들어가며
전 블로그 중 devport api 서버의 GraalVM Native image를 적용하는 건을 다룬 글이 있었습니다. GraalVM Native Image의 빠른 시작 시간과 가벼운 메모리 풋프린트를 필두로 Native Image가 가져오는 이점들만을 생각하고 비교적 낮은 스펙의 EC2에서 서버를 운영하기 위해 적용을 했었습니다. 하지만 이를 운영하다 보니 일반적인 JVM 에플리케이션에 비해 몇가지 아쉬운 점들이 있어 직접 이를 해결하고자 프로파일 기반의 최적화를 진행하기로 했습니다.
Native Image의 문제점
- JIT 컴파일러의 부재로 인한 런타임 환경에서의 최적화 부재
- 무거운 작업이 필요한 메소드들이 중첩되며 부하시 성능 저하 발생
Native Image에서는 JVM에서 JIT 컴파일러가 자동으로 최적화를 처리하는 부분이 부재하기 때문에 JVM에 비해 가볍게, 낮은 스펙의 노드에 빠르게 실행을 할 수 있다는 장점이 있지만 성능은 그리 좋지 않습니다.
이번 글에서는 결국 이를 해결 하기 위해 PGO (Profile Guided Optimization)을 적용하여 Spring Boot GraalVM Native Image의 성능을 향상 시키기 위해 제가 했던 노력과, 프로파일(.iprof) 파일을 추출하고 빌드에 적용하여 애플리케이션을 최적화하는 과정에 대해 공유해보도록 하겠습니다. 나아가 그 결과에 대해서 일반 Native Image와 Hotspot JVM과 비교해보도록 하겠습니다.
백엔드 컴파일러
우선 PGO가 무엇인지 설명하기 전에 일반적인 JVM에서는 최적화가 어떻게 이루어지는지 설명 해보도록 하겠습니다.
《JVM 밑바닥까지 파헤치기》 책의 표현을 빌리자면 자바는 “컴파일 타임”을 프론트엔드와 백엔드로 범위를 나눌수 있고 해당 컴파일 타임의 ‘최적화’ 대상도 다르게 정의 할 수 있다고 설명 합니다.
- 프론트엔드 컴파일러: JDK의 javac, 이클립스 JDT(Java Development Tool)의 증분 컴파일러(ECJ) 등
- 백엔드 컴파일러: JIT 컴파일러 (Hotspot VM의 C1·C2 컴파일러), Graal 컴파일러, AOT 컴파일러 등
간략하게 설명하자면 프론트엔드 컴파일러는 개발자의 코딩 및 작업 효율을 높이는 최적화를 진행하고, 백엔드 컴파일러는 런타임에서의 실행효율 최적화를 목적으로 진행하는 것입니다.
결국 devport api 서버의 성능을 끌어올리기 위해서는 이 백엔드 컴파일러에 집중을 해야 헸습니다.
우선 devport는 api 서버는 CI 단계에서 Graalvm의 native Image만 빌드하지 않습니다. Paketo의 빌드팩을 사용하여 JVM (BellSoft Liberica JRE 21) 버젼의 이미지 또한 빌드를 진행합니다.
해당 JVM은 Hotspot 기반으로 실행시 런타임에서 JIT컴파일러가 많은 최적화를 진행합니다.
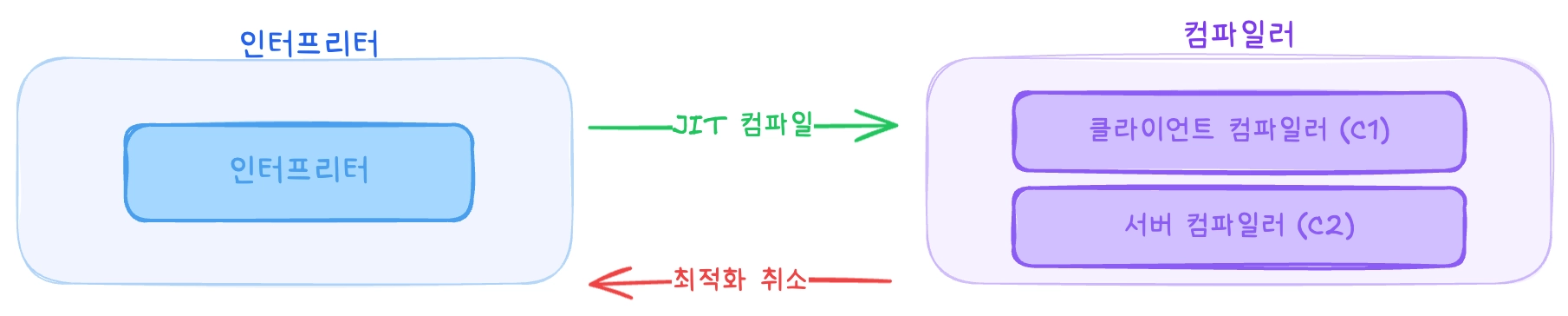
출처: 《JVM 밑바닥까지 파헤치기》 저우즈밍 지음, 이복연 옮김 p.519
Hotspot JVM에서는 JIT 컴파일러와 Interpreter가 협력하며 최적화를 진행합니다. 이 과정에서 JIT 컴파일러가 최적화를 더 많이 할 수록 시간이 더 오래 걸리고 그중에서 더 많이 최적화 된 코드를 생산하기 위해 인터프리터가 성능 모니터링(Profiling) 정보를 수집하기도 합니다.
결국 이 최적화의 목적은 자주 실행되는 메서드나 코드 블록이 발견되면 이를 핫 코드(Hot Spot)라고 식별하고 해당 부분을 네이티브 코드로 컴파일하여 다양한 최적화를 적용해 런타임에서의 성능을 높이는 것입니다.
Hotspot JVM의 Hot Spot 탐지
제가 사용하는 JVM의 hotspot 탐지 과정은 Counter-based입니다. 즉, 설정된 임계치(Thresholds)를 넘어야 단계적으로 최적화를 진행하는 것입니다.
OpenJDK의 소스 코드를 살펴보면 실제로 이 최적화의 각 단계(Tiered compilation)의 설명이 자세하게 주석으로 적혀있는 걸 볼 수 있습니다.
https://github.com/openjdk/jdk/blob/jdk-21%2B35/src/hotspot/share/compiler/compilationPolicy.hpp
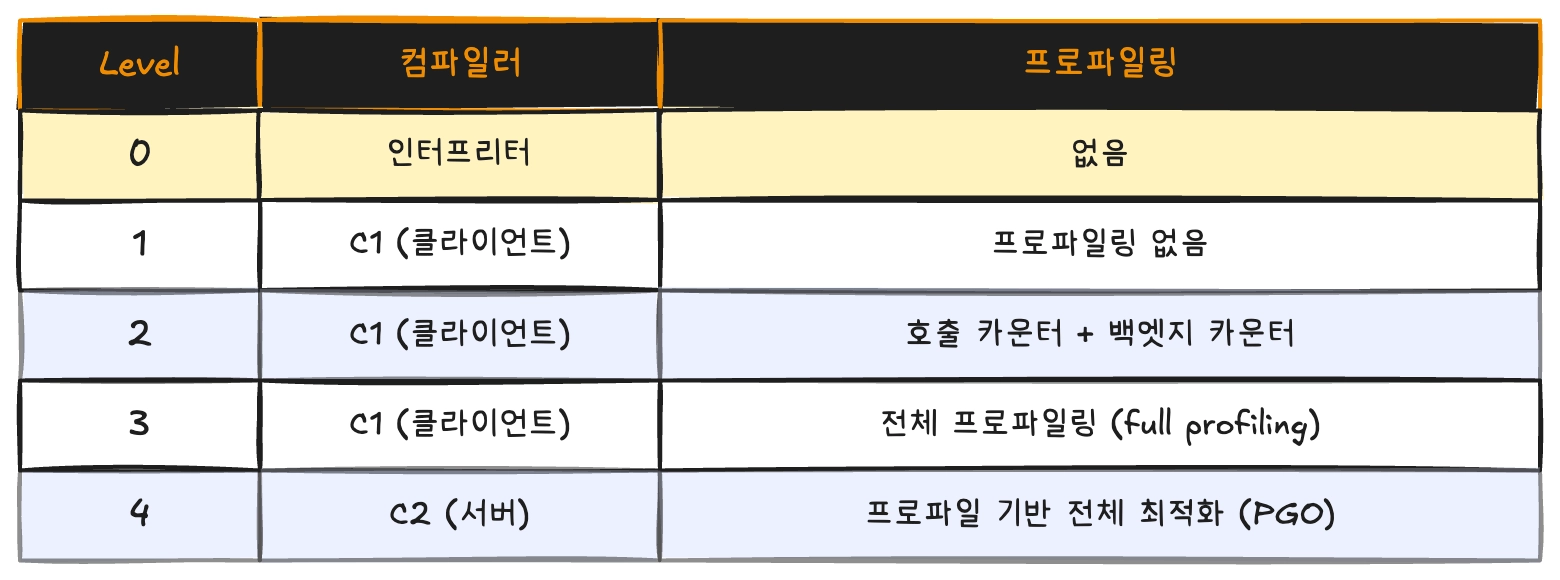
소스코드의 적힌 설명을 요약하자면 총 5개의 계층의 컴파일 단계가 있는 것을 확인 할 수 있습니다.
