devport에는 Ports라는 페이지가 있습니다. AI, Agent, Loop, Harness, LLM 등 매일 쏟아지는 새로운 AI 관련 프로젝트 중 눈여겨 볼만한 프로젝트를 선별하여 위키를 제공해주는 곳이라고 생각하시면 됩니다.
이런 공간을 만들고 나니 사용자가 위키를 처음부터 끝까지 읽지 않고, 궁금한 걸 바로 물어볼 수 있는 챗봇이 필요하겠다는 생각이들었습니다.
챗봇을 위해서는 당연히 RAG를 구축해야 겠다고 생각했고, 그러면 벡터 DB가 필요하게 됩니다.
devport와 같은 프로젝트에 쓸만한 벡터DB의 선택안은 정말 많습니다.
ChromaDB, Qdrant, Weaviate 와 같은 오픈 소스들도 있고 혹은 managed 서비스인 Pinecone과 같은 선택도 있습니다.
하지만 저는 PosgreSQL을 선택했습니다. 네 그렇습니다. 관계형 DB의 대표주자인 그 PostgreSQL 맞습니다.

"왜 관계형 DB로 벡터 임베딩/검색을 하지?"
이 글에서 이 질문에 대한 저의 답과 나름의 정당화를 공유 해보았습니다.
또한 pgvector에 대한 설명과 함께 pgvector의 인덱싱 방법에 대해 탐구하고 나아가 Postgres의 벡터 검색 성능이 다른 벡터 DB와 비교해 어떤 위치에 있는지에 대해서도 한 번 살펴 보겠습니다.
pgvector?
GitHub - pgvector/pgvector: https://github.com/pgvector/pgvector
사실 벡터 DB에 조금이라도 관심이 있다면 pgvector에 대해서는 많이 들어봤을 것이라고 생각합니다. PostgresSQL에서 지원하는 플러그인으로 ChromaDB, Qdrant, Weaviate같은 vector 전용 검색 공간을 제공하는 벡터DB가 아닌 벡터 임베딩을 그냥 하나의 데이터 type으로 간주하여 기존의 Relational Database에 하나의 컬럼으로 관리하는 것처럼 디자인 된 Postgres의 플러그인입니다.
결국 추가적인 운영 오버헤드 없이, 이미 PostgreSQL을 사용하고 있다면 플러그인으로만 추가하여 더 관리해야 할 리소스를 줄이고 효율적으로 벡터 검색을 구현 할 수 있는 것입니다. 그럼 결국 RAG에 필요한 벡터들도 이미 사용 중인 하나의 DB에서 관리 할 수 있는 것이죠.
“오 좋은데? 리소스 비용도 줄이고, 관리도 기존 RDB 관리하듯 ACID 특성까지 유지하며 벡터 DB를 운영한다고?? 개꿀이네 ~~”
이게 사실이면 너무 좋겠죠, 하지만 편리성 뒤에는 항상 트레이드 오프가 존재합니다.
pgvector의 인덱싱 IVFFlat vs HNSW
pgvector를 활성화 하는 법이나 어떻게 entity를 설정해야 하는지에 대한 설명은 생략하겠습니다. 이미 수많은 관련 내용을 쉽게 찾을 수 있고 솔직히 AI한테 딸깍 한번이면 저보다 더 자세한 설명을 얻을 수 있을 것입니다.
그럼 저는 pgvector가 왜 vector 임베딩/검색으로 비효율적인지에 대해서 얘기해보록 하겠습니다.
pgvector에 대해서 조금만 찾아보면 꽤 긍정적인 내용들이 대부분일 것입니다. "벤치마크도 나쁘지 않고 다른 벡터 전용 DB와 비교해서 꿀릴게 없다, 리소스도 절약하고 운영 오버헤드를 줄여라." 뭐 이런 내용이 주를 이룹니다. 하지만 이는 사실과는 좀 거리가 있다고 생각합니다.
우선 vector 인덱싱에 대해서 살펴보도록 하겠습니다.
pgvector는 2개의 인덱싱 type를 제공해줍니다. IVFFLAT 과 HNSW.
