
논문 제목 : Wide Residual Networks
논문 링크 : https://arxiv.org/pdf/1605.07146.pdf
이번에 리뷰할 논문은 Wide Residual Network이다.
여태 보던 논문 형태랑 조금 다르게 시원시원하고 글자도 큼직하다.
기존의 ResNet보다 넓이를 더 넓힌 모델이다.
나름 ResNet의 후속작으로 유명하기에 리뷰하게 되었다.
매번 논문을 너무 자세하게 리뷰하다보니 너무 오래 걸린다.
물론 내 말로 정리하다보니 이해도가 높아지고 추후 복습 시 유용하게 쓰일 것 같지만,
그걸 감안해도 너무 오래 걸린다..
따라서 최대한 요약해서 써볼 예정이다.
후기 : CIFAR, SVHN, COCO에서 SOTA 성능을 냈지만 ImageNet에서는 못 내서 아쉽..
전반적으로 너비 넓히는게 짱짱이에요~ 하는 느낌.
WRN의 계산 속도 향상 + wide의 regularizer 역할 + dropout with BN을 얻어가는 좋은 논문이다.
Abstract
이 논문에서 저자는 ResNet 구조에서 깊이는 줄이고 너비는 넓힌 구조를 제시한다.
이를 WRNs(wide residual networks)라 하며, 기존의 얇고 깊은 것들에 비해 훨씬 좋다고 한다.
16-layer-deep WRN이 기존의 1000-layer deep network보다 정확도나 효율성 면에서 압도했다.
WRN 구조를 통해 CIFAR, SVHN, COCO, ImageNet 등에서 SOTA 성능을 냈다.
1. Introduction
Deep Neural Network는 exploding/vanishing gradient, degradation과 같은 많은 문제가 있었다.
최신 residual network는 Inception 구조와 비교해서 더 나은 일반화 능력을 보여줬다.
Residual link는 deep neural network의 수렴 속도를 높였다.
현재 residual network 연구의 중점은 ResNet block의 activation 순서와 residual network의 깊이이다.
Width vs depth in residual networks
Residual network에서 너비와 깊이 어느것이 더 중요할까.
Circuit complexity theory literature에 따르면 shallow circuit은 deeper circuit보다 기하급수적으로 많은 component를 필요로 했다.
그래서 residual network 저자들은 최대한 얇게 구조를 만들고 depth를 키워 parameter를 적게하려 했다.
심지어 "bottleneck" 구조란 것도 제시해 ResNet block을 더 얇게 만들었다.
그러나 이렇게 깊은 구조는 network의 weakness를 더 키운다.
Residual block이 학습하도록 강제하지 않기에, 어떠한 것도 배우려 하지 않을 수 있고, 깊은 구조라면 몇몇 block만 쓸모있는 정보를 배울 수도 있다.
이를 해결하기 위해 randomly disabling residual block 등이 등장했다
(랜덤하게 residual block을 없애는 방법, dropout과 유사하다).
저자는 ResNet block을 넓히는 것이 깊이를 깊게 하는 것보다 성능 향상에 더 효율적이라는 것을 보여준다.
단적인 예로, Pre-activation ResNet에 비해 50배나 적은 layer와 2배 더 빠른 속도를 가진 wider deep residual network를 만들어냈다.
심지어 wide 16-layer deep network는 1000-layer thin deep network와 비슷한 parameter 수를 가지고 있지만, 학습은 몇 배나 빠르고 정확도는 같다.
즉 residual network의 핵심은 "residual block"이고, 깊이는 부차적인 것이다.
더 나은 wide residual network는 2배 더 많은 parameter를 가지고 있는데,
이정도 정확도 개선을 위해서는 thin network라면 수천 layer를 추가했어야할 것이다.
Use of dropout in ResNet blocks
보통 dropout은 parameter가 많은 top layer에 쓰여 feature coadaption과 over fitting을 막는데 쓰인다.
그러나 dropout은 BN에 의해 대체되었는데, BN이 regularizer 역할도 하고 성능도 더 좋았기 때문이다.
저자는 dropout이 학습을 regularize하고 overfitting을 막음을 연구했다.