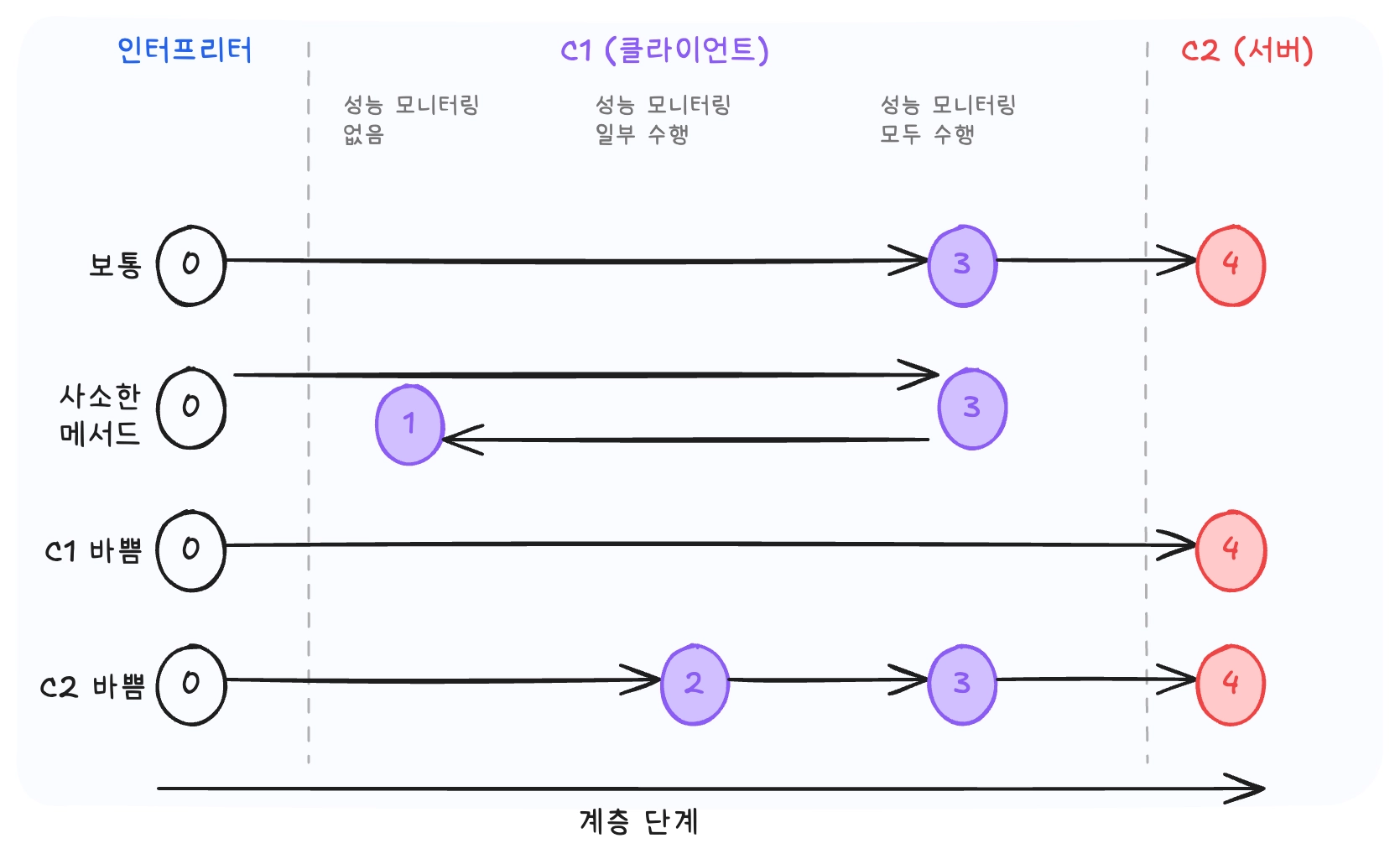
출처: 《JVM 밑바닥까지 파헤치기》 저우즈밍 지음, 이복연 옮김 p.521
이는 실제 환경에 따라 메서드가 단계적으로 최적화를 거쳐 프로파일링이 적용된 데이터를 이용하는 C2 컴파일러로 컴파일 될 수 도 있고 다시 경우에 따라 deoptimization이나 정책 변화로 다시 낮은 단계로 돌아가거나, 혹은 예외적인 상황에서는 0단계에서 바로 4단계의 컴파일 단계로 건너뛸수도 있습니다.
간략하게 요약하자면, 메서드의 실행 횟수가 많아질수록 Hotspot은 해당 코드에 더 높은 단계의 최적화를 실행 시키고, 실행 중 수집한 프로파일 정보를 바탕으로 더 강한 최적화를 적용해 런타임 성능을 높이게 되는 것입니다.
그럼 Native Image에서는?
Native Image에서는 이런 과정들이 런타임에서 전혀 일어나지 않습니다. 빌드 시점에서 모든 메서드와 경로를 한번에 판단하여 바로 binary로 컴파일을 진행하기 때문에 런타임에서 특정 메소드가 더 많이 호출되더라도 이를 수정 할 수 있는 방법이 없습니다.
그럼 어떻게 성능을 높일 수 있을까?
→ 이를 해결 해 주는 것이 바로 PGO입니다.
Profile Guided Optimization (PGO)
PGO는 말 그대로 생성된 프로파일 정보(.iprof)를 가지고 이를 가이드로 삼아 빌드 시점에서 최적화를 진행하는것을 뜻합니다. 여기서 Profile이란 애플리케이션 런타임에서 특정 이벤트가 얼마나 일어났는지에 대한 요약된 로그입니다. 해당 이벤트에 대한 로그를 기반으로 컴파일러가 이를 활용해 AOT 컴파일시 이를 활용하여 빌드 시점에서 최적화를 진행하기 위해서 사용합니다.
해당 로그에서는 다음과 같은 정보들을 중점으로 로그를 수집합니다.
- 해당 메소드가 얼마나 호출되었나?
if조건에서true가 얼마나 되었나?- 메소드가 객체를 얼마나 할당 했나?
String값이 특정instanceof체크에 얼마나 전달 되었나?
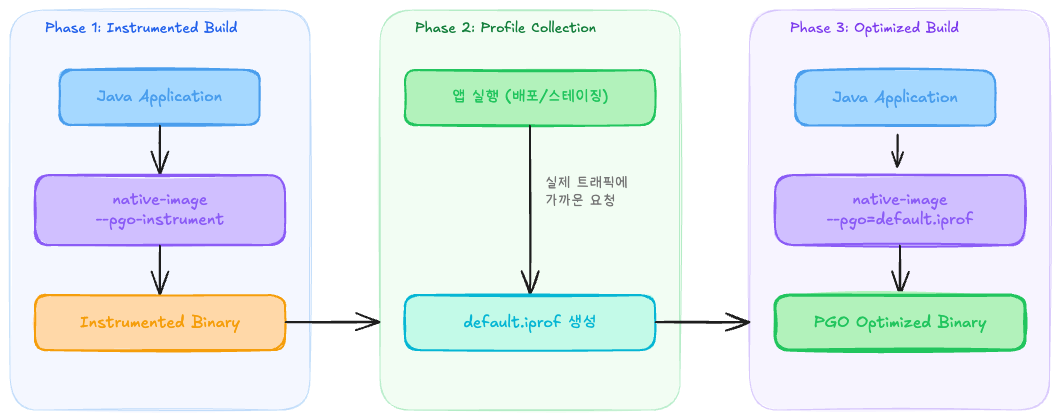
한번에 binary로 빌드하는 Native Image의 빌드에서 이 정보를 얻을 수 있는 방법이 없습니다. 그래서 PGO를 적용한 Native Image binary를 빌드하고 해당 빌드 아티팩트를 실행시켜 실제 트래픽에 가까운 요청을 애플리케이션에 보내 이 정보들을 직접 추출해내고 그 정보들을 바탕으로 다시 빌드하는 과정을 거쳐야 합니다. 이게 전반적인 PGO GraalVM Native Image의 생성 방식입니다.
