
devport를 시작하며 api 서버를 어떤 언어와 프레임워크 조합으로 개발을 할지 꽤 고민했던 것 같습니다. API 서버 개발을 전적으로 AI에 맡겨 바이브 코딩 집중적으로 진행해 좀 더 빨리 프로덕트를 만드는 것에 집중을 하자면 TypeScript기반의 Next.js로 아마 진행했을 것 같습니다. 만약 좀 더 실험을 해보자는 마음이 강했다면 Go를 기반으로 한 서버 개발을 진행했을 것 같습니다. 하지만 여기서도 제가 자바를 선택 한 이유는 최근 클라우드와 devops쪽에 집중하면서 자프링 스택의 개발과 공부를 소홀히 한 것 같은 생각이 들어 복습이 필요하다고 느꼇습니다. 또 다른 한가지의 이유는 Spring Boot 4.0.0 릴리즈 노트에서 제 눈의 가장 띄었던 강화된 GraalVM과 AOT(Ahead-of-time)컴파일 지원이었습니다.
GraalVM?
GraalVM은 Java 애플리케이션의 성능을 높이면서 동시에 더 적은 리소스를 사용하기 위해 Oracle Labs에서 시작된 프로젝트입니다.
그렇다면 성능을 높이면서도 리소스 사용량을 줄일 수 있는 방법은 무엇일까요?
GraalVM은 이 문제를 해결하기 위해, 기존처럼 JVM 위에서 코드를 실행하는 대신 애플리케이션을 네이티브 binary로 직접 컴파일하는 AOT(Ahead-of-Time) 컴파일 방식을 사용합니다.
이 글에서는 이러한 Java의 Native Image가 기존 Java 애플리케이션의 실행 방식과 어떤 차이가 있는지, 그리고 어떤 트레이드오프가 존재하는지 살펴보겠습니다. 먼저 이를 이해하기 위해 먼저 기존 JVM의 JIT(Just-In-Time) 컴파일 방식과 비교해보고, JVM과 Native Image가 각각 어떤 특징을 가지는지 정리해 보겠습니다.
또한 devport에 이를 실제로 적용하면서 제가 직접 겪었던 경험을 함께 공유하는 시간을 가지도록 하겠습니다.
JVM vs Native Image
우선 컴파일 방식의 차이점을 들여다 보기전에 기존의 자바 에플리케이션의 JVM과 GraalVM의 Native Image의 작동 방식을 먼저 살펴보겠습니다.
JVM의 구조
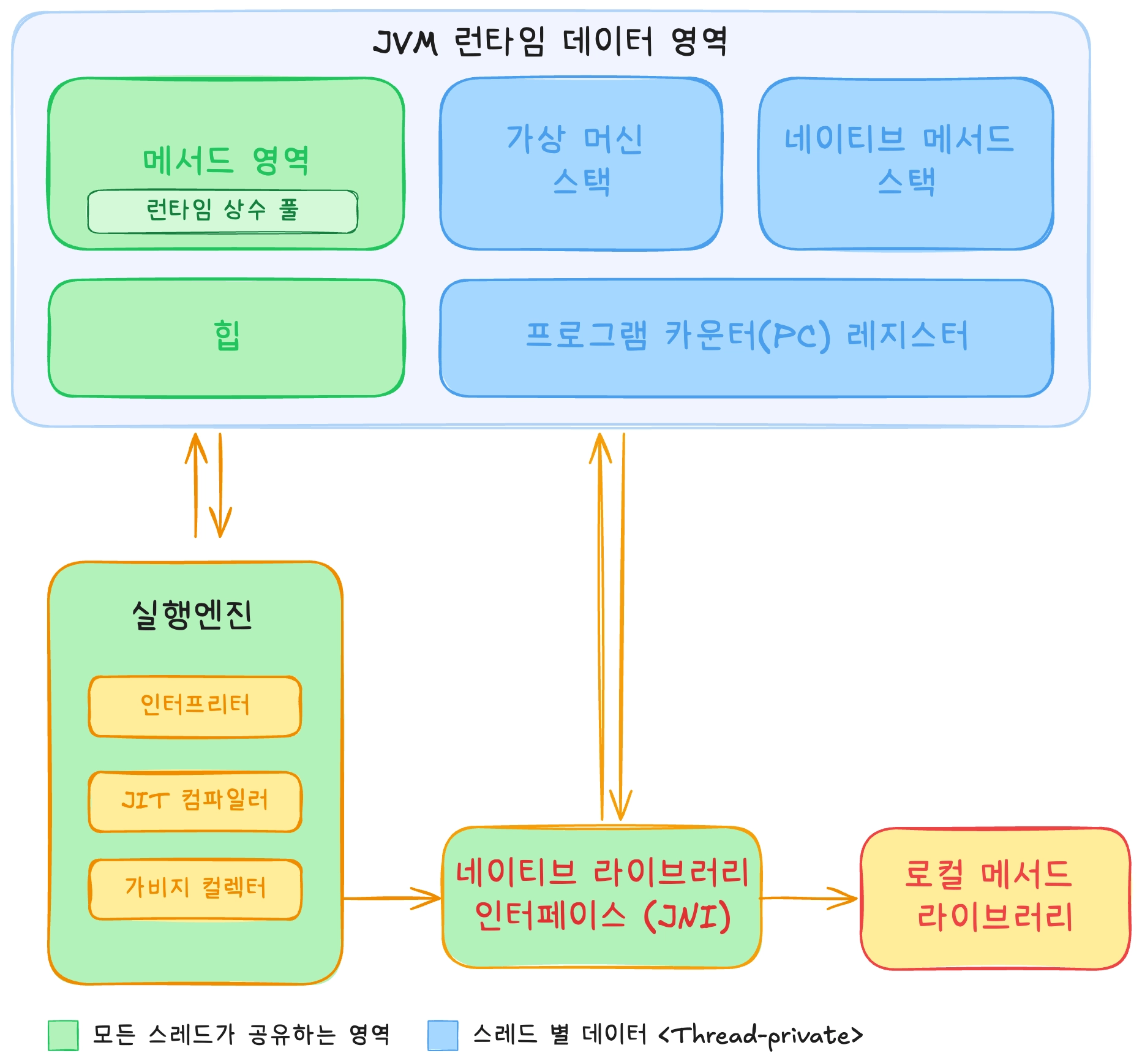
