논문 제목 : Deep Residual Learning for Image Recognition
논문 링크 : https://arxiv.org/abs/1512.03385
Abstract
깊은 neural net은 학습하기가 힘들다.
그래서 residual learning framework를 활용해서 더 깊은 network를 효과적으로 학습했다.
Accuracy가 증가했고 optimize도 쉬워졌다.
평가에 사용된 layer는 152개로 VGG net보다 8배 깊어졌다.
ImageNet의 데이터셋으로 3.57%의 error를 달성했다.
1. Introduction
깊은 신경망은 이미지 분류에 자주 이용되었다.
네트워크의 깊이가 상당히 중요하기 때문이다.
그렇다면 항상 더 많은 layer를 쌓으면 더 좋은 네트워크를 얻을까?
이를 방해하는 첫 문제는 vanishing/exploding gradients 문제였다(기울기 소실/폭주).
그렇지만 이는 normalize의 도입으로 해결되었다.
10개가 넘는 layer도 SGD를 이용한 역전파로 학습 가능했다.
그렇지만 또 새로운 문제, degradation problem이 제기되었다.
이는 어느순간 네트워크가 정체되었다가 나빠지는 현상이다.
그러나 이는 overfitting에 의해 일어난 것이 아니다.
Degranation 문제를 해결하는 방법은 더 깊은 모델을 만드는 것이다.
Layer를 추가해 identity mapping을 하게하면 될 것이다! -> 안됨.
오히려 실험 결과는 깊어질수록 에러가 커지는 것을 볼 수 있다.
이는 Figure 1을 보면 알 수 있다.
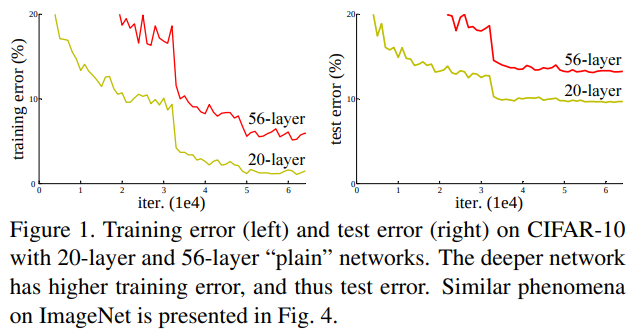
Figure 1은 "plain" network를 20, 56층 쌓은 것이다.
그래서 이 degradation 문제를 deep residual learning framework의 도입으로 해결했다.
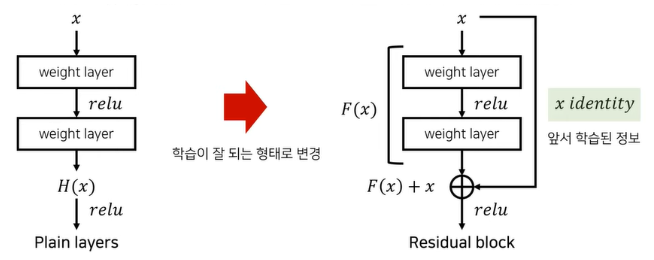
[출처 : https://www.youtube.com/watch?v=671BsKl8d0E]
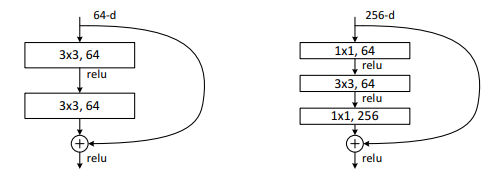
왼쪽이 기존 구조, 오른쪽이 residual 구조이다.
기울기 소실을 막기 위해서는 어떻게 해야할까?
입력과 출력이 거의 같아야 할 것이다.
그래야 많은 layer를 거쳐도 처음 입력만큼의 세기가 유지되어 소실이 일어나지 않을 것이다.
즉, 기존의 출력 를 로 새롭게 정의한다.
여기서 는 중간 layer들의 결과이다.
우리는 입력과 출력의 차이(residual, 잔차라 한다)를
로 정의했다.
그래서 기존의 를 identity mapping에 fit하게 맞추기 보다,
새로 정의한 를 0으로 만들기(입력과 출력 차이를 0으로)가 더 쉽기에 이를 사용한다.
따라서 이 구조가 residual block이 되는 것이다.
일단 파라미터를 더 추가하지도 않고 계산량이 크게 늘지도 않는다.
또 몇 개의 layer를 건너뛰는 효과가 있어 gradient vanishing 문제 해결에도 효과적이고, backward 계산도 용이해졌다.
ImageNet으로 실험한 결과
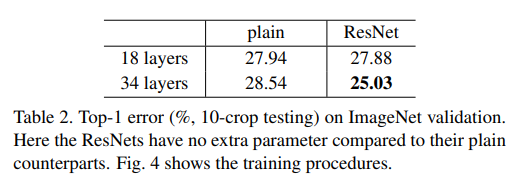
1) deep residual net도 기존의 plain net보다 최적화하기 쉽고
2) 더 깊어진 깊이 덕분에 accuracy도 높아졌다.
2. Related Work
이 부분은 간략히 핵심만 적도록 하겠다.
Residual Representation
Residual 표현을 쓴 다른 연구로부터 알 수 있는 점은,
합리적인 문제 재구성이나 preconditioning은 최적화를 간단히 만들 수 있다는 것이다.
Shortcut Connections
Shortcut 연결을 쓴 다양한 연구가 잇다.
기존 연구와 달리, 이 논문은 residual function을 항상 학습한다.
즉 identity shortcut이 절대 닫히지 않으며, 모든 정보가 지나가며 residual function이 학습된다.
또 기존 연구는 매우 깊은 깊이에서 accuracy 증가를 나타내지 않았다.(우리는 그르타~)
3. Deep Residual Learning
3.1 Residual Learning
만일 multiple nonlinear layers 점근적으로 복잡한 함수에 근사할 수 있다면,
residual function()도 근사 가능할 것이다.
이론상 두 방법 모두 근사는 가능하지만, 그 난이도에 차이가 있다.
이 재구성은 Fig 1의 degradation 문제로부터 출발했다.(직관이랑 반대였음 ㅠㅠ)
실제로는 identity mapping이 최적일 확률이 낮다.
그러나 이런 재구성이 문제를 precondition하는데 도움을 줄 수 있다.
(= 실제 최적 함수는 identity mapping이 아니지만, precondition 할 때 도움이 됨)
만약 최적 함수가 zero mapping보단 identity mapping에 가깝다면,
solver가 약간의 변화로 identity mapping을 학습하는게 새로운 함수 학습보다는 더 쉬울 것이다.
실험에서 학습된 resiudal 함수들은 작은 반응이 있었다.
즉 identity mapping이 합리적인 preconditioning을 제공한다는 것을 알 수 있다.
(= 최적함수가 zero인지 identity인지는 정확히는 모름,
오히려 optimal이 identity라고 보기 어렵다.
그렇지만 identity에 더 가깝다면 이렇게 로 근사하는게 도움됨.
왜냐하면 저렇게 가정하면 조금만 더 학습하면 되지만, 가정하지 않으면 아예 쌩으로 다 학습해야 하기 때문에..
이전 입력값을 출력값에 더해줘서 identity mapping이 항상 수행된다 -> 학습 난이도도 줄어듦)
3.2 Identity Mapping by Shortcuts
모든 stacked layer에 대해 residual learning을 적용했다.
Building block은 다음과 같이 정의된다.