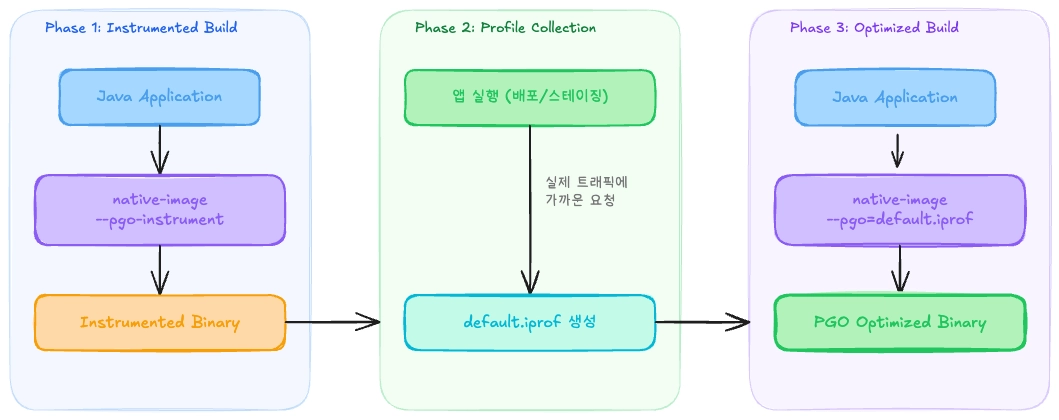
직접 PGO Native Image 빌드하기
그럼 직접 PGO를 진행한 과정에 대해 공유 해보겠습니다. 우선 PGO를 생성하고 적용하기 위해서는 Oracle에서 제공해주는 GraalVM을 사용해야 합니다.
https://docs.oracle.com/en/graalvm/enterprise/22/docs/reference-manual/native-image/
GraalVM의 Community Edition과 달리 PGO, Advanced JIT 등, 다양한 기능이 있던 오라클의 JDK는 원래 Enterprise 전용으로 많이 출시 돼 일반적인 유저 입장에서는 사용이 어려웠는데 2024년부터는 오라클의 GraalVM이 GFTC 라이센스로 출시 되고 있어 무료로 상업적인 사용이 가능해 졌습니다.
devport는 Paketo Cloud Native Buildpack으로 도커 이미지를 생성합니다. 빌드 생성시 PGO Instrument와 함께 Native Image를 생성하기 위해 ‘--pgo-instrument’를 환경변수로 주입해줍니다.
tasks.named('bootBuildImage') {
//빌더 버젼
builder = "paketobuildpacks/builder-noble-java-tiny:0.0.124"
def isNative = !project.hasProperty('buildJvm')
def bps = []
//Native 빌드시 Oracle 빌더를 사용
if (isNative) {
bps.add("docker.io/paketobuildpacks/oracle")
bps.add("urn:cnb:builder:paketo-buildpacks/java-native-image")
} else {
bps.add("urn:cnb:builder:paketo-buildpacks/java")
}
if (isNative) {
//PGO instrument 빌드시
if (project.hasProperty('pgoInstrument')) {
nativeArgs.add('--pgo-instrument')
nativeArgs.add('-J-Xmx28g') //빌더 컨테이너가 사용할 메모리 (16gb 이상 권장)
}
//프로파일 빌드시
if (project.hasProperty('pgoProfile')) {
nativeArgs.add("--pgo=${project.property('pgoProfile')}")
}
env["BP_NATIVE_IMAGE_BUILD_ARGUMENTS"] = nativeArgs.join(' ')
}
environment = env
if (project.hasProperty('pgoProfileHostPath')) {
bindings = ["${project.property('pgoProfileHostPath')}:/platform/pgo/default.iprof:ro"]
}
}해당 build.gradle을 보시면 한가지 주의해야 할 점은 바로 '-J-Xmx28g' 환경변수 입니다. 이는 빌더 컨테이너 내부에서 Java 프로세스의 최대 힙을 설정해주는 명령어 입니다.
저의 기존 CI 파이프라인은 Github Actions의 Free Tier인 ubuntu-24.04-arm러너를 사용했었는데 해당 러너 의 스펙은 4vCPU의 16gb의 메모리를 가지고 있습니다. PGO Instrument 빌드 또한 해당 러너로 빌드하면 큰 문제 없을 것이라고 예상했지만 메모리가 부족해 러너에서 OOM 에러가 떴습니다.
다른 방안을 찾기 위해 무료 CI 러너들을 찾아보다가 결국에는 그냥 해당 빌드를 위해 ec2 (8vCPU/32gb/arm) 하나 실행하고 빌드만 끝나면 바로 끄는 방식으로 진행 했습니다.
어차피 pgo 정보가 담긴 아티팩트를 생성하기 위한 intrument 빌드가 무거운 것이지 pgo의 프로파일을 활용할 가이드 빌드는 기존의 Github Actions의 무료 티어로도 충분하기 때문에 임시방편으로 충분하다고 생각했습니다. pgo instrument 빌드는 앱의 서비스 로직이 수정되거나 많은 기능이 추가되지 않는 이상 재빌드 할 필요가 많지 않을 것이고 기존의 프로파일을 수정없이 사용해도 일반적인 빌드(추출된 프로파일 정보를 가지고 하는 일반적인 업데이트)는 문제가 없을 거라고 판단했기 때문입니다.
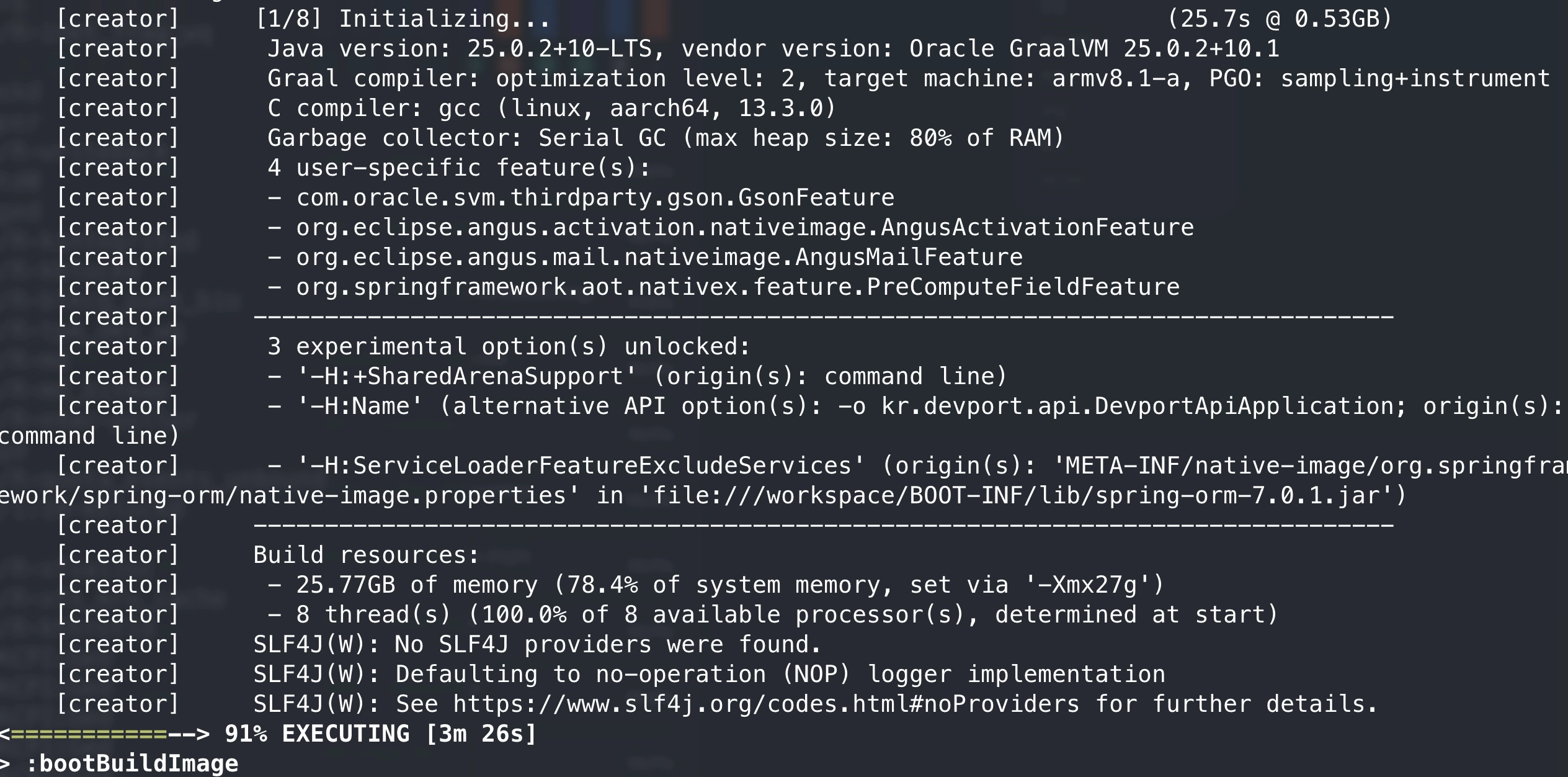
결국 27gb를 빌더 컨테이너의 할당해 pgo-intrument native image 빌드에 성공했습니다.