IVFFlat(Inverted File with Flat Quantization): 벡터 공간을 클러스터로 나누기
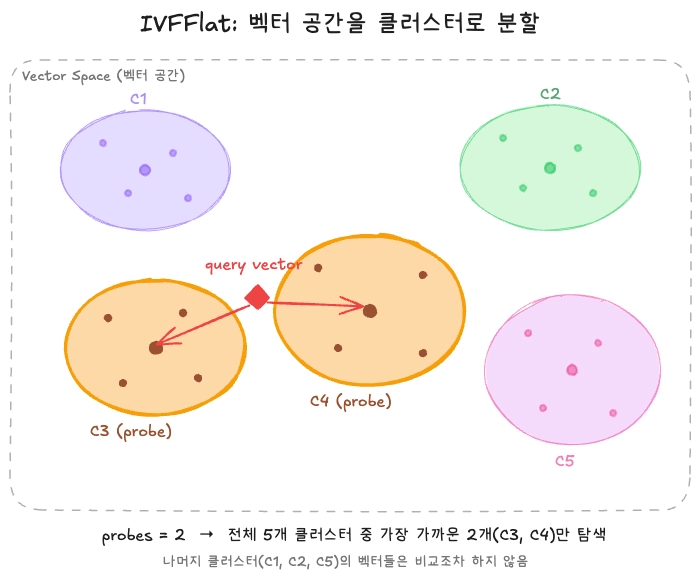
아이디어는 비교적 단순합니다. 벡터 공간을 미리 여러 개의 클러스터로 나눠두고, 검색할 때는 쿼리 벡터와 가까운 클러스터 몇개를 찾은 뒤, 그 클러스터 후보내에서 검색을 하게 되는 것입니다.
CREATE INDEX idx_wiki_section_chunks_embedding ON wiki_section_chunks
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);lists가 전체 공간을 몇 개의 클러스터로 나눌지 결정합니다. 검색을 할때는 ivfflat.probes 파라미터로 "몇 개의 클러스터를 탐색할지"를 결정 해야 합니다. 당연히 probes를 늘리면 정확도는 올라가겠지만 속도는 떨어지겠죠.
“이때 그럼 lists 값은 어떻게 설정해야 하지?”
이게 사실 이 인덱싱 방법에 있어 가장 중요한 설정 값이라고 생각합니다. 너무 적으면 클러스터가 적어 속도는 빠르겠지만 정확도는 저하될 것이고, 또 너무 많으면 정확도는 올라가겠지만 속도가 느려질 것입니다. 성능적인 부분 외에도 데이터 분포가 균일하지 않으면 어떤 클러스터는 벡터가 몰릴 수 있고 어떤 클러스터는 거의 비어있을 수도 있습니다. 결국 이런 고민들 속에서 공식 문서에서 추천하는 값은 rows/1000 정도로 매우 대략적인 공식으로 값을 추천하고 있습니다.
하지만 이 인덱싱 방식의 더 큰 문제는 클러스터들이 인덱스를 만들 때를 시점으로 데이터 분포가 고정된다는 점입니다. 새로운 벡터가 들어오면 기존 클러스터 중 가장 가까운 곳에 배정 될 뿐, 클러스터 자체가 다시 나눠지거나 재조정되지 않기 때문에 시간이 지나면 지날 수록 분포가 점점 틀어지고 검색 품질이 나빠질 수 있습니다. 결국에는 인덱스를 다시 처음부터 리빌드를 해야 하는 수 밖에 없는 것이죠.
이 문제는 devport의 ports페이지에는 큰 걸림돌이 될 것이라고 판단했습니다. ports 페이지에서 선별되는 프로젝트는 화제성과 기능적인 부분을 모두 고려하여 제가 직접 선별하여 프로젝트를 ports에 추가 여부를 결정합니다. Wiki를 생성하는 것은 AI(portki)로 자동화를 구현했지만 프로젝트 선정만큼은 제가 직접 저의 트렌디한(??) 개발 감각으로 결정을 하는 것이죠. 이제 막 서비스를 운영한지 2달도 안되었기 때문에 결국 신규 추가 빈도는 매우 많을 것이며 실제로도 이틀에 한번 꼴로 신규 프로젝트를 추가하고 있습니다. 그럼 저는 신규 프로젝트를 추가 할 때마다 인덱스를 다시 빌드해야하는 번거로움을 겪어야 하는 것입니다. 그 작업동안 서비스에도 많은 영향을 미칠 것이고요.