는 쌓인 layer들을 라는 가중치로 계산한 것이다.
이 함수가 바로 학습되어야 할 residual mapping이다.
는 layer의 input, output vector이다.
는 사실 input, output 차원 맞추기 용이다. 맞다면 굳이 쓰지 않고
이렇게 사용하면 된다.
를 더해주는 것은 element-wise addition으로 컴퓨팅 복잡도에 큰 영향을 주지 않는다(무시함).
사실 갑자기 이 부분이 막혀서 고민했다.
과연 코드로 구현해도 가 0이 되도록 학습시킬 수 있을까?
내 결론은 굳이? 였다.
를 0으로 만들어! 라고 지시하기 보다는 그냥 로 만들어 놓으면
는 학습 가능한 함수가 아니니 를 자동으로 학습할 것이다.
그리고 학습을 거듭하면서 알아서 최적의 를 찾겠지...
여기서 코드적 의의는 input을 더해줘서 gradient vanishing을 없앤 것이라 보면 될 것 같다.
이론적 의의는 위에 말한대로 identity mapping을 최적화해준 것이다.
(사실 그것도 실제로는 최적이 아니니 오히려 코드로 구현했을때 0으로 만들어! 라고 지시 안하는게 맞는듯)
Residual function F는 상당히 유연하다.
Layer 수는 내 마음대로 정할 수 있다(다만 layer가 1개라면 써도 별 장점이 없었다).
또 위에서 단순화를 위해 FC layer로 수식을 보였지만, convolutional layer를 써도 상관없다.
Convolutional layer를 쓸 경우 차원을 맞추기 위해 1x1 convolutional layer를 쓴다.
이때 element-wise addition은 두 feature map 간의 channel-by-channel로 수행된다.
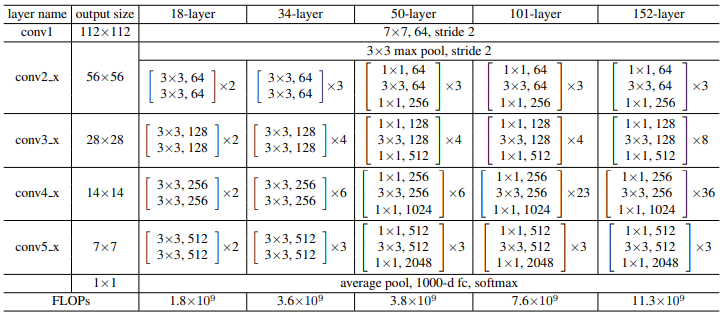
3.3 Network Architectures
네트워크 구조를 살펴보자.
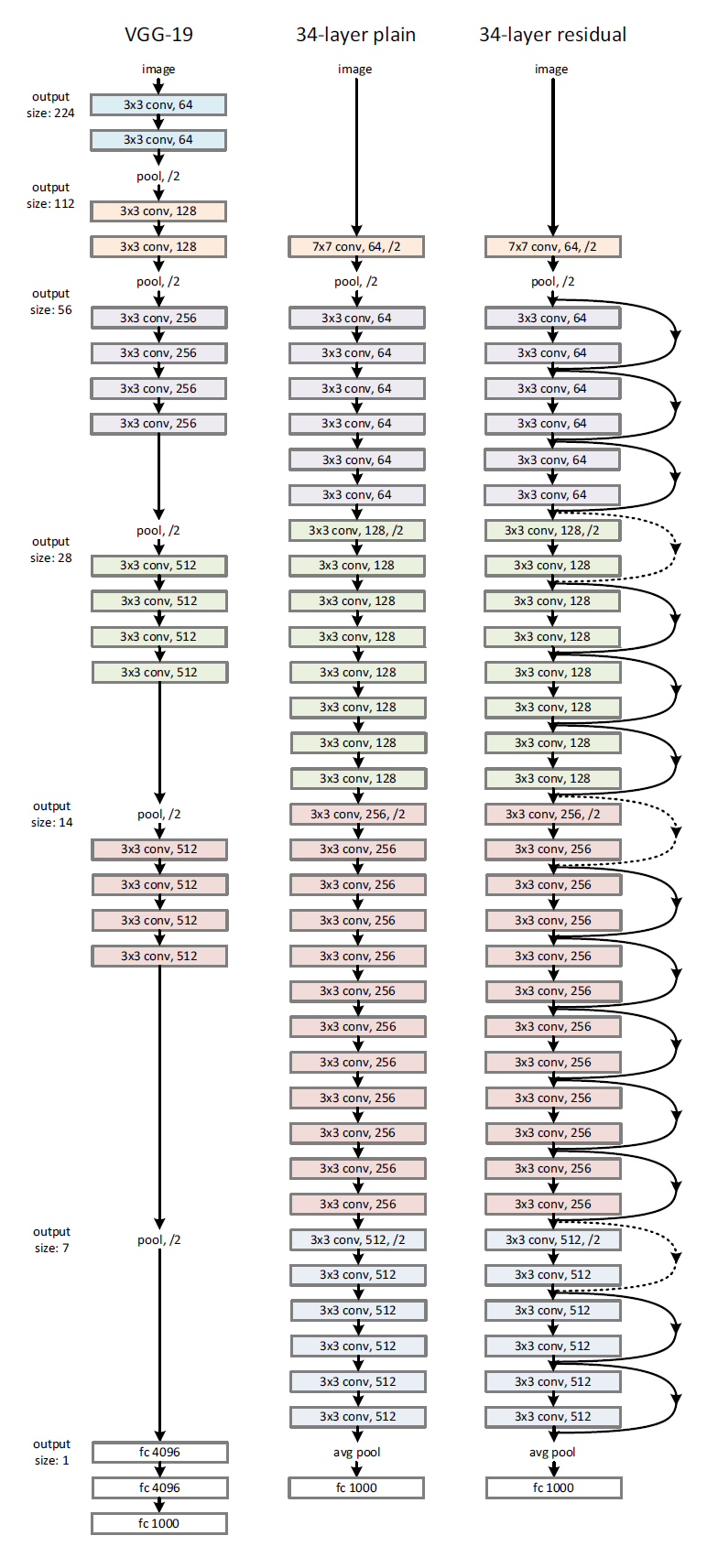
Figure 3. Example network architectures for ImageNet
출처 : https://sike6054.github.io/blog/paper/first-post/
1) Plain Network
Plain 구조의 근본은 VGGnets의 철학으로부터 영감을 받앗다.
Convolutional layer는 대부분 3x3 filter를 가진다.
그리고 두 가지의 간단한 디자인 룰이 있다.
(i) 같은 output feature map 크기에는, 같은 수의 filter를 가진다
(ii) feature map 크기가 반으로 줄어들면, filter의 수는 2배가 되어 각 layer마다 time-complexity가 같도록 한다
Stride 2를 가진 convolutional layer로 downsampling을 즉각 진행했다.
Network는 global average pooling layer와 1000-way FC layer(with softmax)로 끝난다.
우리의 모델이 VGGnet보다 더 적은 filter 수와 더 낮은 복잡도를 가지고 있었다.
우리의 34-layer baseline은 36억의 FLOPs(multiply-adds)를 가지고 있는데, 이는 VGG-19의 18%이다.
FLOPs란?
딥러닝에서 주로 쓰이는 연산량 계산법이다.
FLoating point Operation Per Seconds로 단위 시간(1s)당 얼마나 많은 floating 연산을 하는지를 나타낸다.
