도구"로 사용하자는 논문이 나왔습니다. 이름부터 HuggingGPT인데, 아이디어 자체를 설명한다는 관점에서 논문리뷰를 해볼까 합니다.
Introduction
워낙 날이 갈수록 성능은 높아지고 있는 LLM이지만, 본질적으로 LLM은 다음과 같은 한계를 가지고 있습니다.
- 입출력이 텍스트로 한정되어 있기 때문에 멀티모달 환경에 적용하기 어렵습니다. (ChatGPT 기준으로)
- 실생활에는 단일 Task가 아닌 여러 개의 sub-task를 요구하는 작업들이 있고, 여러 개의 모델을 스케줄링하고 사용해야 하는 경우도 있습니다.
- LLM의 zero-shot, few-shot 성능이 좋다고는 하지만, 여전히 일부 fine-tuned model보다 성능이 약한 경우가 많습니다.
이를 해결하고자 하는 관점에서 논문은 HuggingGPT를 가져옵니다. AI 모델들은 모두 언어로 설명될 수 있습니다. 그러므로 LLM을 AI 모델을 관리하는 도구로 사용하자는 아이디어로 HuggingGPT가 제안됩니다. 여기서 AI task를 수행하기 위해 모델을 사용하기 위해서는 우선 그 모델에 대한 좋은 품질의 설명(description)이 필요한데, 이를 위해 공식 ML 커뮤니티, 그 중에서도 유명한 Hugging Face를 사용합니다. 즉 HuggingGPT는 공식 ML 커뮤니티인 Hugging Face와 품질 좋은 LLM인 ChatGPT를 연결시킨 AI 모델 관리용 툴이라고 볼 수 있습니다.
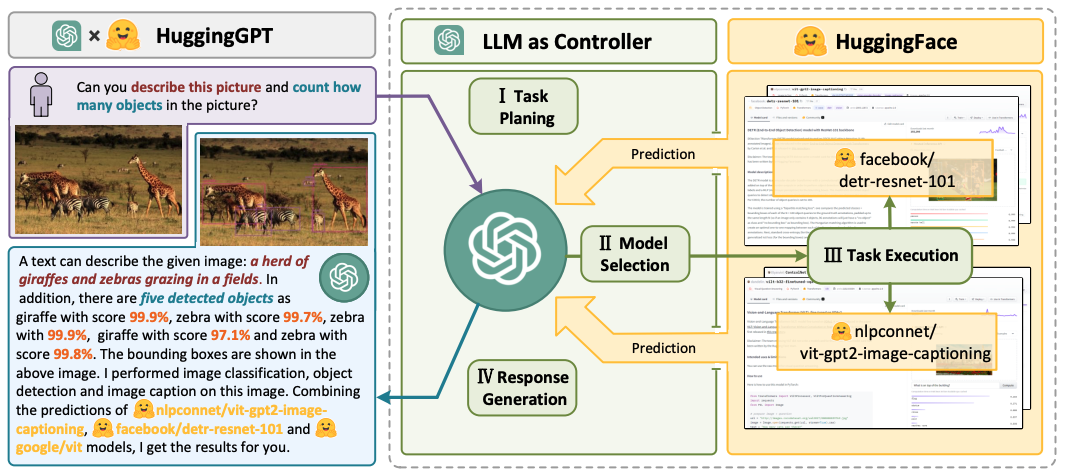
HuggingGPT는 아래의 네 가지 스테이지를 거쳐 사용자의 요청에 응답합니다.
- Task Planning: 사용자의 요청사항을 이해하고 어떤 테스크가 필요할지 정의하는 단계입니다.
- Model Selection: Hugging Face의 model description을 바탕으로 앞서 정의한 테스크 각각에 가장 적합한 모델을 선택합니다.
- Task Execution: 각각의 모델들을 실행하고 ChatGPT에게 결과를 전달합니다.
- Response Generation: 수집된 결과들을 바탕으로 사용자에게 제공할 응답을 만듭니다.