기존 자바 application은 빌드 후 jar 파일들을 생성합니다. 이때 앱을 실행하면 JVM이 bytecode로 된 .class 파일들을 실행하기 위해서 JVM 프로세스를 시작하고 OS로부터 메모리를 할당받아서 JVM 런타임 데이터 영역이 만들어 집니다. 이후 실행엔진이 메서드 영역에서 바이트코드를 읽어오고 이를 인터프리터로 실행하거나 JIT 컴파일러로 컴파일을 진행하며 기계어로 변환해 애플리케이션을 실행합니다. 이후 힙에 객체를 만들고 VM 스택에 프레임을 쌓고, PC 레지스터로 다음 실행 위치를 추적하며 이 작업을 반복적으로 실행하는 것이 일반적인 JVM 구조입니다.
JVM 실행 엔진은 인터프리터와 JIT 컴파일러로 나뉩니다. 앱이 시작되면 인터프리터가 바이트코드를 한 줄씩 해석해 실행하고, 그동안 JVM은 뒤에서 메서드 호출 빈도 같은 프로파일링 데이터를 모읍니다. 특정 코드가 자주 실행돼 hot code로 판정되면 JIT이 이를 기계어로 컴파일하고, 수집된 프로파일을 바탕으로 최적화 작업를 진행합니다. 덕분에 충분히 워밍업된 JVM은 뛰어난 피크 성능을 보여주지만, 이 모든 과정이 런타임에 일어나기 때문에 시작은 느리고, 피크에 도달하기까지 시간이 걸린다는 비용을 떠안게 됩니다.
이런 복잡한 구조로 자바가 실행되는 이유는 바로 자바의 근간인 WORA(Write Once, Run Anywhere) 철학 때문입니다. 플랫폼에 종속되지 않은 바이트코드를 만들고, 각 OS/CPU에 맞는 기계어를 JVM이 해석하여 변환하는 방식으로 "한 번 작성하면 어디서든 실행된다"를 구현한 것이죠.
클라우드 환경에서 JVM이 가지는 단점
전통적인 Java 애플리케이션은 이런 JVM의 특성 때문에 클라우드 환경에서 다른 프레임워크보다 상당한 불리한 조건에 있습니다. 그 이유는 클라우드에서 비용의 핵심은 결국 메모리와 CPU 사용량이고 컨테이너 기반의 운영환경이 대부분인 대 쿠버네티스의 세계에서는 이런 Java 애플리케이션을 마이크로서비스로 배포한다는 것이 꽤 비효율적인 선택이기 때문입니다.
그럼 GraalVM Native Image는 무엇이 다른가?
GraalVM의 Native Image는 이름 그대로 자바 애플리케이션을 빌드 시점에 자바 코드를 통째로 네이티브 바이너리로 컴파일해 버리는 기술입니다. 바이트코드의 중간계층 사라져 JVM이 필요한 JIT이나 인터프리터 컴파일러가 실행시 필요가 없게 되는 것입니다.
