Very Deep Convolutional Networks For Large-Scale Image Recognition(VGGNet)
Classification(Paper)
논문 제목 : Very Deep Convolutional Networks For Large-Scale Image Recognition
논문 링크 : https://arxiv.org/pdf/1409.1556.pdf
이번에 리뷰할 논문은 VGGNet이다.
원래 AlexNet-VGGNet-GoogLeNet.. 등의 순으로 소개했어야 하는데
아무래도 구조가 간단해서 미루고 미루다보니 이제 한다.
사실 구조만 보면 단순하기도 하고, ILSVRC 2등이라 크게 매력적이지 않을 수 있다.
하지만 단순하기에 여러 model들의 BackBone으로 자주 쓰이고,
당시 1등인 GoogLeNet보다 훨씬 간단한데 어떻게 저런 좋은 성적을 냈는지 살펴봐야 한다.
그래서 이 논문을 리뷰하게 되었다.
간략하게 핵심 위주로 살펴보자.
Abstract
이미지 인식 성능에 Convolutional network의 깊이가 얼마나 영향을 미치는지 조사했다.
3x3 size의 작은 convolutional filter를 사용해 16-19까지 깊이를 늘렸고,
이 덕분에 ILSVRC의 classification 분야에서 2등을 차지했다.
1. Introduction
Large public image repository가 사용 가능해지고, GPU같이 높은 컴퓨팅 시스템의 등장으로 이미지 인식 분야에서 다양한 성공을 이뤄냈다.
AlexNet(2012) 이후로 accuracy를 높이기 위한 다양한 시도가 이루어졌다.
First convolutional layer를 바꾸고나, training과 testing을 바꾸는 등 여러 방법이 제시되었지만,
이 논문에서는 깊이에 집중할 것이다.
3x3 size의 작은 filter 덕분에 convolutional layer의 깊이를 차근차근 늘렸고, parameter를 조정했다.
그 덕분에 accuracy가 크게 증가했다.
2. ConvNet Configurations
ConvNet의 깊이 증가로 인한 성능 향상을 비교하기 위해,
모든 ConvNet layer 세팅은 같은 원칙으로 설정되었다.
2.1 Architecture
- Input은 224x224x3 이미지이다.
- Preprocessing은 mean RGB 값을 각 픽셀에서 뺀 것이다.
- 이미지는 stack of conv layer를 지난다, 그리고 conv는 가장 작은 3x3 size이다.
stride=1, padding=same(1)이다.
(3x3은 상, 하, 좌, 우, 중간의 개념이 있는 최소 단위이다) - 1x1 conv filter는 input channel의 linear transformation을 위해 사용했다.
- Max-pooling은 5개이며, 일부 conv 뒤에 있다.
크기는 2x2에 stride=2이다. - FC layer는 총 3개로, 각각 4096/4096/1000(class 수) 의 channel을 지니고 있다.
- 모든 hidden layer는 ReLU를 사용했다.
- LRN(Local Response Normalization)은 컴퓨팅 비용 증가, 메모리 사용량 증가의 문제가 있지만 정작 성능 향상이 없어 사용하지 않았다.
2.2 Configuration
Table 1, ConvNet 구조이다.
A-E는 깊이만 다르다.
깊이는 11(8 conv, 3 FC)~19(16 conv, 3 FC)이다.
너비(channel 수)는 max-pooling layer 뒤에서 2배로 커지며, 64부터 시작해서 512까지 커진다.
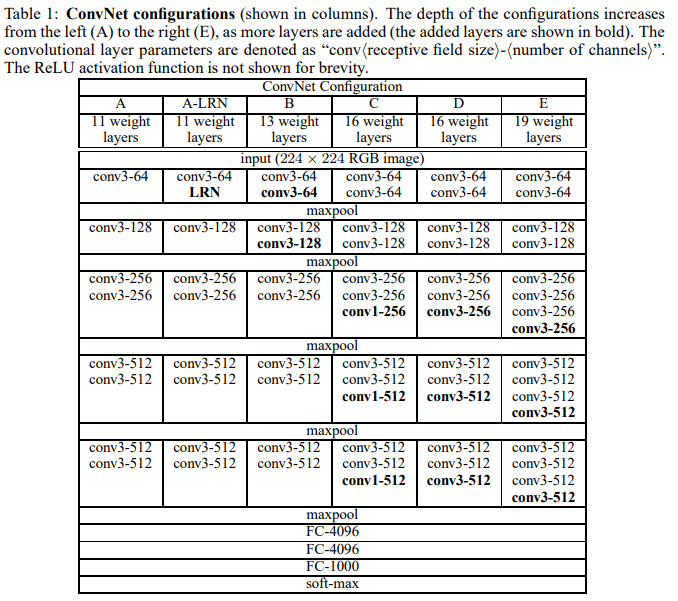
Table 2, parameter 수이다.