그림을 보면서 설명을 하자면, 먼저 사용자 요청을 분석해서 ChatGPT를 이용해 Task Planning을 진행합니다. 사용자의 요청이 "여자아이가 책을 읽는 이미지를 생성해줘, 근데 example.jpg에 있는 남자아이의 포즈와 비슷하게 해줘. 그리고 새로 만든 이미지를 너의 목소리로 설명해줘"입니다. 여기서 나올 수 있는 테스크는 총 6단계로, pose detection -> pose-to-image -> image-class -> opject-detection -> image-to-text -> text-to-speech 이며, task를 정의하는 단계까지 1단계에서 진행합니다.
두 번째 단계에서도 ChatGPT를 사용해서 각각의 task에 가장 적합할 모델을 Hugging Face model description을 보고 선택합니다. Object detection 단계에서는 facebook/detr-resnet-101을 선택하는 식으로 말이죠. 그 다음 세 번째 단계에서 모델을 실행하고, 그 결과를 다시 ChatGPT에게 전달해서 사용자 응답을 만드는 과정이 네 번째 단계가 됩니다.
논문의 Contribution은 다음과 같습니다.
- LLM과 Expert model의 장점을 모두 보완했습니다.
- multiple modality와 도메인을 커버하는 AI 테스크를 수행할 수 있음을 보였습니다.
- task planning에 대한 평가를 진행하였습니다.
- 실험을 통해 복잡한 테스크도 수행할 수 있다는 것을 증명했습니다.
그럼 앞서 언급한 HuggingGPT의 네 가지 단계를 자세히 살펴보도록 하겠습니다.
HuggingGPT
Task Planning
사용자 요청에 따라 테스크를 정의하는 단계로, 각각의 테스크는 순서와 dependency(테스크 간 선후관계)를 가져야 합니다. 이를 위해 HuggingGPT는 ChatGPT를 이용해 아래의 두 가지 요소로 구성된 prompt designing을 진행합니다.
- Specification-based instruction: 테스크를 설명할 때 지정된 포맷(json)을 사용하도록 합니다. "task", "id", "dep", "args"로 구성되는데, 여기서 "dep"은 이전에 수행되어야 할 테스크의 id를 의미합니다.
- Demonstration-based parsing: 테스크를 설명하는 demonstration을 추가합니다. 이를 통해 모델이 테스크 간 연관관계를 보다 잘 이해할 수 있게 만들어줍니다. 추가로 아래와 같은 문구를 추가해서 ChatGPT가 채팅 로그를 확인하고 사용자 요청을 멀티턴으로 받아들일 수 있게 합니다.
"To assist with task planning, the chat history is available as {{ Chat Logs }}, where you can trace the user-mentioned resources and incorporate them into the task planning stage"
Model Selection
각각의 테스크 리스트에 맞는 모델을 선택하는 단계입니다. Hugging Face로부터 model description을 수집하고, In-context task-model assignment mechanism에 따라 모델을 선택합니다.
여기서 In-context task-model assignment mechanism을 설명하자면 다음과 같습니다. ChatGPT의 prompt에 모든 모델 정보를 넣을 수 있다면 좋겠지만, 입력 토큰의 수는 한계가 있습니다. 따라서 먼저 테스크에 맞는 모델을 필터링하고, Hugging Face 내에서의 다운로드 수를 기준으로 정렬한 다음, 후보 모델을 top-K개만큼 추려내는 과정을 의미합니다. 개인적인 의견으로는 최신 모델일수록 당연히 다운로드 수가 적은 만큼 추후에 top-K를 고르는 방식 자체는 변경될 것 같다고 생각됩니다.

Task Execution
선택된 모델에 대한 Inference를 진행하는 단계입니다. 이 때 resource dependency를 관리하는 것이 필요하기 때문에 <resource>라는 표시를 통해 이전 단계의 테스크에 대한 resource dependency를 명시합니다. 없을 경우 병렬로 모델을 실행해서 효율성을 높이게 됩니다.
Response Generation
최종 응답을 만드는 단계로, 앞선 단계로부터 얻은 결과들을 합쳐 요약하고, 사용자가 이해할 만한 언어로 바꾸는 작업을 합니다.