이전(Pre-activation ResNet)에는 identity part of block에 dropout을 쓸 때의 부정적 효과를 보였지만,
그 대신 convolutional layer 사이에 넣는 것을 주장한다.
이를 통해 오히려 새로운 SOTA급 결과를 얻어낼 수 있었다.
2. Wide residual networks
Identity mapping이 있는 Residual block은 다음 식을 따른다.
은 network의 l-th unit의 input, output이고 F는 residual function, 은 block 내의 parameter이다.
Pre-activation ResNet 논문에서는 2개의 block이 있다(Fig. 1 참고).
- basic : conv3x3 - conv3x3(BN, ReLU가 앞에 있는)
- bottleneck : conv1x1 - conv3x3 - conv1x1(dimension reducing and expanding)
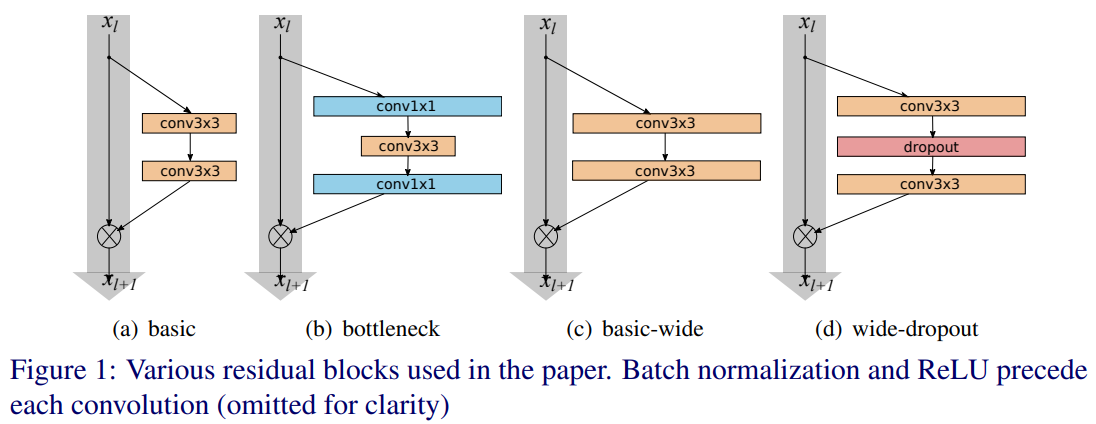
Pre-activation 논문에서는 conv-BN-ReLU였는데 여기서는 BN-ReLU-conv이다(DenseNet하고 순서 똑같다!).
이는 BN-ReLU-conv가 더 빨리 학습하고 더 나은 결과를 얻기 때문이다.
또 연구 주제가 "widening"이기에, network를 thin하게 만드는 "bottleneck"은 고려하지 않고 "basic" residual 구조에만 집중한다.
Residual block의 representational power를 늘리는 방법은 3가지가 있다.
- 1) Block 당 더 많은 conv layer 더하기
- 2) Conv layer를 feature plane을 더해서 더 넓히기
(즉 feature map dimension을 크게 만든다는 뜻) - 3) Conv layer의 filter size 키우기
작은 filter가 효과적이므로 3x3보다 작은건 쓰지 않는다.
여기서 2개의 factor를 도입한다.
- deepening factor l : block 내 conv의 수
- widening factor k : conv layer의 feature 수에 곱해진 값
Basic block의 경우 l=2(깊이 2), k=1(차원은 그대로 유지)이다.
전반적인 구조는 Table 1에 있다.