저는 결국 다른 인덱싱 방법에 좀 더 눈을 두게 되었습니다.
HNSW(Hierarchical Navigable Small World): 스킵 리스트에서 영감을 받은 다층 그래프
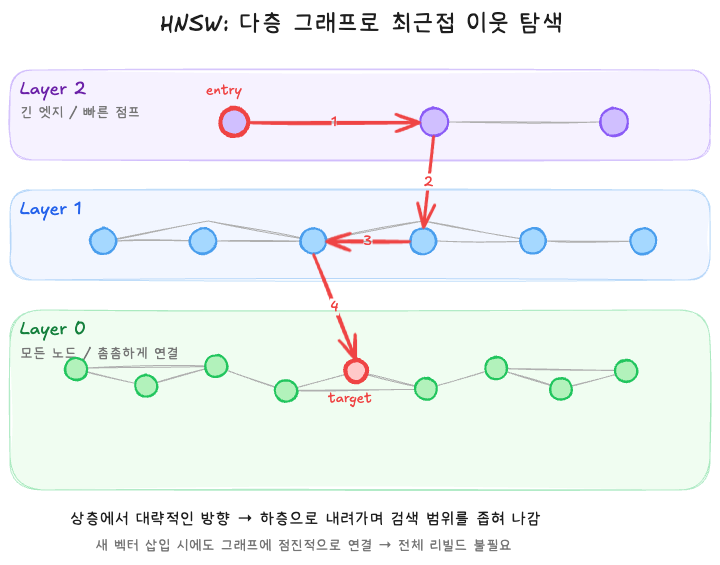
HNSW(Hierarchical Navigable Small World)는 완전히 다른 접근을 씁니다. 벡터들을 여러 층으로 쌓인 그래프로 연결해두고, 위층에서 아래층으로 내려오면서 점점 가까운 이웃을 좁혀 나가는 방식입니다.
이 구조의 근본은 스킵 리스트(skip list) 에서 나왔습니다. 스킵 리스트는 정렬된 데이터에서 빠른 검색을 위해 "건너뛰는 레인"을 층층이 쌓는 자료구조로 위층일수록 노드가 적고 한 번에 멀리 점프할 수 있고, 아래층으로 내려갈수록 촘촘해지면서 정밀한 검색이 가능해집니다.
HNSW도 같은 원리입니다. 최상층에는 벡터가 몇 개 없고, 이 노드들은 벡터 공간의 먼 거리를 한 번에 건너뛸 수 있는 "긴 엣지(long edges)"로 연결되어 있습니다. 쿼리가 들어오면 최상층에서 대략 가까운 영역으로 빠르게 이동하고, 한 층씩 내려오면서 검색 반경을 좁혀 최종적으로 가장 가까운 이웃을 찾아냅니다. 이 구조 덕분에 HNSW는 수백만 개 벡터에서도 몇 밀리초 안에 검색 결과를 낼 수 있습니다.
CREATE INDEX idx_wiki_section_chunks_embedding ON wiki_section_chunks
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);HNSW를 사용 할때는 세 가지 파라미터가 있습니다.
m 은 각 노드가 그래프에서 몇 개의 이웃과 연결될지를 결정합니다. 값이 크면 그래프가 촘촘해져서 검색 정확도(recall)가 올라가지만, 인덱스 용량과 빌드 시간이 늘어납니다. 16이 기본값입니다.
ef_construction 은 인덱스를 만들 때 각 노드의 이웃 후보를 얼마나 많이 살펴볼지를 결정합니다. 값이 크면 더 좋은 이웃을 찾을 확률이 높아져 인덱스 품질이 올라가겠지만, 빌드가 느려집니다.
SET hnsw.ef_search = 40;
SELECT wiki_section_chunks_embedding FROM wiki_section_chunks
ORDER BY embedding <=> $1::vector
LIMIT 10;ef_search 는 검색 시점에 탐색할 후보 리스트 크기입니다. 이건 런타임 파라미터라 쿼리마다 바꿀 수 있습니다. 높이면 recall이 올라가고, 낮추면 속도가 빨라집니다.