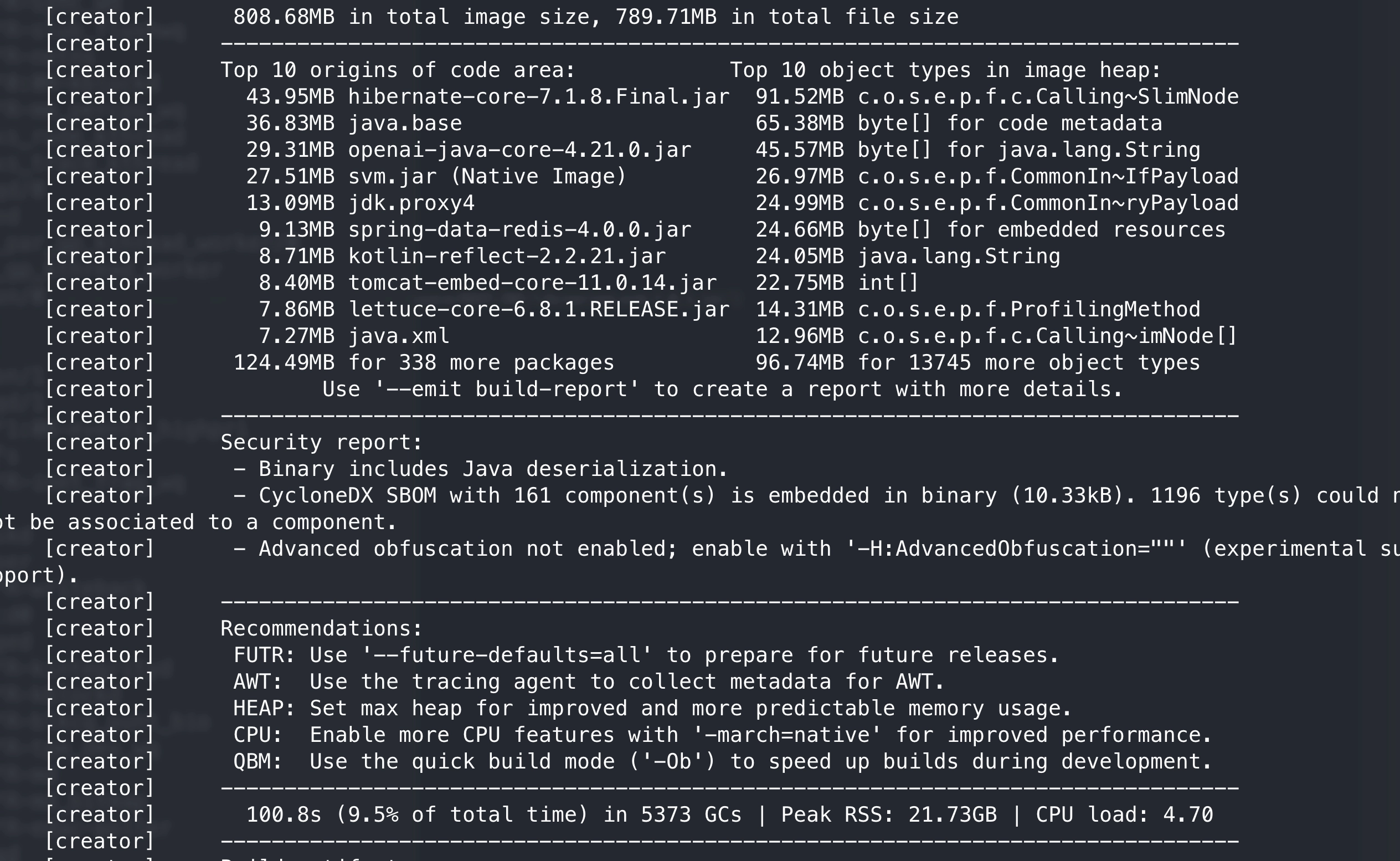
빌드 결과를 확인해 보니 이미지 사이즈가 2배이상 증가 한 것 (기존 350 → 808mb)을 볼 수 있었습니다. 이는 런타임에서 실제 메소드가 얼마나 실행되는지를 측정하기 위한 agent가 같이 있기 때문입니다. 어차피 profile 출출 후 가이드 빌드에는 다시 작아지니 이는 크게 걱정하지 않아도 됩니다.

pgo-instrument: 트래픽을 통해 PGO Profile 생성
이제 intrument 빌드가 끝났으면 해당 image를 가지고 실제 트래픽에 최대한 같은 요청을 보내며 실행을 해줘야 합니다. devport와 같은 사이드 프로젝트에서는 실제 트래픽이 사실 상 거의 없기 때문에 저는 k6로 가장 많이 사용되는 api 경로들에 부하를 주는 방식으로 최적화를 진행했습니다. 결국 프로덕트를 개선한다는 목적보다는 실험을 한다는 생각으로 부하를 주고 PGO Native Image 생성하고 기존의 Image 와 JVM의 성능과 비교해 보며 차이점을 확인 해 보겠습니니다.
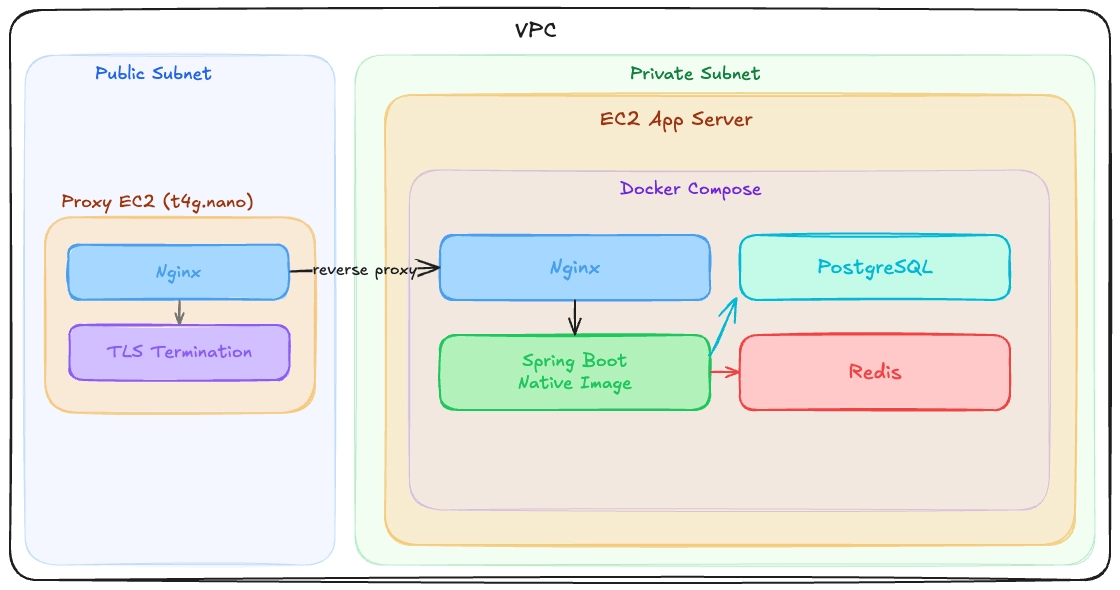
devport의 백엔드는 이런식으로 구성되어 있습니다. 물론 만약 프로덕트 자체에의 성능 개선을 주 목적을 한다면 최대한 프로덕션과 비슷한 환경으로 트래픽을 주어 프로파일을 만드는 것을 추천 드립니다. 하지만 저 같은 경우는 성능 개선도 염두하고 진행을 했지만, pgo로 인한 개선사항 자체에 대해서 실험해보자는 의도가 강했기 때문에 pgo 프로파일 추출을 위한 트래픽을 보낼때 nginx와 같은 프록시를 거쳐서 요청을 하지 않고 앱 자체에 바로 요청을 보내 실험을 진행했습니다.
k6로 트래픽을 줄 스크립트을 작성하고 이를 실행할 인스턴스를 앱과 같은 서브넷에 위치시켜 해당 컨테이너(Spring Boot)의 포트로 바로 부하를 주는식으로 실험을 진행했습니다.
k6로 큰 부하를 줘 성능 실험을 해 볼 대상 endpoint는 총 4개 입니다.