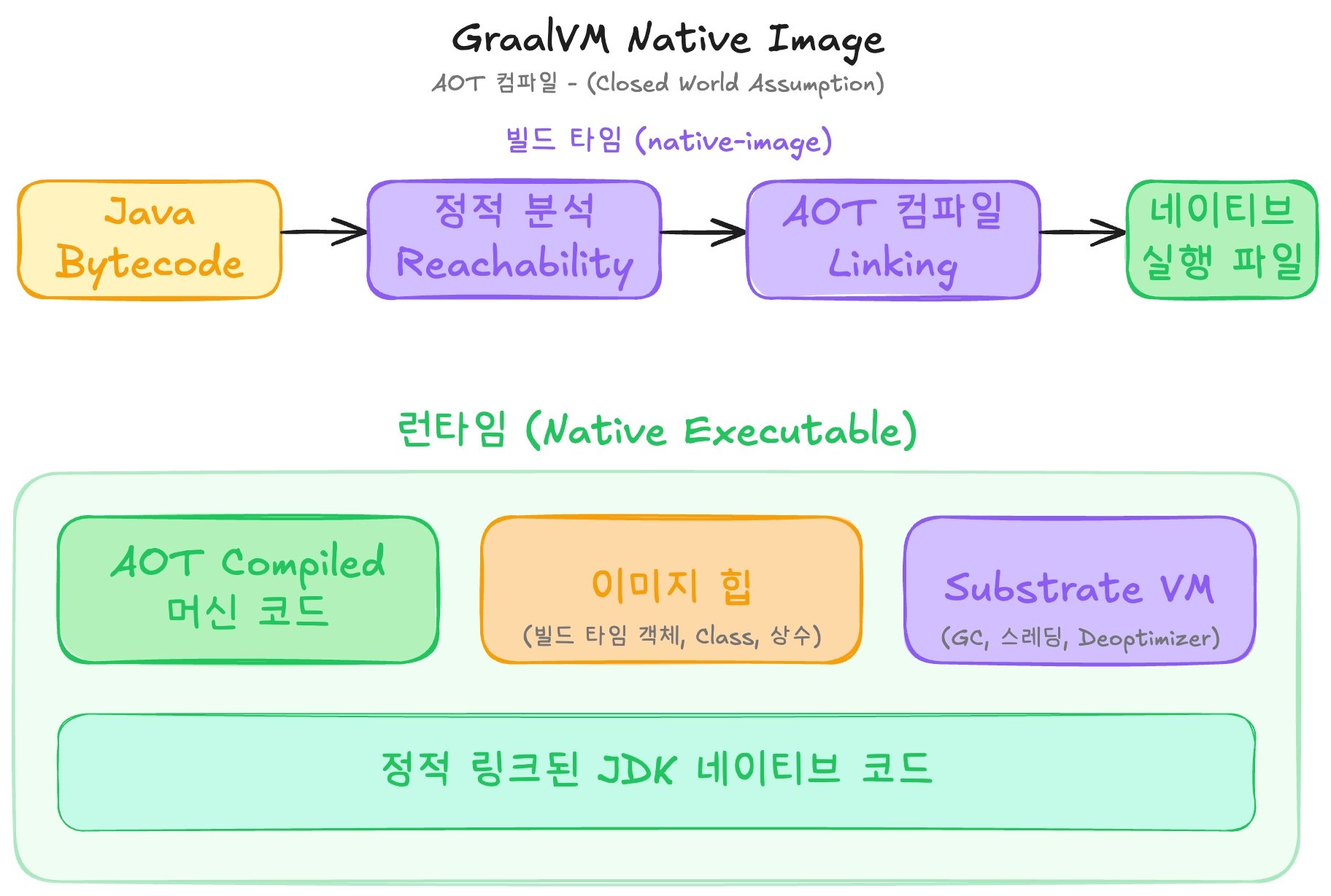
GraalVM의 Native Image는 이름 그대로 자바 애플리케이션을 빌드 시점에 네이티브 바이너리로 통째로 컴파일해 버리는 기술입니다. JVM에서는 빌드와 실행이 느슨하게 분리되어 있습니다. javac가 .java를 .class로 바꾸고, 이 바이트코드가 런타임에 JVM에 의해 로드되고 해석되고 JIT로 다시 컴파일되는 방식입니다. 반면 Native Image는 이 흐름을 근본적으로 뒤집어, 원래 런타임에 해야 할 일들의 상당 부분을 빌드 시점으로 끌어올립니다.