IVFFlat과 비교했을 때 HNSW의 진짜 장점은 동적 데이터에 훨씬 잘 맞는다는 점입니다. 새 벡터가 들어와도 그래프에 점진적으로 연결하면 끝이고, 전체 구조를 리빌드할 필요가 없습니다. 실제로 대부분의 벤치마크에서도 HNSW가 IVFFlat보다 recall과 속도 양쪽에서 더 좋은 결과를 보여주는 것을 확인했습니다. 그래도 만능 해결법은 아니긴 합니다. 새로운 insertion을 할때마다 그래프에 lock이 필요하고 write 작업에 정말 많은 부하가 있을 때는 이 인덱싱이 병목이 될 수도 있을 것입니다.
pgvector의 한계
여기까지 보면 "그럼 무조건 HNSW 쓰면 되겠네"라는 생각이 들지만, 사실 인덱스를 고르는 건 시작에 불과합니다. 진짜 골치 아픈 건 필터링입니다. RAG에서는 저처럼 WHERE project_external_id = :id로 범위를 좁히고 그 안에서 벡터 검색을 돌리는 패턴이 일반적입니다. PostgreSQL 쿼리 플래너는 "필터를 먼저 적용할지(pre-filter), 벡터 검색을 먼저 하고 결과에 필터를 걸지(post-filter)"를 판단해야 합니다.
더 근본적인 문제는 PostgreSQL 플래너가 벡터 데이터의 분포를 이해하지 못한다는 점입니다. 플래너가 특정 행들의 임베딩이 벡터 공간에서 얼마나 뭉쳐 있는지는 모르기 때문에 검색 성능이 낮아지는 것입니다. ChromaDB나 Weaviate 같은 전용 벡터 DB들이 filtered HNSW나 선택도 기반 자동 전략 같은 기능을 제공하는 이유가 바로 여기에 있습니다.
또 하이브리드 검색이라는 벽이 있습니다. 하이브리드 검색이란 벡터 유사도와 full-text 검색을 결합해서 의미 기반 매칭과 키워드 매칭을 동시에 잡는 방식인데, PostgreSQL은 tsvector로 풀텍스트 검색을 매우 잘 지원하고 pgvector는 벡터 검색을 어느정도 잘 지원하지만, 이 두 개를 어떻게 결합할지는 전적으로 개발자의 몫입니다. Cosine distance는 0에서 2 사이, ts_rank는 작은 소수점 숫자라 스케일이 달라 그냥 더할 수도 없습니다. 결국 직접 판단해서 구현해야 하는데, 많은 전용 벡터 DB는 이걸 기본으로 제공합니다. 이런 문제들을 해결해주는 플러그인 또한 있지만 이런 것들을 해결하려다 보면 결국 pgvector를 선택한 이유였던 "운영 복잡도 감소"라는 명분이 점점 작아지게 되는 것입니다.
결국 사실 많은 것을 고려해봤을 때 벡터 임베딩/검색 용도로 pgvector를 사용한다는 것은 오히려 더 비효율적일 수도 있는 것이죠.
그럼에도 pgvector를 devport에서 사용하겠다는 정당화
물론 devport의 임베딩/검색 성능이 중요하다면 벡터 전용 DB를 도입해야 겠지만 사실 devport는 pgvector가 더 적절하다는 판단을 했습니다. 그 이유는 다음과 같습니다.
1. write 임베딩이 프로덕트에서 일어나지 않는다.
이 이유가 가장 큰 이유입니다. Ports 페이지에 있는 프로젝트들은 제가 직접 선별해서 로컬 및 개발 환경에서 AI Tool(주로 codex)로 Wiki를 생성합니다. 그리고 그 생성된 Wiki를 다시 검증한 후에야 임베딩을 진행하고 그것을 prod에 있는 DB로 마이그레이트를 진행합니다. 프로덕트에서 사용자의 채팅으로 인한 질문 임베딩은 일어나지만 사용자 측에서의쓰기(벡터 임베딩) 부하는 존재하지 않는 것입니다. 이는 결국 HNSW의 약점이라고 할 수 있는 ‘insert시 lock’이 트래픽으로 안터진다는 의미입니다.
