파서(Parser)
파서는 이전 글에서 봤듯이, 데이터(문서 파일)이 왔을 때 이것을 컴퓨터가 이해할 수 있게끔 구조를 재구성하는 단계라고 이해하면 되겠다. 파서는 우선 문서가 오게되면 이 문서를 토큰이라는 유효성이 있는 단어 단위로 나누어 분해하고, 이것을 언어구문규칙에 따라 파싱트리로 재생성한다. 결과적으로는 기계어로 바꾸기 직전단계까지의 과정을 파서가 담당하고 있는 것이다. 파서가 파싱을 통해 파싱트리가 완성되면 파싱트리를 가지고 컴파일러는 기계어로 변환하는 작업에 들어간다. 일종의 컴퓨터에서 전처리기의 역할을 브라우저 파서가 맡고 있다고 생각하면 된다.
파싱 예
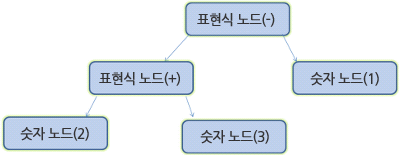
전에 이렇게 정해진 규칙에 따라서2 + 3 - 1을 분해하는 과정을 거쳤다. 이 과정에서 의미 있는 어휘들인 연산자 +,-, 그리고 중간에 들어가는 숫자원소들 단위로 나누어 파싱트리의 노드를 구성했던 것을 기억하고 있을 것이다.
여기에서 사용된 어휘 기준(어휘를 나누는 기준)은
수학에서는 표현식의 정수, 기호단위로 나누어진다
라는 것이다.
사용된 구문 조건에는 여러 개가 있을 텐데,
대표적인 것들을 따져보면 다음과 같다.
- 언어 구문의 기본적인 요소는 표현식, 항, 연산자다.
- 언어에 포함되는 표현식의 수는 제한이 없다.
- 표현식은 '항'뒤에 '연산자' 그 뒤에 또 다른 항이 따르는 형태다.
- 연산자는 더하기 토큰 또는 빼기 토큰이 온다.
- 정수 토큰 또는 하나의 표현식은 항이다.
입력된 값 2+3-1을 분석해 보자.
규칙에 맞는 첫 번째 부분 문자열은 2이다. 규칙 5번에 따르면 이것은 하나의 항이다. 두 번째로 맞는 것은 2+3 인데 이것은 항 뒤에 연산자와 또 다른 항이 등장한다는 세 번째 규칙과도 일치한다. 입력 값의 마지막 부분까지 진행하면 또 다른 일치를 발견할 수 있다. 2+3은 항과 연산자와 항으로 구성된 하나의 새로운 항이라는 것을 알고 있기 때문에 2+3-1은 하나의 표현식이 된다. 2++은 어떤 규칙과도 맞지 않기 때문에 유효하지 않은 입력이 된다.
파서의 종류
파서는 기본적으로 하향식 파서와 상향식 파서가 있다. 하향식 파서는 구문의 상위 구조로부터 일치하는 부분을 찾기 시작하는데 반해 상향식 파서는 낮은 수준에서 점차 높은 수준으로 찾는다.
두 종류의 파서가 예제를 어떻게 파싱하는지 살펴보자. 하향식 파서는 2+3과 같은 표현식에 해당하는 높은 수준의 규칙을 먼저 찾는다. 그 다음 표현식으로 2+3-1을 찾을 것이다. 표현식을 찾는 과정은 일치하는 다른 규칙을 점진적으로 더 찾아내는 방식인데 어쨌거나 가장 높은 수준의 규칙을 먼저 찾는 것으로부터 시작한다.
상향식 파서는 입력 값이 규칙에 맞을 때까지 찾아서 맞는 입력 값을 규칙으로 바꾸는데 이 과정은 입력 값의 끝까지 진행된다. 부분적으로 일치하는 표현식은 파서 스택에 쌓인다.
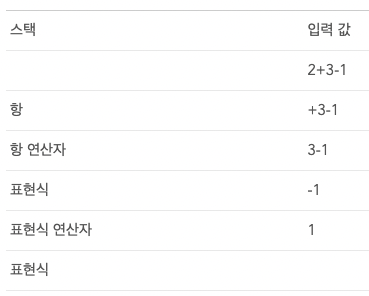
상향식 파서는 입력 값의 오른쪽으로 이동하면서(입력 값의 처음을 가리키는 포인터가 오른쪽으로 이동하는 것을 상상) 구문 규칙으로 갈수록 남는 것이 점차 감소하기 때문에 이동-감소 파서라고 부른다.