또한 GraalVM 프로젝트에는 가장 핵심적인 역할을 하는 Substrate VM이 있습니다. Substrate VM은 HotSpot 같은 전통적인 JVM을 대체하는 아주 작은 런타임 환경으로, 자체적인 예외 처리, 스레드 관리, 메모리 관리, 가비지 컬렉션, JNI 접근 메커니즘 등을 갖추고 있습니다. GraalVM은 이 Substrate VM과 사용자 프로그램, 필요한 JDK 클래스들을 하나로 묶어 단일 네이티브 실행 파일, 즉 Native Image를 생성합니다. 결국 "JVM 없이 실행되는 자바"라고 부르는 것은 정확히 말하면 "JVM 대신 Substrate VM 위에서 실행되는 자바"인 셈입니다.
Native Image 빌드 파이프라인
native-image 툴이 호출되면 내부적으로는 상당히 복잡한 빌드 파이프라인이 돌아갑니다. 단계별로 정리해 보면 다음과 같습니다.
1) 클래스 로딩과 포인터 분석(Points-to Analysis)
애플리케이션의 메인 엔트리에서 시작해 참조되는 모든 클래스, 메서드, 필드를 수집합니다. 이 과정에서 GraalVM은 각 변수와 필드가 실제로 어떤 타입의 객체를 가리킬 수 있는지를 추적하여 프로그램 전체의 타입 흐름 그래프를 만듭니다. 이 그래프가 이후 모든 최적화의 기반이 됩니다.
2) 도달 가능성 분석(Reachability)
포인터 분석 결과를 바탕으로 "엔트리 포인트로부터 실제로 도달 가능한 코드가 무엇인가"를 계산합니다. 도달할 수 없다고 판단된 클래스, 메서드, 필드는 최종 바이너리에 아예 포함되지 않습니다. JVM은 "이 코드가 실행될 수도 있다"는 가정 아래 클래스패스 전체를 로드하지만, Native Image는 "이 코드는 절대로 실행되지 않을 것이다"라고 증명할 수 있는 부분을 과감히 잘라냅니다.
3) 빌드타임 초기화와 이미지 힙 스냅숏(Image Heap Snapshot)
Substrate VM은 애플리케이션의 일부 클래스 초기화(static initializer)를 빌드 시점에 실제로 실행한 뒤, 그 결과로 만들어진 객체 그래프(= 힙 상태)를 그대로 스냅숏으로 찍어 이미지에 박아 넣습니다. 런타임에 이 바이너리가 실행되면 스냅숏이 그대로 메모리에 매핑되고, 앱은 이미 초기화가 끝난 상태에서 곧바로 비즈니스 로직으로 진입할 수 있습니다. 자바 가상 머신이 수행하던 초기화 과정을 건너뛰고 프로그램을 곧바로 실행하여 초기 구동 시간을 획기적으로 줄인 원리가 바로 이 이미지 힙 스냅숏에 있습니다.
4) AOT 컴파일과 네이티브 링킹
도달 가능한 모든 메서드는 빌드 시점에 Graal 컴파일러가 직접 기계어로 컴파일합니다. 이때 정적 분석으로 확보한 타입 정보 덕분에 가상 메서드 호출(virtual call)을 직접 호출(direct call)로 치환하는 등 공격적인 최적화가 광범위하게 이루어집니다. 생성된 기계어, 이미지 힙 스냅숏, Substrate VM 런타임 코드는 하나의 파일로 링킹되어 우리가 실행할 수 있는 단일 바이너리가 됩니다. 런타임에 이 바이너리가 하는 일은 본질적으로 이미 초기화된 힙을 메모리에 올리고, 이미 컴파일된 기계어를 실행하는 것 입니다.
Native Image의 장점
Native Image는 결국 빌드타임에서 도달 가능한 코드, 정적 분석, 링킹을 통해 JVM이 거쳐야하는 워밍업 단계나 JIT 컴파일러가 필요없게 되는것입니다. 바이너리, 즉 기계어로 이미 컴파일이 되었기 때문에 애플리케이션 start time이 매우 빠르고 즉시 피크 성능에 도달하게 되는 것입니다. 그 결과로 CPU 사용량과 메모리가 엄청 단축 됩니다.
얼마나 단축되는지 그럼 직접 devport.kr의 백엔드 코드로 직접 확인을 해보겠습니다.
해당 수치는 macbook pro m4 환경에서 2CPU, 2GB 메모리를 할당한 docker desktop에서 진행했습니다.