연산량에 포함되는건 더하기, 빼기, 곱셈, 나눗셈... 등 다양하다.
2) Residual Network
Plain network에 shortcut 연결을 더해서 residual version을 만들었다.
Identity shortcut은 입력, 출력의 차원이 같을 때 사용 가능했다.
차원이 증가하는 경우(네트워크 이미지에서 점선 화살표), 우리는 두 가지의 옵션을 고려했다.
(i) Zero entry를 추가로 padding해 차원을 맞추고 identity mapping을 했다.
이는 parameter의 추가 없이 수행 가능하다.
(ii) 앞서 말한 것 처럼 를 사용해 projection shortcut을 진행한다.
만일 shortcut이 사이즈가 다른 두 feature map에서 수행되었을 시, 두 옵션 다 stride 2로 수행되었다.
Feature map 사이즈가 달라지는 이유는 stride 2를 가진 convolutional layer로 downsampling을 했기 때문이다.
(+ filter 수는 2배가 되었다.)
3.4 Implementation
- 이미지는 scale augmentation을 위해 [256, 480]에서 무작위로 샘플링된 shorter side로 resized된다.
- 이미지나 horizontal flip된 이미지로부터 224 x 224 crop을 무작위로 샘플링한다(per-pixel mean을 subtract하고).
- 기본적인 color augmentation이 적용되었다.
- Batch Normalization은 convolution 바로 후, 그리고 activation 바로 전에 수행되었다.
그래서 따로 dropout은 사용하지 않았다. - 가중치는 He 초기화를 사용했다.
- Plain/Residual net들은 모두 밑바닥부터 학습했다.
- 256의 mini batch size로 SGD를 사용해 학습했다.
- Learning rate는 0.1로 시작해 error plateaus(loss function에 평지가 생겨 업데이트가 되지 않을 때)마다 10으로 나눴다.
그리고 모델들은 의 반복 횟수로 학습되었다. - 가중치 감소는 0.0001이고, momentum은 0.9이다.
왜 He 초기화를 사용했을까?
He 초기화는 를 표준편차로 하는 정규분포로 초기화한다.
Xavier는 활성함수가 선형일 때(sigmoid 계열), He는 활성함수가 보통 ReLU일 때 사용한다.
ResNet은 활성함수가 ReLU이므로 He를 사용했다.
테스트에는 보편적인 10-crop testing 기법을 사용했다.
더 좋은 결과를 위해 fully convolutional form을 채택했고,
이미지 shorter side가 {224, 256, 384, 480, 640}인 것으로 resize해서 score를 평균냈다.
4. Experiments
4.1 ImageNet Classification
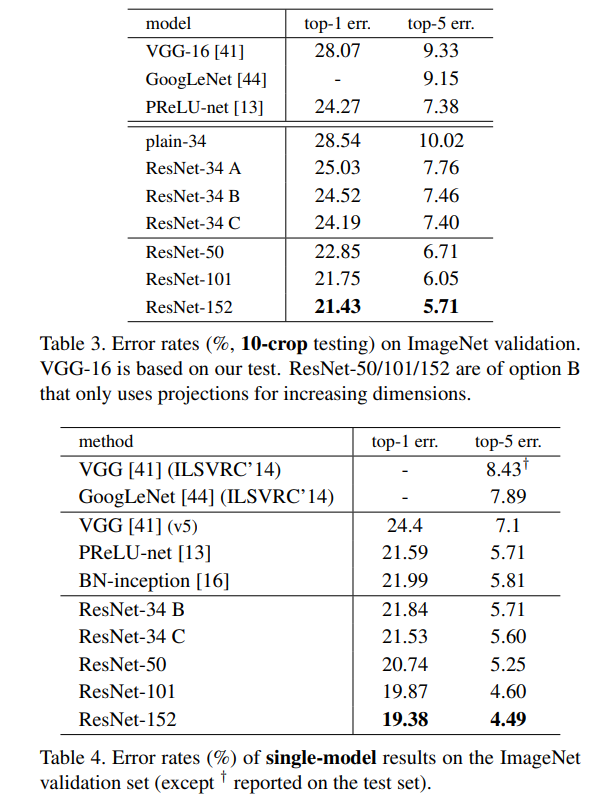
ImageNet 2012에서 1000개의 class를 가진 이미지로 평가했다.
128만장의 training 이미지, 5만장의 validation 이미지, 10만장의 test이미지로 수행했다.
결과는 top-1, top-5 error로 평가했다.
[ResNet 구조]
Plain Network
18-layer와 34-layer plain net으로 평가했다.
결과는 더 깊은 24-layer가 더 높은 validation error를 만들어냈다.
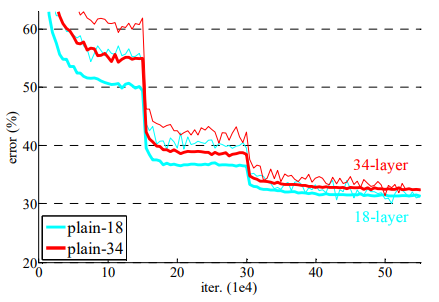
Error 그래프에서 degradation problem을 관측했다.
18-layer가 34-layer의 일부였음에도, 전체 training 과정에서 더 높은 training error를 보여줬다.
저자는 최적화 논문이 기울기 소실때문에 생기는 것이 아니라고 말한다.
왜냐하면 Batch Normalization을 사용해서 forward도 0이 되지 않게 했고,
backward propagation도 잘 되는 것을 확인했기 때문이다.
34-layer도 여전히 꽤 괜찮은 error가 나와서 solver는 잘 작동함을 알 수 있다.
저자는 아마 deep plain net이 지수적으로 낮아지는 수렴 속도로 인해 training error가 감소했을 것이라 추측한다.
Residual Network
기본적 구조는 plain net과 같되, shortcut이 3x3 filter에 붙어있다.
첫 비교에는 모든 shortcut에 identity mapping과 zero-padding을 적용했다(Table 2. 우측).
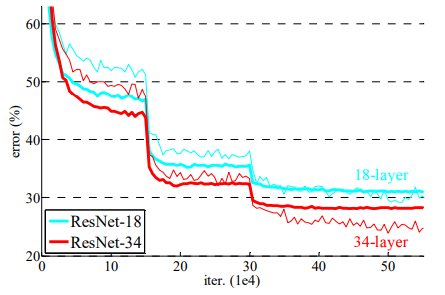
세 가지 관측 결과가 있다.
(1) 오히려 깊이가 깊을수록 더 좋아졌다.
34-layer ResNet은 훨씬 낮은 training error(validation data에도 낮은 error)를 보여주었다.
이는 깊어진 깊이로 accuracy가 나아졌고, degradation problem을 잘 해결한 것이다.
(2) 34-layer ResNet은 34-layer plain net과 비교하였을 때 top-1 error가 3.5% 줄었다.
이는 매우 깊은 system에서 residual learning의 효과를 보여준다.
(3) 18-layer ResNet과 plain net은 유사한 성능이었지만, ResNet은 훨씬 빨리 수렴했다.
충분히 깊지 않을 때 SGD solver로 plain net도 괜찮은 결과를 낼 수 있지만,
이런 상황에서도 ResNet이 훨씬 빠른 단계에서 수렴했다.
Identity vs Projection Shortcut
앞서 parameter-free한 identity shortcut이 학습에 도움됨을 보았다.
