
논문 제목 : Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
논문 링크 : https://arxiv.org/pdf/1602.07261v2.pdf
Abstract
매우 깊은 convolutional network는 이미지 인식 성능에 중요한 역할이다.
특히 Inception 구조, residual 연결은 최근 성능 향상에 큰 영향을 주었다.
이 논문에서 Inception network를 residual로 학습하면 훨씬 빨라짐을 알 수 있었다.
또한 residual이 없는 expensive inception network보다 약간 더 성능이 좋았다.
적절한 activation scaling이 매우 넓은 residual Inception network 학습을 안정화시키는지 설명할 것이다.
세 개의 residual과 하나의 Inception-v4를 조합하여 CLS 대회에서 3.08%의 top-5 error를 기록했다.
1. Introduction
이 논문에서 두 개의 최근 아이디어를 조합할 것이다.
바로 Residual 연결과 Inception 구조이다.
Residual은 매우 깊은 구조 학습에 용이하고, Inception은 대체로 깊은 구조를 가지고 있다.
따라서 적용하면 residual approach의 이점은 모두 얻으면서 컴퓨팅 효율은 증가할 것이다.
또 Inception 그 자체만으로도 깊고 넓어질 수 있는지 실험했다.
그래서 Inception-v4를 개량해서(단순화, Inception 더 추가) Inception-v4를 디자인했다.
DistBelief(Tensorflow 이전의 구글 머신러닝 학습 도구) 대신 Tensorflow를 사용해서 훨씬 학습이 쉬웠다.
순수 Inception 구조인 Inception-v3, Inception-v4, 그리고 유사 비용의 하이브리드 버전인 Inception-ResNet을 비교할 것이다.
Inception-v4와 Inception-ResNet-v2는 유사한 성능(SOTA를 넘는)을 보였다.
조합하면 얼마나 더 작동할 지 궁금해서 여러 모델을 조합했다.
다만 조합 시 single frame의 성능 이득만큼 성능이 좋아지진 않았다.
그럼에도 새로운 SOTA급 성능을 보여주었다.
마지막 섹션에서는 분류 실패 사례를 살펴볼 것이다.
모델 병합이 여전히 데이터셋의 label noise에 도달하지 못했음을 통해 발전의 여지를 볼 수 있다.
2. Related Work
Residual 연결은 두 signal을 합침으로써 여러 이점을 얻었다.
Residual 논문 저자들은 매우 깊은 convolutional network 훈련에 필수적이라고 하지만,
이 논문에서는 본인들이 직접해본 결과 꼭 그런건 아니라고 한다.
Inception은 GoogLeNet에서 처음 도입되었으며 BN, factorization 등의 아이디어를 거쳐 개량되었다.
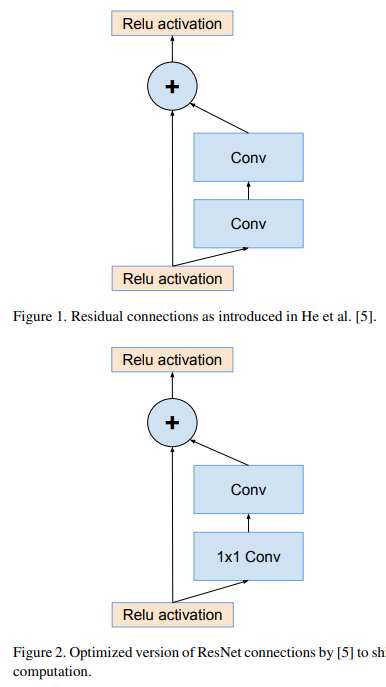
3. Architectural Choices
3.1 Pure Inception Blocks
과거의 Inception model들은 sub-network로 분리되어 학습되었다.
그러나 TensorFlow의 도입으로 더이상 분리하지 않고 학습할 수 있게 되었다.
이는 back-propagation과 여러 계산 과정에서의 tensor 연산 최적화 덕분이다.
또 training speed를 최적화하기 위해, 다양한 sub-network간의 computation을 균형맞추며 layer 크기를 조절했다.