시작 시간 (Start Time)
JVM

Native Image

CPU/Memory
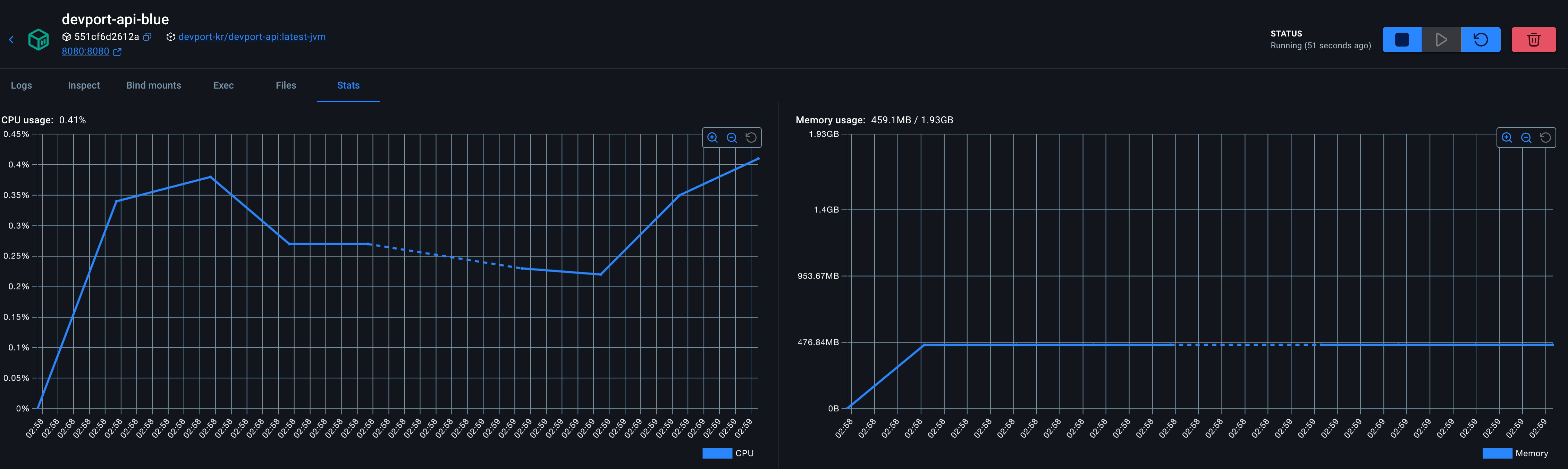
JVM
Native Image
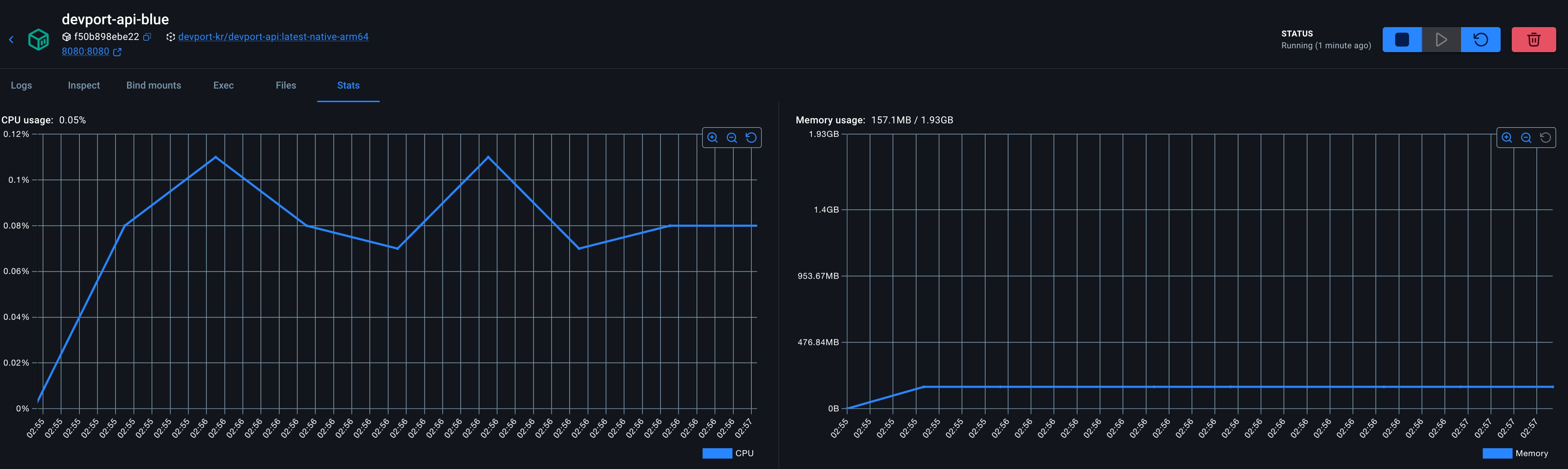
- 시작시간 4.504초 → 0.457초
- CPU 사용량 0.4코어 → 0.1코어
- 메모리 사용량 476mb →230mb
시작 시간은 약 10배 단축되었고, idle 상태의 메모리 사용량은 476MB에서 230MB로 약 52% 줄었으며, CPU 사용량은 0.4 코어에서 0.1 코어로 떨어졌습니다. 물론 해당 측정은 idle 상태의 리소스와 콜드 스타트에 한정된 것이며, 충분히 예열된 JVM의 피크 처리량은 별도의 이야기라고 하실 수 있습니다. 하지만 최근 GraalVM의 공식 문서에 따르면 GraalVM 25 기준으로 PGO(Profile-Guided Optimization)와 G1 가비지 컬렉터를 결합하면 JVM 대비 동등하거나 더 나은 처리량과 지연 시간을 달성할 수 있다고 합니다.— 이에 대해서는 실제 부하 테스트를 진행해 비교하는 시간을 다른 글에서 가지도록 하겠습니다.