그렇다면 projection shortcut도 그럴까? 세 가지 옵션으로 비교했다.
A) zero-padding shortcut이 increasing dimension에 사용됨, 다른 shortcut도 모두 identity
B) projection shortcut이 increasing dimension에 사용됨, 다른 shortcut은 identity
C) projection shortcut만 사용함
성능은 C>B>A 순서였다.(C/B는 아주 미미한 차이, B/A는 미미한 차이)
이를 분석해보자면 다음과 같다.
A/B는 zero-padding으로 추가된 부분은 residual learning의 이점을 가지지 못해 B가 더 나은 성능을 가지는 것 같고,
B/C는 추가된 parameter가 학습에 도움을 준 것 같다고 추정된다.
그렇지만 이러한 미미한 차이는 degradation problem에 큰 영향을 주지 못한다.
따라서 memory/time complexity 문제로 인해 C는 사용하지 않는다.
Identity shortcut은 특히 아래에 소개될 bottlenet 구조의 복잡도를 늘리지 않기 위해 중요하다.
Deeper Bottleneck Architectures
이제 더 깊게 network를 만들어보자.
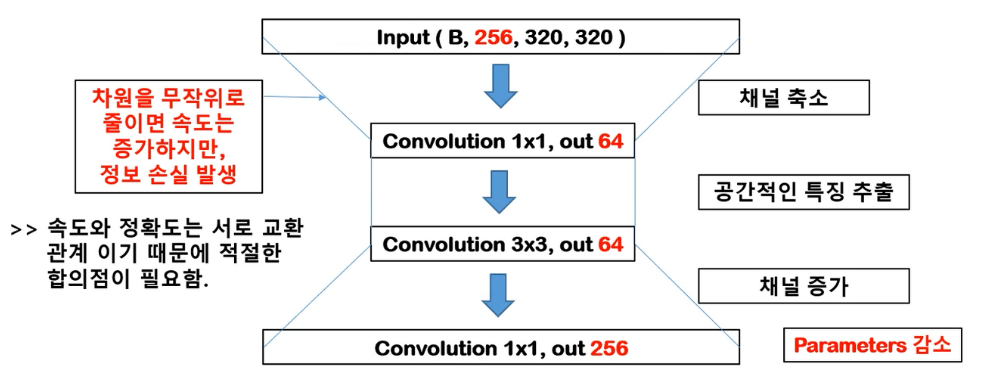
Training time을 줄이기 위해, bottleneck design을 사용했다.
각 residual function F에서, 3x3 conv layer 2개 대신 1x1 / 3x3 / 1x1 conv layer 3개를 사용했다.
1x1은 각각 차원 축소/확대(복원) 역할이다.
Parameter-free identity shortcut은 bottleneck 구조에서 계산량 줄이기와 모델 사이즈 축소에 중요하다.
만일 projection shortcut을 사용했다면 그 크기와 복잡도는 2배로 늘었을 것이다.
왜냐하면 shortcut이 두 개의 높은 차원 간에 연결되어 있기 때문이다.
Parameter 계산은 다음 블로그를 참조하자.
https://coding-yoon.tistory.com/116
블로그 이미지로 요약하자면 다음과 같다.
Channel이 4배가 되지만 parameter의 수는 약 3배로 줄어든다.
1x1은 spatial 특징이 없고 축소의 역할만 한다(spatial 특징은 최소 kernel 2부터).
참고로 parameter 계산은 Filter 가로 x Filter 세로 x Input Channel x Output Channel 이다.
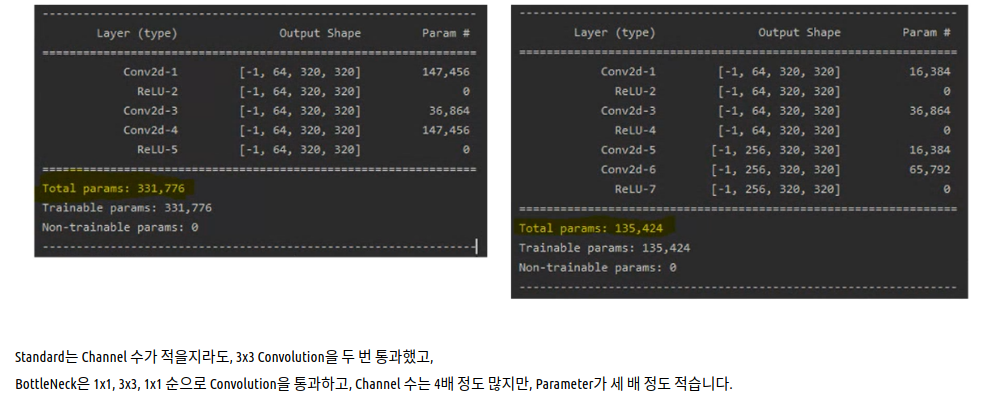
1) 50-layer ResNet
34-layer ResNet에 있는 2-layer block을 이 bottleneck으로 대체했다.
Shortcut은 B option(projection shortcut은 차원 증가에만, 나머지는 identity shortcut)을 사용했다.
연산량은 38억 FLOPs다.
2) 101-layer and 152-layer ResNets
Bottleneck layer를 더 많이 사용해서 만들었다.
깊이는 증가했지만 여전히 VGG-16/19 net보다 낮은 복잡도를 가지고 있다.
연산량은 113억 FLOPs다(VGG-16/19는 각각 153억/196억 FLOPs다).
34-layer 보다 50/101/152-layer Resnet이 좀 더 나은 결과를 냈다.
Degradation problem도 없고 깊이에 따른 accuracy 높아짐도 얻었다.
4.2 CIFAR-10 and Analysis
이번에는 CIFAR-10 데이터셋으로 실험했다.
이 데이터셋은 10개의 클래스이며, 5만 장의 training 이미지, 1만 장의 test 이미지로 되어있다.
좋은 결과보다는 매우 깊은 network에서 어떻게 작동하는지를 보기 위함이다.
- Plain/residual 구조는 Fig 3.의 중간/우측을 사용했다.
- 네트워크 입력은 32x32 이미지이다(per-pixel mean subtracted).
- 첫 layer는 3x3 convolutions이다.
- 그리고 3x3 convolution이 적용된 6n개의 layer stack을 사용했다.
각 feature map은 {32, 16, 8}의 size를 가지고 있고 각 feature map size마다 2n layer가 있다(그래서 3x2n = 6n layer). - Subsampling은 stride 2의 convolution으로 수행되었다.
- 네트워크의 끝은 global average pooling, 10-way FC layer, 그리고 softmax이다.
그래서 총 6n+2개의 stacked weighted layer가 있다(6n + 첫 layer + FC layer).
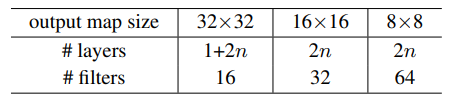
- Shortcut은 3x3 layer pairs에 사용되었고(총 3n개의 shortcut), 모두 identity shortcut을 사용했다(A).
그래야 residual model이 plain과 정확히 같은 깊이, 너비, parameter 수를 가지기 때문이다. - Weight decay는 0.0001이고 momentum은 0.9이다.
- 가중치는 He 초기화이며 dropout없이 Batch Normalizaiton을 사용했다.
- Mini batch는 128 크기로 두 개의 GPU에서 학습되었다.
- Learning rate는 0.1로 시작해서 32k, 48k 반복마다 10으로 나누었다.