저자의 이전 연구에서는 구조를 바꾸는 것에 상당히 보수적이었다.
그러나 바꾸지 않으면 더 복잡해짐에 따라, 이 논문에서는 불필요한 짐을 버리고 Inception Block의 grid size를 획일화했다.
Convolution에 "V"라고 표기된 것은 valid padding(padding 없는 것, output size 감소),
"V"가 없는 것은 same padding(input, output size가 같게 padding하는 것)이다.

Pure Inception-v4 전체 구조 모습이다.
3.2 Residual Inception Blocks
Inception network의 residual version을 위해, 원래 Inception보다 cheaper한 Inception block을 사용했다.
각 Inception block은 activation 없는 1x1 convolution layer를 통해 filter expansion을 했다.
이는 Inception block의 차원 감소를 보상하기 위해 scaling up하는 과정이다.
많은 버전을 테스트했지만, Inception-v3와 비용이 비슷한 "Inception-ResNet-v1",
Inception-v4와 비슷한 "Inception-ResNet-v2"만을 소개할 것이다.
Inception-v4의 학습 시간은 많은 수의 layer로 인해 실제로 확연하게 느렸다.
Residual과 non-residual Inception에 약간의 기술적 차이가 있었다.
바로 Inception-ResNet에는 BN을 오직 traditional layer에만 사용했다(summation에는 사용하지 않았다!).
사실 traditional layer가 대체 뭔지 궁금해서 찾아봤는데, 아무리 찾아도 나오지 않았다.
문맥상 그리고 구현한 코드들을 살펴보니 죄다 BN 적용한 것으로 보아
그냥 summation(마지막에 concatenate 하는 부분) 빼고는 다 쓰는듯 하다..
이는 BN이 이점이 있지만, single GPU에 모델의 복제본을 유지하기 위함이었다.
큰 activation size를 가진 layer들이 GPU를 불균형하게 소비함이 밝혀졌다.
BN을 그러한 layer에 사용하지 않음으로써 Inception block을 확연히 늘릴 수 있었다.
컴퓨팅 기술의 발전으로 이러한 trade-off가 불필요하길 바란다.
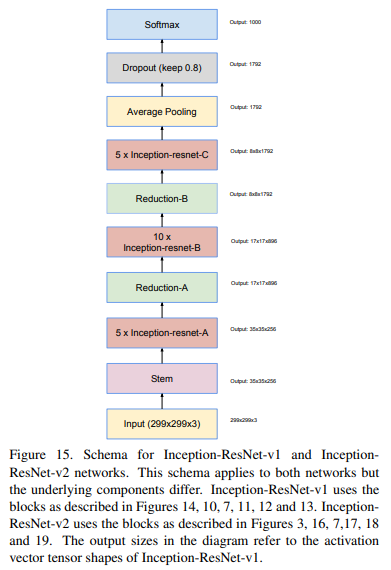
Inception-ResNet-v1, Inception-ResNet-v2 전체 구조 모습이다.
구조는 전반적으로 같으나 사용된 module이 조금씩 다르다.
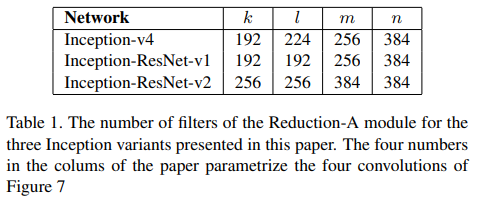
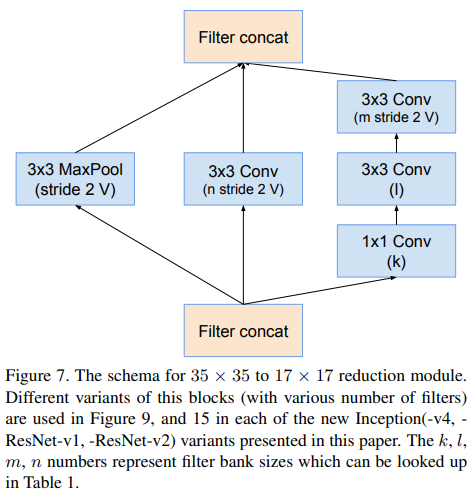
Reduction-A 모듈의 filter 수이다.