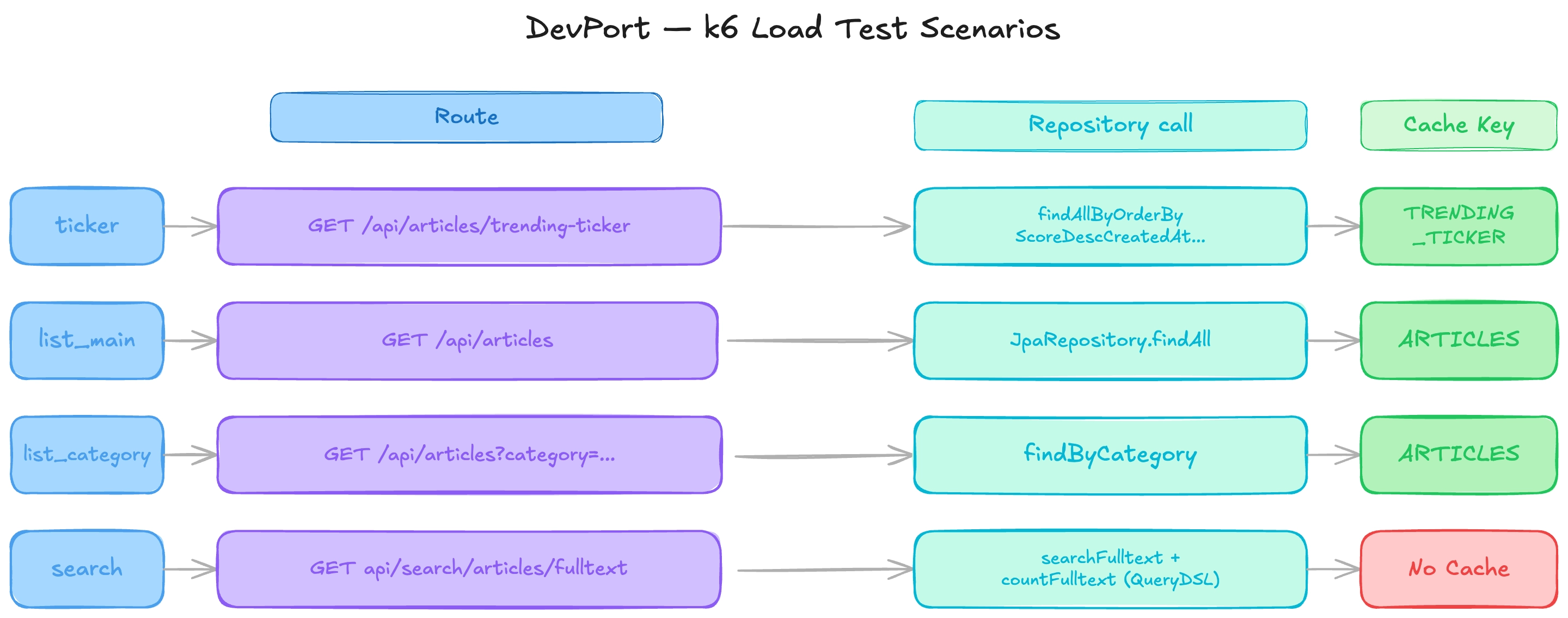
4개의 엔드포인트들의 구조를 설명하자면 위와 같습니다. ticker, list_main, list_category, search는 모두 articles 엔티티를 위한 api로 각자 별도의 목적에 맞는 repository call을 진행하고 redis를 통한 캐시를 진행합니다. 다만 search는 각 article의 본문 내용에서 fulltext search를 하는 매우 무거운 작업이며 이는 캐시 기능 또한 없습니다.
결국 이 최적화의 주 대상은 Redis I/O + Jackson deserialize + Jackson serialize 이 세가지 입니다. search api는 QueryDSL + JPA가 되겠습니다.
pgo-profile: 프로파일이 적용된(최적화 된) 빌드
트래픽을 보내는 스크립트가 끝나고 앱을 정지 시키면 이와 같이 default.iprof이 생성됩니다. 해당 파일이 바로 Profile입니다. 약 100mb가 조금 안되는 크기 였습니다.
이 프로필을 가지고 아래의 args를 통해 빌드를 재 실행하면 PGO Native Image가 생성됩니다.
"--pgo=${project.property('pgoProfile')}"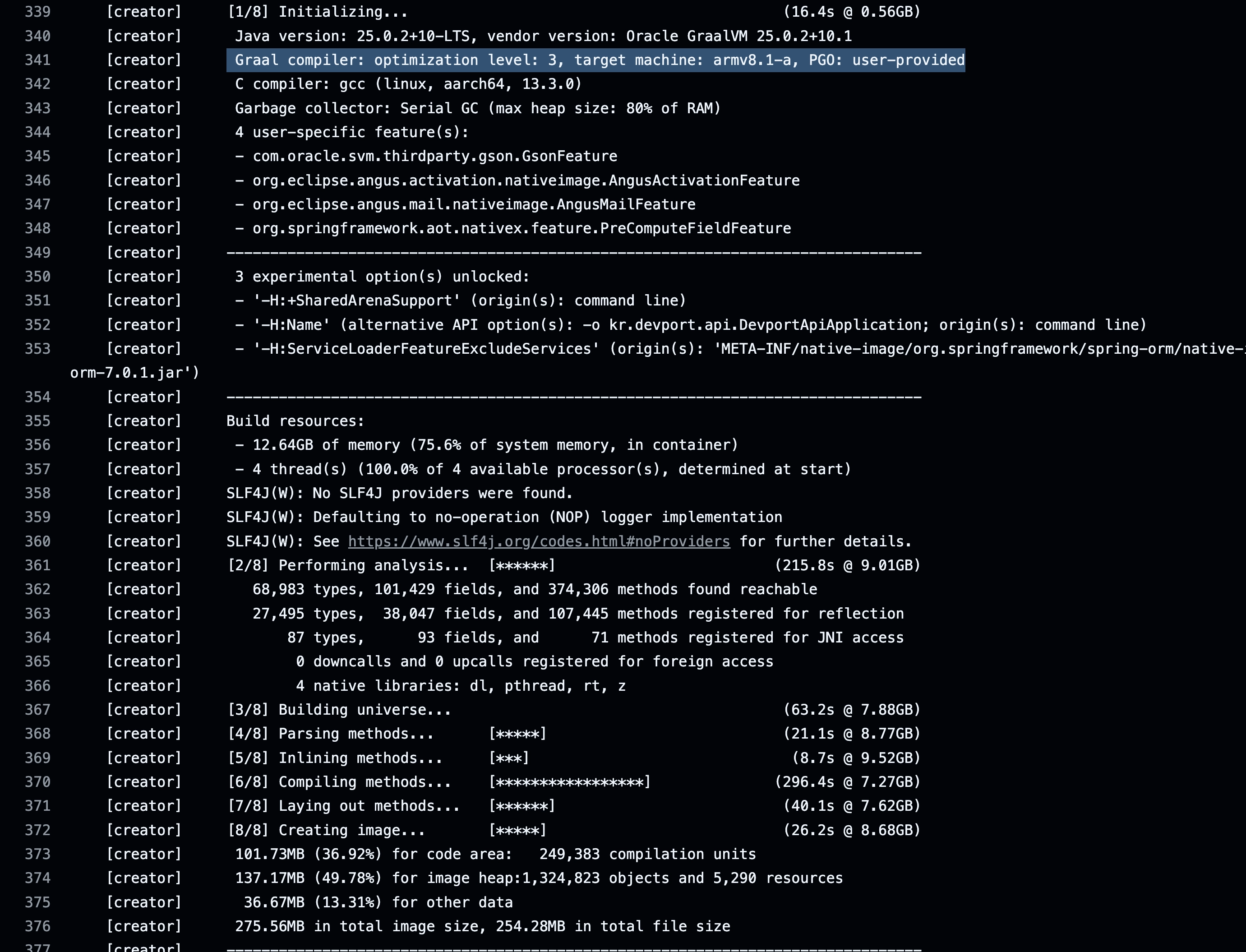
Graal 컴파일러의 Optimization 레베일 기존 2에서 → 3으로 올라간 것을 확인 할 수 있습니다. PGO를 적용한 빌드가 진행되는 것입니다. 이미지 크기도 다시 기존의 이미지 크기 (275mb)로 복구 된 것을 확인 할 수 있습니다.
그럼 이제 pgo-GraalVM Native Image, GraalVM Native Image, JVM 이 3가지에 대한 성능 비교를 진행 해보겠습니다.