그리고 64k 반복에서는 학습을 종료했다. - 45k/5k train/val split을 했다.
- 간단한 data augmentation을 했다.
4 pixel이 각 side에 padding되고, 32x32 crop이 무작위로 이미지와 horizontal flip에서 수행되었다.
테스트에는 오직 원본 이미지 32x32만 사용했다.
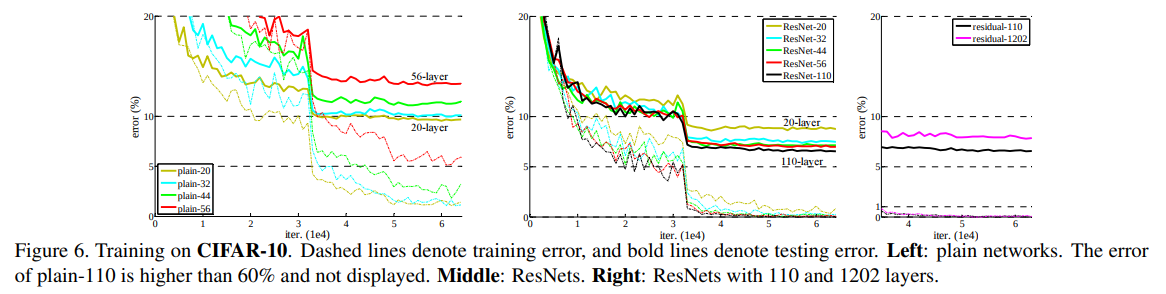
n={3, 5, 7, 9}일 때 비교했다.
이는 각각 20, 32, 44, 56-layer network를 만든다.
깊은 plain net은 깊이가 증가하면 training error가 증가했다.
이는 ImageNet과 유사했다(그리고 MNIST도).
따라서 최적화가 힘든건 근본적인 문제인 것으로 추정된다.
ResNet의 경우 역시 ImageNet과 유사하게 작동했다.
최적화 문제와 깊이에 따른 accuracy 증가를 얻어냈다.
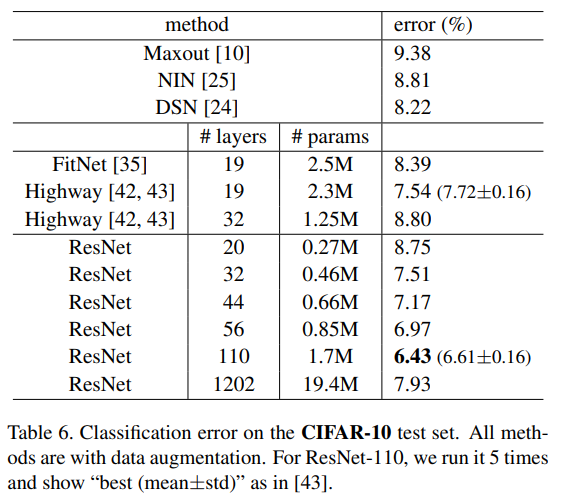
n=18(110-layer ResNEt)도 실험했다.
이 경우 learning rate가 0.1은 수렴하기에 너무 커서, 0.01로 training을 warm-up했다.
Training error가 80%(약 400번 반복) 아래로 가면 다시 0.1로 돌아가서 training했다.
남은 learning rate는 이전과 마찬가지로 진행했다.
110-layer도 마찬가지로 잘 수렴했다.
이는 FitNet이나 Highway 같은 네트워크보다 더 적은 파라미터를 가지고 있지만, SOTA 수준을 보여줬다.
Analysis of Layer Responses
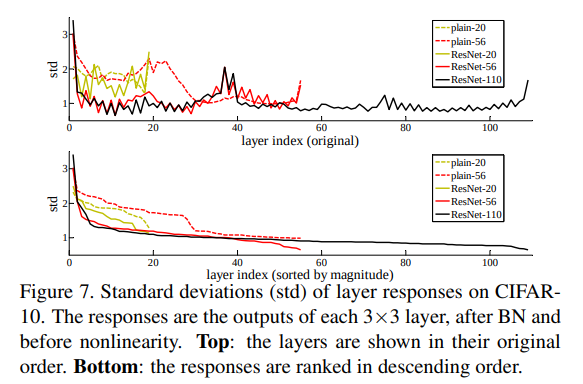
Fig. 7은 layer response의 표준편차를 보여준다.
이러한 response들은 3x3 layer, BN 다음의 출력이다(ReLU 이전!).
ResNet의 경우 residual function의 response 강도가 드러난다.
Residual function이 non-residual function보다 0에 더 가깝다는 사실을 보여준다.
이는 논문의 basic motivation을 뒷받침해준다(0에 더 가깝다는).
또한, 더 깊은 ResNet은 더 작은 response를 보여준다.
즉, 더 많은 layer가 있을 때 ResNet의 각 layer는 자신을 조금 덜 바꾸는 경향이 있다.
Exploring Over 1000 layers
n=200으로 설정해 1202-layer network도 실험했다.
Training error는 0.1% 이하, test error는 7.93%였다.
나쁘지 않았지만, 오히려 110-layer network에 비하면 좋지 않았다.
이는 모델이 너무 커서(19.4M) 이 작은 dataset에 맞지 않았다고 추측된다.
즉 overfitting된 것이다.
또한 논문에서는 강력한 규제인 dropout이나 maxout을 사용하지 않았으며, 적용했다면 더 좋은 결과가 나올 것이다.
ResNet은 앙상블이다?
한 흥미로운 논문이 있다.
ResNet이 앙상블 모델처럼 작용한다는 것이다.
앙상블이란 여러 모델을 섞어 최적의 결과를 도출하는 방법이다.
ResNet의 skip-connection이 여러 통로를 만드는 효과를 주기에 앙상블처럼 작용한다는 것이다.
자세히는 이해 못했지만 대략적으로 저렇게 작용하는 것만 알면 될듯.
Detail은 아래 논문 참조.