2. 벡터 임베딩을 사용하는 기능이 아직 위키 챗봇 하나뿐이다
devport에서 벡터 검색이 필요한 기능은 현재 Ports의 위키 챗봇이 유일합니다. 이 한 가지 기능을 위해 Qdrant나 Weaviate 같은 별도 인스턴스를 띄우는 건 명백한 오버 엔지니어링이라고 판단했습니다. 별도 벡터 DB를 도입한다는 건 어쩔 수 없이 운영해야 할 컴포넌트가 하나 더 늘어나고, 모니터링 대상도 늘어나며, 백업/복구 전략도 따로 세워야 합니다. 게다가 위키 데이터의 메타데이터는 이미 PostgreSQL에 있는데, 이걸 별도 벡터 DB와 동기화 해야 한다? 혼자서 개발하는 프로젝트에서 여기까지는 진짜 무리라고 생각했습니다. 또한 임베딩 대상인 위키의 본문과 실제 임베딩이 같은 트랜잭션 안에서 처리된다는 점은 저에게 굉장히 큰 이점으로 느껴 졌습니다.
3. 나의 프로젝트에 맞게 설정하고 튜닝
Pinecone 같은 managed 서비스도 꽤 매력적이지만 크게 두개의 장애물이 있다고 생각했습니다. 첫째, 어차피 트래픽이 늘어나 scale out이 필요한 시점이 오면 managed 서비스의 요금은 free-tier를 넘어 설 것이라고 생각합니다. devport와 같은 무료 서비스를 운영하는 입장에서 이는 감당하기 힘들다고 생각했습니다. 둘째, Pinecone은 의도적으로 인덱스 파라미터를 거의 노출하지 않는 것으로 알고 있습니다. HNSW의 M이나 ef_construction 같은 값을 사용자가 직접 튜닝할 수 없고, "알아서 잘 해준다"는 것을 포인트로 영업을 하는 서비스입니다. 일반적인 워크로드에는 충분하겠지만, 제가 앞서 길게 설명한 것처럼 인덱스 파라미터 선택은 워크로드 특성에 따라 결과가 크게 달라질 수 있다고 생각했고, 직접 만질 수 없다는 건 곧 "내 프로젝트에 맞게 튜닝하지 못한다" 라는 느낌이 강했습니다. 그래도 학습의 목표가 어느정도 있는 이 프로젝트에서는, pgvector가 더 가치가 있다고 생각했습니다.
4. 아직은 충분하다
만약 devport가 성장해서 위키 외에도 여러 기능에서 벡터 검색이 필요해지고, 임베딩 데이터의 단위가 늘어, 필터링과 하이브리드 검색이 정말로 병목이 되는 시점이 온다면, 그때는 망설이지 않고 다른 벡터 DB로 옮길 것 같습니다. 그리고 그 마이그레이션은 이미 준비가 되어있습니다. 청크 데이터와 메타데이터는 이미 PostgreSQL에 정형화되어 있고, 검색 인터페이스 또한 한 곳에 모듈화를 잘 했기 때문에 구현체만 교체하면 됩니다. 즉, "아직은 충분하다" 라는 것이 결정의 핵심이었습니다.
끝
결론적으로 pgvector를 선택한 건 "pgvector가 최고의 솔루션"이어서가 아닙니다. 위에서 본 것처럼 필터링, 하이브리드 검색, 실시간 인덱싱 같은 영역에서 분명한 한계를 가지고 있습니다. 단지 devport의 현재 워크로드가 그 한계와 부딪히지 않았고. 트레이드오프를 종합적으로 비교해봤을 때 이게 가장 좋은 선택이었기 때문이었습니다.
이런 결정을 내리는 과정 자체가 저에게는 꽤 값진 시간이었습니다. 그동안 RDB와 NoSQL을 비교해본 경험은 많았지만, 벡터 DB라는 카테고리를 이렇게 깊게 파고들어본 건 처음이었습니다. 인덱싱 알고리즘부터 필터링 전략, 관리형 서비스의 추상화까지 하나씩 살펴보면서 많은 것을 얻을 수 있었다고 생각합니다. 그리고 무엇보다, 단순히 "좋은 거, 유행하는 것"을 고르는 게 아닌 내 프로젝트의 워크로드 특성을 기준으로 여러 대안을 저울질하고 근거를 가지고 선택하는 과정이, 제가 생각해왔던 "엔지니어링"에 가장 가까운 경험이었던 것 같습니다.