더 얕은 기존의 net과 비교하여, 깊이가 더 깊어졌음에도 weight 수는 더 커지지 않았다.
(vs 144M weights in (Sermanet et al., 2014))

2.3 Discussion
기존의 ILSVRC-2012, 2013에서 top-performing 하던 구조들과 이 ConvNet은 꽤 다르다.
큰 receptive field(filter, 11x11/4 or 7x7/2)를 첫 layer에 쓰는 대신,
3x3/1 의 작은 receptive field를 전체 net에 적용했다.
3x3 conv layer가 2개면 5x5의 효과를, 3개면 7x7의 효과를 낸다.
이에 대한 장점은 2개가 있다.
- 개수가 증가함에 따라 ReLU를 더 많이 쓰게 되어 비선형성이 증가한다.
즉 더 discriminative(결과가 다양)해진다. - Parameter의 수가 줄어든다.
3x3xC 3개의 경우, parameter는 이다.
7x7xC 1개의 경우, parameter는 이다.
이는 7x7에 비해 3x3이 약 81% 감소한 수치이다.
즉 이러한 상황에서 7x7 conv layer에 대해 정규화를 도입해 3x3으로 decomposition(분해)했다고 볼 수 있다.
1x1 conv layer는 크기는 변하지 않게 하면서 input, output channel 수를 동일하게 설정한다.
이는 같은 차원에 linear projection을 하며, conv에 딸려오는 ReLU가 또 비선형성을 추가한다.
GoogLeNet에서는 1x1 conv layer를 dimension change(parameter 줄이기)의 목적으로 사용했는데, 여기서는 linear projection과 ReLU를 쓰기 위해 사용한다.
3. Classification Framework
3.1 Training
학습 과정은 AlexNet의 방법을 대체로 따른다(단 input crop의 sampling만 빼고).
- 학습은 mini-batch GD, momentum=0.9, weight decay(L2, penalty multiplier = )을 사용해 다항 로지스틱 회귀(cross-entropy)를 최적화하며 진행되었다.
- Dropout은 첫 2개의 FC layer에 적용되었다(ratio = 0.5).
- Batch size는 256이다.
- Learning rate는 이며, validation accuracy가 더 나아지지 않으면 10으로 나눴다.
학습동안 총 3번 나눠졌다.
학습은 370K의 반복(74 epoch)에서 멈췄다.
AlexNet보다 더 적은 epoch에서 멈춘 것은
(a) 깊은 깊이와 작은 conv filter size로 인한 정규화로 더 쉽게 수렴함
(b) 각 layer의 pre-initialization
이 2개가 원인일 것으로 추정한다.
네트워크의 pre-initialization은 중요하다.
Table 1의 Configuration A에는 얕아서 random initialization으로 학습되기에 충분했다.
그리고 더 깊은 구조는 A의 layer weight로 첫 4개의 conv layer, 3개의 FC layer를 초기화했다(중간은 random).
Pre-initialization된 layer도 learning rate를 줄이지 않아 바뀔 수 있게 했다.
Random initialization은 평균 0, 분산 의 정규분포이며 편향은 0이다.
가중치를 pre-training없이 random하게 할 수 있던건 Xavier Glorot의 논문에 나온 방법을 쓴 덕이다.
224x224의 input 이미지 크기를 고정하기 위해, training 이미지를 SGD 반복 당 이미지 당 한 번씩 random하게 crop하여 사용했다.
Augmentation을 위해 random horizontal flipping과 random RGB color shift를 했다.
Training image size
S를 isotropically-rescaled된 image의 가장 짧은 side라 하자.
(isotropically-rescaled란 기존 이미지의 비율을 유지하며 rescaled된 것)
근데 crop size가 224x224니까 S는 224보다 커야한다.
즉 S=224라면 이미지 전체를 crop하고(짧은 쪽은 다 포함됨), 224보다 크다면 잘라낼 것이다.
기존 image와 같은 비율로 rescale하고, 224x224로 crop한다.
세 가지 방법으로 S를 실험했다.