구조마다 수가 다른 것을 볼 수 있다.
k, l, m, n은 Fig. 7의 parameter이다.
3.3 Scaling of the Residuals
Filter의 수가 1000이 넘어가면, residual이 불안정해지고 training 종료 전에 일찍 "죽는" 현상이 나타났다.
이 말은 average pooling 전 마지막 layer에서 0만 계속 나오는 것이다.
이는 learning rate를 낮추거나 BN을 더하는 걸로는 해결되지 않았다.
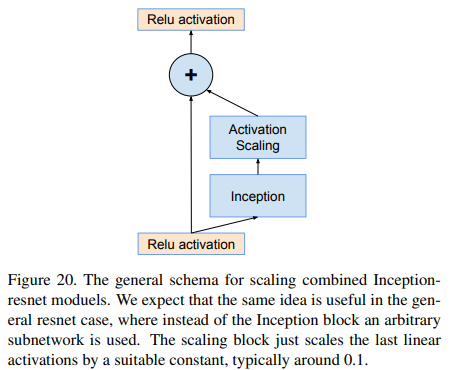
이전 layer의 activation에 residual을 바로 더하기 전에 0.1 ~ 0.3의 factor로 scaling down하면 안정화됨을 알아냈다(Fig. 20 참조).
He의 논문(ResNet)에서는 매우 낮은 learning rate로 "warm-up"하는 방법이 제시되었다.
그러나 이 방법은 filter가 엄청나게 많은 경우 정도의 아주 낮은 learning rate로도 해결되지 않았다.
Scaling down을 쓰는게 더 안전했다.
설령 쓸 필요가 없는 상황이어도 마지막 accuracy에 영향을 주지 않고 오히려 training 안정화에 도움이 된다.
Fig.20, Inception block 대신 임의의 subnetwork를 사용하는 resnet에도 유용할 것으로 보인다.
Scaling block은 마지막 linear activation을 적절한 상수(0.1 정도)로 scale하는 것이다.
쉽게 말해서, output = x + Inception(x) 에서 output = x + scale(Inception(x))로 바꾸면 된다.
4. Training Methodology
- Network는 20개의 복제본을 NVidia Kepler GPU에서 Tensorflow의 분산학습을 이용해 훈련되었다.
- Stochastic gradient를 사용했다.
- 실험 초기에는 0.9의 decay를 가진 momentum을 사용했고,
가장 높은 성능은 = 1.0, decay = 0.9를 가진 RMSProp으로 훈련되었다. - Learning rate는 0.045이며, 매번 2번의 epoch마다 0.94의 exponential rate로 decay했다.
- Model 평가는 계산된 parameter의 running average로 계산했다.
5. Experimental Results
Top-1과 Top-5 validation error를 training에서 관찰했다.
Poor bounding box로 인해 제외된 1700개를 생략한 validation set의 subset으로 학습이 되었음을 실험 후에 찾았다(학습 : validation - 1700 poor entities = validation subset).
이건 CLSLOC benchmark에서만 했었어야 하는데...
그럼에도 훨씬 긍정적인 성능 향상이 있었다.
성능 차이는 Top-1 error에서 0.3%, Top-5 error에서 0.15% 였다.
이 차이가 일관되었기에, 그래프 간 비교가 공정했다.
(미미한 차이라서 우연이라 생각할 수 있겠지만, 그래프에서 계속 일관된 차이 보여줌)
반면 50000개의 이미지로 구성된 valiation set에 대해서는 multi-crop과 결과 ensemble을 재수행했다.
(아마 single crop, ensemble 안한 것이 1700개를 제외했다는 말이고,
multi-crop, ensemble할 때는 1700개 포함한 50000개 모두 다 썼다는 말인듯.)