클라우드 환경에서 GraalVM이 해결해주는 JVM의 문제점
압도적으로 빠른 시작 시간.
앞서 설명한 이미지 힙 스냅숏 덕분에 JVM 워밍업 단계가 사실상 사라집니다. Native Image로 만든 바이너리는 수십 밀리초 단위로 기동이 끝납니다. 쿠버네티스의 HPA가 부하를 감지하고 파드를 스케일 아웃할 때, 새 파드가 준비되기까지의 시간이 곧 SLO 위반 시간으로 이어집니다. 시작 시간이 짧다는 것은 곧 스케일 아웃 속도가 빨라진다는 의미이고, 이는 마이크로서비스와 서버리스 환경에서 엄청난 우의를 가집니다.
둘째, 낮은 메모리 풋프린트. JVM은 HotSpot 코드 캐시, JIT 컴파일러, 메타스페이스, 여러 내부 데이터 구조를 모두 메모리에 올려 두고 돌아갑니다. 반면 Native Image는 JIT이 필요 없고 도달 불가능한 코드는 이미 잘려 나갔기 때문에, 같은 애플리케이션을 훨씬 적은 메모리로 띄울 수 있습니다. 쿠버네티스 파드 관점에서 이 차이는 그대로 비용으로 연결됩니다. 하나의 노드에 띄울 수 있는 파드 밀도가 올라가고, requests.memory를 더 타이트하게 잡을 수 있으며, 결과적으로 비용이 줄어듭니다. devport.kr처럼 저 같은 가난한 개인이 운영 비용을 직접 감당해야 하는 프로젝트에서는 이 부분이 가장 크게 다가왔습니다.
그렇다면 CPU 사용량, 메모리, 시작 시간, 성능 심지어 컨테이너 이미지 풋프린트까지 모두 GraalVM Native Image가 우수하다면, 왜 사람들은 JVM을 계속 쓸까요?
Tradeoffs
물론 Native Image는 만능 해결책이 절대 아닙니다.
1초 이하의 시작시간, 10분 이상의 빌드 시간
자프링으로 개발을 하다보면 빌드를 하고, application을 실행시키며 잘 작동하는지 확인을 하며 개발하는게 일상이지만, Native Image는 빌드가 10분 이상 걸리다 보니 사실상 이런 개발 방식은 불가능합니다. 결국 개발 환경에서는 JVM을 사용하고 배포시에만 네이티브로 컴파일하는 이중 워크플로우가 현실적입니다. 저 또한 이런 방식으로 개발을 진행했습니다. 또한 GraalVM으로 Native Compile을 하기 위해서는 경험상 최소한 16gb의 램을 GraalVM에 할당해야합니다. 그렇지 않으면 저처럼 Macbook이 미친듯이 스와핑을 시도하는 것을 경험하실 수 있습니다. 저는 결국 개발은 로컬에서 JVM으로, 기능 단위로 Github Actions의 무료 러너로 이미지 빌드, 그리고 배포. 이런식으로 진행을 했습니다.