- S=256
- S=384
- S를 [256,512]의 범위에서 random sampling
사실 이는 이미지의 물체 크기가 다르기에 합리적이다.
또 training set augmentation으로 쓰일 수 있다(=scale jittering).
빠른 학습을 위해 S=384를 고정하고 pre-train했다.
3.2 Testing
Test할 때, ConvNet과 input image는 아래의 과정을 거친다.
- Q(test scale, training scale인 S와 같을 필요 x)가 가장 짧은 이미지 side가 되게 isotropically rescaled한다.
각 S에 대해 다양한 Q를 쓰면 성능이 향상된다. - FC layer를 모두 conv layer로 바꾼다(첫 FC는 7x7, 2개의 FC는 1x1).
이는 이미지를 적용하는 구조를 fully-convolutional net을 만든다. - 결과는 class 수에 맞게 channel을 조정한다.
- 이미지에 대한 fixed-size vector를 제공하기 위해 score map은 sum-pooled된다.
- 이미지 dataset을 augment하기 위해 horizontal flipping하며, flip된 이미지는 최종 결과에 평균으로 들어간다.
Fully-convolutional network가 전체 이미지에 적용되므로, test에는 컴퓨팅적으로 비효율적인 multi-crop을 할 필요가 없다.
(그치만 crop을 많이하면 성능이 올라간다 by Szegedy et.al(2014))
Multi-crop 평가는 dense 평가와 상호보완적이다(conv의 경계 조건때문에).
(dense 평가는 위에서 class 수에 맞게 channel을 만들고 score를 계산하는 것이다.
multi-crop에 비해 연산량이 훨씬 줄어든다!)
: ConvNet을 crop에 적용하면, feature-map은 zero padding된다.
반면 dense 평가는 같은 crop에 대해 옆 이미지를 쓰기 때문에 결과적으로 receptive field를 크게 키워주고 더 많은 context를 잡을 수 있다.
multi-crop : 이미지를 "처음"부터 자르기에, 0으로 padding함.
dense : conv을 통해 class만큼 channel만 만들면 됨, 여기서 conv할 때 multi-crop이 강제적으로 0으로 padding한 것과 다르게 convolution 연산은 한 픽셀의 주위값을 받아오기에 receptive field를 높여주는 효과를 줌)
3.3 Implementation Details
C++ Caffe toolbox를 사용했지만 몇 가지 수정을 거쳐 full-size 이미지를 다양한 scale에 대해 train했다.
Multiple-GPU로 데이터를 병렬적으로 학습했다.
각 GPU에서 gradient를 병렬적으로 계산한 후, 평균내어 전체 batch의 gradient를 구했다.
4-GPU는 GPU 1개보다 약 3.75배 빠르다.
4. Classification Experiment
ILSVRC 대회에서 쓰이는 dataset으로 classification 결과를 얻었다.
- Dataset은 training(1.3M), validaiton(50k), test(100k)인 3개의 set으로 나뉜다.
- Top-1 error와 top-5 error로 평가했다.
Top-1 error는 multi-class classification error이고,
Top-5 error는 핵심 평가 지표로, top-5 predicted categories를 벗어난 이미지의 비율이다. - 실험에서는 validation set을 test set으로 활용했고, 대회에서는 test set으로 결과를 냈다.
4.1 Single Scale Evaluation
- Fixed S일 경우 Q=S이다.
Jittered S일 경우 Q=0.5()이다.
즉 평균치를 사용했다. - Model A에서 LRN을 사용해 A-LRN network를 만들어봤지만 성능 향상이 없어 B~E에는 사용하지 않았다.
- A->E로 갈수록 ConvNet 깊이는 커지지만(11->19) error는 감소했다.
- 성능이 B<C인걸로 보아 non-linearity(ReLU 더 사용함)가 추가되면 도움된다.
- 같은 깊이인 C와 D를 비교해보자.
일부 layer에서 C는 1x1 conv를 사용했고 D는 3x3 conv를 사용했다.
성능은 C<D이다.
즉 spatial context를 capture하는 것 역시 중요하다. - Error rate는 19 layer에서 saturate되었는데, 더 큰 dataset에 대해서는 더 깊어도 될 것이다.
- B와 B에 쓰인 3x3 conv 2개를 5x5 conv로 대체한 얕은 구조를 비교했다.
Top-1 error는 얕은 구조쪽이 7% 높았다.