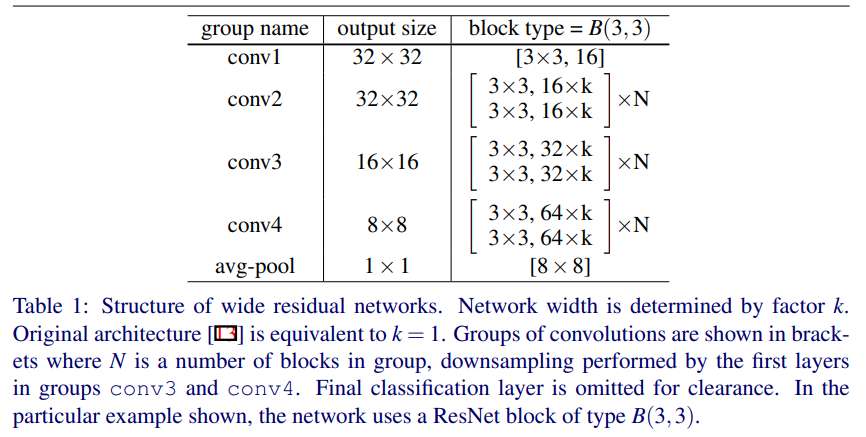
- conv1 : 첫 conv layer, size 고정되어 있음
- conv2, conv3, conv4 : size N, residual block, size는 k로 조정됨
- average pooling
- final classification
의 순서이다.
실험은 basic 구조를 바꾸며 진행했다.
2.1 Type of convolutions in residual block
B(M)을 residual block이라 하고, M은 block 내의 conv layer들의 kernel size list 이다.
즉 B(3, 1)은 conv3x3 - conv1x1 로 구성된 residual block이다.
Feature plane의 수는 block 내에서 동일하게 유지된다(bottleneck을 고려하지 않기로 했으므로).
그렇다면, basic residual 구조에서 conv3x3은 얼마나 중요할까?
그리고 conv1x1로 대체되거나 conv1x1의 조합으로 변형된다면 어떤 효과가 있을까?
이는 representational power의 변화를 가져올 것이다.
- B(3, 3) : 정석적인 "basic" block
- B(3, 1, 3) : conv1x1가 1개 추가됨
- B(1, 3, 1) : 각 conv의 차원이 같으므로, "straightened(펴진)" bottleneck
- B(1, 3) : conv1x1 - conv1x3을 network 내에서 반복함
- B(3, 1) : 이전 block과 유사한 아이디어
- B(3, 1, 1) : Network-in-Network style block
2.2 Number of convolutional layers per residual block
Deepening factor l에 대해서도 실험했다.
복잡도는 유지하되 다른 l과 d를 적용해 network를 만들었다.
(즉 parameter는 유지하니 d와 l은 반비례 관계이다)
2.3 Width of residual blocks
또한 widening factor k에 대해 실험했다.
Parameter 수는 l, d에 대해 선형적으로 증가하지만, k에 대해서는 2차로 증가한다.
그러나, layer를 넓히는게(k를 크게 하는게), small kernel 수천개를 넣는 것보다 GPU 계산에서 더 효율적이다.
(GPU는 큰 텐서의 병렬 컴퓨팅에 강하다)
그래서 이상적인 d, k 비율을 찾고 싶다.
k=1을 "thin", k>1을 "wide"한 network라 지칭하겠다.
또 WRN-n-k 표기는 WRN network가 conv layer n개와 widening factor k로 이뤄졌다는 것이다.
(참고로 VGG 구조와 WRN-22-8, WRN-16-10은 너비, 깊이, parameter 수 면에서 거의 비슷하다.
Residual 구조 이전의 network들은 상당히 넓은 경향이 있다)
2.4 Dropout in residual blocks
넓히는 것이 parameter 수를 늘리기에, regularization 방법을 연구했다(parameter 많아지면 overfitting).
ResNet은 이미 BN을 쓰지만, 이는 큰 data augmentation을 필요로 한다(bad ㅠ).
따라서 저자는 dropout layer를 residual block 내 conv layer 사이에 넣었다.
(이는 ReLU 뒤인데, 다음 residual block의 BN을 교란하고 overfitting을 막는다
아마 BN-ReLU-conv-dropout-BN-ReLU-conv인듯?)
이는 diminishing feature reuse 문제를 해결해 학습을 강화한다.
(즉 dropout -> 한 unit이 최대한 많이 커버하게 함,
따라서 feature를 각 unit이 최대한 학습하게 함)
3. Experimental results
실험에서 사용한 데이터는 CIFAR(10, 100), SVHN, ImageNet이다.