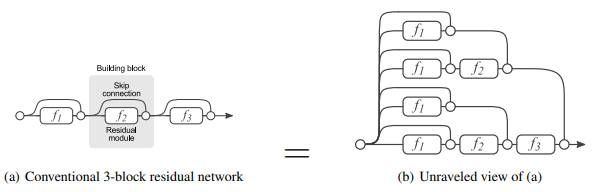
논문 참조 : Residual Networks Behave Like Ensembles of Relatively Shallow Networks
https://arxiv.org/pdf/1605.06431.pdf
Code
시행착오와 배운 점
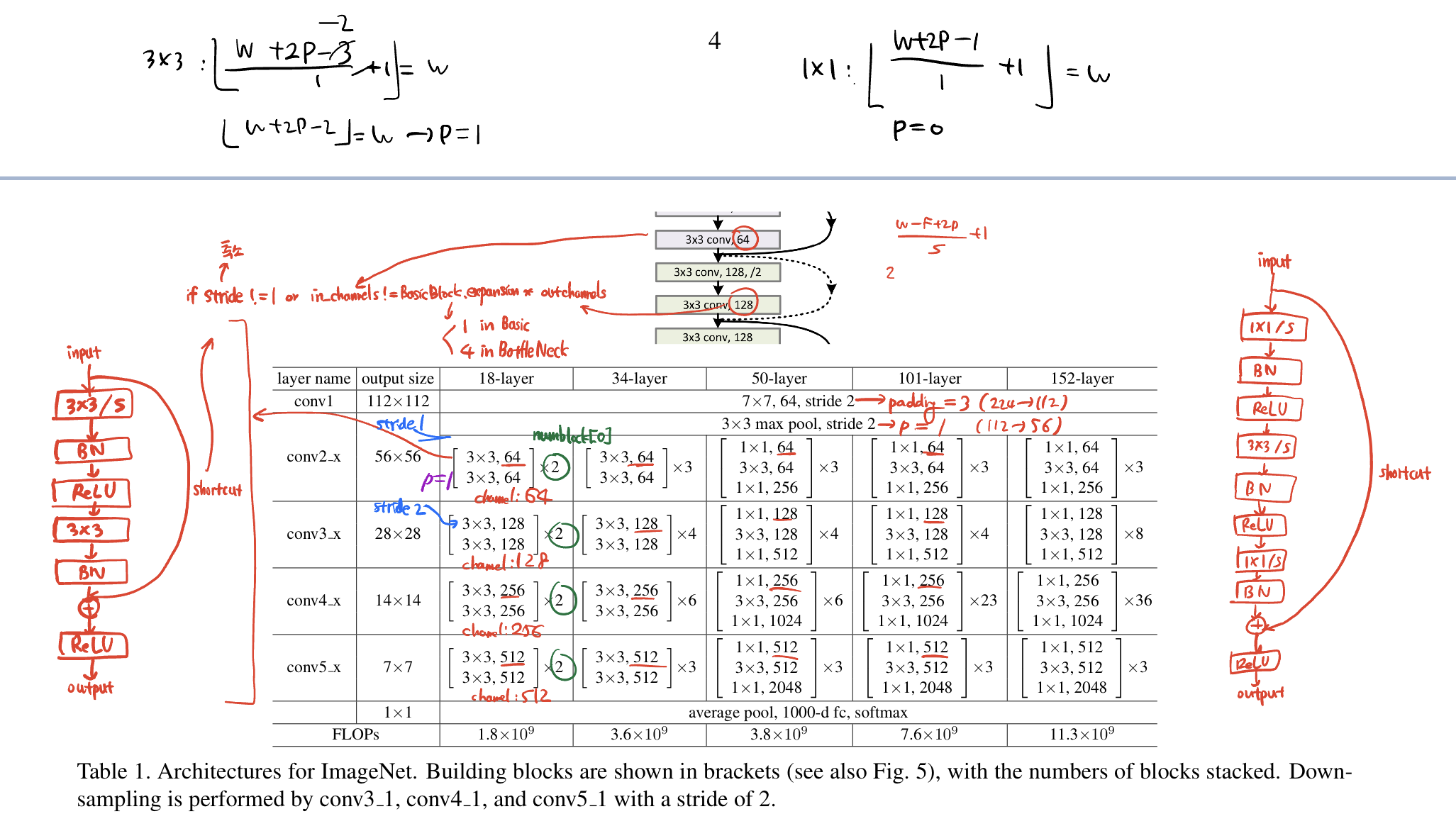
코드 구현 전 직접 계산을 뚝딱뚝딱..해보았다.
보기 어렵지만 요점만 간략히 보자.
1) 첫 단계에서 7x7x64 conv layer가 있다. 이는 stride 2이며,
input size가 224x224인데 output이 112x112이므로 padding=3이다.
그 다음 3x3 max pool layer는 stride가 2이고 112x112->56x56 이므로 padding=1이다.
2) Basic Block은
3x3/stride -> BN -> ReLU -> 3x3/padding=1 -> BN -> + shortcut -> ReLU 이다.
여기서 첫번째 stride는 downsampling할 때 2로 설정하는 경우가 있어 저렇게 뒀고,
보통 3x3은 width를 유지하기 위해 padding=1로 설정한다(검은 수식 참고).
3) BottleNeck은
(그림에 1x1/stride가 아니라 1x1/1(padding=1이라는 뜻)로 바꿔야 한다.)
1x1/1 -> BN -> ReLU -> 3x3/stride -> BN -> ReLU -> 1x1/1 -> BN -> + shortcut -> ReLU 이다.
1x1은 width를 유지하고 channel만 바꿔주므로 padding=0(default값)으로 설정한다(검은 수식 참고).
4) 구현 효율성(18/34/50/101/152 layer를 다 따로 만들 순 없기에..)을 위해 변수 처리를 했다.
먼저 numblock이라는 변수로 매 단계에서 쓰이는 block의 수를 처리했다.
예를 들어 34-layer는 [3, 4, 6, 3]과 같이 list로 넣었다.
또한 각 단계에서 channel의 시작은 64/128/256/512와 같이 정해져있고, bottleneck의 경우 마지막 output이 4배로 늘어난다.
따라서 기본적으로 정해진 수를 넣되, expansion 키워드를 활용해 늘어난 배수를 처리했다.
그리고 18/34는 Basic Block을, 50/101/152는 BottleNeck만을 쓰기에 각각 BasicBlock으로 할 지, BottleNeck으로 할 지 매개변수로 둬서 효율적으로 만들었다.
5) Projection shortcut은 1x1 convolution(stride=stride, padding=0)으로 처리했다.
주 목적은 output channel 수를 맞추는 것이다.
역시 Batch Normalization을 적용했다.
6) Stride는 conv2_x(channel이 64인 layer)를 제외하곤 모두 2로 시작한다. 쟤는 1이다.
7) 구현하다보면 이런 의문이 든다.
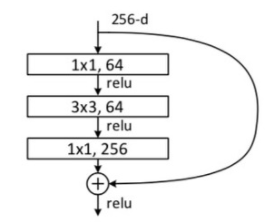
BottleNeck 구조는 다음과 같다. Input과 Output * expansion이 같다면 굳이 projection shortcut을 쓸 필요가 없다.
그러나 구조를 잘 보면

처음 BottleNeck을 쓸 때 그 전에 어떠한 전처리도 없다.
Input channel이 max pool 직후에는 64지만 projection shortcut이 없으려면 256이어야 한다.
따라서 이 부분에서 무언가 처리를 해줘야 할 것 같은데...
참고한 코드들은 이 부분을 따로 설명하지 않았다.
아마도 정밀한 코드에서는 따로 처리를 해주거나 그럴 것 같다.
원칙대로라면 identity shortcut이 있어야 한다.
여기서는 그냥 projection shortcut을 쓰는 듯 하다.
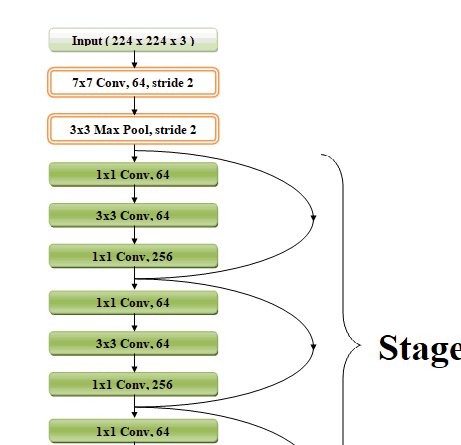
출처 : https://cv-tricks.com/keras/understand-implement-resnets/
8) 원래는 global average pooling을 써야하지만 torchvision과 참고한 코드는 모두 adaptive average pooling을 사용해서 그렇게 바꿨다.
AdaptiveAvgPool2d는 다음과 같이 작동한다.
기존의 pooling 함수는 kernel size를 지정해줬지만, AdaptiveAvgPool2d는 output size를 지정해준다.