최종 ensemble 결과는 test set으로 수행했고, over-fitting되지 않았는지 검증을 위해ILSVRC 서버로 보내졌다.
아래는 Inception과 Inception-ResNet 결과이다.
Single Crop
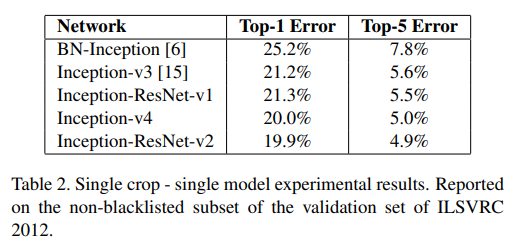
Table 2. Single Crop에서 전반적인 결과이다.
Inception-ResNet-v2가 성능이 제일 좋다.
Top-5
Fig. 22. Inception-v3와 Inception-ResNet-v1의 Top-5 error를 single model/single crop으로 non-blacklist에서 비교한 것이다.
성능의 향상뿐만 아니라 학습 속도가 엄청나게 향상됨을 볼 수 있다.
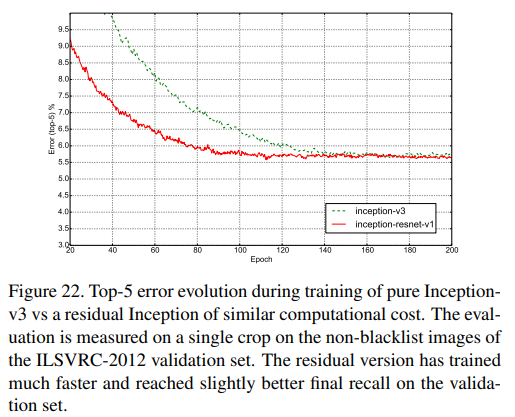
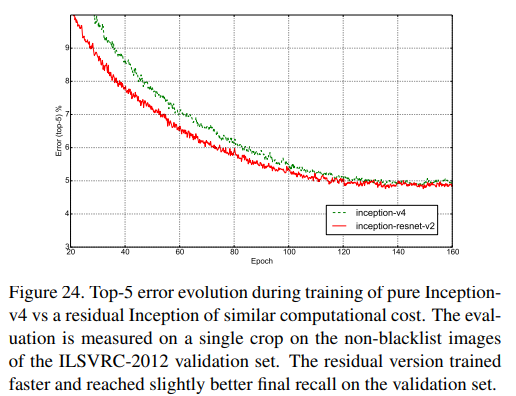
Fig. 24. Inception-v4와 Inception-ResNet-v2의 Top-5 error를 single model/single crop으로 non-blacklist에서 비교한 것이다.
성능과 학습 속도 모두 약간 더 향상되었다.
Non-blacklist에 대해 single model, single crop으로 4개의 모델의 Top-5 error를 비교한 것이다.
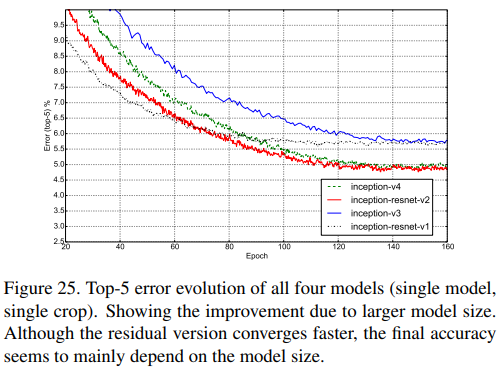
Top-1
Fig. 21. Inception-v3와 Inception-ResNet-v1의 Top-1 error를 single model/single crop으로 non-blacklist에서 비교한 것이다.
학습 속도가 엄청나게 향상되었지만, traditional Inception-v3보다 최종 성능이 약간 안 좋아졌다.