CIFAR, SVH은 pre-activation 사용함
- CIFAR(10, 100)
Data augmentation : horizontal flip, random crops(4 pixel로 padded, missing pixel은 원래 이미지의 reflection으로 채워짐)
Heavy한 augmentation 사용 안함.
ZCA whitening도 쓰고, 일부는 mean/std normalization 씀(타 실험과 비교 위해) - SVHN : 그냥 255로 나눠 [0, 1] 범위로 input 만듦
- ImageNet : 100 layer보다 적을 때 pre-activation 차이 없어서 original ResNet 사용
이제 다른 ResNet block 구조에 따른 발견과, 제안된 wide residual network의 성능을 분석할 것이다.
모든 실험은 "block 내 convolution type"과 "block 당 convolution 수"가 중점이고
k=2를 사용, Pre-activation ResNet에 비해 얕아진 깊이를 사용해 학습을 빠르게 했다.
Type of conovlutions in a block
Parameter 수를 비슷하게 하기 위해 layer를 조절했다.
- WRN-40-2 : B(1,3,1), B(3,1), B(1,3) - conv3x3이 1개
- WRN-28-2-B(3,3)
- WRN-22-2-B(3,1,3)
Test accuracy는 5번 돌려서 median을, 시간은 training epoch 당으로 계산했다.
결과는 다음과 같다.
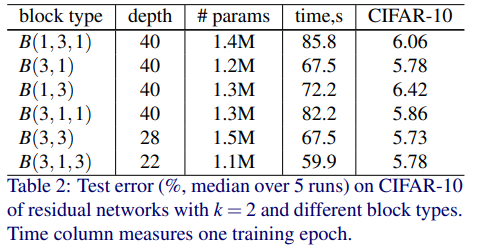
- Accuracy : B(3,3)이 제일 낫고, B(3,1), B(1,3)은 B(3,3)과 거의 비슷하다
- 시간 : B(3,1,3)이 다른 것보다 약간 더 빠르다
결과가 큰 차이가 없어 통일성을 위해 앞으로 WRN 구조에는 conv3x3만 사용할 예정이다.
Number of convolutions per block
Block 당 conv를 조절하는 deepening factor l을 바꿔가며 실험했다.
구조는 WRN-40-2, conv3x3, l은 [1, 2, 3, 4]이다.
Parameter와 conv layer 수는 유지했다.
(이 말은 총 40 layer이며, l이 커질수록 block 수가 줄어든 것이다)
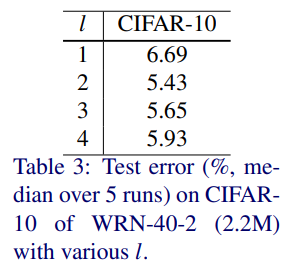
결과는 B(3,3)이 제일 낫고, B(3,3,3)/B(3,3,3,3)은 제일 안 좋은 것으로 나타났다.
제일 안 좋은 이유는 아마도 l이 커지며 block 수가 줄어서 residual connection이 줄어들었기 때문이라 추정된다.
B(3)도 꽤 나빴기에, 남은 실험에서는 B(3,3)만 고려할 예정이다.
(conv3x3만 사용 -> B(3,3)만 사용, 범위를 좁혀나감)
Width of residual blocks
Widening parameter k를 늘리기 위해서는 layer 수를 줄여야 한다.
최적의 k, layer 수 비율을 찾기 위해 k는 2에서 12, 깊이는 16에서 40으로 조절하며 실험했다.
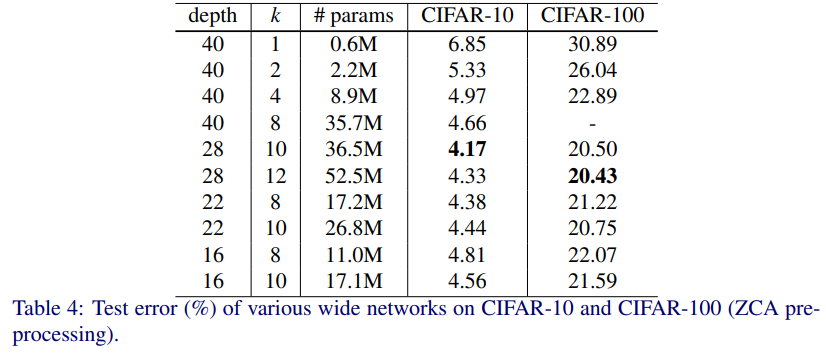
결과는 다음과 같다.
