오늘부터 자료구조를 처음으로 접하게되면서 Stack과 Queue를 배웠다. 기초적인 개념으로는 굉장히 쉽게 느껴졌으나, 개념적으로 만날때와 알고리즘으로 만날 때는 전혀 달랐기 때문에 관련 내용을 블로깅하기로 결정했다.
자료구조?
자료구조(Data Structure)라는 것은 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케하는 자료의 조직, 관리, 저장을 의미한다. 더 정확히 말해, 자료 구조는 데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령을 의미한다. wiki dic.
사전적인 내용을 살펴보면 정보 즉, 데이터라는 것을 체계적으로 정리하는 구조적인 방법을 이야기한다고 볼 수 있다. 여기서 정리한다는 의미는 단순히 데이터만을 정리하는 것이 아니라, 데이터 간의 관계 혹은 데이터 값 자체의 분류 기준, 데이터에 적용할 수 있는 함수나 명령까지도 정리하는 것이다. 자료구조라고해서 오늘 공부한 Stack이나 Queue같은 이름붙여진 것들만 있는 것이 아니다.
- JavaScript의 데이터형 자료구조
- number
- string
- boolean
- Null
- undefined
- Symbol
- Object
위와 같은 분류 자체도 데이터를 타입에 따라 단순 데이터형 구조체계를 만든 것이므로 일종의 자료구조라고 볼 수 있다. 간단하게 이야기하면, 컴퓨터 내부에서 데이터에 편리하게 접근하고 변경하기 위해서 데이터를 조작하기 위해 사용되는 사용되는 모든 데이터구조를 자료 구조(Data Structure)라고 한다고 한다고 이해하면 되겠다.
자료구조를 사용하는 이유?
위에서 일부 이야기했지만, 자료구조라는 것은 기본적으로 데이터(자원)을 효율적으로 저장하고 관리해서 메모리를 효율적으로 사용하기 위함이다. 간단하게 예를 들어보자. 만약에 내가 사람들의 정보를 보관하려고 하는데, 그 사람들의 정보를 단순히 변수에 원시자료형인 String을 사용한다고 가정해보자.
const name = "Brian kim"; const age = "29"; const height = "178"; const address = "nowon-gu, seoul"; . . . . (수 천명의 정보를 나열한다고 생각해보자..)
이렇게 작성한다고 가정하면, 한 사람의 정보만을 다루는데도 여러 변수를 계속적으로 사용해야하고, 이러한 데이터들이 나열되어있을 때 인식을 하기도 어렵고 개개인을 구분하는데만 엄청난 시간이 소요될지도 모른다. 관리도 어렵고, 조작도 어려우며 이렇게 맞지 않는 자료구조를 사용하는 것은 메모리에도 엄청난 부담이 된다.
const personData = { 1: { "brianKim", "29", "178", "nowon-gu, seoul" } . . . 2000 : { "danielCho", "27", "169", "dobong-gu, seoul" } } // //2000명의 데이터를 보관하는 Object let personDataIns = { }; // //2000명의 데이터를 인스턴스로 보관하는 Object class PersonData { constructor(name, age, height, address){ this.name = name; this.age = age; this.height = height; this.address = address; } getName(){ return this.name; } setName(newName){ this.name = newName; } } // // 사람 정보를 생성하는 class, 일종의 자료형을 만드는 과정 for(let person in personData){ const personData = new personData({person}); } // 개개의 속성을 숫자로 달아주지 못했다.
이런 식으로 데이터를 적절하게 사용한다면 기존에 사용해야할 메모리보다 훨씬 효율적이고, 데이터를 관리하는데에 있어서도 훨씬 직관적이고 편리하고 빠르게 처리할 수 있게 된다. 이것은 데이터의 성격마다, 처리 방식이 달라지기 때문인데 필요에 따라서는 인스턴스가 아니라, 단순이 객체에 key-value 쌍만으로 보관할 수도 있다. 자료구조를 사용하는 이유는 효율성과 관리편의성때문이다.