Closed-World에서 오는 리플렉션/프록시/리소스 문제
앞서 말했듯 GraalVM은 컴파일 시점에 도달 가능한 코드만 바이너리에 담습니다. 그런데 자바 생태계는 오랫동안 리플렉션, 동적 프록시, 런타임 클래스패스 탐색에 의존해 발전해 왔고 Spring 역시 빈 생성, AOP, 직렬화/역직렬화, ORM의 지연 로딩, 프록시 객체 등 수많은 곳에서 이 기술들이 사용됩니다. Native Image는 이런 동적 동작들을 스스로 발견할 수 없기 때문에, 직접 리플렉션 힌트(reachability metadata) 를 제공해 주어야 합니다. Spring Boot 3부터는 프레임워크 차원에서 AOT 엔진이 상당 부분을 자동으로 처리해 주지만, 네이티브 이미지를 고려하지 않은 라이브러리를 쓰게 되면 결국 직접 RuntimeHintsRegistrar를 구현하거나 reflect-config.json을 작성해야 하는 상황이 필요할 것으로 예상됩니다.
Native Image 적용시 주의해야 할 점
실제로 devport 백엔드를 Native Image로 빌드하면서 제가 부딪힌 문제들을 해결하는 데 생각보다 긴 시간이 걸렸습니다. 그중 특히 기억에 남는 두 가지를 공유해보겠습니다.
1. Tracing Agent가 만든 메타데이터가 조용히 무시되던 문제
Native Image를 빌드할 때 리플렉션, 프록시, 리소스 접근 같은 동적 동작들을 GraalVM에 알려주려면 reachability-metadata.json 파일이 필요합니다. 이 파일은 직접 작성할 수도 있지만 현실적으로 불가능합니다.
다행히 GraalVM은 이를 위해 tracing agent라는 도구를 제공합니다. JVM 위에서 애플리케이션을 실행하면서 모든 리플렉션/프록시/리소스 접근을 캡처해 메타데이터 파일로 자동 생성해주는 도구입니다.
java -agentlib:native-image-agent=config-output-dir=src/main/resources/META-INF/native-image \
-jar build/libs/devport-api.jar이 상태로 애플리케이션을 띄우고, 실제 트래픽(로그인, API 요청, 캐시 적중, JWT 발급 등)을 모두 요청한 뒤 종료하면 지정한 디렉토리에 reachability-metadata.json이 생성됩니다. devport의 경우 약 660KB, 수천 개의 항목이 찍혔습니다.
그런데 정작 Native Image를 빌드하면 여전히 똑같은 리플렉션 에러들이 쏟아졌습니다. 분명히 메타데이터는 존재하는데, 빌더가 이를 전혀 참조하지 않는 것처럼 동작했습니다.
원인을 찾는 데 정말 오랜 시간이 걸렸습니다. 결론부터 말하면 경로가 잘못되어 있었습니다. tracing agent는 src/main/resources/META-INF/native-image/ 바로 아래에 파일을 떨궈줬지만, GraalVM Native Image Builder는 이 경로를 그냥 읽어주지 않습니다. 다음과 같이 <groupId>/<artifactId> 하위 디렉토리 안에 있어야 자동으로 인식합니다.
src/main/resources/
└── META-INF/
└── native-image/
└── kr.devport.backend/ # groupId
└── devport-api-agent/ # artifactId (임의 식별자)
└── reachability-metadata.json`이 규칙은 GraalVM이 같은 아티팩트의 메타데이터가 여러 라이브러리에서 충돌하는 것을 방지하기 위한 네임스페이스 목적입니다. 하지만 tracing agent는 기본적으로 이 구조를 자동으로 만들어주지 않기 때문에, 직접 옮겨주거나 agent 실행 시 출력 경로를 명시해야 합니다.
java -agentlib:native-image-agent=config-output-dir=src/main/resources/META-INF/native-image/kr.devport.backend/devport-api-agent \
-jar build/libs/devport-api.jar만약 이 글을 보시는 분이 tracing agent를 사용 중인데 빌드가 리플렉션 에러로 실패하고 있다면, 제일 먼저 메타데이터 파일이 올바른 groupId/artifactId 하위 경로에 있는지 확인해 보시길 권합니다.
한 가지 더 덧붙이자면, tracing agent가 만들어준 메타데이터를 무조건 신뢰하면 안 됩니다. agent는 JVM에서 실행되는 동안 발생하는 모든 동적 동작을 캡처하는데, 이 중 일부는 네이티브 이미지에서 의도적으로 배제되어야 하는 것들입니다. 예를 들어 Spring ORM은 Hibernate의 ByteBuddy BytecodeProvider를 Native Image에서 로드하지 않도록 내부적으로 exclusion 설정을 가지고 있는데, tracing agent는 JVM에서는 이 provider가 정상 로드되는 것을 보고 META-INF/services/org.hibernate.bytecode.spi.BytecodeProvider를 리소스 glob으로 메타데이터에 추가해버립니다. 그러면 Spring이 이미 해둔 exclusion을 애플리케이션 메타데이터가 덮어써버리면서, 런타임에 ServiceLoader가 ByteBuddy를 찾으려다 에러가 나게 됩니다. tracing agent 실행 후에는 출력된 메타데이터를 한 번 훑어보면서 META-INF/services/ 관련 glob들을 AI를 적극적으로 활용하며 검토해보시길 추천드립니다.