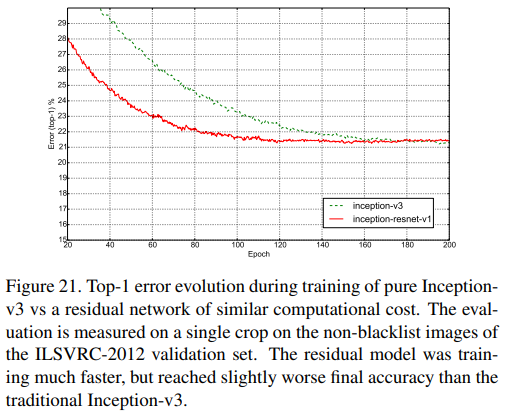
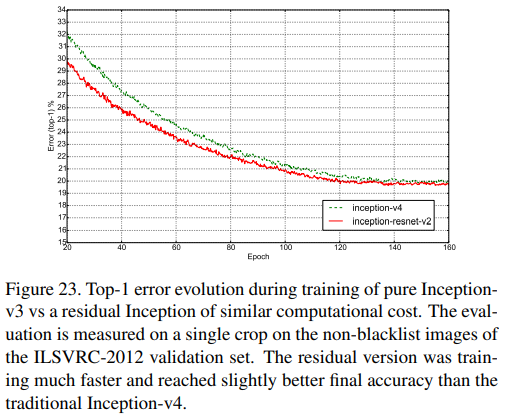
Fig. 23. Inception-v4와 Inception-ResNet-v2의 Top-1 error를 single model/single crop으로 non-blacklist에서 비교한 것이다.
성능과 학습 속도 모두 약간 더 향상되었다.
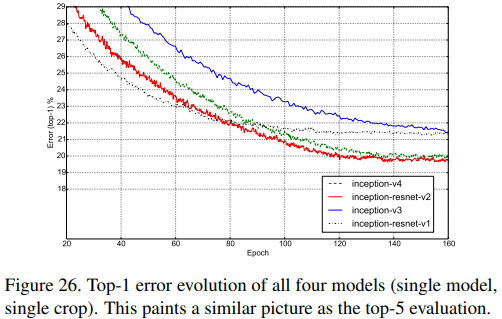
Non-blacklist에 대해 single model, single crop으로 4개의 모델의 Top-1 error를 비교한 것이다.
Multi Crop
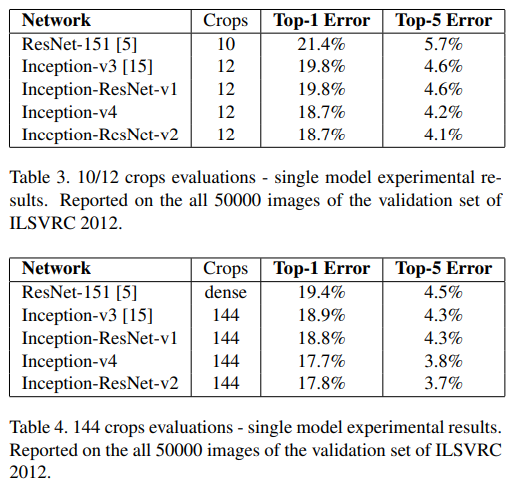
Table 3, Table 4. 10/12 crop과 144 crop으로 single model 성능을 비교했다.
확실히 Inception-ResNet-v2가 성능이 제일 좋다.
Ensemble
Table 5. 4~6개의 model을 ensemble해 결과를 냈다.
각 model들은 144 crop/dense 결과들을 ensemble한 것이다.
(ResNet-151, Inception-v3는 single model 결과를 ensemble한 듯)
여기서 Inception-v4 1개와 Inception-ResNet-v2 3개가 ensemble된 경우, test-set에 대해 top-5 error가 3.08% 나왔다.
이는 overfitting 되지 않았음을 보여준다.
(심지어 validation set보다 결과가 더 좋음!)

6. Conclusions
3개의 새로운 network 구조를 보였다.