자료구조
자료구조에서 수행되는 일
- Search(데이터 탐색)
- Insert(추가)
- Delete(삭제)
- 변경은 데이터 무결성에 문제가 생길 수 있다.
자료구조의 선택 기준
- 자료의 처리 시간 (효율성)
- 자료의 크기(자료 형태나, 보관의 적절성을 판단하기 위해)
- 자료의 활용(탐색) 빈도
- 자료의 갱신(추가/삭제) 정도
- 프로그램의 용이성
자료구조의 분류
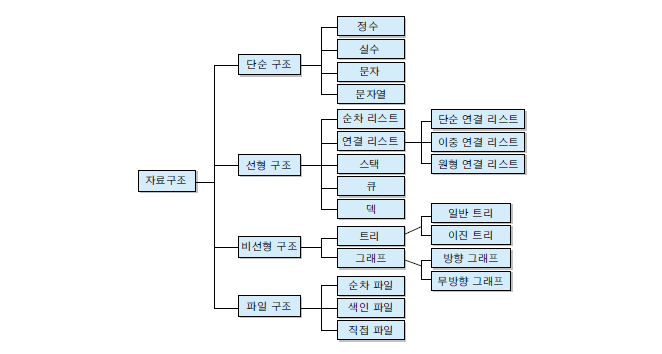
-
단순구조
프로그래밍에서 사용되는 기본 데이터 타입(number, string, object, boolean . . .) -
선형구조
저장되는 자료의 전후관계가 1:1(배열, 리스트, 스택, 큐 등등)
주로 (개념적으로)일렬로 배치되어 관리되는 데이터 구조 -
비선형 구조
데이터 항목 사이의 관계가 1:n 또는 n:m
데이터가 (개념적으로)트리형태로 구성되어 관리되는 데이터 구조 -
파일구조
서로 관련된 필드들로 구성된 레코드의 집합인 파일에 대한 자료구조
자료구조와 알고리즘의 관계
자료구조를 구현하기 위해서는 알고리즘이 필요하다.
- 자료구조 자체의 구현 알고리즘 : 자료를 조작하는 규칙을 논리적으로 구현하는 방법
(자료구조 메서드 알고리즘 : 데이터를 탐색하고 추가하고 삭제하는 방법적인 알고리즘)
쉽게 간단한 예를 들어보면, class를 정의해서 사용하는 것부터가 자료 구조를 구현하는 알고리즘이 된다. - 자료구조를 이용한 알고리즘 : 자료구조 자체를 활용해서 어떤 주어진 문제를 해결하기 위한 알고리즘
Queue?! Stack!?
어떤 데이터의 구체적인 구현 방식을 생략하고, 데이터의 추상적 형태와 그 데이터를 다루는 방법만을 정해놓은 것을 가지고 ADT(Abstract Data Type) 혹은 추상자료형이라고 한다. 큐도 스택도 대표적인 ADT다. 어떤 데이터 형이 물리적으로 있는 것은 아니지만, 추상적으로 그러한 형태로 데이터 구조를 만들어 사용하는 것이다. 그렇기 때문에 꼭 반드시 큐를 위한 혹은 스택을 위해 구현된 코드가 아니라 필요에 따라서 부분적으로 생략하거나 필요한 기능만을 살려서 구현해서 사용할 수 있는 것이다.
Queue(큐!)
- 데이터를 집어넣을 수 있는 선형(Linear:추상적인 형태가 선형적 구조)인 자료형이다.
- 먼저 집어넣은 데이터가 먼저 나온다. input과 output이 나누어져있고, 들어온 순서대로 데이터를 가공하는 데이터 구조다. 줄여서 FIFO(First In First Out)이라고 부른다.
- 데이터를 집어넣는 enqueue, 데이터를 추출하는 dequeue 등의 작업을 할 수 있다.
큐(Queue)는 Gap(차이)를 극복하기 위한 ADT다.