- 16, 22, 40 layer에서 width가 1->12로 증가하면 accuracy도 증가했다.
- k=8, 10으로 고정된 경우, 깊이가 16->28일때는 증가했지만, 깊이가 40일때는 오히려 감소했다.
WRN-40-4와 ResNet-1001을 비교해보자.
- WRN-40-4가 더 나은 정확도를 보여준다(CIFAR-10, CIFAR-100 둘다)
- 그러나 parameter 수는 얼추 비슷하다(8.9M, 10.2M).
- 즉 이 레벨에서 깊이보다 너비가 더 regularization 효과가 강하다
- 심지어 WRN-40-4가 8배 더 학습이 빠르다.
따라서 원래 residual network는 최적의 k-layer 비율이 아니다.
또 WRN-28-10과 ResNet-1001을 비교해보자.
학습 동안 mini batch size는 유지했다.
- WRN-28-10은 128 batch size를, ResNet-1001은 64 batch size를 사용했다.
- WRN-28-10이 CIFAR-10에서는 0.92%, CIFAR-100에서는 3.46% test error를 낮췄다.
- Layer 수는 WRN-28-10이 약 36배 적다.
즉 이전의 주장(깊이는 regularization 효과를 주고, width는 network가 overfit하게 한다)에 반하는 결과를 보여줬다.
WRN-28-10, WRN-40-10은 ResNet-1001보다 3.6, 5배 많은 parameter가 있지만 성능은 훨씬 좋았다.
(즉 parameter 많아져도 성능 좋아졌다 -> regularize 잘 됨 -> width가 regularize 더 잘함)
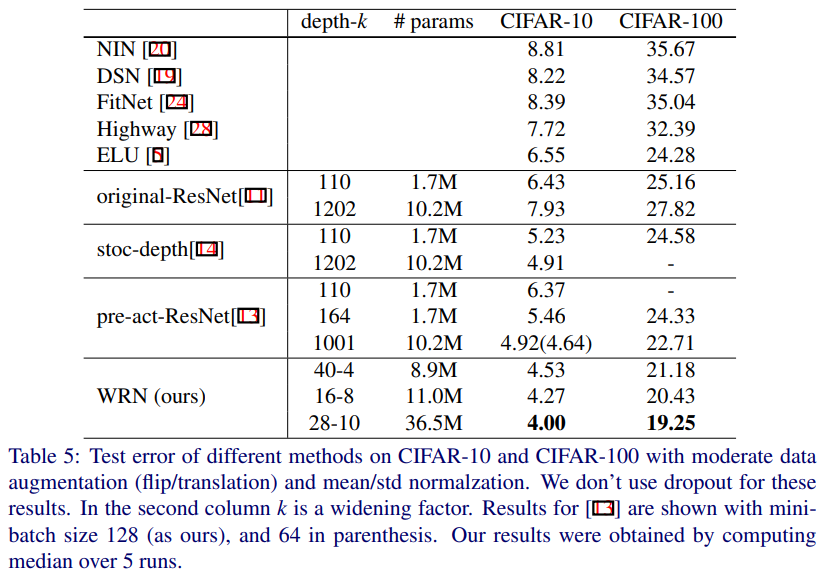
일반적으로 CIFAR의 mean/std preprocessing이 wider, deeper한 network를 더 좋은 accuracy로 훈련했다.
그리고 이를 통해 CIFAR-100에서는 18.3%(WRN-40-10)의 test error를 달성하며 새로운 SOTA 성능을 보였다.
(이는 ResNet-1001보다 4.4% 개선된 수치이다)
따라서
- widening은 일정 범위까지 accuracy를 높인다(너무 많아지면 오히려 낮아졌음, 새로운 regularize 필요)
- Regularize 효과는 width > depth
- widening : 학습 속도 빨라짐 + 더 깊고 heavy한(parameter 많은) network 훈련 가능
이래도 안써?