- Inception-ResNet-v1 : Invception-v3와 비슷한 컴퓨팅 비용을 지닌 hybrid Inception 구조
- Inception-ResNet-v2 : 확연히 성능이 좋아진(그리고 더 비싸진) hybrid Inception 구조
- Inception-v4 : Inception-ResNet-v2와 비슷한 성능을 보여주는 non-Residual, pure Inception 구조
Residual 연결의 도입으로 training speed가 얼마나 향상되는지 연구했다.
또한 이전의 network보다 모델 크기가 더 깊어짐에 따라, 훨씬 향상된 성능을 보여주었다(residual 유무와 상관없이!).
Code
구현
핵심적인 부분만 설명할 것이다.
먼저 BasicConv2d Block을 만들어서 추후 model 구축을 쉽게 하자.
만드는 이유는 conv->BN->ReLU의 과정을 한 번에 하기 위해서이다.
# Basic Convolutional Module
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, bias = False, **kwargs),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x):
x = self.conv(x)
return x# Make Stem of Inception-v4 and Inception-ResNet-v2
class Stem(nn.Module):
def __init__(self):
super(Stem, self).__init__()
# 299x299x3 -> 147x147x64
self.conv1 = nn.Sequential(
BasicConv2d(3, 32, kernel_size = 3, stride = 2, padding = "valid"),
BasicConv2d(32, 32, kernel_size = 3, stride = 1, padding="valid"),
BasicConv2d(32, 64, kernel_size = 3, stride = 1, padding = "same")
)
# 147x147x64 -> 73x73x160(64/96)
self.branch1a = nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 0)
self.branch1b = BasicConv2d(64, 96, kernel_size = 3, stride = 2, padding ="valid")
# 73x73x160 -> 71x71x192(96/96)
self.branch2a = nn.Sequential(
BasicConv2d(160, 64, kernel_size = 1, stride = 1, padding = "same"),
BasicConv2d(64, 96, kernel_size = 3, stride = 1, padding = "valid")
)
self.branch2b = nn.Sequential(
BasicConv2d(160, 64, kernel_size = 1, stride = 1, padding = "same"),
BasicConv2d(64, 64, kernel_size = (7, 1), stride = 1, padding = "same"),
BasicConv2d(64, 64, kernel_size = (1, 7), stride = 1, padding = "same"),
BasicConv2d(64, 96, kernel_size = 3, stride = 1, padding = "valid")
)
self.branch3a = BasicConv2d(192, 192, kernel_size = 3, stride = 2, padding = "valid")
# 71x71x192 -> 35x35x384(192/192)
# if padding = 0(valid), kernel = 3, stride = 2 / if padding = 1, kernel = 4, stride = 2
self.branch3b = nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 0)
def forward(self, x):
x = self.conv1(x)
# why dim=1? because we use mini-batch, so input will be (batch_size, channels, x, y)
x = torch.cat((self.branch1a(x), self.branch1b(x)), dim=1)
x = torch.cat((self.branch2a(x), self.branch2b(x)), dim=1)
x = torch.cat((self.branch3a(x), self.branch3b(x)), dim=1)
return xStem 구현이다.
최대한 논문과 비슷하게 만들었다.
눈여겨 볼 부분은 padding을 valid/same으로 한 부분과
중간에 MaxPool2d가 kernel size가 안 적혀있어서 맞춘 부분이다.
이는 padding size에 따라 취향껏 정하면 된다.
Concat할 때 dim=1인 이유는 input이 (batch_size, channels, x, y)의 형태로 들어오기 때문이다.
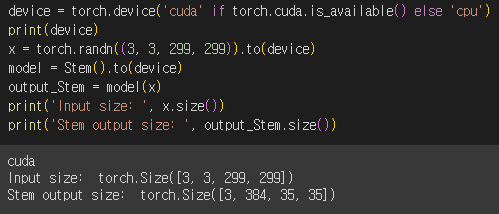
이렇게 중간 중간 체크하는 부분을 만들어줘야 한다.
안 그러면 모두 생성한 후 맞추기에는 너무 복잡하다.
논문에는 input, output channel/size가 정확하게 명시 안되어있는 경우도 있어 직접 계산해보길 바란다.