예를 들어 7x7x2048 이 output이고, AdaptiveAvgPool2d((1,1))을 했다면, output은
1x1x2048이 될 것이다.
따라서 마지막에 FC layer는 2048(=512*block.expansion) x num_classes 로 설정하면 된다.
9) for m in self.modules()를 하면 모델 내 layer들을 차례로 반환한다.
여기에 if isinstance(m, nn.Conv2d)를 통해 type을 알 수 있다.
10) nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')라는 코드가 있다.
이를 살펴보자(참고로 He initialization = Kaiming Initialization).
먼저 PyTorch 공식 설명이다
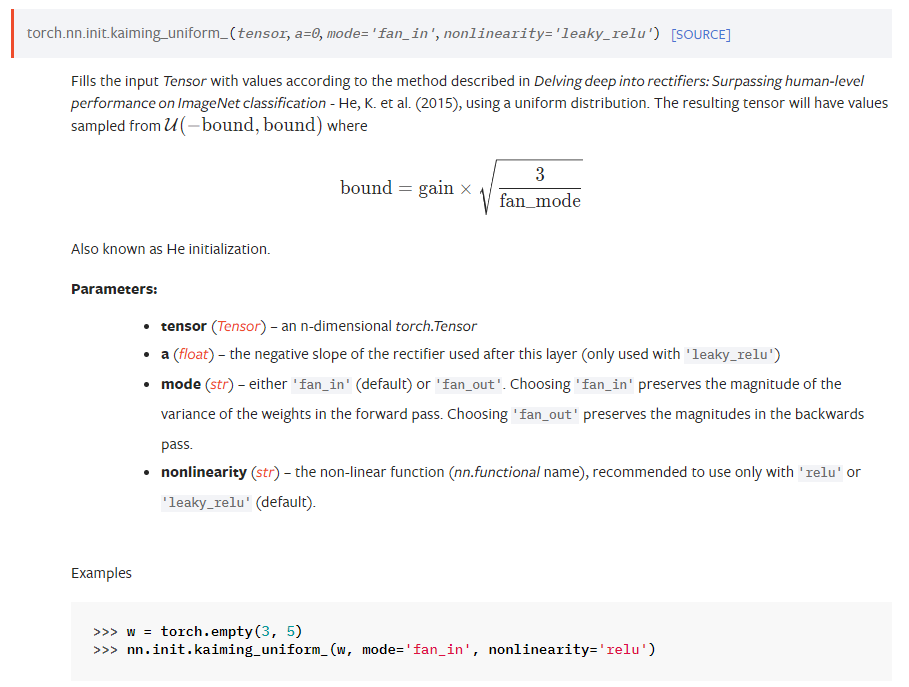
Delving deep into rectifiers 논문에 나온대로 초기화하겠다는 것이다.
즉 He 초깃값으로 의 정규분포를 가진다.
또 mode='fan_out'은 torchvision의 resnet이 그렇게 써서 쓰긴 했다.
fan_in : 입력값(그 전 layer의 뉴런의 수)
fan_out : 출력값(그 다음 layer의 뉴런의 수)
쉽게 말해 fan_in 설정 시 순전파 시 가중치 분산을 보존시킨다(왜냐면 이전 뉴런을 기반으로 설정).
fan_out 설정 시 역전파 시 가중치 전체의 크기를 보존시킨다(왜냐면 역전파 시 이전 뉴런을 기반으로 설정).
사실... 큰 상관은 없을 것 같긴 하다.
여기서는 역전파를 기준으로 잡은듯?
참고) Xavier는 fan_in, fan_out을 더해서 쓰기에 굳이 파라미터로 안 넘긴다.
ReLU를 쓴 이유는 실제 활성 함수로 쓰는게 아니라 범위를 잡을 때 나눠지는 값(상수)를 정하는 것이다.
Leaky ReLU와 ReLU 둘 중 하나를 선택하면 된다.
우린 ReLU를 활성 함수로 썼으니 그걸 선택하면 된다.
참고 : https://www.facebook.com/groups/PyTorchKR/posts/1362335700572774/
근데 Batch Normalization은 가중치가 굳이.. 필요가 없을텐데 왜 초기화 해준걸까.
Linear도 뭘로 초기화했다고 없긴한데... 일단 했다.
그냥 해주는김에 한 듯? 사실 큰 상관없다. 핵심은 He Initialization.
11) nn.Flatten과 x.view(x.size(0),-1)이 같은 역할의 함수인 것은 알고 있었다.
그러나 어이없는 실수를 했다..
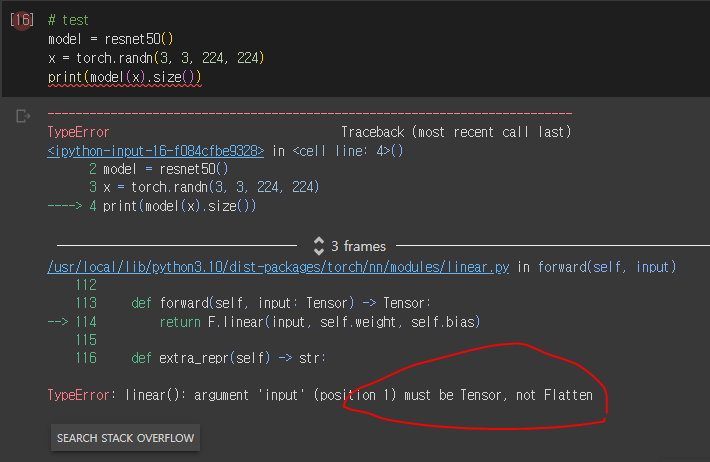
이런 오류가 뜨는 것이다!
알고 보니... nn.Flatten(x)가 아니라 nn.Flatten()(x)이다..
잘 나온다.
구현
디테일한 내용들은 github을 참조하자.
참조한 블로그들과 코드가 유사하지만, 몇 가지 입맛대로 좀 뜯어 고쳤다.
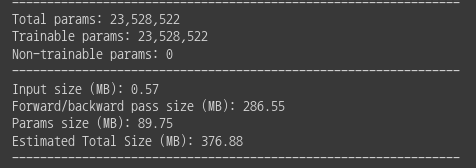
Model Summary(ResNet50 기준)인데, 꽤 가벼운 것을 볼 수 있다.
VGG보다 가볍다!
Train Code도 제작했다.
ImageNet이 아닌 CIFAR10에서 학습했으며, 논문에서 CIFAR10용 구조를 따로 주지만 굳이 사용하지 않았다.
내가 이번에 제작한 코드 중 제일 뿌듯한 것은 ReduceLROnPlateau이다.
ReduceLROnPlateau
ReduceLROnPlateau는 learning rate scheduler의 일종으로, 모델의 개선이 없으면 learning rate를 수정하는 함수이다.
한 번 살펴보자.

PyTorch 공식 사용법이다.
우리의 문제는 바로! CIFAR10 validation set이 없다는 것이다...이런.
그래서 먼저 load_dataset()부터 뜯어고쳐야 한다.