파서 자동 생성
파서를 생성해 줄 수 있는 도구를 파서 생성기라고 한다. 언어에 어휘나 구문 규칙 같은 문법을 부여하면 동작하는 파서를 만들어 준다. 파서를 생성하는 것은 파싱에 대한 깊은 이해를 필요로 하고 수동으로 파서를 최적화하여 생성하는 것은 쉬운 일이 아니기 때문에 파서 생성기는 매우 유용하다.
웹킷은 잘 알려진 두 개의 파서 생성기를 사용한다. 어휘 생성을 위한 플렉스(Flex)와 파서 생성을 위한 바이슨(Bison)이다. 렉스(Lex)와 약(Yacc)이라는 이름과 함께 들어본 적이 있을지도 모르겠다. 플렉스는 토큰의 정규 표현식 정의를 포함하는 파일을 입력 받고 바이슨은 BNF 형식의 언어 구문 규칙을 입력 받는다.
Flex(Fast lexical analyzer generator)

HTML 파서
HTML 파서는 HTML마크업을 파싱 트리로 변환한다.
HTML 문법 정의
HTML의 어휘와 문법은 W3C에 의해 명세로 정의되어 있다.
현재 버전은 HTML4와 초안 상태로 진행 중인 HTML5 이다.
문맥 자유 문법이 아님
파싱 일반 소개를 통해 알게 된 것처럼 문법은 BNF와 같은 형식을 이용하여 공식적으로 정의할 수 있다.
안타깝게도 모든 전통적인 파서는 HTML에 적용할 수 없다. 그럼에도 불구하여 지금까지 파싱을 설명한 것은 그냥 재미때문은 아니다. 파싱은 CSS와 자바스크립트를 파싱하는 데 사용된다. HTML은 파서가 요구하는 문맥 자유 문법에 의해 쉽게 정의할 수 없다.
HTML 정의를 위한 공식적인 형식으로 DTD(문서 형식 정의)가 있지만 이것은 문맥 자유 문법이 아니다. 이것은 언뜻 이상하게 보일 수도 있는데 HTML이 XML과 유사하기 때문이다. 사용할 수 있는 XML 파서는 많다. HTML을 XML 형태로 재구성한 XHTML도 있는데 무엇이 큰 차이점일까?
차이점은 HTML이 더 "너그럽다"는 점이다. HTML은 암묵적으로 태그에 대한 생략이 가능하다. 가끔 시작 또는 종료 태그 등을 생략한다. 전반적으로 뻣뻣하고 부담스러운 XML에 반하여 HTML은 "유연한" 문법이다.
이런 작은 차이가 큰 차이를 만들어 낸다. 웹 제작자의 실수를 너그럽게 용서하고 편하게 만들어주는 이것이야 말로 HTML이 인기가 있었던 이유다. 다른 한편으로는 공식적인 문법으로 작성하기 어렵게 만드는 문제가 있다. 정리하자면 HTML은 파싱하기 어렵고 전통적인 구문 분석이 불가능하기 때문에 문맥 자유 문법이 아니라는 것이다. XML 파서로도 파싱하기 쉽지 않다.
DOM
파싱 트리는 DOM 요소와 속성 노드의 트리로서 출력을 위한 출력 트리가 된다. DOM은 문서 객체 모델(Document Object Model)의 준말이다. 이것은 HTML 문서의 객체 표현이고 외부를 향하는 자바스크립트와 같은 HTML 요소의 연결 지점이다. 트리의 최상위 객체는 문서이다.
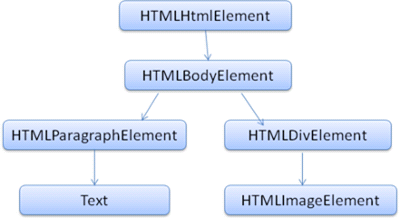
DOM은 마크업과 1:1 관계를 맺는다.
<html> <body> <p>Hello World</p> <div> <img src="example.png"/><div> </div> </body> </html>다음과 같은 마크업이 있다고 했을 때,
이런 방식으로 DOM트리를 구성하게 된다.
HTML과 마찬가지로 DOM은 W3C에 의해 명세가 정해져 있다. 이것은 문서를 다루기 위한 일반적인 명세인데 부분적으로 HTML 요소를 설명하기도 한다. HTML 정의는 www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html에서 찾을 수 있다.
트리가 DOM 노드를 포함한다고 말하는 것은 DOM 접점의 하나를 실행하는 요소를 구성한다는 의미다. 브라우저는 내부의 다른 속성들을 이용하여 이를 구체적으로 실행한다.