코드에는 내가 직접 모두 계산해서 적어놨다.
class Inception_ResNet_A(nn.Module):
def __init__(self, in_channels):
super(Inception_ResNet_A, self).__init__()
# 35x35x384 -> 35x35x32
self.branch1 = BasicConv2d(in_channels, 32, kernel_size = 1, stride = 1, padding = "same")
# 35x35x384 -> 35x35x32
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, 32, kernel_size = 1, stride = 1, padding = "same"),
BasicConv2d(32, 32, kernel_size = 3, stride = 1, padding = "same")
)
# 35x35x384 -> 35x35x64
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, 32, kernel_size = 1, stride = 1, padding = "same"),
BasicConv2d(32, 48, kernel_size = 3, stride = 1, padding = "same"),
BasicConv2d(48, 64, kernel_size = 3, stride = 1, padding = "same")
)
# after concat, 35x35x128
# 35x35x128 -> 35x35x384
self.dimchange = nn.Conv2d(128, 384, kernel_size = 1, stride = 1, padding = "same")
self.bn = nn.BatchNorm2d(384)
self.relu = nn.ReLU()
def forward(self, x):
x_shortcut = x
x = torch.cat((self.branch1(x), self.branch2(x), self.branch3(x)), dim=1)
x = self.dimchange(x)
x = self.bn(x_shortcut + x)
x = self.relu(x)
return xInception-ResNet-A이다.
여기서 shortcut 부분을 보면 따로 처리를 안하고 바로 더해준 것을 알 수 있다.
참고한 코드에는 shortcut에도 1x1 convolution이 있던데 굳이 필요없는 것 같아서 삭제했다(논문에도 없음).
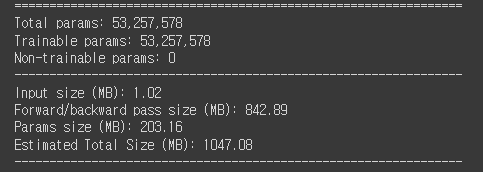
모델 요약이다.
1000MB를 넘는다. 정말 크다.
ResNet이 376MB 쯤이었으니 거의 3배다.
그래서 학습할 때 mini batch size도 좀 줄여서 했다.
# hyperparameter
args = EasyDict()
args.batch_size = 32
args.learning_rate = 0.005
args.n_epochs = 5
# functions
criterion = nn.CrossEntropyLoss(reduction = 'sum').to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
PATH = '/content/gdrive/MyDrive/Colab Notebooks/inceptionv4.pt'
import os.path
epoch_start = 1
if os.path.exists(PATH):
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch_start = checkpoint['epoch'] + 1
print("successfully loaded!")
print("epoch saved until here: ", epoch_start-1)
print("train starts from this epoch: Epoch ", epoch_start)Data 불러오는 코드이다.
이전 코드랑 비교해서 약간 수정했다.
Epoch start 부분이 이상해서 고쳤다.
이제 예를 들어 3 epoch까지 저장했다면 4 epoch부터 정상적으로 시작한다.
이전 코드는 좀.. 뭔가 이상했음.
Learning rate는 참고한 블로그에서 0.001로 했으나 수렴이 잘 되지 않았다고 하기에
5배 정도 올려서 setting했다.
Batch size도 model이 커서.. 좀 줄였다.
Epoch도 마찬가지이다.
이번 논문은 크게 시행 착오가 없어서 따로 기록할게 없다.
Result
너무 오래걸려서 도저히 더 못 돌렸다..