참고로 scheduler는 이렇게 불러낸다.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer = optimizer, mode = 'min', \
factor=0.1, patience = 10, verbose=True)이제 load_dataset()을 고쳐보자.
def load_dataset():
# preprocess
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
transforms.Resize((224, 224))
])
# load data
train = datasets.CIFAR10(root="./data", train=True, transform=transform, download=True)
train_size = int(len(train) * 0.8) # 80% training data
valid_size = len(train) - train_size # 20% validation data
train, valid = random_split(train, [train_size, valid_size])
test = datasets.CIFAR10(root="./data", train=False, transform=transform, download=True)
train_loader = DataLoader(train, batch_size=args.batch_size, shuffle = True)
val_loader = DataLoader(valid, batch_size=args.batch_size, shuffle=True)
test_loader = DataLoader(test, batch_size=args.batch_size, shuffle=True)
return train_loader, val_loader, test_loader이렇게 쪼개는 것은 https://discuss.pytorch.org/t/split-dataset-into-training-and-validation-without-applying-training-transform/115429 를 참조했다.
보면 알다시피 먼저 train load한 뒤, 이걸 쪼개고, DataLoader로 만든다.
참고로 random_split을 쓰려면 from torch.utils.data.dataset import random_split해야 한다.
여튼, 그렇게 쪼개고 나서 val_loader도 반환한다.
그 다음, 우리는 validation loss를 계산하는 함수를 만들어야 한다.
def loss_val(model, val_loader):
total_loss = 0
for batch_idx, (images, labels) in enumerate(val_loader, start=1):
images, labels = images.to(device), labels.to(device)
output = model(images)
total_loss += criterion(output, labels)
loss = total_loss / len(val_loader)
return lossWow.
먼저 total loss를 모두 계산한다.
Batch마다 그냥 더해주면 된다.
그리고 total loss를 데이터셋 크기로 나눠주고 loss를 반환한다.
마지막으로 적용해보자.
for epoch in range(args.n_epochs):
model.train()
train_loss = 0
correct, count = 0, 0
for batch_idx, (images, labels) in enumerate(train_loader, start=1):
images, labels = images.to(device), labels.to(device)
output = model(images)
optimizer.zero_grad()
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, preds = torch.max(output, 1) # torch max output is (max, max_index)
count += labels.size(0)
correct += torch.sum(preds == labels)
# here!
with torch.no_grad():
val_loss = loss_val(model, val_loader)
scheduler.step(val_loss)Batch마다 하는 것이 아니라, epoch마다 한다.
따라서 with torch.no_grad()(=학습하지 말고)를 쓰고 validation loss를 계산한다.
그리고 scheduler.step(val_loss)를 하면 알아서 발전이 없으면 조정해준다.
참 쉬워보이는 코드일 수 있지만.. PyTorch 문외한이라 삽질하며 겨우 찾았다.
돌려보지 않아 100% 확신할 수 없지만, 그래도 돌아갈 것이다.
학습 과정 저장하기
아주 중요하다.
나같이 열악한 환경에서는 매번 새로 가중치를 학습할 수는 없는 노릇이다.
자세한 글은 다음을 참조하자.
https://velog.io/@bpbpbp_yosep/PyTorch에서-모델-저장하기
Result
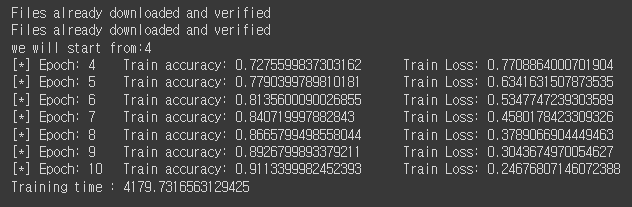
처음에 학습하다가 컴퓨터 연결이 끊겨서.. ㅠㅠ
돌려본 결과 Train Accuracy는 무려 91.1% 가량 나온다.
내 자식... 10 epoch만에 이정도를..? 기특하다!!!
그렇지만 객관적 시험을 쳐보자.
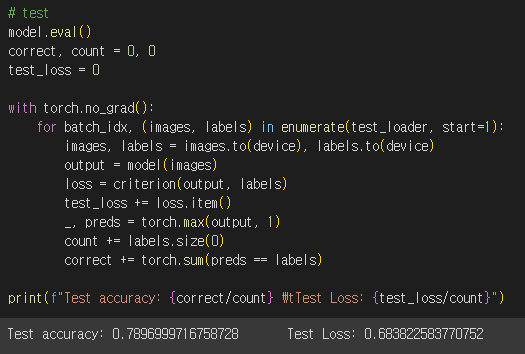
세상에... 훌륭하다.
약 78%의 accuracy를 얻었다.
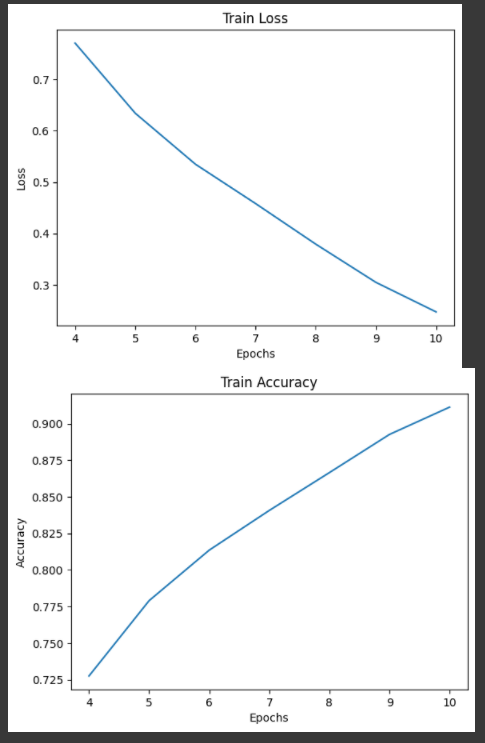
Train Loss와 Accuracy 그래프이다.
순조롭게 잘 학습하는 것을 볼 수 있다.
원래라면 validation으로 graph를 그리지만.. 대충 때웠다.
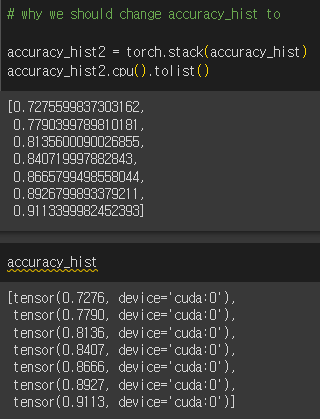
+) 그래프 그릴 때 accuracy_hist가 말썽이었다.
cuda:0, 즉 GPU에 있어서 그래프가 그려지지 않는 것이었다!
그래서 해결했다.
전체 코드는 Github에 있습니다~~.
https://github.com/Parkyosep/Paper/tree/main/ResNet
Reference
이론적 배경
[1] https://phil-baek.tistory.com/entry/ResNet-Deep-Residual-Learning-for-Image-Recognition-논문-리뷰
[2] https://daeun-computer-uneasy.tistory.com/28
[3] https://techblog-history-younghunjo1.tistory.com/279
[4] https://velog.io/@1-june/Residual-Block-간단-예시
[5] https://www.youtube.com/watch?v=671BsKl8d0E
[6] https://sike6054.github.io/blog/paper/first-post/
[7] https://di-bigdata-study.tistory.com/3
[8] https://yngie-c.github.io/deep%20learning/2020/03/17/parameter_init/
[10] https://cv-tricks.com/keras/understand-implement-resnets/
코드 구현
[10] https://deep-learning-study.tistory.com/534
[11] https://github.com/kuangliu/pytorch-cifar/blob/master/models/resnet.py
[12] https://cryptosalamander.tistory.com/156
[13] https://github.com/roytravel/paper-implementation/blob/master/resnet/train.py