즉 작은 filter가 사용된 깊은 구조가 큰 filter를 쓴 얕은 구조보다 더 성능이 좋다는 것이다. - S를 [256, 512] 범위에서 추출하여 훈련한 scale jittering은 fixed S(S=256, 384)보다 더 성능이 좋았다.
Test에서 single scale이 쓰임에도 불구하고 성능 향상을 보여줬다.
즉 scale jittering을 통한 training set augmentation은 single scale로 test할 때 성능 향상에 도움이 된다.
4.2 Multi-Scale Evaluation
Test에 single scale 대신 scale jittering으로 multi-scale test를 해보자.
Test 이미지를 rescale한 후, network를 통과시켜 나온 결과를 average했다.
Training, test 이미지의 scale 차이가 크면 오히려 성능이 떨어지므로, 비슷하게 설정했다.
- Fixed S의 경우 Q = {}
- Jittered S의 경우 Q = {}
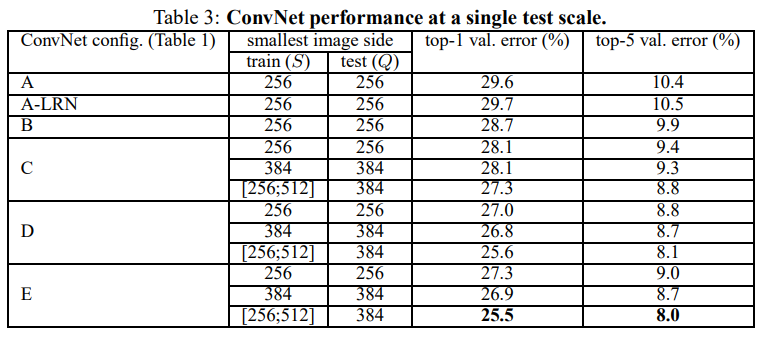
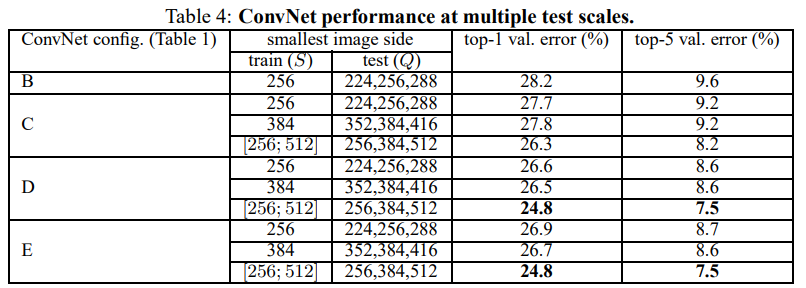
Table 3는 test를 single scale로 한 결과이며, Table 4는 test를 scale jitter해서 사용했다.
앞서 single scale에서도 깊이가 깊고(D, E), training을 scale jitter한 것이 fixed S보다 성능이 좋았다.
Talbe 4를 보면 알 수 있듯이, 여기서도 D, E, train with scale jitter가 성능이 좋다.
Validation set에 대해 top-1/top-5 error가 각각 24.8%/7.5% (공교롭게도 D, E가 성능이 완전 똑같다)이다.
E의 경우 test set에서 7.3%의 top-5 error를 달성했다.
4.3 Multi-Crop Evaluation
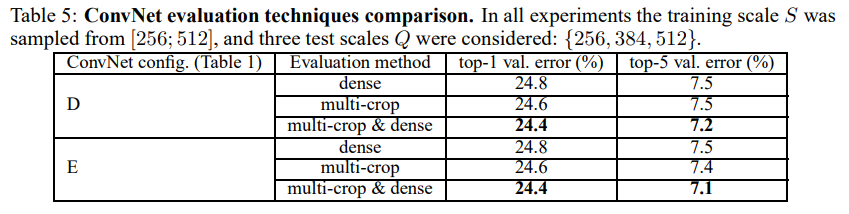
앞서 test할 때 network를 fully-convolutional로 바꾸었으므로 multi-crop도 적용 가능하다.
Dense(그냥 이미지 통째로 사용)와 multi-crop(한 이미지에 대해 crop 여러 번)을 비교해보자.
Multi-crop이 dense보다 약간 더 낫다.
4.4 ConvNet Fusion
여러 model을 soft-max class posterior를 평균내는 방식으로 합쳤다.
ILSVRC 대회 기간에는 single-scale network와 multi scale model D만 훈련했다.
D는 fine-tunning을 모든 layer 말고 FC layer만 하는 방식이었다.