Dropout in residual blocks
Dropout을 conv 사이에 써서 모든 dataset에서 훈련했다.
최적의 dropout probability를 찾기 위해 cross-validation 방법을 썼고, 그 값은
CIFAR에서 0.3, SVHN에서 0.4이다.
WRN-28-10에 적용한 dropout은 CIFAR-10,100에서 각각 0.11%, 0.4%의 test error를 낮췄다
(median of 5 run + mean/std preprocessing).
다른 ResNet 구조에서도 마찬가지로 error를 낮췄다.
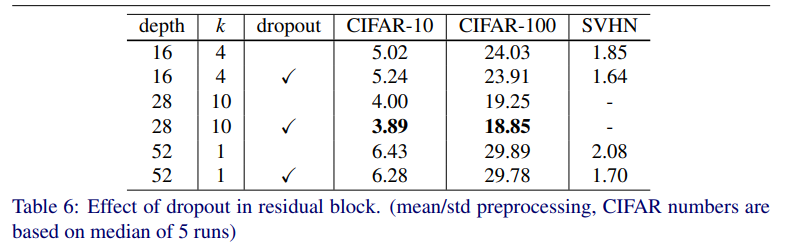
이는 CIFAR-100에서 20%에 근접한 error를 만들어 낸 첫 결과였다.
심지어 heavy data augmentation을 쓴 방법을 능가했다!
WRN-16-4은 CIFAR-10에서 약간의 accuracy drop이 있었다.
이는 parameter 수가 적어서 그런 듯 하다.
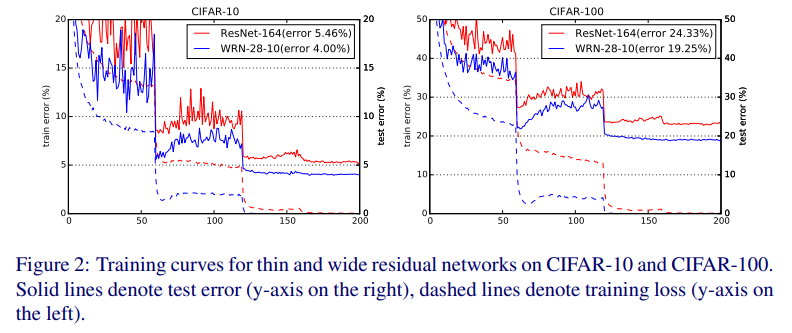
첫 learning rate drop 이후 loss와 val error가 커져, 다음 learning rate drop까지 osciliate하는 문제가 있었다.
원인은 weight decay때문이었는데, 그러나 이걸 낮추면 accuracy가 낮아진다.
Dropout이 이를 해결했다(Fig. 2, 3).
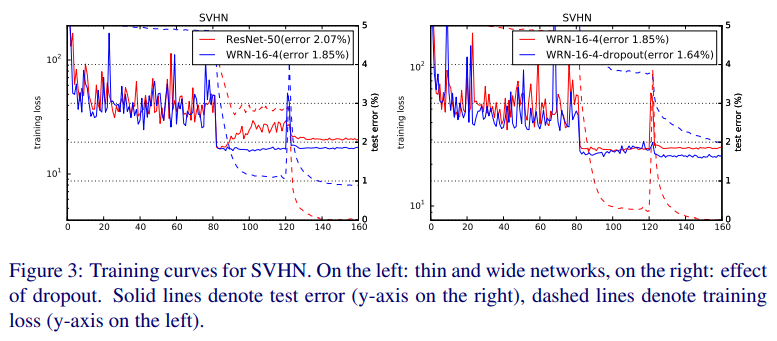
효과는 SVHN에서 더 두드러진다.
이는 아마도 data augmentation을 안해서 BN이 overfit했기에, dropout이 regularizer 효과를 한 듯 하다.
(SVHN은 255로 나누기만 했다, BN은 data가 충분히 많아야 함 그렇지 않다면 overfit하게 만들어 성능 낮아질수도..