실험 결과
Hotspot JVM
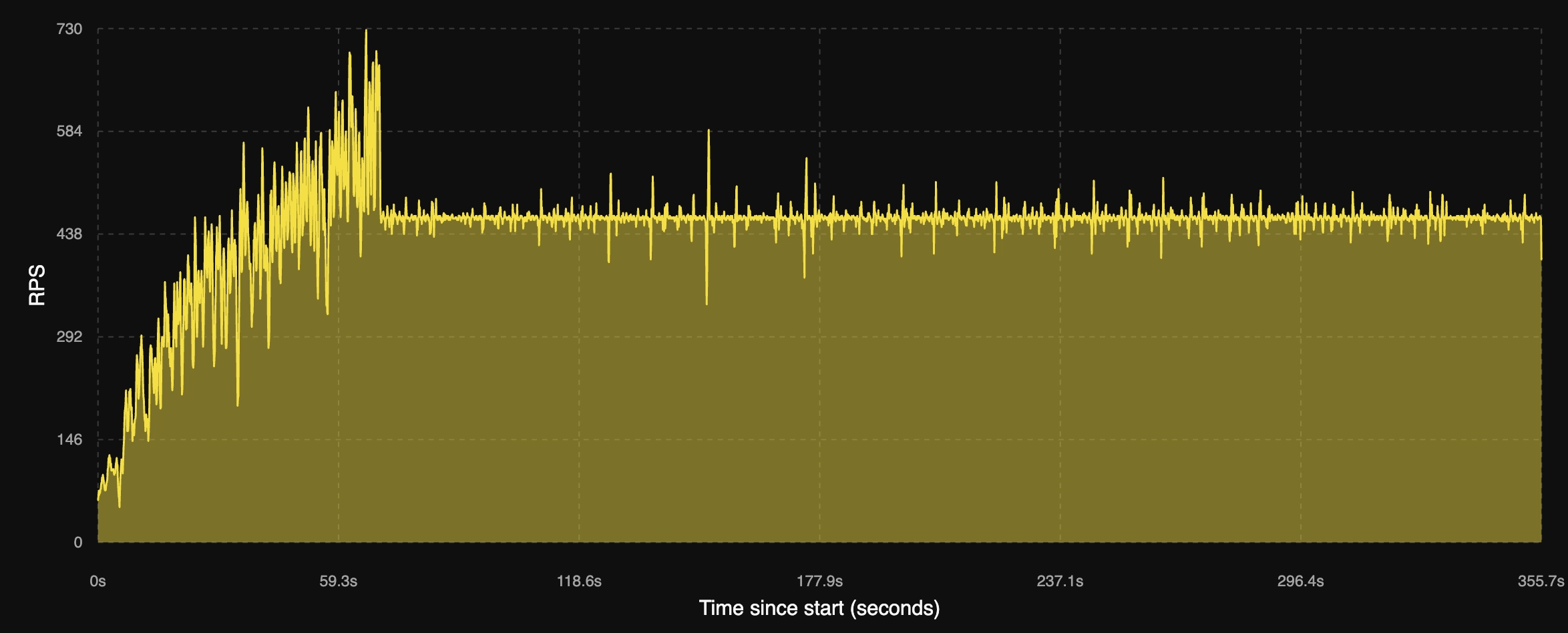
Hotspot JVM 처리량
JVM 기반의 애플리케이션은 기동 직후 약 1분간은 처리량이 매우 불안정한 것을 확인 할 수 있었습니다. 이는 아직 애플리케이션이 시작한지 얼마되지 않은 이른바 ‘warm up’ 단계로 JIT 컴파일러 최적화 작업을 지속적으로 수행 하고 있기 때문입니다. 약 70초가 지난후 부터는 매우 안정적으로 부하를 처리하는 모습을 확인 할 수 있었습니다.
Native Image
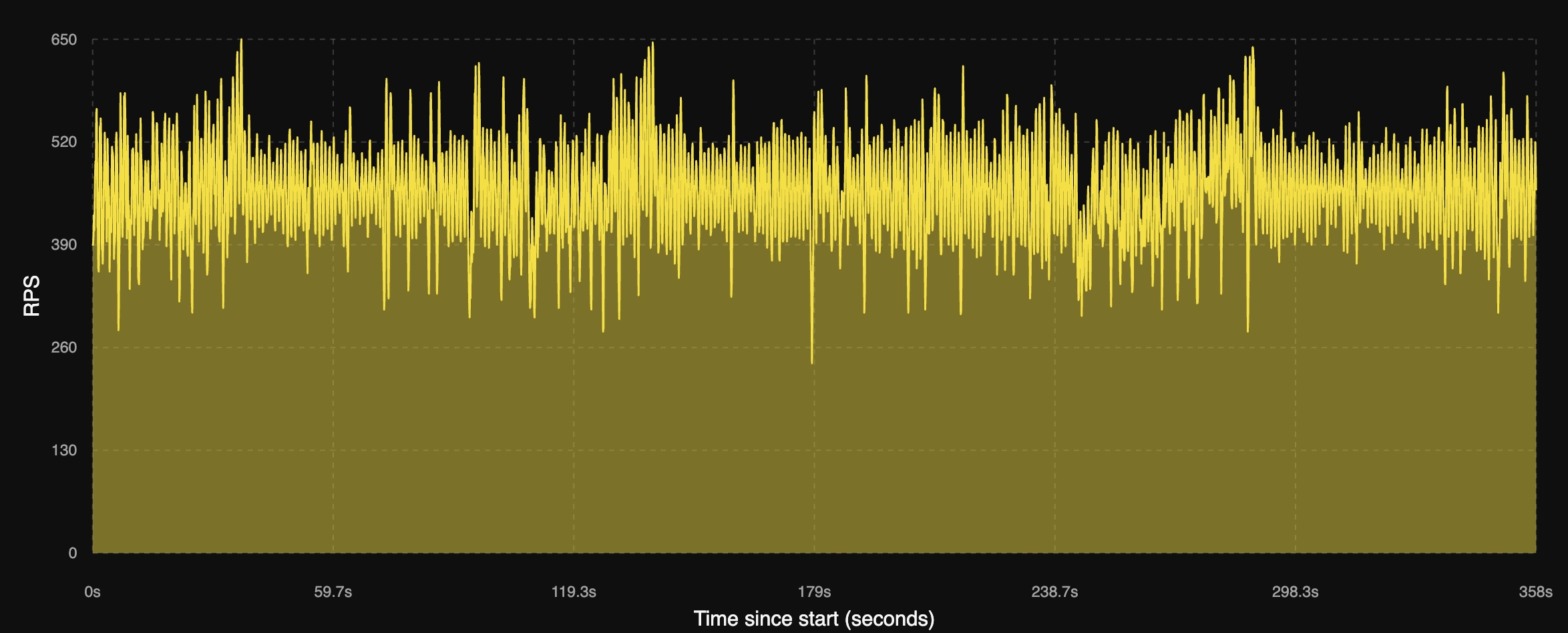
Oracle GraalVM Native Image
다음은 Native Image입니다. 바로 바이너리로 빌드되어 머신코드를 실행하기 때문에 기동 직후부터 바로 최대 성능에 달하는 처리량에 도달 하는 것을 확인 할 수 있습니다. 하지만 런타임에서 최적화가 일어나고 있지 않고 있기 때문에 이 최대 성능이 계속 유지되는 것 또한 확인 할 수 있었습니다. 또한 처리량이 Hotspot JVM에 비해 좀 불안정적인 것을 확인 할 수 있었지만 순간적인 peak 처리량은 좀 더 높은 것을 확인 할 수 있었습니다.