7개의 network ensemble은 7.3%의 ILSVRC test error를 보여줬다.
대회 후, 두개의 best-performing model(D, E)만 합치는 방법이 생각나서 실행했다.
Dense evaluation으로는 7.0%, dense와 multi-crop을 같이 쓴 경우 6.8%의 test error를 얻었다.
참고로 single model의 최고 성능은 7.1%의 test error이다(model E, Table 5).

4.5 Comparison with the State of the Art
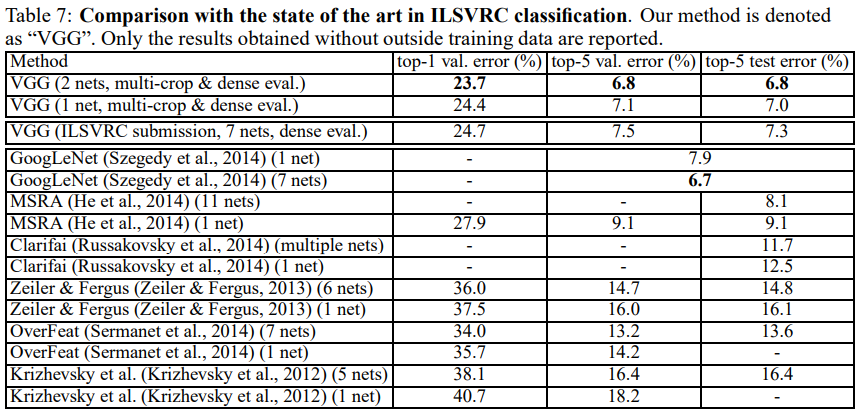
SOTA 결과물들과 비교해보자.
Table 7을 보면, ILSVRC-2014에서 7.3%의 test error로 2등을 수상했다.
또 대회 이후 2개의 net을 ensemble해 6.8%의 test error를 만들었다.
이는 ILSVRC-2012, 2013의 우승자를 훨씬 압도하는 결과이다.
2013년에 1등을 한 GoogLeNet(6.7%)과 거의 비슷한 결과이다(GoogLeNet은 7 net을 ensemble했다!).
단일 model로는 1등이다(7.0%, GoogLeNet보다 0.9% 앞섬).
주목할만한 점은, 구조는 LeCun이 제안한 ConvNet에서 크게 벗어나지 않고 깊이를 늘려 달성했다는 점이다.
5. Conclusion
이 논문에서 저자들은 19 weight layers라는 매우 깊은 convolutional network(당시..^^)를 만들었다.
Representation 깊이가 classification accuracy 향상에 도움되고, SOTA 성능을 달성할 수 있었다.
(Network의 표현력 깊이이므로 layer 수를 말하는듯)
이 연구는 다시 한 번 representation 깊이의 중요성을 확인시켜준다.
Summary
이 논문의 핵심을 요약해보자.
- ConvNet 깊이의 중요성을 보여줌
- 큰 filter 대신, 3x3 size의 filter가 잘 작동함을 보여줌
- LRN을 사용하지 않음(당시 LRN을 많이 사용함)
- Scale-jittering, test image multi-crop 등 성능 향상을 위한 이미지 처리를 사용함
- 비교적 단순한 구조로 구성되어 향후 Backbone으로 많이 쓰임
Code
구현
이번 코드는 거의 100% 스스로 짠 첫 코드이다.
FC layer 부분이 약간 오류가 나서 그것만 좀 찾아봤다.
뿌듯쓰 ^_^
여태 더 복잡한 구조를 짜다보니 이번 것은 간단했다.
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, bias=False, stride = 1, padding="same", **kwargs),
nn.ReLU()
)
def forward(self, x):
return self.conv(x)먼저 기본 Conv2d를 정의한다.
여기서 filter size는 3이고, stride는 1이며, padding=1(=same)으로 한다했으니 그대로 적용한다.