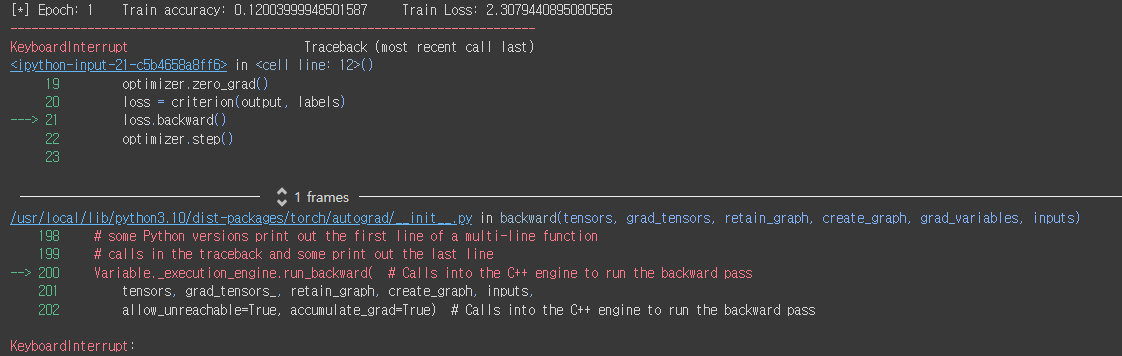
처참한 흔적...ㅋㅋㅋㅋ
Training Accuracy는 약 0.12가 나왔다.
더 돌렸다면 더 좋아졌을지도,,,
Appendix
Inception-v1/v2/v3/v4 차이
전체적으로 정리해보자.
Inception-v1
- 같은 해에 나온 VGG보다 성능이 크게 좋지는 않았다.
- Inception module을 최초로 사용했다.
- 1x1 convolution으로 차원을 축소했다.
- Auxiliary classifier을 도입했다.
Inception-v2
- 연산량을 줄이기 위해 filter를 더 나눈다.
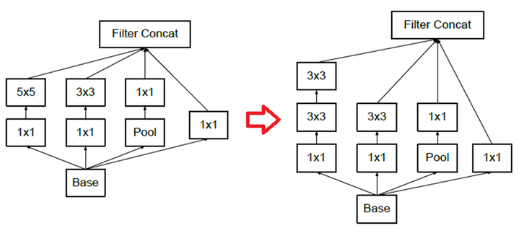
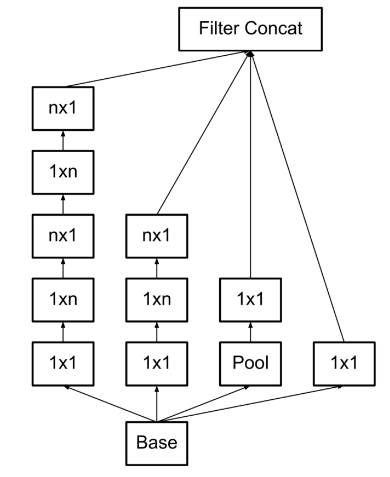
- 여기에 nxn filter마저 쪼갠다.
- 모델 초반의 auxiliary classifier가 쓸모없음이 밝혀지며 삭제했다.
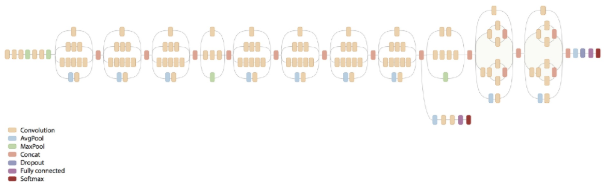
Inception-v3
- Optimizer를 RMSProp으로 변경했다.
- Label smoothing을 사용했다.
- 마지막 FC layer에 BN-auxiliary를 사용했다.
Inception-v4
- 기존 v1~v3가 성능은 좋지만 모델 구조가 너무 복잡했다.
이에 최대한 단순화 + Inception module을 더 많이 사용해서 성능과 구조 모두 잡았다.
자세한 것은 아래의 블로그를 참조하자.
https://hyunsooworld.tistory.com/entry/Inception-v1v2v3v4는-무엇이-다른가-CNN의-역사
전체 코드는 github에 있습니다~~.
https://github.com/Parkyosep/Papers/tree/main/Inception_v4
Reference
Paper
[1] https://sike6054.github.io/blog/paper/fourth-post/
[2] https://hyunsooworld.tistory.com/entry/Inception-v1v2v3v4는-무엇이-다른가-CNN의-역사
Code
[3] https://deep-learning-study.tistory.com/537