Hotspot JVM vs Native Image 비교
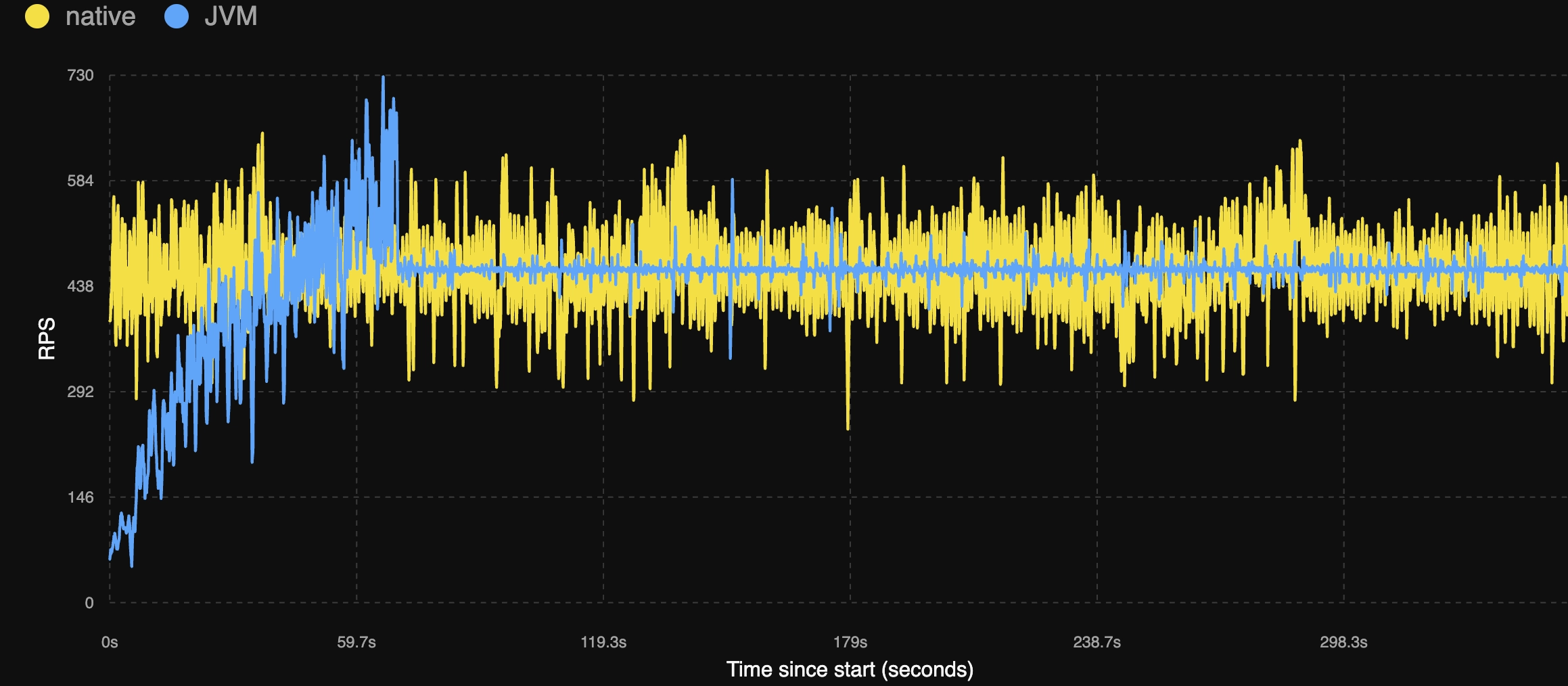
Hotspot JVM vs Oracle GraalVM
PGO Native Image
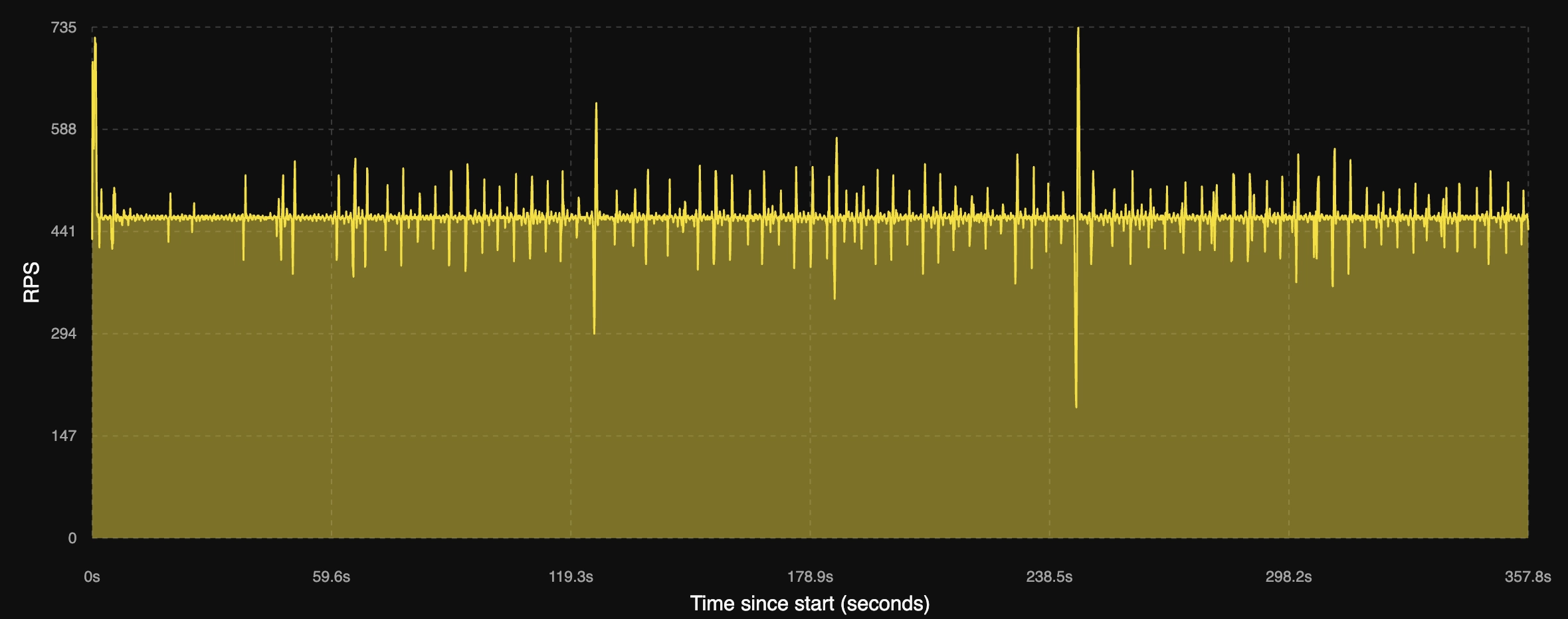
PGO guided Oracle GraalVM Native Image
PGO를 적용한 Native Image의 요청 처리량은 위와 같았습니다. 불안정적인 처리가 확실히 잡혀 안정적으로 요청을 처리하는 모습을 확인 할 수 있었습니다.
이 둘의 차이점은 p99 레이턴시 지표를 확인하며 더 확실하게 확인 할 수 있었습니다.
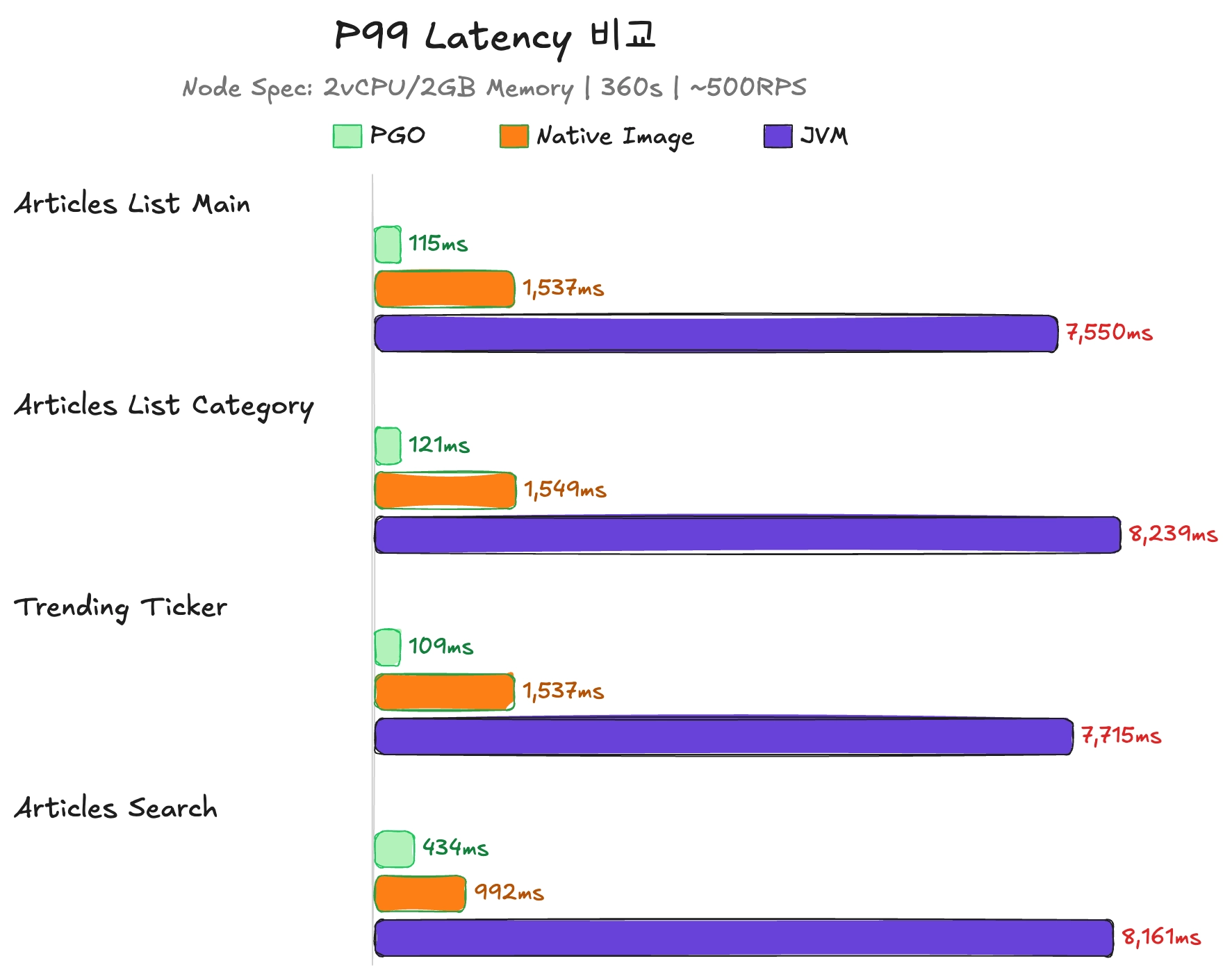
PGO/Native Image/JVM p99 레이턴시 비교
PGO 가이드가 적용된 Native Image는 일반 Native Image보다 p99 레이턴시가 약 13배 이상 빨랐고 JVM 보다는 약 67배 이상 차이가 난 걸 확인 할 수 있었습니다.
