1. Question
Given a 0-indexed n x n integer matrix grid, return the number of pairs (ri, cj) such that row ri and column cj are equal.
A row and column pair is considered equal if they contain the same elements in the same order (i.e., an equal array).
Example 1:
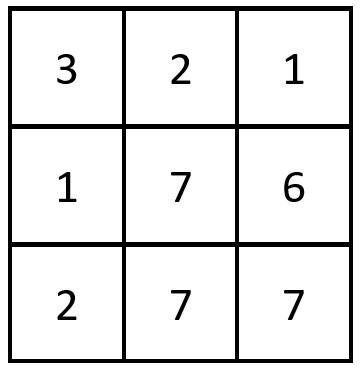
Input: grid = [[3,2,1],[1,7,6],[2,7,7]]
Output: 1
Explanation: There is 1 equal row and column pair:
- (Row 2, Column 1): [2,7,7]Example 2:
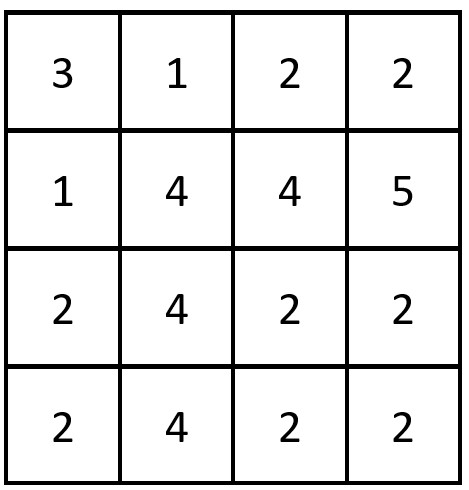
Input: grid = [[3,1,2,2],[1,4,4,5],[2,4,2,2],[2,4,2,2]]
Output: 3
Explanation: There are 3 equal row and column pairs:
- (Row 0, Column 0): [3,1,2,2]
- (Row 2, Column 2): [2,4,2,2]
- (Row 3, Column 2): [2,4,2,2]2. Thoughts
Make a counter for Row and Column.
if same key exists for both Row and Column,
add Row_occurance * Column_occurance.
return sum
3. Tips learned
3.1. Cannot Counter List (Should change to tuple)
If you want to count the occurrences of sublists (as sublists themselves), that's a bit more complex because lists are not hashable and cannot be directly counted by Counter. However, you could convert the inner lists to tuples, which are hashable, and then use Counter:
# Convert each sublist to a tuple so it can be counted
tuple_list = [tuple(lst) for lst in nested_list]
counts = Counter(tuple_list)
print(counts)In this case, Counter will count how many times each tuple (converted from the sublists) appears in your list of lists.
3.2. * (Unpacking Operator)
The asterisk (*) is known as the unpacking operator in Python. When used in the context of a function call, it takes a list, tuple, or other iterable, and 'unpacks' its contents, passing them as individual arguments to the function.
Here's a simple example without zip to illustrate how * works:
def my_function(a, b, c):
print(a, b, c)
my_list = [1, 2, 3]
my_function(*my_list)In the my_function call, *my_list takes the list my_list and unpacks it, so the function is effectively called as my_function(1, 2, 3).
Now, in the context of the zip function:
list_of_lists = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
result = zip(*list_of_lists)What happens here is that *list_of_lists unpacks the outer list, so zip doesn't receive just one argument (the whole list of lists), but each sublist as a separate argument:
result = zip([1, 2, 3], [4, 5, 6], [7, 8, 9])This allows zip to then iterate over these sublists in parallel, taking the first element from each to create the first tuple, the second element from each to create the second tuple, and so on.
When you use the * operator within a function call, it's as if you're removing the outer brackets of the list (or other iterable) and placing each of the item individually into the function call. This is why it's often referred to as "unpacking", because it takes a collection of items and unpacks them into individual arguments.
3.2. Map vs List
List of tuple
rows = [tuple(row) for row in grid]uses a list comprehension to create a list of tuples. This is an eager operation, meaning it processes the entire grid at once, creates the tuple for each row, and stores them all in a list in memory.
Map of tuple
rows = map(tuple, grid) uses the map function to create an iterator that will convert each row to a tuple on demand. This is a lazy operation, which means the tuples are not created until you iterate over rows. If you iterate over rows multiple times, the conversion from list to tuple will happen each time.
Both are valid in Python and can be used interchangeably in many contexts. However, if you are working with very large datasets and want to save memory, map might be a better choice since it doesn't create the entire list of tuples in memory at once. On the other hand, if you need to iterate multiple times over the converted rows or need indexing, a list comprehension would be the better choice.
4. My solution
class Solution:
def equalPairs(self, grid: List[List[int]]) -> int:
pair = 0
rows = [tuple(row) for row in grid]
row_counter = Counter(rows)
column = tuple(zip(*grid))
column_counter = Counter(column)
for tupl in row_counter:
if tupl in column_counter:
pair += row_counter[tupl] * column_counter[tupl]
return pair
78/78 cases passed (405 ms)
Your runtime beats 97.12 % of python3 submissions
Your memory usage beats 8.64 % of python3 submissions (22 MB)5. AI Solution and Improvements
A minor optimization can be to combine the process without needing to create a separate counter for columns:
from collections import Counter
class Solution:
def equalPairs(self, grid: List[List[int]]) -> int:
# Create a counter for rows directly from the grid
rows_counter = Counter(map(tuple, grid))
# Transpose the grid to get the columns as rows, and then create a counter
cols_counter = Counter(map(tuple, zip(*grid)))
# Find the sum of products of matching row and column counts
return sum(rows_counter[row] * cols_counter[row] for row in rows_counter)In this solution:
- We create the
rows_counterby mapping each row to a tuple (tuples can be hashed and used as keys in a Counter). - We transpose the grid with
zip(*grid)to get the columns in the same order as rows and count them. - We iterate over the
rows_counterand for each row, we multiply the count of that row by the count of the corresponding column (if any) and sum these products to get the total number of pairs.
This solution is as Pythonic as it gets, making good use of Counter, map, and zip functions to solve the problem in a concise and readable manner.