참고 : https://www.quora.com/Does-batch-normalization-sometimes-lead-to-an-overfitting-problem)
그 증거로 Fig. 3에서 loss(점선)가 dropout 없이는(붉은선) 거의 안 낮아진다.
결과는 Table 6에 있다.
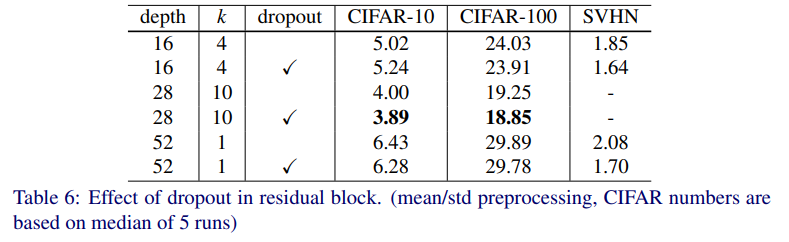
Dropout이 thin, wide 모두에게 도움됨을 보여준다.
Thin 50-layer deep network가 152-layer deep network(with stochastic depth)보다 성능이 더 좋았다.
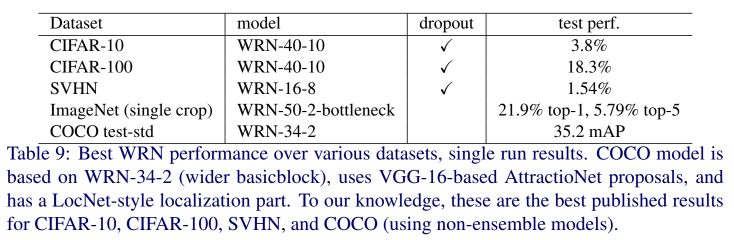
추가로 WRN-16-8을 SVHN에서 dropout을 써서 훈련했는데(Table 9), 1.54%를 달성했다(최고 기록).
Dropout 없이는 1.81%이다.
결과적으로 dropout은 thin, wide network 모두에게 효과적이다.
ImageNet and COCO experiments
ImageNet에 대해 다음과 같은 실험을 진행했다.
처음에는 non-bottleneck ResNet-18,34를 width 1.0->3.0으로 키우며 실험했다.
결과는 Table 7을 참고하자.
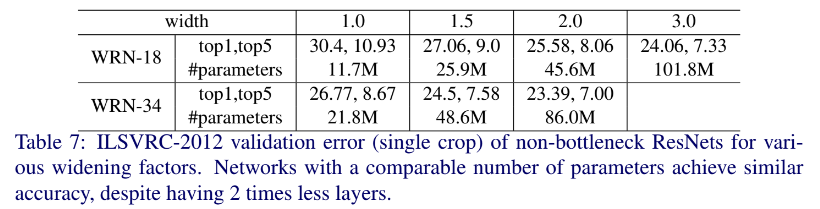
여기서 알 수 있듯이 width가 커지면 accuracy가 커졌다.
비슷한 parameter를 가진 network는 깊이가 달라도 비슷한 결과를 보여줬다.
다만 이러한 network가 parameter가 많지만, bottleneck이 더 좋은 결과를 냈다.
이는 아마도 bottleneck이 ImageNet 분류 작업에 더 잘 맞거나, 복잡한 문제에는 깊은 network가 필요하기 때문일 것이다.
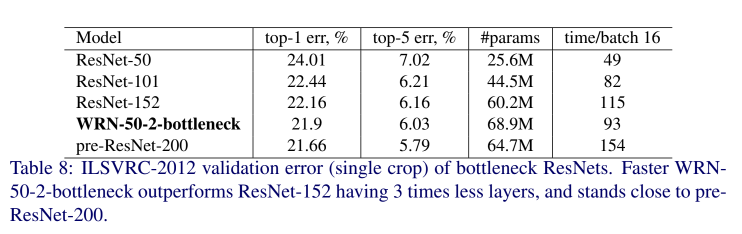
이를 시험하기 위해, ResNet-50을 inner conv3x3 layer width를 넓히며 테스트했다.