하지만 해당 지표만을 바라보고 JVM의 p99 레이턴시를 비교하는 것에는 문제가 있습니다. 웜업 시간에 오래 걸린 요청들 대부분이 JIT 컴파일러의 최적화 작업 때문에 비교적 오래 걸렸기 때문입니다.
아래는 약 30분간 지속적인 트래픽을 보내 웜업을 충분히 한 JVM의 p99 수치 비교입니다.
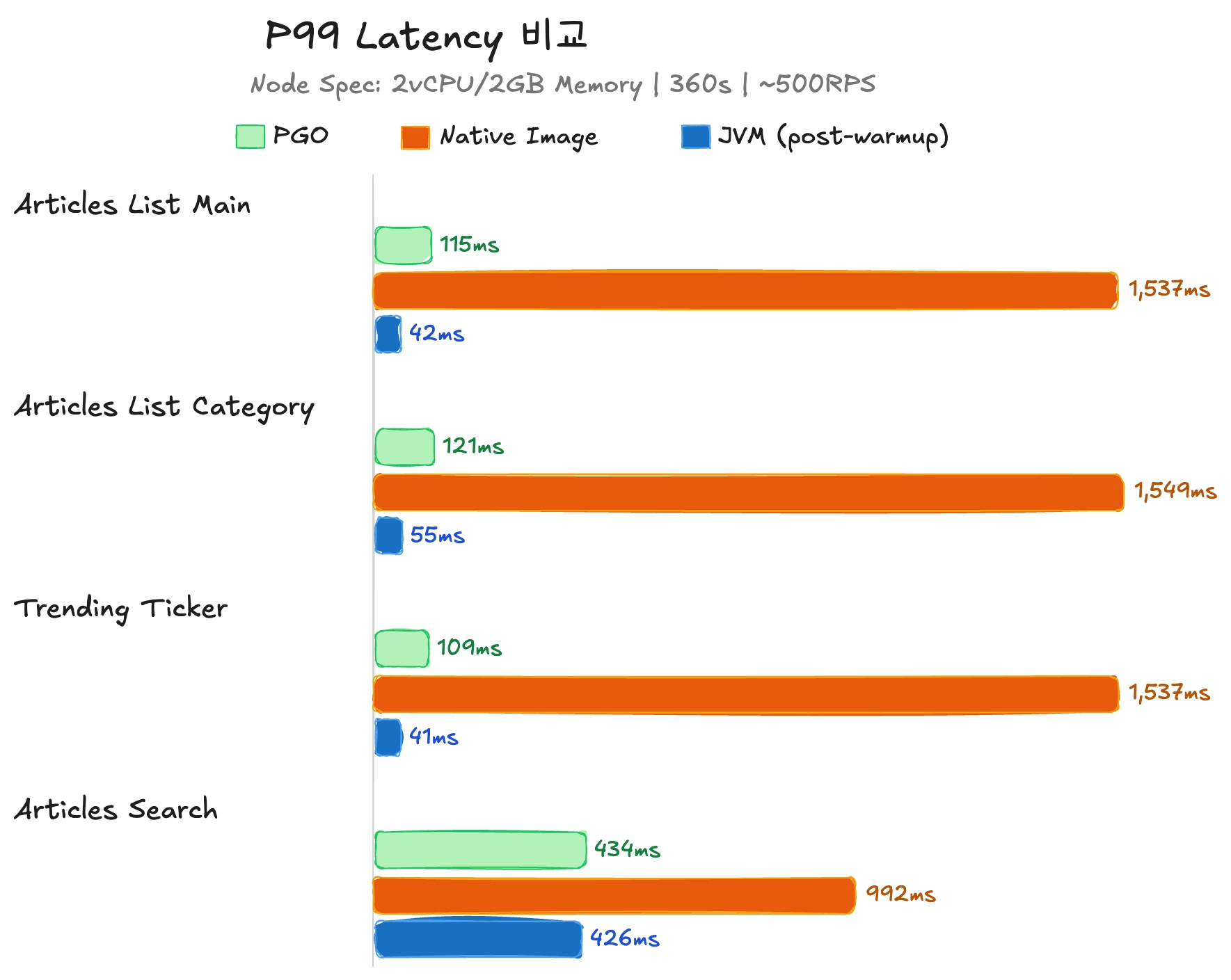
PGO/Native Iamge/JVM(Post-Warmup)
JVM이 웜업 시간을 충분히 거친 후에는 확실히 높은 성능을 보여주는 것을 확인 할 수 있습니다. DB 성능의 영향을 많이 받은 fulltext search를 진행한 search api를 제외하고는 모두 60ms 미만이라는 엄청난 수치를 보여주었습니다.
GraalVM의 공식 홈페이지에서는 PGO를 통해 Native Image의 성능을 JVM과 같거나 혹은 더 높게 끌어올릴 수가 있다고 했는데 직접 실험한 결과를 보니 그렇지 않아 개인적으로 조금 실망 했었습니다. 하지만 PGO 적용을 통해 매우 유의미한 성능개선을 할 수 있었고 이는 훨씬 더 작은 실행 파일 이미지에서 거의 JVM과 유사한 성능을 보였다는 점에서 의의가 있었다고 생각합니다.
PGO-GraalVM 장점 요약
그럼 PGO GraalVM의 진정한 장점은 무엇일까?
다시 한번 말하자면, 우선 가장 큰 장점은 훨씬 더 작은 메모리 풋프린트입니다. 이는 애초에 제가 GraalVM을 devport에 도입하고자 했던 가장 큰 요인이었고 스타트 타임이 매우 빠르다는 점에서 잦은 배포와 롤백을 자유롭게 할 수 있다는 편의성 또한 매력적으로 다가왔었습니다. 이전에 다른 프로젝트를 진행하면서 JVM 기반의 스프링 에플리케이션을 kubernetes에 운영하면서 성능 문제로 인한 많은 어려움을 겪었기 때문입니다. 또한 웜업이 필요없다는 점에서 컨테이너 기반의 환경에서 다양한 스케일 아웃 정책이 필요하면 이 또한 매우 큰 장점으로 다가올 수 있습니다. 그 외에도 장애가 발생해거나 버그가 발견되면 비교적 빠르게 회복을 할 수 있고 또 배포 시 트래픽 스위칭을 기존의 JVM만큼 까다롭게 진행하지 않아도 된다는 점 또한 있을 것 같습니다. 이 모든걸 유지하면서 성능 또한 그에 준하는 수준까지 끌어올리 수 있는 것이 GraalVM Native Image의 장점인 것 같습니다.
장점 요약
- 작은 메모리 풋프린트 — 도입을 결정한 가장 큰 동기. 이전 JVM 기반 Spring 애플리케이션을 K8s에서 운영하며 겪었던 리소스 문제에 대한 직접적인 해결책
- 빠른 스타트 타임 — 잦은 배포와 롤백을 부담 없이 수행 가능
- 웜업 불필요 — 컨테이너 환경에서 스케일 아웃 정책을 자유롭게 설계 가능
- 빠른 장애 복구 — 재기동 비용이 낮아 버그/장애 발생 시 회복 시간 단축
- 단순한 트래픽 스위칭 — JVM처럼 예열 절차를 신경 쓰지 않고도 배포 가능
- 준수한 런타임 성능 — 위 이점들을 유지하면서도 실용적인 수준의 성능 확보
물론 아직 Serial GC와 G1GC만 지원한다는 점에서 세밀한 GC 튜닝이 어려울 수 있고 다양한 관리 부담이 존재 한다는 단점이 있습니다. 결국에는 GraalVM의 도입 여부는 이를 충분히 자신의 상황에 맞게 트레이드 오프를 고려해 선택 해야 하는 부분이라고 생각합니다.
실험 결과는 해당 리포지토리에서 k6 스크립트와 함께 확인 해 보실 수 있습니다.
https://github.com/devport-kr/graalvm-pgo-build-k6-traffic
회고
devport 프로젝트를 진행하면서 자바 생태계의 시야를 좀 더 넓히고자 《JVM 밑바닥까지 파헤치기》 [저우즈밍 지음, 이복연 옮김] 책을 구매했고 많은 부분들을 학습 및 참고하면서 프로젝트를 진행했습니다. Native Image를 적용하기 의해 많은 노력을 했지만 역설적이게도 이를 진행하면서 JVM의 작동 방식에 대해서 더 많은 것을 배웠던 것 같습니다. 특히 JIT 컴파일러의Tiered Compilation, 프로파일이 기반 optimization, deoptimization 등 GraalVM을 적용하지 않더라면 JVM의 추상화 속에서 쉽게 간과 했을 기술들 이었던 것 같습니다.
정말 많은 시간을 투자하면서 고생을 했지만 그만큼 많이 얻어간 시간이었습니다.