2. SpEL T() 표현식이 AOT에서 무너지는 문제
devport 백엔드에서는 캐시 키를 일관성 있게 관리하려고 CacheKeyFactory라는 static 유틸리티 클래스를 만들어 @Cacheable의 키 생성에 사용하고 있었습니다. 코드는 대략 이런 모양이었습니다.
@Cacheable(
value = CacheNames.WIKI_DETAIL,
key = "T(kr.devport.api.domain.common.cache.CacheKeyFactory).wikiDetail(#slug)"
)
public WikiDetailResponse getWikiDetail(String slug) { ... }SpEL의 T(...) 표현식은 지정된 타입의 static 메서드를 런타임에 호출할 수 있게 해주는 문법입니다. JVM에서는 아주 깔끔하게 동작하고, 실제로 테스트 환경에서는 아무 문제가 없었습니다.
그런데 Native Image에서 이 엔드포인트를 처음 호출하는 순간 다음과 같은 에러를 만났습니다.
org.springframework.expression.spel.SpelEvaluationException: EL1005E: Type cannot be found 'kr.devport.api.domain.common.cache.CacheKeyFactory'
분명히 클래스는 존재하는데, SpEL이 "타입을 찾을 수 없다"고 말하는 상황이었습니다. 원인을 추적해보면 결국 앞서 설명한 Closed-World Assumption으로 이어집니다. T(...) 는 내부적으로 Class.forName("kr.devport.api.domain.common.cache.CacheKeyFactory")를 호출하는데, 이 문자열은 컴파일 시점의 정적 분석으로는 어떤 클래스가 로드될지 예측할 수 없는 동적 참조입니다. GraalVM 입장에서는 이 클래스가 "도달 가능하다"는 증거가 없으니 바이너리에 포함시키지 않거나, 포함되어 있어도 Class.forName으로 찾을 수 있도록 등록해주지 않습니다.
결국 CacheKeyFactory를 static 유틸리티에서 Spring Bean으로 바꾸고, SpEL에서는 T() 대신 bean reference (@beanName) 문법으로 호출하도록 변경했습니다.
// Before (Native Image에서 실패)
@Cacheable(
value = CacheNames.WIKI_DETAIL,
key = "T(kr.devport.api.domain.common.cache.CacheKeyFactory).wikiDetail(#slug)"
)
// After (Native Image에서 동작)
@Cacheable(
value = CacheNames.WIKI_DETAIL,
key = "@cacheKeyFactory.wikiDetail(#slug)"
)결과적으로 Native Image를 쓸 생각이라면 T(...) 같은 동적 타입 참조는 처음부터 피하는 것이 좋을 것 같습니다...
회고
이 외에도 사실 정말 많은 트러블슈팅이 있었습니다. 앞의 두 가지가 제게 가장 기억에 남지만, 실제로 Native Image를 적용하다 보면 이것 말고도 수많은 에러를 만나게 될 거라고 생각합니다. Jackson 역직렬화, Redis 직렬화, JJWT 정적 초기화, Hibernate lazy proxy…
하지만 Opus에게 많이 물어보다 보면 충분히 해결하실 수 있을 겁니다. 저 또한 Opus 없이는 절대 이 여정을 끝내지 못했을 겁니다. 물론 Opus도 가끔 틀린 답을 주기 때문에 결국은 다시 검토를 해봐야 할 것 같습니다. 특히 이 부분은 자료가 별로 없기 때문에 더욱 더 그런 것 같습니다.
언젠가는 devport가 거대한 서비스가 되어 애플리케이션을 마이크로서비스로 분리하고, GraalVM의 진가를 제대로 볼 수 있는 날이 왔으면 좋겠습니다. 그날이 오면 주말을 통째로 날려가며 reachability-metadata.json과 씨름했던 시간들을 보상받을 수 있지 않을까 싶습니다. 물론 그전에 먼저 devport에 사용자가 좀 생겨야겠지만…
긴 글 읽어주셔서 감사합니다.
References
https://www.graalvm.org/
https://github.com/spring-projects/spring-framework/wiki/Spring-Framework-7.0-Release-Notes
https://www.graalvm.org/latest/introduction/
https://wikidocs.net/blog/@jaehong/10663/
저우즈밍 지음, 이복연 옮김, 《JVM 밑바닥까지 파헤치기》, 인사이트, 2024.