Experiments
사실 HuggingGPT를 평가할 만한 지표가 당장은 없기 때문에 논문의 저자들은 다양한 시행착오를 통해 대략적으로라도 모델을 평가하고자 했습니다. 그렇기 때문에 정성평가도 함께 진행되며, contribution에도 언급된 정량평가 방식도 이 논문에서 새롭게 고안해냈습니다.
Qualitative Results
논문의 Appendix를 통해 보다 더 자세히 설명하기는 했으나, 요약을 하자면 다양한 테스크(NER, object detection, video generation)에 대해서, 그리고 복잡한 테스크(multiple implicit task), 그 외에도 다양한 시나리오에 대해 정성평가를 진행했다고 합니다. 그 결과 HuggingGPT가 테스크를 순서와 dependency에 맞게 적절하게 구성한다는 것을 확인했다고 합니다.
Quantitative Evaluation
정량평가는 오로지 1단계인 Task planning에 대해서만 진행했다고 합니다. Task 자체를 Single task, Sequential task, Graph task로 나누고 각각에 대해 평가를 진행합니다.
-
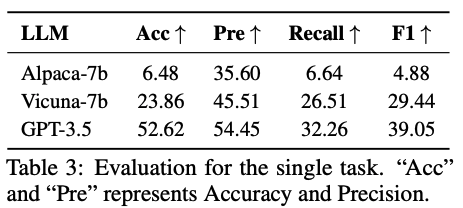
Single task: 단일 테스크에 대한 평가이며, 테스크의 이름과 라벨이 동일한 경우만 맞은 것으로 간주합니다. 이 때 지표로는 F1 score와 accuracy를 사용했습니다.
-
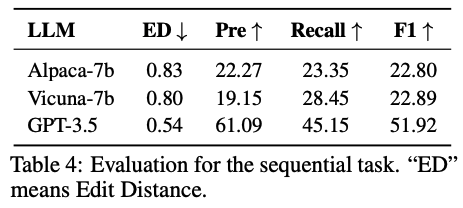
Sequential task: 여러 개의 테스크가 연속적으로 연결된 경우에 대한 평가로, F1과 Edit Distance를 평가 지표로 사용합니다.
-
Graph task: 사용자의 요청이 일반적으로 acyclic graph 형태를 그린다는 가정 하에 진행했습니다. F1 score도 사용했지만, 여기서 GPT-4에게 평가를 맡기는 GPT-4 Score를 도입하게 됩니다.

각각에 대해 사용한 평가데이터는 크게 두 가지를 사용합니다. 우선 annotator들에게 직접 요청을 만들라고 지시합니다. 그 다음 GPT-4에게 task planning을 시켜 라벨링을 한 데이터를 첫 번째 평가데이터로 사용합니다. 두 번째 평가데이터는 일부 복잡한 테스크(46개)에 대해 사람에게 직접 라벨링을 시킨 high-quality human-annotated dataset을 사용합니다. 앞선 실험들은 모두 첫 번째 평가데이터를 사용했으며, 두 번째 평가데이터에 대해 실험을 진행한 결과는 아래와 같습니다.

이 모든 실험의 결론은, 사용하는 LLM 모델의 성능이 좋을수록 정량 지표가 압도적으로 좋아졌다는 것입니다. 또한 슬프게도(?) 사람이 직접 하는 경우와 비교하면 아직은 성능차이가 많이 난다고 언급됩니다.
한계점 & 의견
우선 저자들이 언급한 HuggingGPT의 한계점은 아래와 같습니다.
- HuggingGPT의 task planning 능력이 LLM 성능에 심하게 좌우되었다는 것입니다. 따라서 LLM을 task planning에 최적화시킬 방법이 필요하다고 언급했습니다.
- LLM과 수 차례 interaction해야 하기 때문에 비용이 많이 발생하며, 효율성을 높일 수 있는 방법이 필요합니다.
- 입력할 수 있는 토큰의 길이가 제한되어 있습니다.
- LLM 모델의 특성으로 인해 Instability(불안정성)이 큽니다. 이는 LLM의 Hallucination 현상으로 인한 것으로 보여집니다.
그 외에 개인적으로 생각하는 한계점은, 평가가 1단계였던 Task planning에 대해서만 진행되었기 때문에 각각의 테스크에 대해 적절한 모델을 선택했는지 등을 알 방법이 없었다는 점입니다. 이는 추후 연구를 통해서 보완할 것으로 보여집니다.
추가로 개인적으로 놀랐던 점은, 본 논문이 2023년 5월 말 정도에 나온 논문인데, 이 글을 작성하는 2023년 7월 말 기준으로 google scholar에 검색하면 인용수가 100회가 나옵니다. 즉 두 달 사이에 관련 논문만 100개가 나왔다는 의미이며, ChatGPT 이후로 수많은 연구가 쏟아지고 있다는 것으로 보여졌습니다. 언제 모든 연구를 따라잡을 수 있을지 무서워졌던 점이었습니다.

좋은 글 감사합니다. 자주 올게요 :)