(이전에는 basic block, 지금은 bottleneck 넓히기)
WRN-50-2-bottleneck은 ResNet-152보다 3배 더 적은 layer를 가지고 있지만 성능이 더 좋았고 훨씬 빨랐다.
-> 즉 bottleneck 넓히기도 효과가 있음
WRN-50-2-bottleneck은 pre-activation ResNet-200보다 약간 성능은 안 좋았지만 2배 더 빨랐다
(근데 parameter는 더 많았음, 속도 빠른게 장점인듯, Table 8 참고).
일반적으로, CIFAR과 달리 ImageNet은 같은 accuarcy에 도달하기 위해 같은 깊이에서 더 넓은 width가 필요했다.
그러나 컴퓨팅 문제(더 큰 network 테스트하려면 8-GPU 필요)로 50 layer 이상은 하지 않았다.
COCO 2016에는 WRN-34-2(MultiPathNet, LocNet의 combination 사용)을 썼다.
34 layer 뿐이지만 single model로는 SOTA급 성능을 냈다(ResNet-152, Inception-v4 base model보다 나은 성능).
Table 9는 best WRN 성능을 보여준다.
Computational efficiency
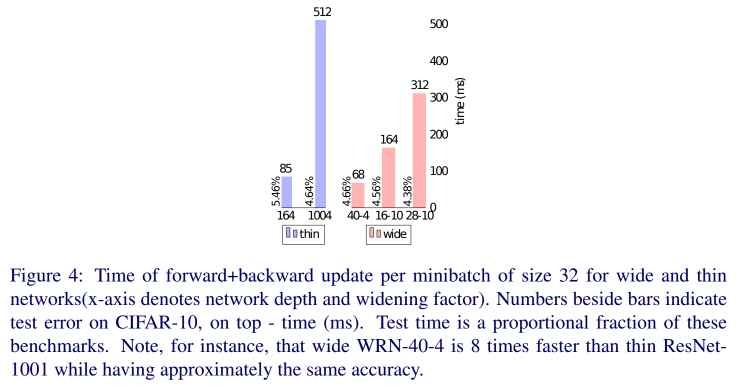
얇고 깊은 residual network는 쌓여있는 구조 때문에 GPU의 성질에 반한다.
Width를 넓히는게 계산 최적화에 더 도움이 되므로 wide residual network가 몇 배 더 빠르다.
Titan X와 cudnn v5를 사용해 forward+backward 계산 속도를 측정했다(minibatch size = 32).
CIFAR에서 WRN-28-10은 ResNet-1001보다 1.6배 빨랐다.
(error rate on CIFAR-10 : WRN-28-2 4.0% / ResNet-1001 4.64%)
ResNet-1001과 같은 성능을 가진 WRN-40-4는 8배 더 빨랐다.
(error rate on CIFAR-10 : WRN-40-4 4.53% / ResNet-1001 4.64%)
Implementation details
학습에 사용한 방법은 다음과 같다.
- SGD(Nesterov, cross-entropy loss)
- Minibatch는 128 size이다.
- Torch 기반이다.
CIFAR
- 처음 learning rate : 0.1, weight decay : 0.0005, dampening : 0, momentum : 0.9)
- Learning rate는 60, 120, 160 epoch에서 0.2로 감소(5로 나눈다는 뜻?)한다.
- 총 200 epoch 학습한다.
SVHN
- 처음 learning rate : 0.01
- Learning rate는 80, 120 epoch에서 0.1로 감소(10으로 나눈다는 뜻?)
- 총 160 epoch 학습한다.
4. Conclusions
Residual network의 width와 dropout의 사용에 대해 연구했다.
이를 통해 CIFAR, SVHN, COCO에서 SOTA 성능을 내는 wide residual network를 만들었고,
ImageNet에서도 큰 발전이 있었다.
CIFAR에서 16 layer로 1000 layer deep network보다 좋은 성능을 내기도 했고,
ImageNet에서는 50 layer로 152 layer deep network보다 좋은 성능을 냈다.
즉, residual network의 핵심은 "깊이"가 아니라 "residual block" 그 자체이다.
또 wide residual network는 학습이 더 빠르다.
Reference