모든 hidden layer는 ReLU가 있다고 하였으므로 ReLU 역시 적용해준다.
class VGGNet(nn.Module):
def __init__(self, nblocks, num_classes=10, init_weights=True):
# nblocks = number of conv3, 4, 5 layer
# if nblocks = 3 -> VGGNet16, if nblocks=4 -> VGGNet19
super(VGGNet, self).__init__()
# conv1
self.conv1 = nn.Sequential(
BasicConv2d(3, 64),
BasicConv2d(64, 64),
nn.MaxPool2d(kernel_size = 2, stride = 2)
)
# conv2
self.conv2 = nn.Sequential(
BasicConv2d(64, 128),
BasicConv2d(128, 128),
nn.MaxPool2d(kernel_size = 2, stride = 2)
)
# conv3
layers = []
layers.append(BasicConv2d(128, 256))
for i in range(nblocks-1):
layers.append(BasicConv2d(256, 256))
layers.append(nn.MaxPool2d(kernel_size = 2, stride = 2))
self.conv3 = nn.Sequential(*layers)
# conv4
layers = []
layers.append(BasicConv2d(256, 512))
for i in range(nblocks-1):
layers.append(BasicConv2d(512, 512))
layers.append(nn.MaxPool2d(kernel_size = 2, stride = 2))
self.conv4 = nn.Sequential(*layers)
# conv5, number of channels don't change
layers = []
for i in range(nblocks):
layers.append(BasicConv2d(512, 512))
layers.append(nn.MaxPool2d(kernel_size = 2, stride = 2))
self.conv5 = nn.Sequential(*layers)
# classifier
self.fc = nn.Sequential(
# since 224x224 -> 7x7, 512x7x7 must be input
# paper does not use average pooling, so I didn't use adaptive average pooling
nn.Linear(512*7*7, 4096),
nn.Dropout(p=0.5),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.Dropout(p=0.5),
nn.ReLU(),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = nn.Flatten()(x)
x = self.fc(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# according to paper, random initialization = (mean=0, variance=10^-2)
nn.init.normal_(m.weight, mean=0.0, std=0.1)
if m.bias is not None:
# if bias exist, bias = 0
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)VGGNet 본체이다.
VGGNet D, E만 구현했는데 여기서 차이는 저번에 여러 모델을 구현할 때처럼 nblocks를 활용했다.

Conv3, 4, 5를 보면 VGG-16은 3개, VGG-19는 4개이다.
따라서 이 숫자로 for문을 돌려 layer를 만들어줬다.
마지막에 MaxPool(kernel=2, stride=2) 넣어주는 것을 잊지 말아야 한다.
Conv3, 4는 channel수가 바뀌기에 이것도 유의해야 한다.
Classifier 부분은 앞에 FC layer 2개에 Dropout(0.5)가 적용된다.
모든 hidden layer에 ReLU를 쓰므로 여기서도 사용했다.
가중치 초기화는 논문에서 나온대로 평균 0, 분산 0.01(=표준편차 0.1)인 정규분포로 초기화했다.
다른 논문은 보통 global average pooling을 사용해서 nn.AdaptiveAvgPool2d를 쓰면 되지만,
여기서는 따로 없어서 nn.Linear(512*7*7, 4096)이라는 무지막지한 크기의 linear layer를 만들었다.
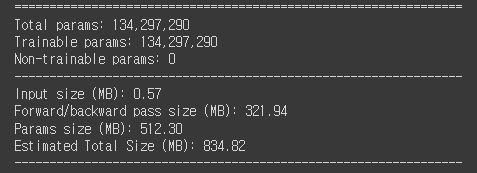
그래서 단순한 구조에 비해 model 크기가 상당히 크다.
참고로 동시대에 출품한 GoogLeNet이
이정도니..
Result
모델이 커서 한 epoch만 학습했다.

이 당시 initialization 기술이 제대로 없어 첫 accuracy가 처참하다..
논문에서도 74 epoch나 학습했다 했으니..

Test accuracy도 처참하다..ㅋㅋ
Current Batch 출력
학습하면서 epoch마다 출력하긴 하는데 대체 현재 어디쯤인지 궁금할때가 있다.
그래서 구글링하며 코드를 찾아본 결과 이렇게 하면 된다.
print(f"\rcurrent batch: {batch_idx} \t Total batch: {len(train_loader)}", end="")\r과 end=""의 조합을 하면, 맨 처음부터 쓰는 효과가 있다.
참고로 \n이 없으니 epoch 출력할 때는
print(f"\n[*] Epoch: {epoch} \tTrain accuracy: {correct/count} \tTrain Loss: {train_loss/count}")이렇게 맨 앞에 \n을 넣어줘야 한다.
전체 코드는 github에 있습니다~~.
https://github.com/Parkyosep/Papers/tree/main/VGGNet
Reference
Paper
[1] https://deep-learning-study.tistory.com/398
[2] https://wikidocs.net/118514
Code
[3] https://deep-learning-study.tistory.com/521