단순히 데이터가 들어온 순서대로 처리된다는 것에 의미를 두면, Queue의 의미가 퇴색될 것만 같다. 그것보다는 데이터를 쌓아두고 들어온 순서대로 "내보낸다"라는 것에 더 큰 의미를 두어야할 것 같다. 컴퓨터 내부에 대해서는 잘모르지만, 세상에는 속도의 차이라는 것이 있다. 단순히 자동차의 속도차이나 그런 것들이 아니라, 빠르고 느린 두 요소간의 차이를 극복한다는 개념에서의 속도 차이다.
예를 들어, 인쇄하는 과정을 볼 수 있는데 CPU는 다른 output device들보다도 훨씬 처리속도가 빠르다. 그런데 프린터기는 1ms안에 프린터를 뽑아낼 수 있는 그런 엄청난 기계가 아니다. 그러므로 둘 간에는 처리 속도의 차이가 생긴다. 이를 극복할 방법으로 인쇄 대기 Queue에 이미 CPU가 인쇄문서로 만들어둔 파일들을 저장해둔다. 이후 프린터는 대기열에 있는 인쇄문서들을 차례로 인쇄하게된다.
JavaScript에서는 배열을 이용해서 간단하게 큐를 구현할 수 있다.
예제코드
class Queue { constructor() { this._arr = []; } enqueue(item) { this._arr.push(item); } dequeue() { return this._arr.shift(); } } const queue = new Queue(); queue.enqueue(1); queue.enqueue(2); queue.enqueue(3); queue.dequeue(); // 1
큐는 주로 순서대로 처리해야하는 작업을 임시로 저장해두는 버퍼(Buffer)로 많이 사용된다.
Stack(스택!)
- 스택은 데이터를 집어넣을 수 있는 선형(linear:추상적인 형태가 선형적인 구조) 자료형이다.
- 나중에 집어넣은 데이터가 먼저 나온다. 이 특징을 줄여서 LIFO(Last In First Out)이라고 부른다.
- 데이터를 집어넣는 push, 데이터를 추출하는 pop, 맨 나중에 집어넣은 데이터를 확인하는 peek등의 메소드를 사용할 수 있다.
스택이라는 구조는 나중에 들어온 데이터를 먼저 꺼낼 수 있는데, 가장 쉽게 생각할 수 있는건 포토샵의 ctrl + Z였다. 방금한 작업을 되돌리는 기능인데, 순서대로 보관되고 최신 것부터 접근할 수 있는 스택이라는 구조는 주로 히스토리를 되돌리거나 저장해두는 것에 적합한 데이터 구조라는 것을 알 수 있다. 데이터를 쌓아둔다는 점에서 Queue와 비슷하지만, output을 보면 가장 최근 것부터 하나씩 꺼내어 볼 수 있다는 점에서 히스토리를 사용하는 기능이나 데이터에 사용하기 적합해보인다.
스택(Stack)은 히스토리를 기록하기 위한 ADT다.
JavaScript 배열을 이용해서 간단하게 스택을 구현할 수 있다.
class Stack { constructor() { this._arr = []; } push(item) { this._arr.push(item); } pop() { return this._arr.pop(); } peek() { return this._arr[this._arr.length - 1]; } } const stack = new Stack(); stack.push(1); stack.push(2); stack.push(3); stack.pop(); // 3
마치며
간단하게 자료구조의 개념과 알고리즘 그리고, Queue와 Stack에 대해서 정리해봤다. 지금까지는 데이터가 들어가고 나오는 과정에 너무 집착해서 정확히 어떻게 사용해야할지 몰랐지만, 그 과정이 쓰이는 목적이나 사용처같은 것을 좀더 상세히 읽고 자료구조나 알고리즘에 대해서 간단하게 정리해보면서 80%정도는 이해한 것 같다. 이제는 이걸 알고리즘에서 실제로 어떻게 활용하는지 예제문제를 풀어보며 실습해보는게 좋을 것 같다.
